过去两年,企业在AI领域的投入持续加大,可以说是一路加速狂奔。大模型、AIGC、智能客服、工业视觉、智能运维、医疗影像分析、数据智能平台……这些热门应用纷纷从概念验证阶段步入实际生产环境。当大家的目光普遍聚焦在GPU算力、模型框架、向量数据库和存储系统上时,一个基础却至关重要的命题常常被忽略:网络,是否真正能够支撑AI业务的持续、稳定运行?
在传统业务中,网络故障的表现通常很直接——访问速度变慢、连接失败、系统不可用,故障特征明显。然而,在AI基础设施的复杂环境中,网络问题要隐蔽得多。一次微小的数据包丢失、一次不经意的TCP重传、一段链路的瞬时拥塞,甚至是一次DNS解析失败——这些在传统业务里可能只是“稍微卡顿一下”的小问题,到了AI环境中,就可能引发严重后果:GPU空转、数据加载延迟、推理响应时间升高、服务调用超时。更麻烦的是,运维团队很容易将故障根源误判为算力不足、存储性能不够或应用架构存在缺陷。
这就意味着,AI时代的网络运维,不能再停留在“链路是否连通”这种简单的二元判断上,必须建立细粒度的网络性能可视化与故障快速定位能力。
AI基础设施为何高度依赖网络?
AI应用并非孤立的单点系统,它是由算力、存储、数据、模型、服务和用户访问共同编织而成的复杂基础设施。在不同应用场景下,网络都扮演着决定性的角色:
以训练场景为例,训练数据需要从存储系统持续传输到计算节点,分布式训练任务要求多个节点之间频繁通信。一旦网络出现拥塞、重传或延迟抖动,部分节点便只能等待,整体训练效率会直接受到拖累。推理场景更是如此,用户发起的请求通常要经过前端入口、API网关、模型服务、数据库、缓存、向量检索,再加上一系列业务系统,任何一个网络链路上的异常,最终都会被用户感知为“响应太慢”或“服务不稳定”。至于AI数据管道,数据采集、清洗、同步、标注、归档和分发,全部依赖大量的网络传输;吞吐量一旦不稳,数据准备速度就会滞后,模型迭代的节奏也会随之被打乱。在边缘AI场景,如工业视觉检测、视频分析、园区安防、医疗影像传输中,网络直接影响图像、视频和传感器数据的实时传输质量;现场链路稍有波动,即使算法再精准也无济于事。
因此,AI基础设施若想实现稳定运行,仅有强大的算力远远不够,还必须拥有可观测、可分析、可追溯的网络层作为坚实后盾。
AI业务中的网络问题,为何难以定位?
AI系统中的网络问题通常具备三个令人头疼的特点:
第一,流量规模庞大且突发性极强。训练数据、模型文件、日志、特征向量、多媒体数据的传输动辄几个GB甚至更大规模,网络瓶颈往往突然出现,或者仅存于某个特定阶段或任务中,常规监控手段根本难以捕捉。第二,链路关系异常复杂。AI平台涉及计算节点、存储、容器网络、调度平台、API服务、数据库、缓存以及各种外部系统。问题出现后,应用团队、系统团队、存储团队、网络团队往往需要共同排查,但由于缺乏统一的网络事实依据,各方很容易陷入相互推诿的境地。第三,故障现象极易被误判。GPU利用率下降了,未必是GPU本身的问题;模型响应变慢了,未必是模型自身的缺陷;数据读取速度慢了,也未必是存储出现了瓶颈——大量根因其实隐藏在网络层,例如连接重传、链路拥塞、DNS异常、会话质量下降,或者存在异常流量在暗中抢占带宽。
正因如此,AI基础设施迫切需要一种工具,能够实时查看网络状态、快速定位性能瓶颈、并可回溯历史数据,让各个团队在事实基础上协同进行故障排除。
Allegro网络万用表:让AI基础设施网络问题可见、可查、可定位
Allegro网络万用表并非AI算法平台,也不是模型训练框架,它的核心价值非常明确——帮助企业清晰洞察网络中正在发生的一切,精准定位性能瓶颈,并准确判断问题根源究竟在网络、服务器、存储还是应用层面。
在AI基础设施中,它可以作为网络性能可视化与故障定位工具,部署在关键网络路径上,对AI平台相关的流量进行实时分析。通过观测网络流量、连接质量、协议行为、会话状态和性能指标,运维团队能够迅速获取判断依据,不再依赖零散的日志、个人经验或反复抓包等耗时操作。
针对AI训练集群,它能帮助用户看清计算节点、存储系统和管理平台之间的通信质量,快速发现高带宽占用、异常连接、重传、延迟抖动等潜在瓶颈。针对AI推理平台,它能分析用户访问、API调用、模型服务、数据库查询和外部系统调用过程中的网络异常,帮助用户在响应慢、连接失败、超时、服务不稳定的情况下快速找到真正原因。针对AI数据管道,它能监测大规模数据传输的带宽占用、通信对象、流量变化和异常行为,帮助用户区分瓶颈究竟在网络、存储还是应用处理层面。而针对边缘AI场景,它能验证现场链路质量,观察摄像头、边缘设备、服务器和业务平台之间的数据传输状态,为工业视觉、视频分析、边缘推理等场景提供网络侧的诊断依据。
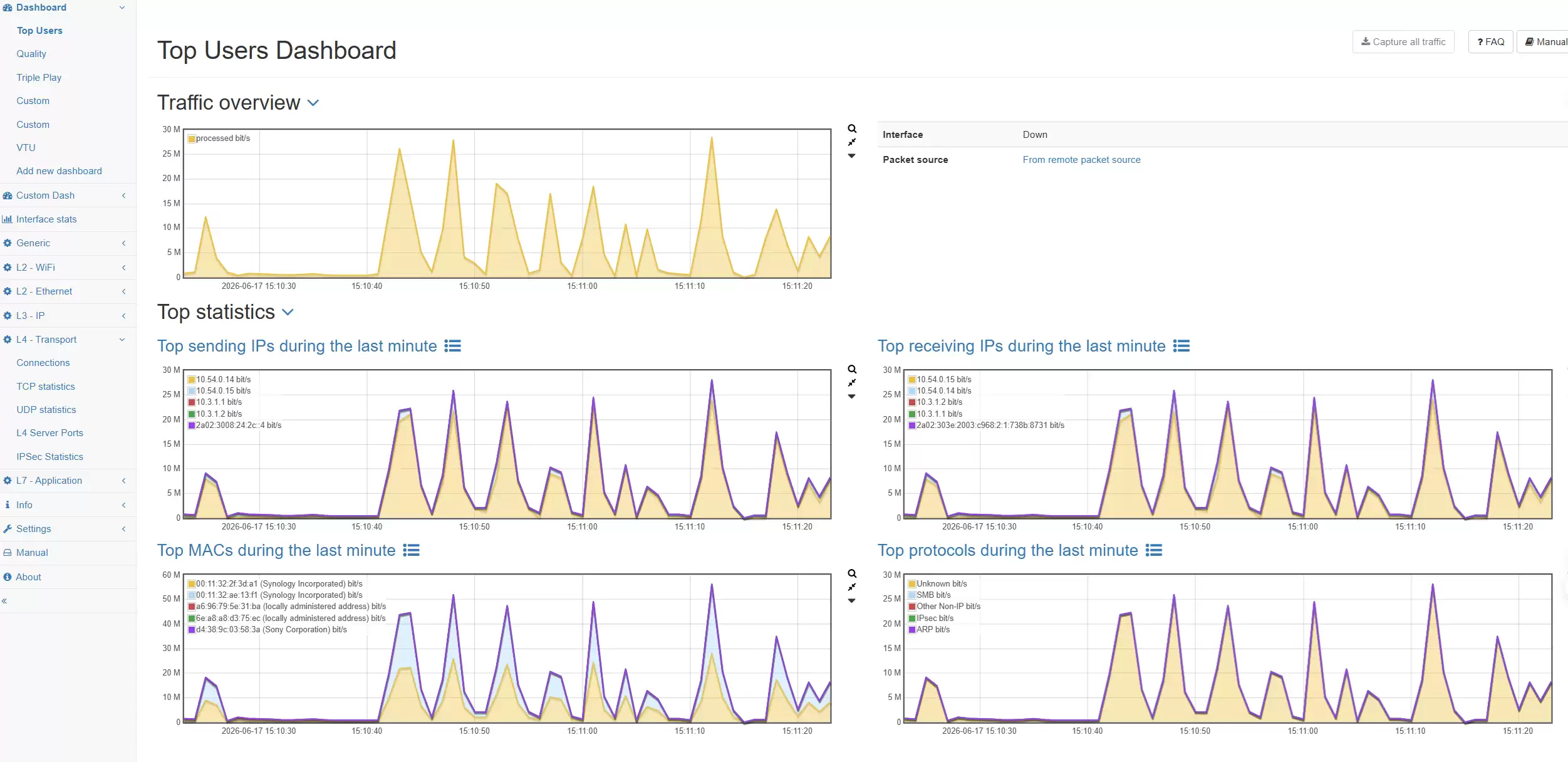
从“事后救火”到“有依据的网络诊断”
许多企业的AI项目上线后,频繁遭遇类似困扰:模型平台偶尔响应缓慢,但应用日志中并无明显报错;训练任务耗时越来越长,GPU和存储的监控数据却无法给出明确结论;数据同步任务时好时坏,业务团队怀疑网络有问题,网络团队却拿不出具体证据;部分用户访问AI服务体验不佳,可问题却无法稳定复现。
这些问题的共同点在于:现象暴露在业务层,而根因却可能隐藏在网络层。如果没有网络侧的细粒度观测,故障排除就变成了跨团队之间反复的猜测和推诿。
Allegro网络万用表的意义,就在于提供了网络侧的客观事实依据。它能帮助团队快速回答几个关键问题:当前到底是谁在占用带宽?流量构成是怎样的?哪些连接存在质量异常?是否存在TCP重传、延迟抖动或会话异常?DNS、DHCP、HTTP等关键协议有无异常行为?问题发生的时间窗口内,网络究竟发生了什么?能否基于历史数据回溯出故障现场?
一旦这些问题能够被迅速回答,AI平台的故障定位效率就会大幅提升。对企业而言,这不仅体现了网络运维工具的价值,更是构建AI基础设施稳定运行能力的基石。
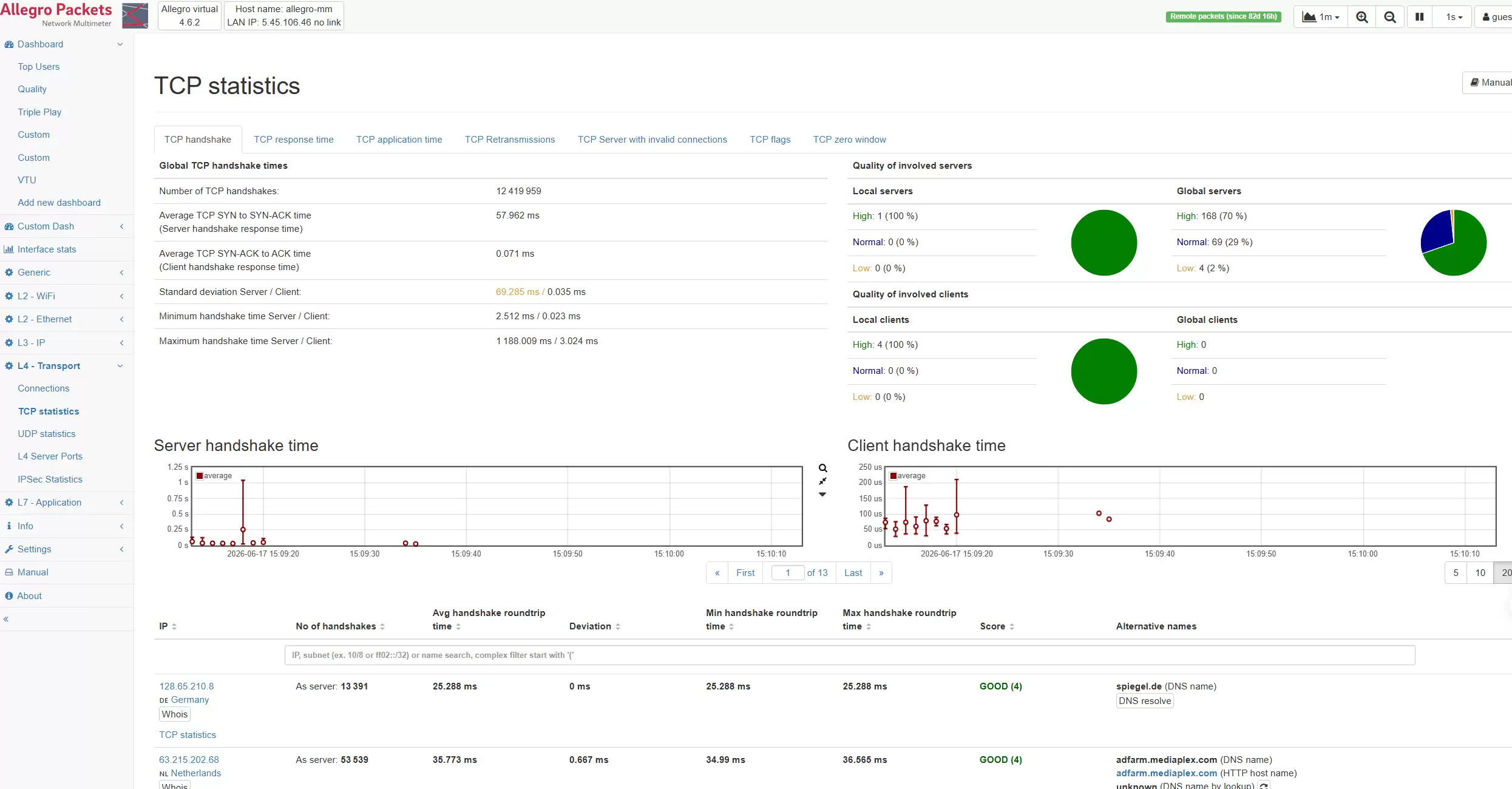
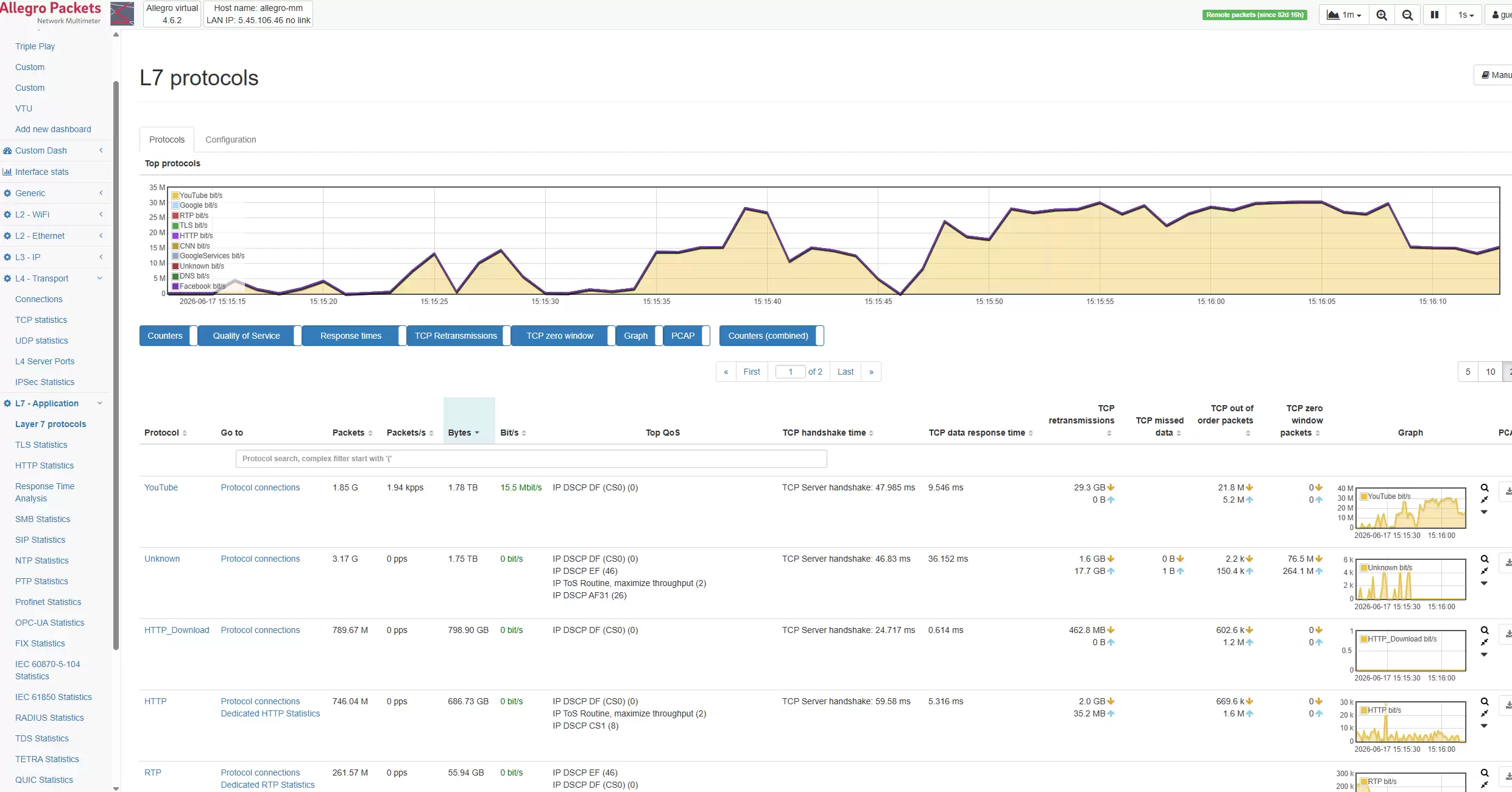
典型应用场景
场景一:AI训练集群网络瓶颈定位
在分布式训练中,任务涉及多个计算节点、共享存储和调度系统。只要部分节点出现等待,整体效率就会下降。运维团队需要判断:是GPU资源不足?数据读取速度太慢?存储系统卡顿?网络出现拥塞?还是某种类型的流量占用了关键链路?Allegro网络万用表能够从网络侧提供可视化分析,帮助用户在第一时间发现异常的通信对象、高流量传输、重传连接以及性能瓶颈,快速锁定排查方向。
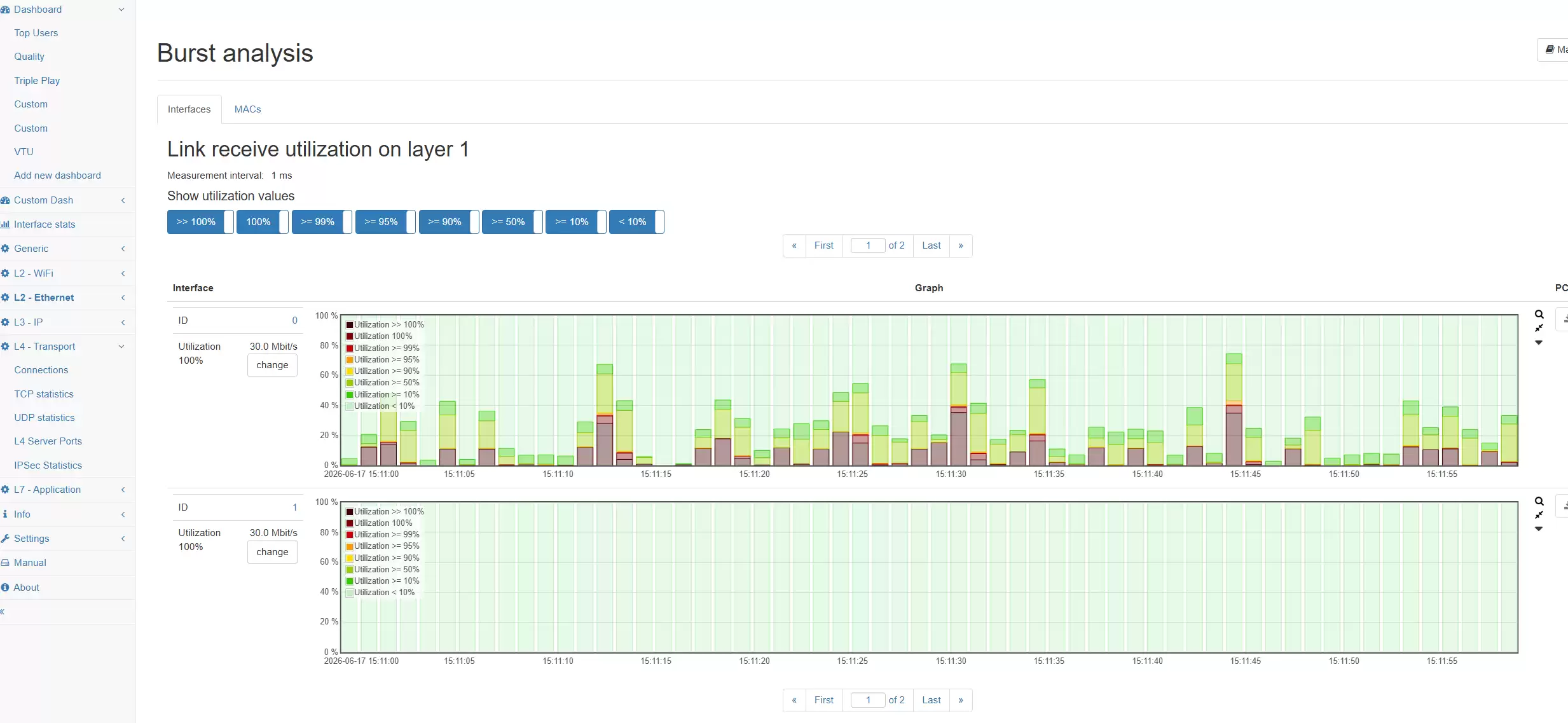
场景二:AI推理服务响应慢排查
AI推理直接面向用户,影响使用体验。一次问答、一张图片生成、一次语音识别或一个检索增强生成请求,背后可能牵扯多个服务组件。当用户反馈“响应慢”时,根因可能存在于入口网络、API网关、模型服务、数据库、向量检索、缓存或外部接口中。Allegro网络万用表能从网络视角观察服务调用链路中的连接质量和流量状态,帮助用户定位访问路径异常、协议异常、连接重传或局部链路拥塞,这对保障服务可用性至关重要。
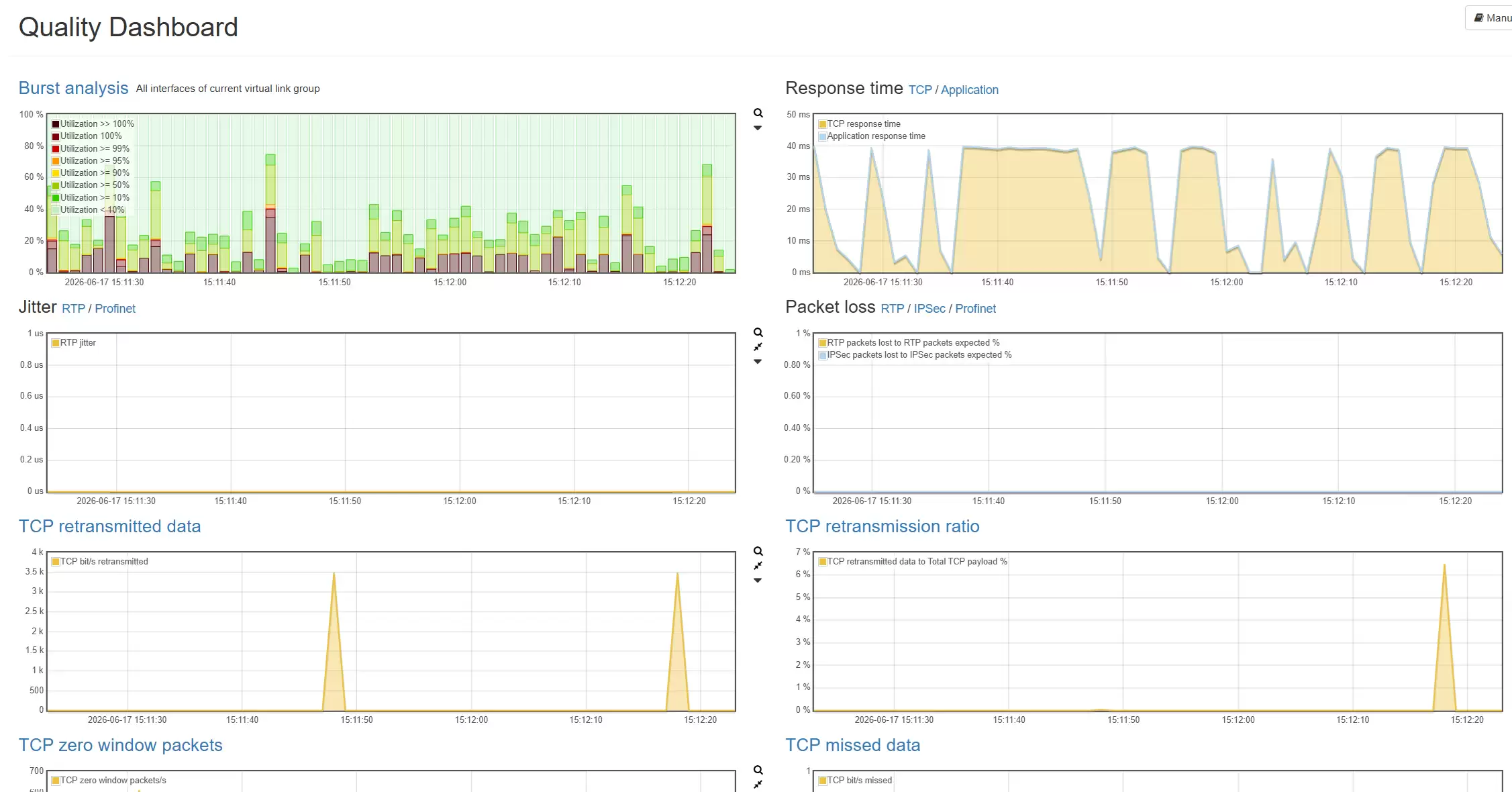
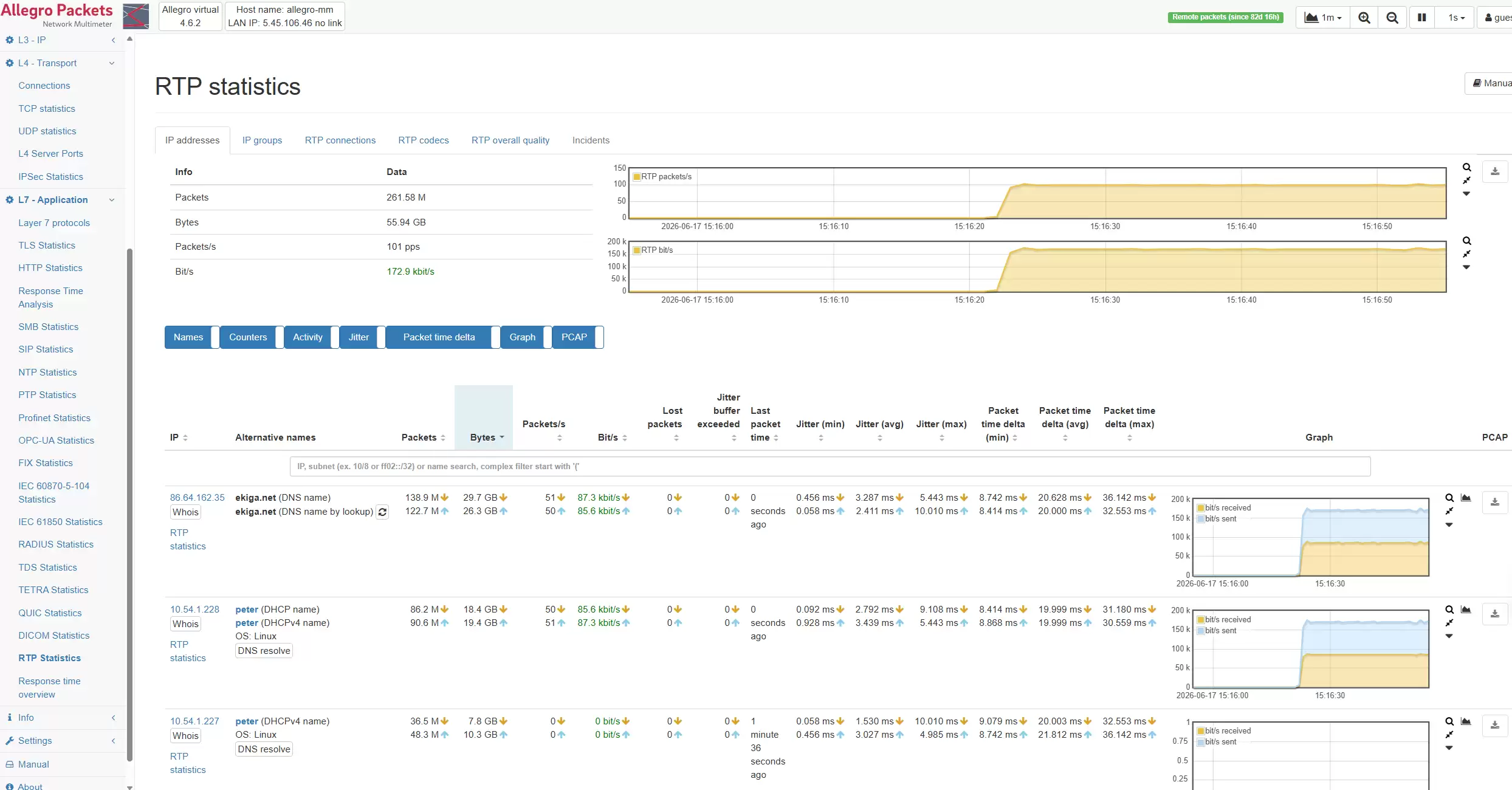
场景三:AI数据传输与存储访问分析
数据是AI项目的基础。训练数据、测试数据、标注数据、模型文件、日志、向量数据都需要在不同系统之间频繁传输。如果网络传输效率不稳定,数据准备就会受影响,模型训练和迭代的节奏也会随之变慢。尤其是当数据湖、对象存储、NAS、分布式文件系统与训练平台之间出现性能下降时,问题常被误判为存储能力不足。Allegro网络万用表可监测传输过程中的网络流量、连接对象、带宽占用和异常行为,帮助用户准确判断瓶颈是否在网络层,并为后续优化和容量规划提供依据。
场景四:边缘AI网络质量验证
边缘AI部署在工业现场、园区、医院、交通、能源、安防等环境中,对实时性和稳定性要求极高,但现场网络条件往往十分复杂。例如,工业视觉检测需要摄像头、边缘节点和后端平台之间稳定传输图像或视频;医疗影像AI分析需保障影像数据的传输质量;园区视频分析要处理大量视频流。Allegro网络万用表可用于现场网络质量验证和异常排查,在系统上线前后识别链路问题,避免将网络的不稳定性误判为算法或平台的缺陷。
AI时代,网络可观测性正成为基础设施的基础能力
企业在建设AI能力时,不能只盯着模型参数、GPU数量和算法精度。进入生产环境后,AI系统能否稳定、高效、可持续地运行,很大程度上取决于底层基础设施的可控性。网络作为连接算力、存储、数据和应用的“大动脉”,一旦不可见,AI平台就很难实现真正的可控。
Allegro网络万用表面向AI基础设施的核心价值,并非替代AI平台,也不是直接优化模型算法,而是为AI平台提供网络层的可视化、诊断与故障定位能力。它帮助企业看清AI业务背后的网络实况,快速识别性能瓶颈,降低跨团队排障成本,为AI应用的稳定运行提供坚实支撑。
在AI应用加速落地的当下,算力决定了性能的上限,而网络则决定了运行的稳定性。对于正在建设或运营AI平台的企业来说,网络性能可视化与故障定位,已不再仅是传统IT运维的附属能力,而是AI基础设施建设中不可忽视的关键环节。




