OpenAI最新推出的GPT-Realtime-2模型,并非简单的性能迭代,而是从底层架构上彻底重构了语音AI。该模型首次将GPT-5级别的推理能力融入实时语音交互中,在Big Bench Audio语音推理测试中取得了96.6%的准确率,与谷歌Gemini 3.1 Flash Live Preview - High版本的表现持平。
性能背后的架构革命
过去,语音系统遵循一条流水线作业:先进行语音识别(ASR),再交由大模型理解处理(LLM),最后由语音合成(TTS)输出——每个环节都必须等待前一环节完成后才能启动。而GPT-Realtime-2直接将模型嵌入持续的音频循环中,在对话进行的同时实现实时推理,无须等一轮结束再开始下一轮。
这种架构变革带来了多项实质改进:并行工具调用与工具透明度、更强的对话恢复能力,以及可调节的推理强度。开发者可以在minimal到xhigh五档之间灵活选择,平衡延迟与推理深度。在对话动态测试中,其最小推理模式以96.1%的得分保持领先,尤其在暂停处理和话轮转换这些容易出现“卡顿”的场景中表现优异。
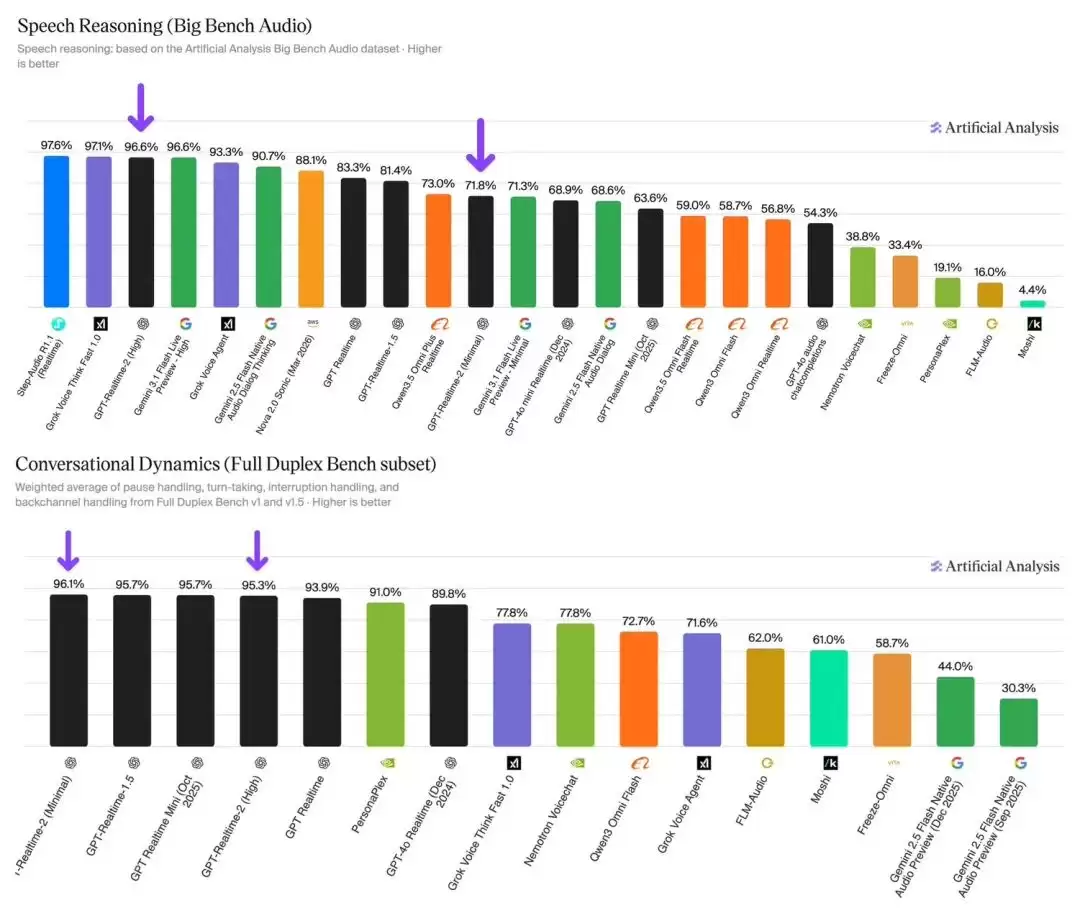
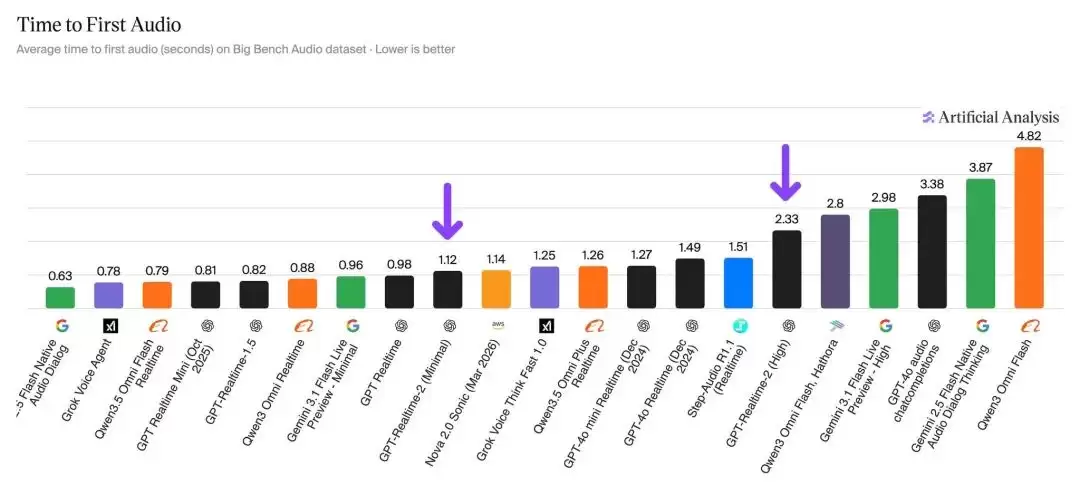
技术层面,128K的上下文窗口是前一代的4倍——这可不是一个小数字。新增的可调节推理强度带来了肉眼可见的差异:高强度模式下首次音频响应时间需要2.33秒,而最低强度下直接压缩到1.12秒——速度快了一倍以上。
实际应用效果显著
真实的测试数据最能说明问题。Zillow在真实通话场景中发现,GPT-Realtime-2将通话成功率从69%一举提升至95%。Zillow的AI负责人Josh Weisberg直言:“在对抗性基准测试中,经过提示优化后通话成功率提高了26个百分点。而且它在公平住房合规性方面明显更加稳健——这对我们来说至关重要。”
当然,榜单上仍有领先者:StepFun的Step-Audio R1.1以97.6%的准确率继续占据语音推理榜首。有开发者已经开始质疑当前测试标准可能已“饱和”,认为生产环境中的持续延迟与可靠性才是更值得关注的指标。
配套生态与价格策略
除了GPT-Realtime-2,OpenAI还同步推出了两款配套模型:GPT-Realtime-Translate(支持70多种输入语言和13种输出语言的实时翻译)和GPT-Realtime-Whisper(低延迟流式转录模型)。三条产品线同时铺开,生态布局意图十分明显。
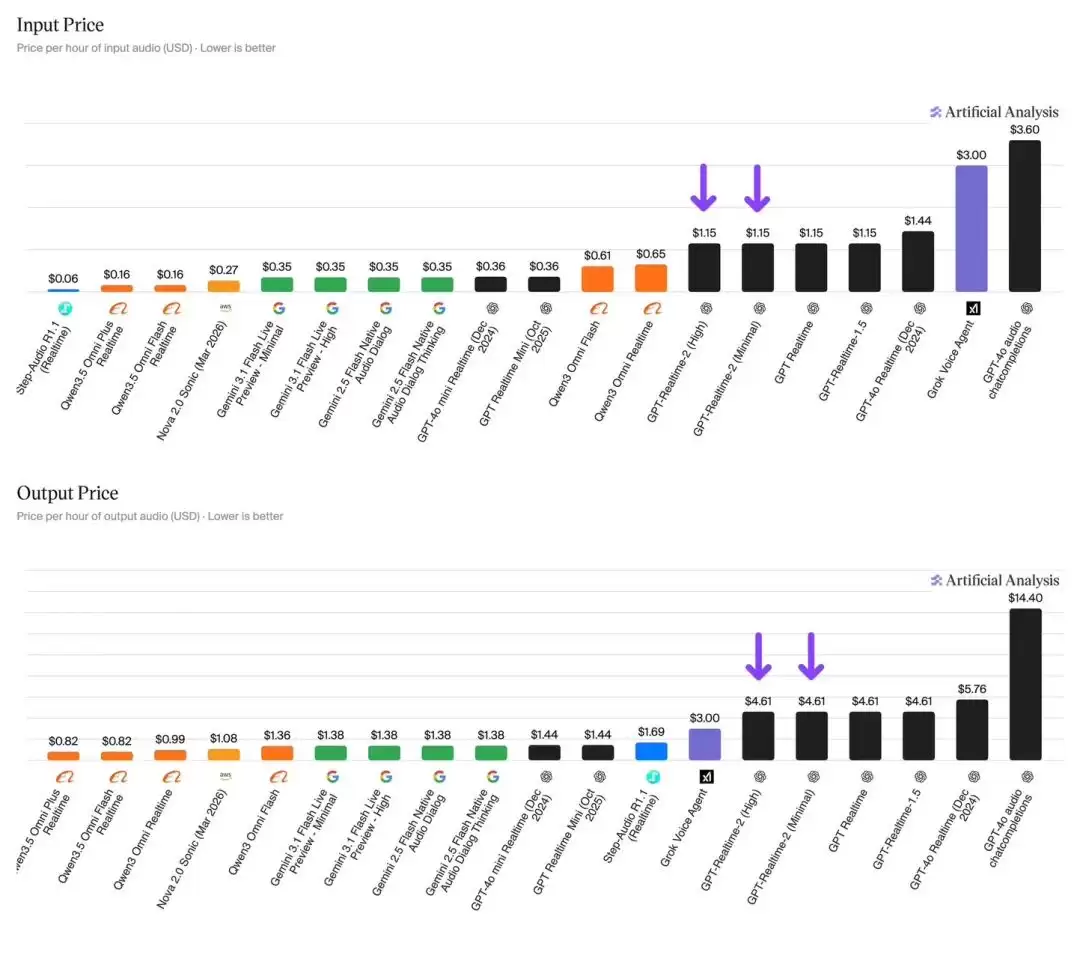
价格方面则保持稳定:音频输入每小时1.15美元,输出每小时4.61美元。对比部分竞品最低0.06美元/小时的输入价格,这一定价显得相当自信——当然,这也是真正能落地使用的代价。
行业反应与未来展望
开发者社区的反应可以用“沸腾”来形容。有评论指出:“实时GPT-5推理是每个语音初创公司都在等待的组合拳”——但OpenAI直接将其做成API层发布,这一举措很可能会改写不少创业公司的路线图。
也有人更务实:“真正的考验在于对话修复能力:能不能打断、能不能从错误回合中爬出来,能不能在4分钟的通话里始终保持状态。延迟只是基本功。”
这三个模型加在一起,构成了新一代语音接口的基础能力。从过去简单的“问一句答一句”,开始转向真正能干活、能对话的语音界面。方向对了,剩下的就是时间问题。




