AI安全当前仍处于技术发展的早期阶段,这已成为行业普遍共识。为此,我们团队精心策划了“顶会顶刊AI安全论文研读”系列,致力于帮助全行业从业者以及有志于投身AI安全领域的新生力量,快速掌握最新技术进展与前沿动态。今天迎来第四期:ICCV 2025 | 机器人的“视觉欺骗”——一个彩色补丁如何让智能机器人“精神错乱”。
先回顾一下前三期:第一期探讨了基于启发式诱导的多模态风险分解越狱攻击;第二期是CVPR 2025 highlight,聚焦分散即关键的越狱攻击研究;第三期是ICML 2025的GuardAgent,为AI智能体配备守护者。本期则将目光投向机器人视觉-语言-动作模型的安全漏洞。
作者介绍
这项研究由罗切斯特理工学院(RIT)、密苏里大学堪萨斯城分校、美国海军研究实验室、罗格斯大学以及Meta AI等多个顶尖高校和研究机构联手完成。团队成员均深耕于机器人、计算机视觉与AI安全领域,是该领域的资深专家。论文首次系统性地揭示了当前最先进的视觉-语言-动作(VLA)模型在物理世界中存在的对抗性漏洞,为急速发展的通用机器人领域敲响了安全警钟。
导读
近年来,机器人领域迎来了一场革命性变革:视觉-语言-动作(VLA)模型的出现,使机器人能够像人类一样理解自然语言指令并与物理世界交互,通用机器人的曙光似乎近在咫尺。然而,这种强大能力也引发了一个尖锐且亟待解答的问题:这些智能机器人真的安全吗?传统的网络安全或图像攻击方法,已难以应对机器人“行动层面”的风险。一个微小的视觉干扰,是否可能让机器人执行灾难性的错误动作?
正是基于这一担忧,该论文首次系统性地探索了VLA机器人的对抗性漏洞,并提出了一种基于补丁的对抗性攻击(Patch-Based Adversarial Attack)。作者没有沿用传统的图像分类攻击思路,而是专门为机器人设计了全新的、面向物理动作的攻击目标:无目标动作偏差攻击、无目标位置感知攻击和目标操纵攻击。只需在场景中放置一个精心设计的物理补丁(Adversarial Patch),就能成功欺骗机器人。
同时,论文还构建了一套涵盖模拟与真实世界的评估基准,并提出了一个创新评估指标NAD(归一化动作偏差),用于精细衡量攻击对机器人行为的扰动程度。实验结果令人震惊:在模拟环境中,攻击可导致高达100%的任务失败率;在真实世界的物理机器人上,攻击成功率也超过43%。这项工作揭示了当前VLA模型的系统性安全缺陷,为构建更安全、更可靠的通用机器人迈出了至关重要的第一步。论文已开源。

【论文题目】Exploring the Adversarial Vulnerabilities of Vision-Language-Action Models in Robotics
【论文链接】https://arxiv.org/pdf/2411.13587
研究背景
随着大型语言模型(LLMs)与视觉模型的深度融合,机器人领域诞生了视觉-语言-动作(VLA)模型。这类模型赋予了机器人一个强大的“大脑”,使其能够:
1. 看懂世界 (Vision):通过摄像头理解复杂的现实场景。
2. 听懂指令 (Language):解析人类用自然语言下达的模糊或复杂任务。
3. 执行任务 (Action):规划并生成一系列精确的物理动作来完成指令。
VLA模型的出现极大地推动了通用机器人的发展,让机器人不再局限于工厂流水线上重复单一动作,而是有望进入家庭、医院等复杂环境,成为人类的得力助手。然而,这种强大的自主行动能力也像一把双刃剑——它带来了前所未有的安全风险。传统的AI安全研究大多集中在数字世界,比如让图像分类器把“熊猫”识别成“长臂猿”。但对于一个在物理世界中行动的机器人来说,风险完全不同。一个错误的动作可能不仅仅是识别错误,还可能打碎贵重物品、损坏设备,甚至对周围的人造成伤害。
当前针对机器人的安全防御体系存在显著的空白:
1. 缺乏针对性的攻击方法:大多数攻击方法为图像识别设计,无法直接迁移到机器人上,因为它们没有考虑机器人的物理约束和连续的动作特性。
2. 缺乏有效的评估标准:如何衡量一次攻击对机器人的“危害程度”?仅仅看任务最终是否失败是不够的,需要更精细的指标来量化机器人行为的异常程度。
3. 对物理世界的忽视:很多攻击只在模拟或数字层面有效,能否在光照、角度不断变化的真实物理世界中稳定奏效,是一个巨大的挑战。
为填补这些空白,研究团队首次将研究焦点对准了VLA,系统地研究如何通过物理手段干扰其视觉感知,从而操纵其物理行为。
动机和理论分析
研究的动机源于对现有机器人系统安全性的深刻担忧。作者认为,要真正评估VLA模型的安全性,必须解决两个核心问题:
1. 攻击目标必须与机器人行为直接相关:单纯的像素级扰动对机器人的连续动作影响甚微。攻击必须能引起显著的、有意义的物理偏差,才能构成真正的威胁。
2. 攻击必须在物理世界中可行:攻击不能只停留在电脑屏幕上,而应该是一种可以被打印出来、放置在真实场景中的物理实体,比如一张贴纸或一个卡片。
为了系统性地评估VLA模型在行动层面的安全性,研究团队构建了一套全面的评测基准:
1. 攻击对象 (Victim Model):选择了当时最先进、最具代表性的开源VLA模型 OpenVLA。为了测试攻击的泛化能力,他们还使用了在不同数据集(模拟/真实)上训练的多个OpenVLA变体。
2. 评测环境 (Environments):
- 模拟环境 (Simulation):基于 LIBERO 基准。这是一个包含数百种长序列、复杂操作任务的模拟平台,允许研究者进行大规模、可重复的实验,以充分验证攻击的有效性。
- 真实世界 (Real World):使用 BridgeData V2 数据集,并部署了一台真实的UR10e七自由度机械臂。这证明了他们提出的攻击方法是切实可行的,而非纸上谈兵。
3. 评测指标 (Evaluation Metrics):
- 任务失败率 (Failure Rate, FR):衡量攻击导致机器人任务失败的比例,是评估攻击效果的宏观指标。
- 归一化动作偏差 (Normalized Action Discrepancy, NAD):这是本文提出的一个创新指标。它不再只关心任务的最终成败,而是精细地衡量在每一步动作中,机器人被攻击后的“实际动作”与“正确动作”之间的差距。NAD值越高,说明机器人行为被干扰得越严重,动作越离谱。
这套基准首次将VLA模型的“行为安全”问题系统化、可量化,为后续研究提供了坚实的测试框架。
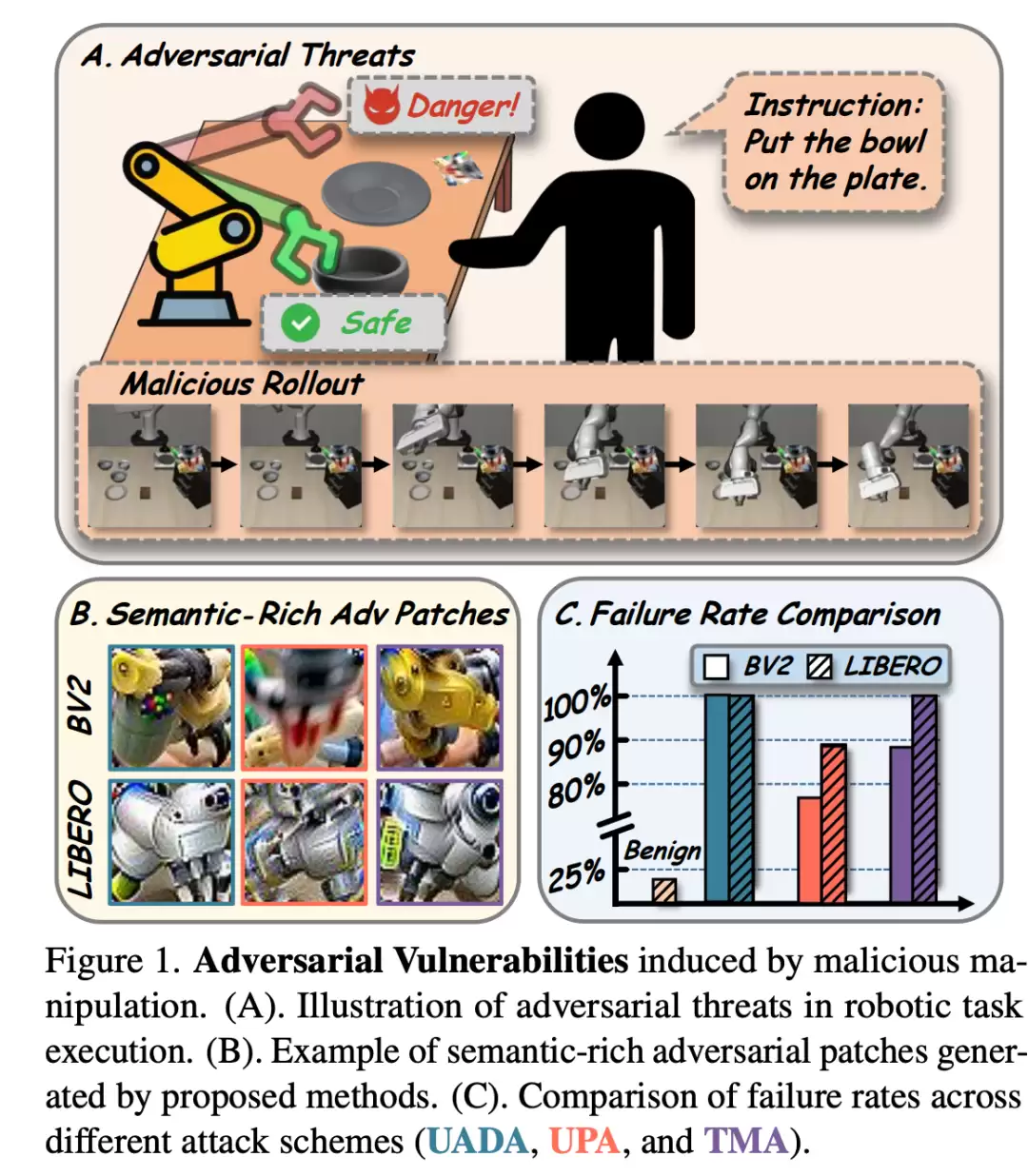
图1: 由恶意操作引发的对抗性漏洞。(A)机器人任务执行中对抗性威胁的示例图。(B)通过所提出的方法生成的语义丰富的对抗性补丁示例。(C)不同攻击方案(UADA、UPA 和 TMA)的失败率对比。
方法
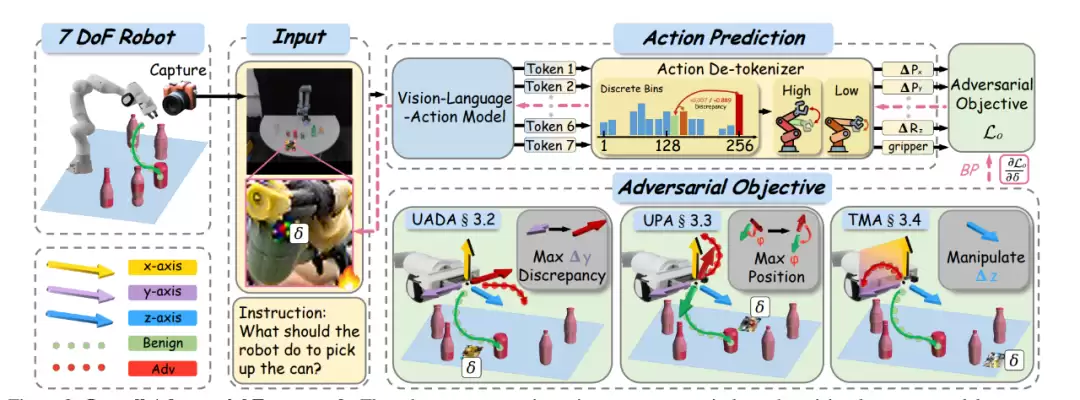
图2: 整体对抗框架。机器人捕获输入图像,通过视觉语言模型对其进行处理以生成代表动作的标记,然后使用动作去标记器进行离散区间预测。该模型通过对抗目标进行优化,这些目标侧重于各种差异和几何形状(即 UADA、UPA、TMA)。前向传播用黑色表示,反向传播用粉色突出显示。这些目标旨在最大化错误并最小化任务性能,视觉重点在于三维空间操作,并在任务执行期间关注生成对抗扰动δ,例如拿起一个罐子。
本研究的核心方法论在于设计并实现了一种物理可行的基于补丁的对抗性攻击(Patch-Based Adversarial Attack)。该方法通过在机器人视觉传感器输入中引入一个经过优化的、小面积的物理补丁δ,旨在系统性地干扰VLA模型的决策过程。与专注于像素级扰动的数字攻击不同,本方法强调攻击在真实物理环境中的可实现性与鲁棒性。
为了有效评估并利用VLA模型在机器人任务执行中的脆弱性,作者没有沿用传统针对图像分类的攻击范式,而是创新性地提出了三种专门针对机器人时空动作特性的攻击目标函数(Attack Objective Functions)。这些函数分别从动作偏差、几何轨迹和定点操纵三个维度对模型进行攻击。
1. UADA (无目标动作偏差攻击 - Untargeted Action Discrepancy Attack)
UADA旨在最大化机器人预测动作与基准真值(ground truth)之间的偏差,从而诱导机器人执行大幅度的错误动作,导致任务失败。该攻击策略不预设特定的错误目标,而是寻求在动作空间内造成最大程度的扰动。其优化过程分为两个阶段:
定义对抗目标:首先,对于给定的基准动作,在机器人各自由度(DoF)的可行动作边界内,确定一个与之距离最远的目标动作。该目标代表了理论上最能扩大偏差的动作。
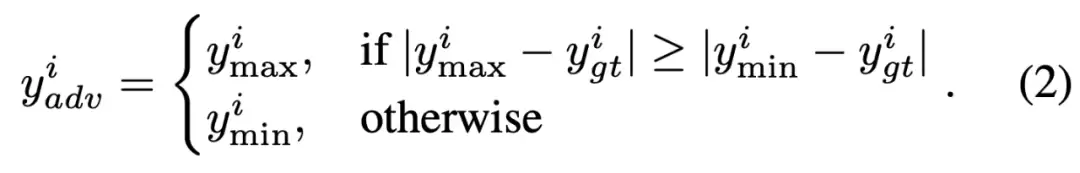
此公式确保了对抗目标始终位于动作空间的边界,从而最大化了与任意动作的潜在偏差。
构建优化函数:为了使优化过程可微,本研究引入了“软动作”(由公式3定义),它通过对模型输出的离散动作概率分布进行加权求和,得到一个连续的动作值。
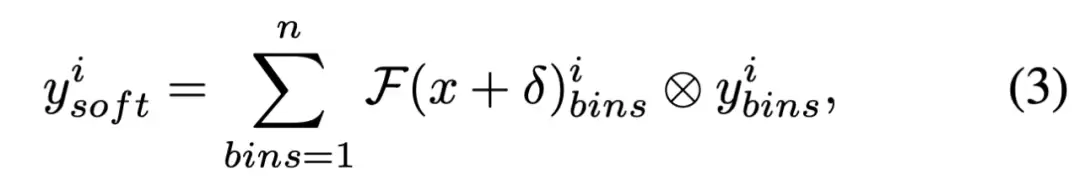
UADA的目标函数 LUADA 被定义为最小化软动作与对抗动作之间的L2范数(平方欧氏距离),从而驱动模型生成趋近于最大偏差目标的动作。
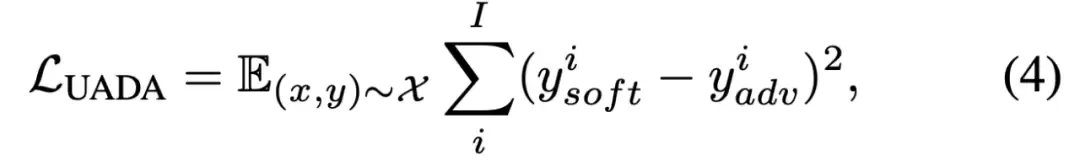
通过梯度下降等优化算法最小化 LUADA,可以生成一个能够显著放大机器人动作误差的对抗性补丁。
2. UPA (无目标位置感知攻击 - Untargeted Position-aware Attack)
UPA攻击专注于从几何层面破坏机器人末端执行器的运动轨迹。与UADA关注单个时间步的动作幅度不同,UPA着眼于由连续动作构成的三维空间路径。它主要攻击控制机器人位置的自由度(ΔPx, ΔPy, ΔPz),利用在每个时间步上引入的方向性误差,这些误差会随时间累积,最终导致机器人轨迹发生显著偏离。
UPA的目标函数 LUPA 精巧地结合了对运动方向和幅度的双重攻击:
- 方向性扰动:通过最小化预测动作向量与最远对抗目标向量之间余弦相似度的负值,来最大化两个向量之间的角度偏差。
- 幅度扰动:通过最小化两个向量之间的L2范数来增大偏差的绝对幅度。
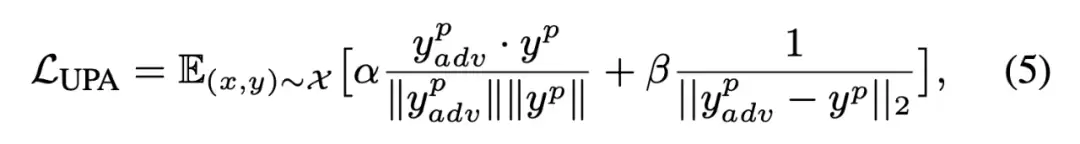
在该公式中,超参数 α 和 β 用于权衡方向性攻击与幅度攻击的重要性。通过最小化 LUPA,生成的补丁能够诱导机器人产生混沌、无目的性的运动轨迹,从而破坏任务的执行。
3. TMA (目标操纵攻击 - Targeted Manipulation Attack)
TMA实现了一种定向攻击策略,旨在精确地操纵机器人,使其执行一个由攻击者预先定义的特定恶意动作。这种攻击模式模拟了更具威胁性的场景,即攻击者意图诱导一种可预测的、特定的系统失效模式,而非随机的混乱行为。
由于VLA模型将连续的动作空间离散化为一系列“箱”(bins),机器人动作预测本质上是一个分类问题。因此,TMA的实现遵循了定向攻击在分类任务中的标准范式:
- 定义恶意目标:攻击者首先指定一个或多个自由度上的目标动作。例如,将某个轴向的移动设为0,以“冻结”该方向的运动。
- 采用交叉熵损失:TMA的目标函数 LTMA 使用交叉熵损失(Cross-Entropy Loss)来最小化模型在受扰动后的预测分布 F(x δ) 与恶意目标的独热(one-hot)分布之间的差异。
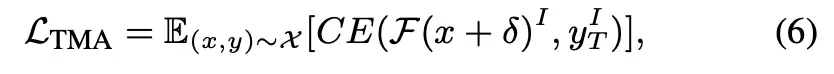
综上所述,这三种攻击目标函数共同构建了一个全面的评估框架,能够从动作幅度、空间轨迹和定点执行等多个关键维度,系统性地探究VLA模型在物理交互任务中的深层对抗性脆弱性。
实验效果
实验设置
1. 数据集与评测环境 (Datasets and Environments):
- 模拟环境 (Simulation):选用 LIBERO 基准,这是一个专为评估机器人长期、多步操作任务而设计的模拟平台。作者特别关注其中的 LIBERO-Long 套件,因为它包含了复杂的任务序列和多样化的物体交互,能更充分地暴露模型在时间累积误差下的脆弱性。
- 真实世界 (Real World):为了验证攻击在物理世界的可行性,作者在一个由 Universal Robots UR10e 七自由度机械臂和 Robotiq Hand-E 夹爪组成的物理平台上进行实验。该平台的数据采集与训练基于 BridgeData V2 数据集,该数据集包含了大规模、多场景的真实世界机器人操作数据。
2. 受害模型 (Victim Models):本文主要攻击目标是 OpenVLA,这是一个当前领先的开源VLA模型。为测试攻击的迁移性(transferability),本文不仅攻击了在LIBERO-Long数据集上训练的模型(in-domain attack),还将在BridgeData V2上生成的对抗补丁用于攻击在LIBERO任务上微调的模型(cross-domain transfer attack),以模拟更具挑战性的黑盒攻击场景。
3. 基线方法 (Baseline Methods):由于这是针对VLA模型的开创性攻击研究,缺乏直接可比的基线。因此,本文构建了两个强基线:
- UMA (无目标操纵攻击):作者将经典的无目标分类攻击(最小化预测与真实标签的交叉熵)适配到机器人动作预测中,旨在将预测动作推离真值。
- 随机噪声 (Random Noise):将一个从高斯分布中采样的随机噪声图案作为补丁,以验证生成的补丁确实是通过优化学习到的有效攻击模式,而非简单的视觉干扰。
4. 评估指标 (Evaluation Metrics):
- 任务失败率 (Failure Rate, FR):宏观指标,定义为 1 - SR (Success Rate),用于评估攻击对任务最终成败的影响。FR越高,攻击越有效。
- 归一化动作偏差 (Normalized Action Discrepancy, NAD):本文提出的细粒度指标,用于量化在每个时间步上,受攻击后的机器人动作与基准动作之间的相对偏差。NAD值越高,说明机器人行为被扰动得越严重。该指标的计算如下:
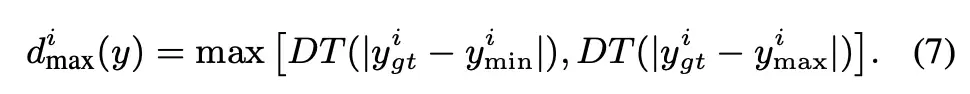
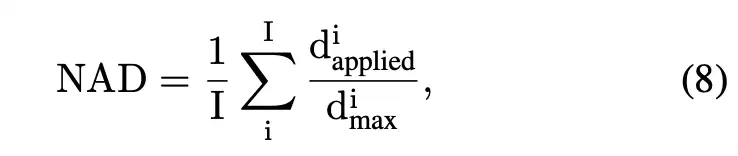
核心实验结果对比
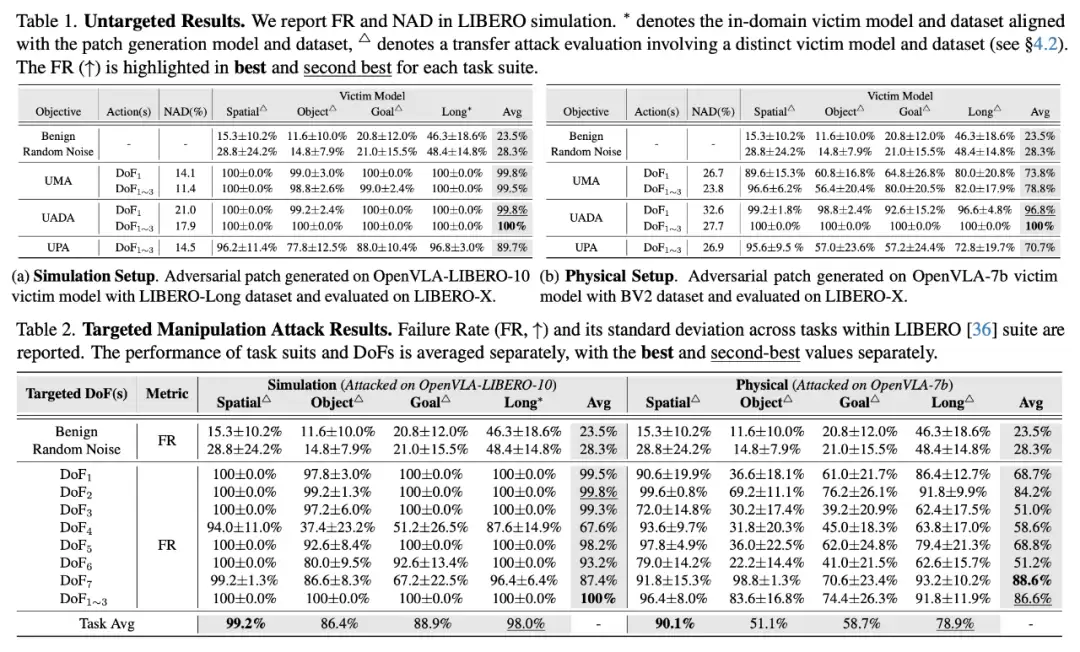
表 1和2:UADA、UPA和TMA三种攻击目标,在模拟和真实物理世界设置下,与两个基线模型的任务失败率(FR)与归一化动作偏差(NAD)对比
攻击的压倒性有效性:在模拟环境中(表1a),提出的UADA和UPA攻击均能实现接近100%的任务失败率,远超基线UMA和随机噪声。特别地,UADA在攻击单个自由度(DoF1)时,其NAD值高达21.0%,显著高于UMA的14.1%,这证明了专门为动作偏差设计的损失函数能更有效地诱导模型产生极端错误行为。
强大的物理世界迁移能力:在更具挑战性的物理设置中(表1b),将在真实世界数据集(BV2)上生成的补丁应用到模拟环境(LIBERO-X)进行测试,攻击依然表现出强大的威力。UADA和UPA生成的恶意动作具有极大的偏差,其NAD值分别高达32.6% (DoF1) 和26.9% (DoF1~3)。这表明生成的对抗模式具有很强的泛化能力,能够跨越模拟与现实的鸿沟(Sim2Real gap)。论文指出,模拟与物理设置下NAD值的差异,可归因于真实世界数据集中更高的环境复杂性、物体多样性和任务难度,这为机器人生成更大的动作偏差提供了更多机会。
TMA的精准操纵能力:在定向攻击任务中(表2),TMA展现了对机器人行为的精准控制能力。在模拟环境中,最大平均失败率达到了100%(良性状态为23.5%);在物理环境中,也达到了88.6%。论文特别指出,在攻击DoF4(控制沿x轴的旋转)时,FR较低。其原因是DoF4在该任务中是一个冗余自由度 (redundant DoF),对其进行攻击不影响任务执行。这突显了在设计机器人对抗攻击时,考虑任务特定性的重要性。
定性研究
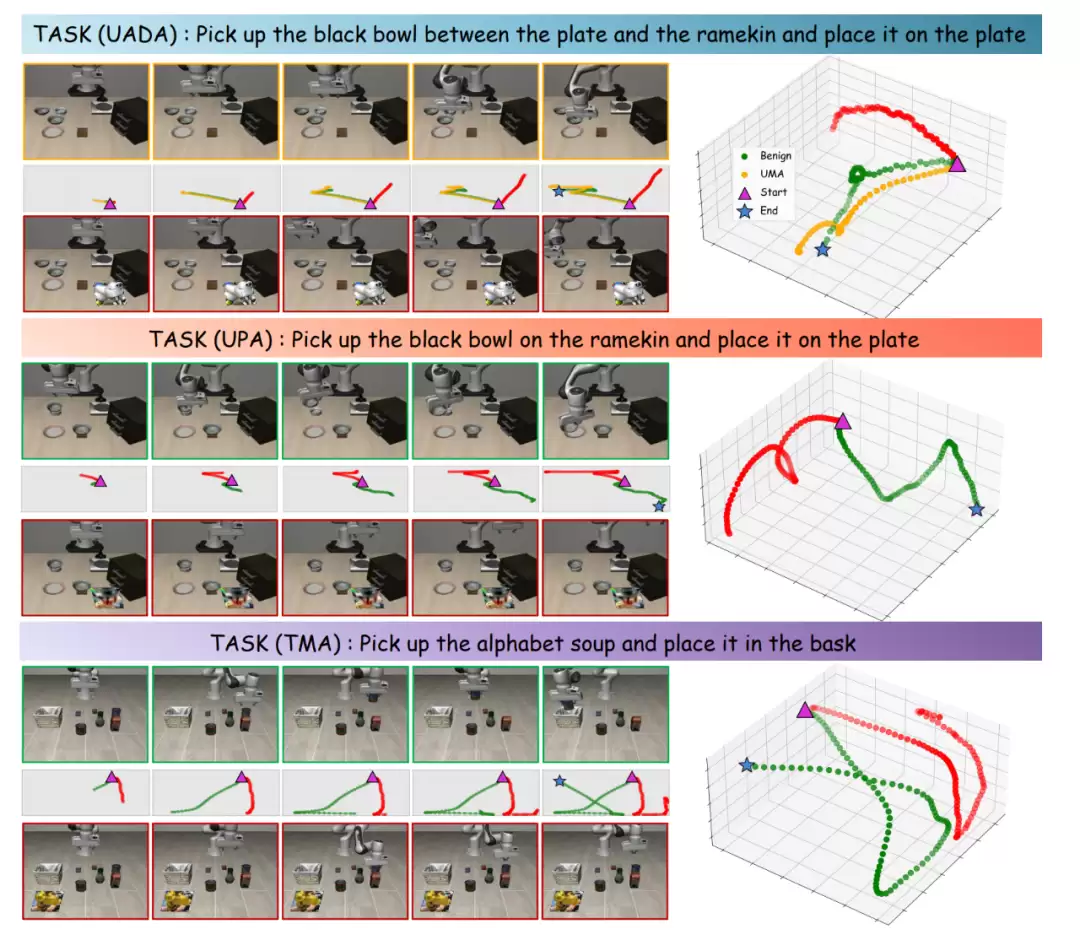
图 3:每个时间步长下良性与对抗性场景的总体 3D 轨迹和 2D 轨迹,以比较生成的对抗性补丁对它们的影响。
- 良性轨迹 (Benign):在没有攻击时(绿色轨迹),机器人的运动平滑、连贯且有明确的目的性,最终成功到达目标点。
- UADA: 相比UMA攻击引起的微小轨迹偏差,UADA能够产生显著更大的轨迹偏离,从而放大对整体任务执行的影响,增加机器人潜在的危害。
- UPA: 在UPA攻击下,机器人表现出混乱和不规则的行为 (chaotic and irregular behaviors),包括机械臂移动到摄像头视野之外的情况。这归因于对抗补丁成功地扰乱了模型的空间感知能力。
- TMA: 在TMA攻击下,可以观察到机器人在被攻击的轴向上(例如x轴)的运动范围显著减小,这表明定向攻击能够有效地约束机器人的特定动作。

图4 直观地展示了物理世界中的一次具体实验案例。图中的任务指令为“把胡萝卜放进碗里 (Put the carrot in the bowl)”。
- 第一行展示的是良性情况 (benign case):在没有对抗补丁干扰时,机器人能够正确识别指令和物体,规划出合理的运动轨迹,并成功完成任务。
- 第二行展示的是对抗情况 (adversarial case):当场景中引入了由UADA方法生成的对抗补丁后,机器人的行为受到了显著的操纵。
该实验得出的核心结论如下:
- 由UADA生成的对抗补丁展示了有效操纵机器人 (manipulate the robot effectively) 的能力。
- 在总共100次真实世界试验中,攻击的成功率超过了43% (exceeding 43%)。
- 论文明确指出,尽管这一成功率低于在数字模拟中观察到的性能(即100%),但它仍然突显了本研究提出的补丁在无需任何额外适配 (without the need for further adaptations) 的情况下,在物理世界应用中的有效性。
- 最为关键的是,在成功的攻击中观察到,机器人产生的不规律运动 (erratic movements)(与模拟场景中的现象类似),对人类安全和周围环境构成了重大风险 (significant risks)。这一发现强调了VLA模型在真实世界应用中面临的严峻威胁。
诊断性实验与鲁棒性评估
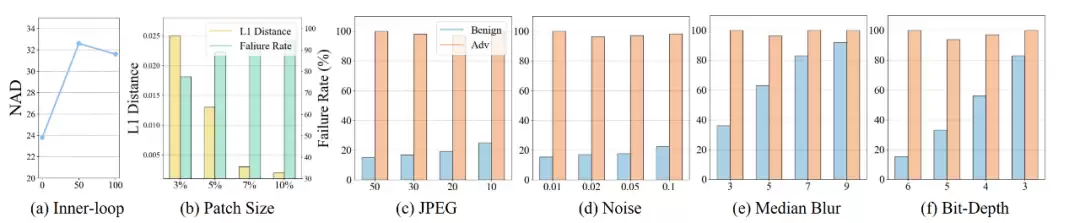
图 5:每个时间步长下良性与对抗性场景的总体 3D 轨迹和 2D 轨迹,以比较生成的对抗性补丁对它们的影响。
- 内部循环步数的影响 (Impact of Inner-loops): 结果显示,随着内部循环步数增加,NAD率先提升然后趋于平缓。实验选择50步作为性能和效率的平衡点。
- 补丁尺寸的影响 (Impact of Patch Size): 预测动作与目标动作的L1距离与补丁尺寸呈反比关系,而任务失败率(FR)与补丁尺寸呈正比关系。这表明更大的补丁为攻击优化提供了更多空间。
- 对防御策略的鲁棒性: 论文测试了四种常见的防御技术(JPEG压缩、添加噪声、中值模糊、降低位深度)。结果显示,所提出的对抗性攻击能够绕过 (bypasses) 大多数防御策略。
系统性讨论

图6:补丁可视化。内容丰富的补丁。
- 补丁模式分析 (Patch Pattern Analysis): 一个核心发现是,生成的对抗补丁在视觉上与机器人自身的结构性关节 (structural joints of a robotic arm) 存在惊人的相似性。
- 系统性漏洞假说: 论文据此提出一个假说:VLA模型在训练过程中可能因受限的摄像头视角而产生了一种表征偏见 (learned representation bias),即模型过度依赖与机器人外观相似的视觉特征来进行决策。对抗性攻击利用并放大了这个系统性的弱点。
结语
尽管视觉-语言-动作(VLA)模型因其强大的机器人能力而获得了广泛的关注与普及,但本研究开创性地提出了针对机器人系统的特定攻击目标,并证明了这些模型实际上容易受到多种类型的攻击。实验结果表明,本文提出的攻击方法暴露了VLA模型中存在的重大漏洞,这引发了人们对于草率地将这些系统部署到现实世界中的担忧。本研究提出的框架为提升人工智能增强的机器人系统的可靠性做出了开创性与奠基性的贡献。




