进入2025年以后,绝大多数企业的AI项目正加速迈入Agent时代。
企业不再满足于只会简单问答的聊天机器人。他们真正期盼的是能自主行动的智能体:能够自动识别并排查系统故障、自动处理工单并分派工程师、自动跟进客户并预估成单概率、自动执行跨部门业务流程,甚至基于实时业务状态做出运营决策。
然而,从演示走向实际生产部署,几乎每一步都会遇到意想不到的挑战。很多团队发现,Agent在演示环境中表现得机智灵活,可一旦接入真实的企业系统,便开始出现各种“失智”行为:回答看似正确,却与实际业务价值毫无关联;推理过程漏洞百出,关键因果链条缺失;多步骤任务执行到中途突然“失忆”;给出违背公司经营常理的业务建议;不同Agent同时得出相互冲突的结论,让业务部门彻底失去信任。
面对这些问题,许多团队的第一反应是将问题归咎于模型:“GPT还是不够强。”“Claude的推理能力太弱。”“DeepSeek的幻觉太严重。”但在Arango的观察中,核心问题根本不在于模型。关键在于——企业始终未能真正为Agent提供可用的业务上下文。
一个真实的企业级错误:500错误与消失的上下文
假设你是一家大型电商平台的技术负责人。凌晨两点,报警电话骤然响起:用户支付失败率突然飙升。你被紧急拉入线上会议,所有人都在等待结论。你打开运维助手,输入了一行指令:“为什么支付失败?”
Agent快速检索了最近15分钟的日志,给出了答案:“支付服务返回500错误,建议重启支付服务实例。”
从语言层面看,这个回答无可挑剔。它准确捕获了日志中的异常信号,表达了正确的技术判断。但从业务层面看,这个回答几乎没有价值——甚至可能构成危险的误导。
因为真正的问题根源是一条完整的因果链:
22:03 Redis集群发生节点重启→连接池瞬间被耗尽→大量订单服务调用超时→支付服务调用失败→支付网关出现500错误→用户端订单支付失败
500错误只是整条链路的末端结果,而Redis节点重启才是真正的根因。如果不恢复Redis容量或调整连接池配置,即便重启支付服务一百次,故障依然存在。
那为什么Agent未能发现根因?因为它看到的,是孤立、扁平的日志片段,而非还原后的完整业务上下文。它不知道支付服务依赖于Redis,不清楚Redis集群的变更历史,也无法理解当晚发生的所有关联事件之间的因果网络。这就是问题的本质:Agent拥有数据,却缺少上下文。
RAG的局限:当“找文档”不再够用
过去两年,行业中最主流的解决方案是RAG(检索增强生成),其架构简单直接:用户提问→Embedding向量化→向量库语义检索→找到最相关的文档片段→交给LLM生成回答。
这种模式对于知识问答型场景非常有效。比如:“公司最新的报销流程是什么?”“OAuth2授权码模式是如何工作的?”“产品A和产品B的功能差异在哪里?”这些问题的答案,天然封装在现有的文档、手册和规范之中。它们本质上是在查找知识。
但企业环境里最关键的决策问题,极少是单纯的知识问答,绝大多数是企业运营中至关重要的关系分析与因果关系推断。例如:“支付为什么突然失败?”(这是事件与组件之间的因果链问题)“哪些客户最有可能在30天内续约?”(这是客户行为与产品使用之间的关联问题)“这次发布的风险究竟在哪里?”(这是变更、依赖和业务影响之间的影响面问题)“哪个供应商是我们的单点风险?”(这是供应链节点与依赖度的网络问题)
回答这些问题,需要理解的远不止某一篇文档,而是:实体与实体之间的关联(客户、产品、合同、团队、系统);事件与事件之间的时序与因果(发布、变更、告警、工单);组织与组织之间的影响范围(部门、权限、流程、SLA)。而这些关系,往往不完整地存在于任何一份单一的文档、表格或日志中。它们是跨系统、跨模态、跨时间的碎片化信息。
企业数据的原罪:上下文碎片化
Arango在其Contextual Data Platform中反复强调一个无法回避的现实:企业数据天然是高度碎片化的。一个所谓的“客户360视图”背后,可能是支离破碎的数据结构:CRM中记录了客户联系人、阶段、最后沟通时间;ERP中存有应收账款、历史订单、信用额度;邮件系统里包含最近三周的报价沟通记录;客服系统里有正在处理的投诉与工单;工单系统中有关联的P1故障及其处理人员;合同系统里存有即将到期的合同与续约条款;知识库里是该客户所在行业的最佳实践案例。
对于经验丰富的人类员工,他们天生具备“上下文拼接”能力:接到客户电话时,脑海中会自动融合投诉历史、付款状态、合同条款和最近接触记录,从而做出合理判断。但Agent不具备这种跨越系统边界的“自动拼接”能力。绝大多数情况下,它被限定在某个系统或某类数据切片内,看到的永远是局部真相。
这也就是为什么,销售Agent可能会根据“客户上周反复打开报价单”这一信号,果断建议:“立刻安排高层拜访,重点推进签约。”从销售漏斗数据来看,这个判断并无毛病。但从企业全局来看,可能完全错误。因为同一时刻,财务系统已经标记该客户存在严重逾期未付款,客服系统显示多个产品缺陷投诉未被处理,法务系统指出该客户存在合同违约风险。销售Agent的判断是准确的,但业务结论却是灾难性的。缺少上下文,就等于缺少判断力。
什么才是真正的“上下文”?
一个普遍的误解是:上下文等于更多文档。似乎只要把PDF、Wiki和邮件都向量化,Agent就自然获得了上下文。但这恰恰是RAG思维最大的盲区。
Arango对“上下文”的定义,更接近一个核心概念:业务上下文(Business Context),即业务运行过程中自然产生的、所有相互关联的、动态变化的信息集合。它既包括传统的非结构化知识:文档、PDF、Wiki页面、邮件正文;更包括结构化的、动态的、彼此勾连的业务要素:用户、客户、供应商;产品、SKU、订单;服务、微服务、基础设施组件;事件、告警、变更、发布;流程、审批、工单流转;权限、角色、组织架构;实时状态(库存、在线、健康度)。
但仅有要素本身还不够。真正的上下文是这些要素之间的关联及其动态演化,例如:客户A签订合同B,关联产品订阅C,部署在环境D,产生工单E,分配给运维工程师F,隶属于支持团队G。当这些关联被完整地连接起来,Agent从“客户A投诉”这一事件中获得的就不再是孤立的投诉记录,而是可以沿着图游走的丰富上下文:合同等级、产品依赖、环境健康度、工单历史、责任人忙闲度。上下文不是信息的简单堆叠,而是信息之间的连接与深层意义。
Arango将其核心目标概括为三个词:统一的、实时的、可信的业务上下文。统一,意味着跨系统打破数据孤岛,以同一个语义层表达;实时,意味着不依赖离线批处理,而是持续捕获变化并更新关联;可信,意味着来源清晰、血缘完整、权限受控,每一步推理都可追溯。
为什么Agent天生依赖上下文层?
Agent与ChatBot的本质区别,不在于模型强弱,而在于行动还是回答。ChatBot的输出是信息,而Agent的输出是决策和行动。任何一个负责任的行动,都必须建立在完整、新鲜、可信的上下文基础之上。
举个例子,用户对智能助理说:“帮我安排下周去纽约出差,顺便见一下客户。”这句话的语义虽然清晰,但信息量严重不足。要真正完成这个动作,Agent至少还需要掌握:这个用户是谁?当前职位和权限如何?下周哪几天有空?是否有不可移动的日程?纽约要见的客户是什么级别?最近三次沟通的内容和情绪状态?公司差旅政策是什么?预算上限、舱位标准、审批流程如何?用户本人的出行偏好是什么?该客户是否存在未解决的严重问题,此时拜访是否合适?
这些信息分散在日历系统、CRM、邮件记录、HR系统、差旅平台和业务沟通工具中。任何一条的缺失,都可能让执行结果陷入尴尬甚至带来商业损失。
传统做法是,Agent每接到一个任务,便临时到各系统去检索、提取、拼装上下文。Arango将这种现象称为“推理时上下文重建”。这种方法存在三个根本性缺陷:
第一,速度慢。每次推理都需要跨多个异构系统进行数据检索与聚合,涉及API调用、权限检查、数据格式转换,延迟极高,在需要快速响应的生产环境中完全不现实。
第二,不一致。不同的Agent、同一Agent的不同调用,由于时序差异、数据更新滞后或查询路径不同,可能拿到完全不同的上下文视图。这直接导致开头所说的“不同Agent得出相互矛盾结论”的混乱局面。
第三,不可解释。当Agent做出一个错误决策,团队回溯时发现,它使用的上下文是“临时拼凑”出来的,没有完整的血缘和版本记录,完全无法确定是模型错、数据错还是拼装逻辑错。
因此,要让Agent在真实企业环境中持续可靠地行动,必须把上下文从“临时制品”升级为持续维护的基础设施。
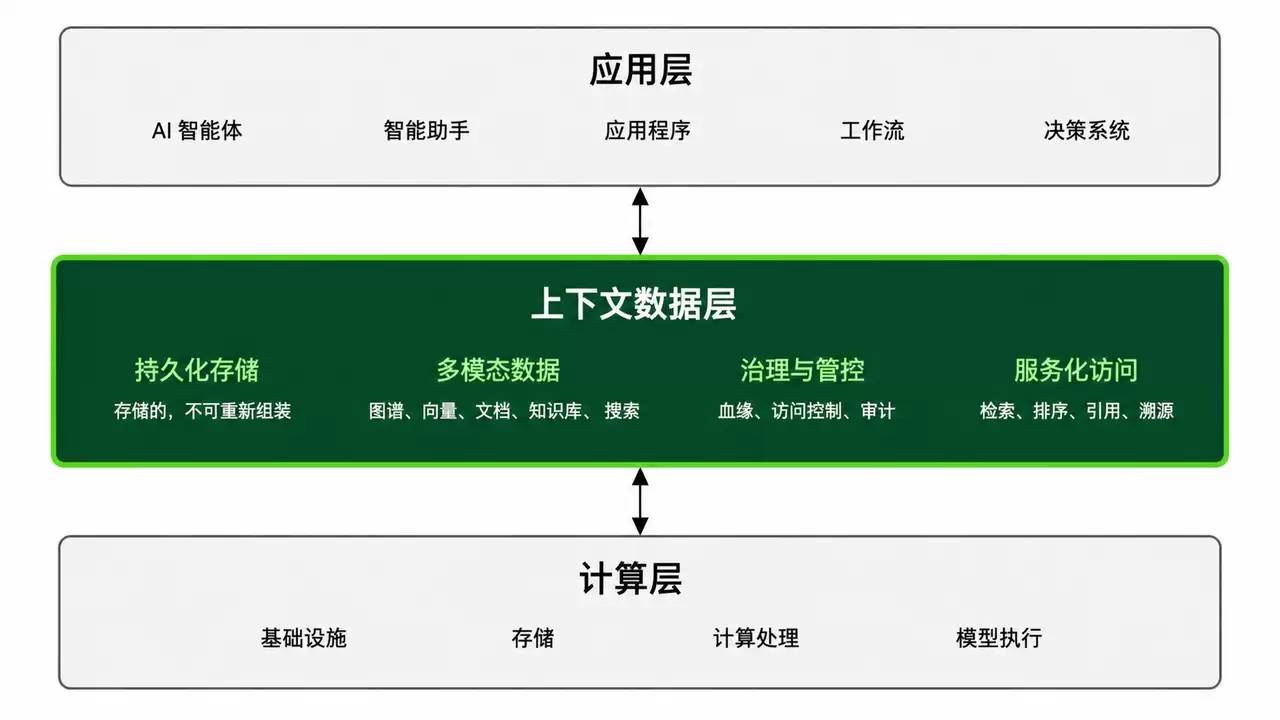
解法:Contextual Data Layer——提前构建的业务语义层
Arango给出的方案非常直接:不要在推理时重建上下文,而应该提前构建上下文,并以API的形式持续供给。这就是Contextual Data Layer(上下文数据层)的核心思想。
架构对比十分明显:传统RAG模式是数据源→向量化→检索片段→LLM;上下文层模式则是各类业务数据源→Contextual Data Layer(持续同步、实时建模)→Agent(获取完整上下文)→LLM(推理与行动)。
Contextual Data Layer并不取代数据源,而是在数据源之上,持续维护一个活跃的企业业务上下文图谱,其中包含:实体(客户、产品、合同、系统、人员、事件);关系(依赖、所属、影响、版本、沟通、交易);状态(在线状态、库存量、运行健康状况、审批节点);事件流(变更记录、告警通知、用户行为);规则与权限(谁有权看到什么,什么操作受什么策略约束)。这使得所有Agent不再各自为战地去理解企业,而是共享同一个统一、实时、可信的业务语义层。
为什么是图模型?上下文的内核是关系网络
很多人会问:用关系数据库、宽表或者更强大的向量库,能不能完成这个任务?答案是:局部可以,整体不能。因为上下文的本质,不是一张二维表上的属性字段,而是高度互联的关系网络。回到支付故障的例子:支付服务依赖Redis集群,Redis集群部署于服务器Node-42,关联最近变更记录#12901,触发告警事件Alert-3344,负责运维团队SRE-Payments,团队包含成员张×、李×。
这个结构天然就是图。如果强行用宽表去表达,要么产生可怕的连接查询和性能瓶颈,要么丢失关系之间的多层依赖,最终给Agent的还是“变形的碎片”。Arango之所以选择图作为核心模型,正是因为图是表达“企业脉络”最高效、最自然的方式。与此同时,Arango并没有抛弃文档、键值、全文检索等多模型能力,而是以图作为骨架,把不同模型的能力有机融合在一个引擎里。
更关键的是,企业现在不必再手工维护一副巨大而昂贵的企业知识图谱。Arango推出的AutoGraph技术,可以直接从现有业务数据中自动构建Context Graph:自动识别实体(通过规则、模式匹配、元数据);自动推断关系(外键、引用、命名规范、事件关联);自动发现依赖链路和服务拓扑;自动注入业务语义,并保持增量更新。最终,这个图不是某个部门的一次性项目成果,而是一个持续自更新的、活的上下文网络,可随时被Agent查询和遍历。
举个更具业务冲击力的例子:供应链风险。当一个地区的二级供应商出现合规问题,Context Graph可以实时沿着“部件→组件→产品→客户合同”的路径,一键识别出所有受影响的高价值客户合同,并触发主动响应。这种全局冲击分析,离开图几乎无法实时完成。
从RAG时代到Context Engineering时代
过去几年,整个行业的注意力被Prompt Engineering吸引,紧接着是RAG Engineering的狂热。大家反复琢磨如何写出更精妙的提示词、如何调优分块策略、如何改进向量相似度。而Arango点出了下一波真正的分水岭:Context Engineering(上下文工程)。
核心问题已经发生根本迁移:不再问“如何让模型更聪明?”而是问“如何让模型获得正确的、完整的、可信的业务上下文?”因为当模型能力日趋同质化,Agent的竞争力不会来自模型参数的数量,而是来自上下文的质量。谁能够率先把散落在文档、数据库、事件流、业务规则和实时状态中的所有碎片,连接成一个统一、实时、可信的Contextual Data Layer,谁才能真正构建出经得起生产环境考验的Enterprise Agent。
这就是为什么Arango不再仅仅把自己定位为一家多模型数据库公司,而是开始重新定义自己为:“The Context Layer for Enterprise AI”——企业AI的上下文层。在这个新的时代叙事里,上下文不再是AI的辅助信息,不再是临时拼凑的检索片段,而是新的基础设施本身。
结语:把上下文当作第一要素
要让Agent不再“犯蠢”,靠的从来不是等待下一版更强的模型。真正重要的是,从现在开始,把上下文当作企业AI体系中的第一要素——提前构建、统一治理、实时演进。当你拥有一个能够持续连接企业所有业务要素的上下文层时,Agent看到的就不再是碎片化的日志、文档或表格,而是一个活的、可供推理的商业世界。从那一刻起,它才开始真正变得聪明。




