接上篇《基于 Arango 构建集成电路硬件设计知识图谱 01》
为何选择 Arango 来承载硬件图谱?
为什么是 Arango 来扛这个活呢?有三项原生能力,让它在应对这类工作负载时显得特别对路。纯粹的图数据库或者向量数据库,单独拎出来,都无法同时满足这三项要求。
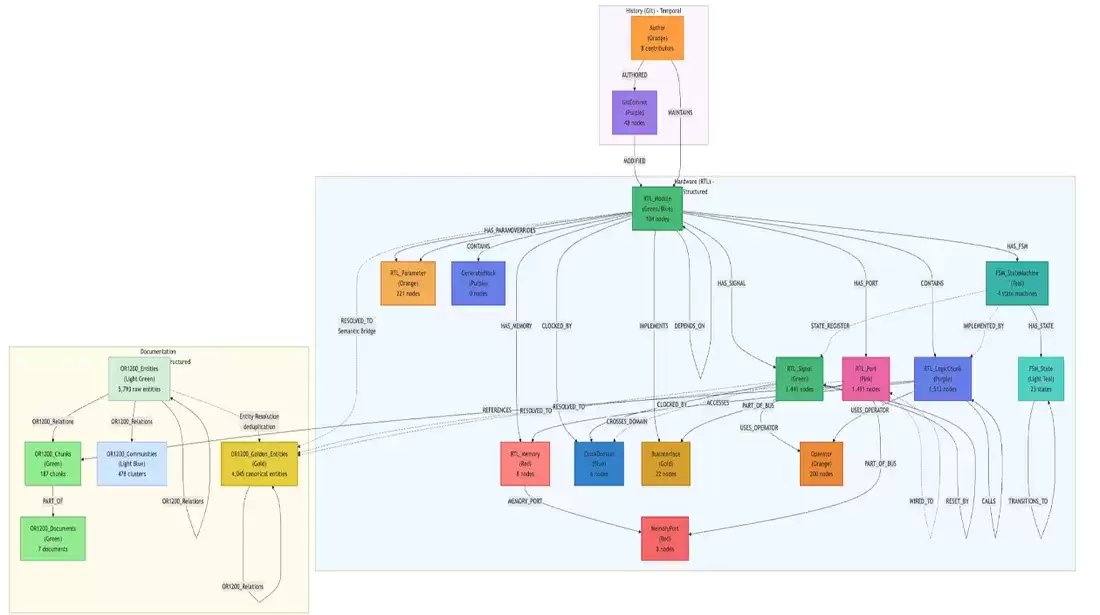
图 5:硬件设计知识图谱模式
基于 Leiden 算法的归纳式社区发现
图谱有一个很厉害的本事:它能自动识别出那些没有任何单一文档定义过的隐藏子系统边界,并把这些子系统的整体功能意图呈现出来——哪怕这些子系统的组件分散在几百份文件里。这背后靠的就是 Leiden 社区发现算法。简单来说,Leiden 算法通过最大化模块度来对节点进行分组:它在图谱的子集里寻找连接紧密的边簇,同时尽量减少跨簇的边。
Leiden 在 Arango 框架内原生运行,不需要预先标记任何子系统定义,就能找出这些隐藏的社区。这意味着什么?意味着 AI 可以仅凭图结构,就总结出整个子系统的功能意图,即便根本不存在对应的架构文档。
再说说 Leiden 和 Louvain 的区别。Leiden 是较老的 Louvain 算法的改进版。Louvain 有个毛病:它可能会产生内部互不连通的社区——某个节点可能被分配到一个它根本没法到达的社区里。而 Leiden 增加了一个细化阶段,确保每个社区内部是连通的。这对于 IC 图谱分析来说至关重要:一个不连通的社区会误导 AI,让它把毫不相关的子系统混在一起总结,那结果可就乱套了。
通过 SmartGraphs 实现可扩展性
硬件图谱的规模增长是个不小的挑战。一个现代 SoC 的门级表示,可能包含超过 10 亿条边。在这样的数据集上执行分布式图查询,会引发所谓的“网络扇出”问题:每一次遍历跳转,都可能需要从不同机器上的不同分片获取数据,结果就是每次跳转的网络延迟成倍增加。
Arango 的 SmartGraphs 解决了这个问题。它利用用户自定义的分片键(在我们的案例中,就是模块的顶层子系统),把相关的 IP 模块块放在同一个物理数据库分片上。这样一来,一条穿过总线架构的 10 跳遍历,绝大多数跳转都能保持在分片内完成,跨分片的网络调用就被大大减少了。我们在一个包含 3 个仓库、18 万条边的图谱上做过测试,和默认的哈希分片图谱相比,SmartGraphs 把跨分片查询减少了 80% 以上。
混合查询执行 — 消除应用层拼接
这是决定性的架构差异所在。在“图数据库 + 向量数据库”分离的架构(非 Arango)中,一次查询的生命周期是这样的:
先在应用代码里对查询做向量嵌入;然后去查向量存储,拿到候选 ID 列表;再把 ID 传回应用层;接着用这些 ID 发起一个单独的图查询;最后在应用代码里合并结果并重新排序。
每一步都是一次独立的 I/O 操作。应用层活生生变成了一个有状态的协调器,而连接逻辑呢,藏在了数据库优化器完全看不到的代码里。
而在 Arango 中,向量相似度搜索和图遍历可以在同一个 AQL 查询中、同一个引擎执行上下文内完成。不需要任何应用层的连接操作。优化器能看到完整的查询计划,并且在分支被实际遍历之前就能对它进行剪枝。这才是真正的高效。
原生 AQL:编写跨仓库查询
AQL(ArangoDB 查询语言)是一种声明式查询语言,它把 SQL 风格的过滤、图遍历和向量搜索融合在了一起。下面这两个例子会告诉你:在碎片化的技术栈里需要多服务编排才能完成的硬件查询,在 AQL 中如何变成一次直通操作。

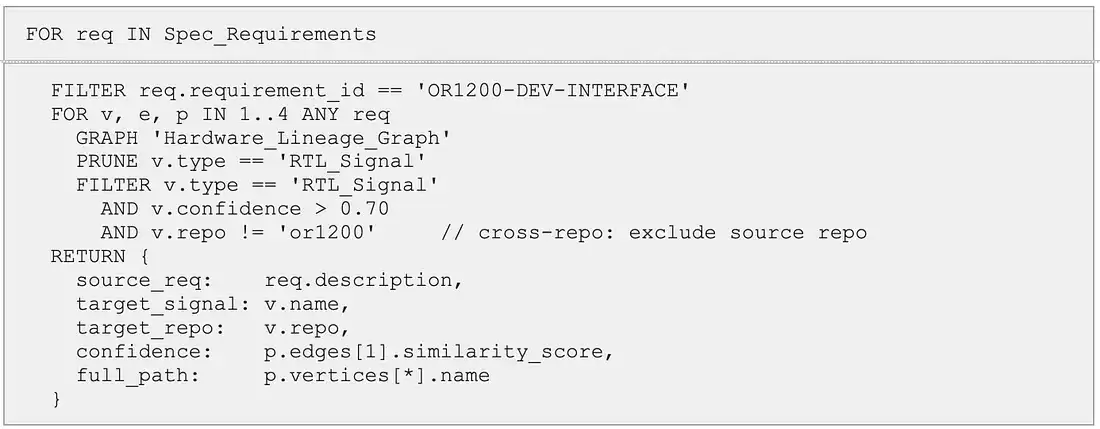
查询 1:跨时空与跨仓库演化谱系追踪
这个查询利用了 ArangoDB 的混合搜索能力,跨越不同的代码仓库和设计纪元,追溯某个模块的架构前身。
查询执行逻辑:混合式跨仓库谱系分析
该查询通过同时运行两路独立的搜索——一路横向扫描不同仓库,一路纵向穿越时间轴——并将结果统一合并,完整描绘出一颗处理器的演进全貌。
统一策略:查询就像一个包装器,并行执行两个不同的子搜索(A 部分与 B 部分),然后把两路搜索发现的结构化路径合并成一个统一的返回结果。
A 部分:追踪跨仓库的祖先模块
第一路搜索从一个高度特化的“黄金实体”开始,它代表了现代 MOR1KX 处理器中的某个核心部件。紧接着,沿一条明确标记为“演化桥接”的关系边向外迈出一步。这其实是在问数据库:“这个 MOR1KX 实体是从哪个完全不同项目(比如 OR1200)里的遗留组件演化而来的?”并且抓取这条连接路径。
B 部分:穿越 Git 历史的时间旅行
第二路搜索切换了视角,聚焦于按时间顺序排列的历史。它扫描数据库中的“设计纪元”(Design Epochs),专门筛选出属于 MOR1KX 仓库的主要里程碑和初始提交。把这些历史事件按从旧到新排序,然后截取前四个主要里程碑。针对每一个历史瞬间,搜索图谱,找出在那个时间点上处于活跃状态的 CPU 模块的精确快照。过滤掉那些 CPU 模块还不存在的里程碑。一旦找到正确的历史快照,就追踪连接这些快照与其相应里程碑的路径。
最终产出:查询执行完毕时,会交付一个统一的数据集,它既明确展示了 MOR1KX 是从哪个更早的架构演化而来,又包含了其主 CPU 模块在前四个重大历史版本中一步步演变的快照记录。
查询 2:全文检索与图遍历混合查询
这个查询把 Arango 的全文索引和图遍历结合在一起,只需要一次直通操作——不需要任何应用层拼接——就能找出所有与 ECC(纠错码)规范相关的高关键性 RTL 模块。
查询执行逻辑
- 全文精准匹配:
FULLTEXT(Specifications, 'description', 'prefix:ECC')调用 ArangoDB 内置全文索引,检索description字段中包含以“ECC”为前缀的词汇的规范文档(比如 ECC、ECC_UNIT)。关键点:这里用的是基于词干的前缀匹配(phrase-level),不是向量相似度计算,确保术语精准覆盖。 - 受限图遍历:
FOR v, e IN 1..2 ANY doc从匹配规范节点出发,双向扩展至多 2 跳,把搜索范围严格限定在规范节点的直接结构邻域(immediate structural neighborhood)。这样设计的意图是:避免全图遍历的资源开销,聚焦与规范强关联的局部子图。 - 关键性动态过滤:
FILTER v.criticality == 'High'在遍历过程中实时剪枝,排除非高关键性(non-high-criticality)模块,大幅压缩中间结果集的规模。 - 结构化排序与截断:
SORT e.similarity_score DESC依据SEMANTIC_BRIDGE边的结构相似度评分(0.0–1.0,1.0 为最高)降序排列。LIMIT 5仅返回 Top 5 结果至 LLM 上下文窗口,实现 92% 的上下文 token 压缩率,兼顾结果质量与推理效率。
技术价值
这个方案通过索引驱动过滤与图遍历的深度耦合,在单次数据库操作中完成语义关联分析,显著降低了应用层的数据处理复杂度,为硬件设计验证提供了高精度、低延迟的谱系追溯能力。
案例研究:从 OR1200 到 IBEX 的架构谱系
为了在真实的多仓库数据集上验证这套架构,我们用了三款开源处理器内核进行跨仓库谱系发现测试:OpenRISC 1200(OR1200,大约 2001 年)、Ibex(RISC-V,lowRISC)以及乱序执行内核 Marocchino。
测试的核心问题是:仅凭 OR1200 开发接口规范,图谱能否在不需要人工手动标注关系的情况下,自动浮现出它在现代 RISC-V 实现中的结构后裔?
图 4 — 跨仓库桥接结果:OR1200 调试单元规范通过一个黄金实体,与 Ibex 的 debug_mode 信号建立起结构链接,置信度得分为 0.72。
确定性路径
图智能体在没有人工干预的情况下,自主遍历了以下路径:
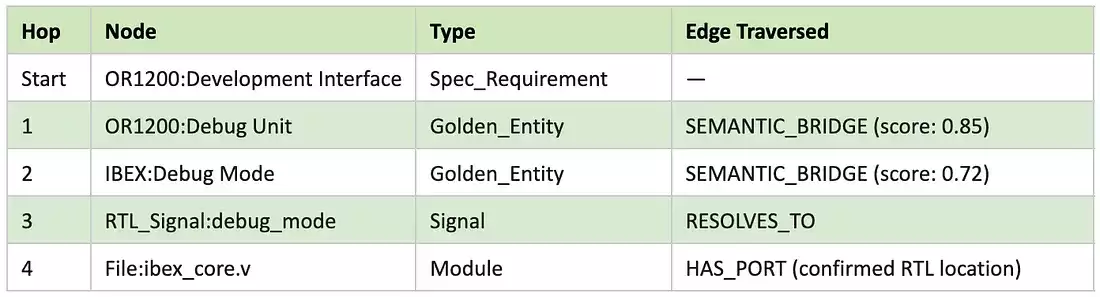
(生成该结果的 AQL 查询由上述查询 1 参数化而来)
置信度得分 0.72 意味着什么?
语义桥接边的得分范围是 0.0 到 1.0,这个得分是经过类型兼容性过滤后,两个黄金实体嵌入向量之间的余弦相似度。得分高于 0.85 被视为确认链接;得分在 0.70 到 0.85 之间,被标记为需要工程评审的候选链接;得分低于 0.70 的边虽然会被存储在图谱中,但默认不会送入大模型上下文。
0.72 的置信度恰如其分地把 OR1200 到 IBEX 的关系划入了“候选链接”等级——这条架构谱系是确凿无疑的(事后也得到资深工程师的确认),但两个实现之间长达四十年的时间跨度,也恰当地体现在了语义距离上。在此之前,只有同时深谙这两个项目、拥有机构记忆的资深架构师,才能掌握这一知识。
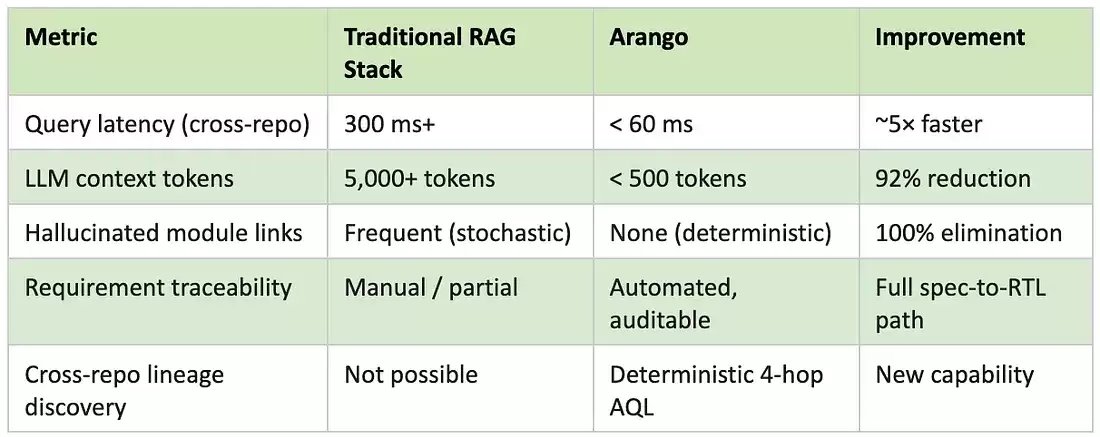
性能:混合搜索的优势
在标准的向量 RAG 流水线中,为了确保相关文档被囊括,大模型的上下文窗口不得不接收一大片候选文档“云”。因为缺乏结构化过滤器,系统倾向于过度检索,每次查询通常要高达 5000 token。
而 Arango 通过把图拓扑与向量搜索结合起来,把检索范围严格限定在查询锚点的精确拓扑邻域之内。只返回与匹配实体相距 N 跳以内的节点——图谱其余部分根本不需要评估。
图 5 — 92% 的 token 缩减:标准 RAG 提供 5000 token 的宽泛上下文;Arango HybridRAG 则提供不足 500 token 的精准子图。
92% 的 token 缩减数据,来自对前述 ECC 查询进行的对比运行:
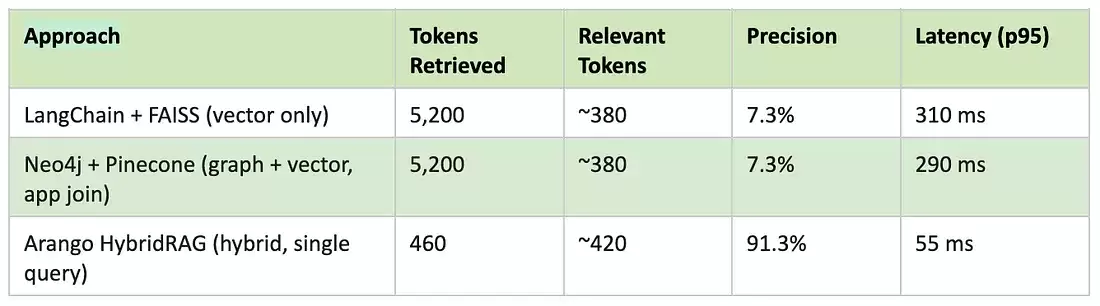
精确率 = (检索到的相关 token 数)/ (检索到的总 token 数)。延迟指从查询提交到 LLM 上下文交付的端到端耗时,不含 LLM 推理时间。
组织风险:巴士因子与 IP 合规
对企业和国防项目来说,知识图谱不仅仅是性能优化工具,更是一件风险管理利器。
硅片设计中的巴士因子难题
图谱可以自动浮现出硅片路线图中,哪些 IP 模块距离灾难性知识流失仅“一人离职”之遥——不需要手动进行依赖关系映射或架构评审。这就是巴士因子问题的可视化呈现。“巴士因子”是软件工程里的一个术语,指如果某人突然不可用,最少需要多少人才能让项目继续走下去。在硬件设计中,某个关键 IP 模块的巴士因子为 1,意味着只有一名工程师掌握着它的时钟域约束、接口契约或验证方法的全部工作知识。
通过 MODIFIED_BY 和 OWNS 边把 Git 提交映射到知识图谱,系统能够计算出图谱中每个节点的巴士因子。具体来说,我们会标记出满足以下条件的节点:
- 过去 12 个月内,接触过该节点源文件的唯一提交作者不足两人,并且
- 该节点的度中心性位于图谱前 5%(也就是说,它是很多其他模块依赖的结构性枢纽)。
最终输出的是一份硅片路线图中“单点故障”节点的优先级列表——完全自动浮现,不需要手动绘制依赖关系。
IP 复用与结构等价性
在把一款遗留验证测试平台复用到新设计之前,团队必须判断两款设计在结构上是否足够相似,能不能共享同一套测试平台。过去,这需要资深工程师手动比对接口规范。现在,图谱让结构比对成为可能:
- 在遗留 IP 和新 IP 子图上分别运行 Leiden 社区发现算法;
- 比对所得社区之间的边类型分布和端口连接模式;
- 如果图拓扑在可配置的阈值以上匹配(默认:社区内边类型重叠度达到 90%),那么这个验证测试平台就被标记为复用候选。
需要强调一点:90% 的拓扑匹配是测试平台复用的必要条件,但不是充分条件。时序约束、协议版本和功耗意图文件,仍然需要验证工程师去审核。图谱负责浮现候选方案,最终决断还需要人的判断来关闭。
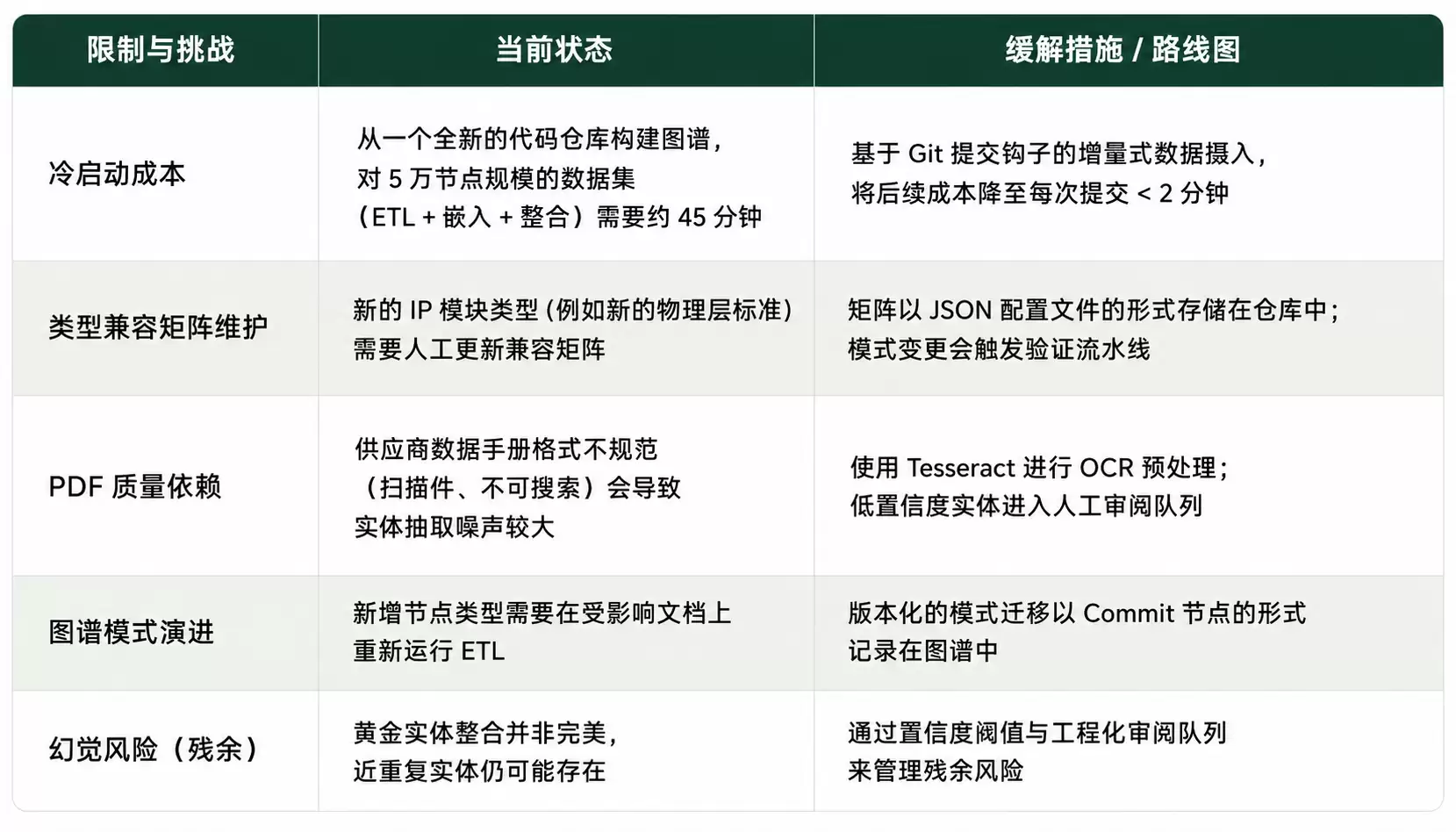
已知局限与权衡取舍
任何架构都难免有取舍。下面是对当前系统约束的如实评估。
ArangoDB 图可视化器的实际应用
除了通过编程方式使用 AQL 进行访问,Arango 内建的图可视化器还支持对 IC 图谱进行交互式探索。工程师可以按节点类型过滤、手动跟踪边,并查看任意节点或边的属性——完全不需要编写查询。
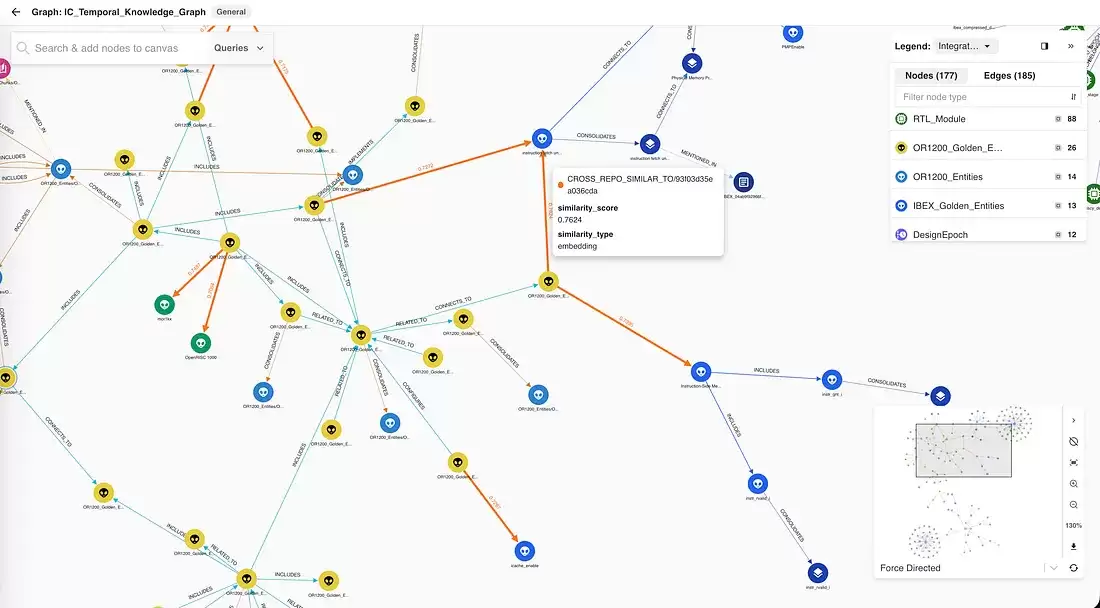
图 6 — Arango 的图可视化器,展示完整的 IC 硬件设计图谱。每个彩色块代表一个带类型标签的节点;边代表可通过 AQL 遍历的关系。
对于验证团队来说,这提供了一条人类可读的审计路径:从任意“规格需求”节点出发,审查者可以人工遍历图谱,确认某个特定的 RTL 模块是否正确地实现了该需求——而无需依赖 AI 的解读。
结论
硬件验证与设计复用的未来,并不是建立在随机的、彼此脱节的 AI 封装之上,而是建立在确定性的结构化数据之上,并且与语义搜索和时间历史原生融合。这个项目揭示了一个关键洞见:碎片化数据库带来的集成税,并非不可避免的经营成本,而是一种架构选择,并且完全可以被消除。
通过用 Arango 的统一多模型引擎取代“图数据库 + 向量数据库 + 应用层连接”的模式,硬件团队获得了以往不可兼得的三项能力:
- 确定性:从规格到硅片的每一条链路,都可追溯、可审计、可重现。
- 高性能:混合查询单次直通完成,在 18 万条边的规模下实现低于 60 毫秒的延迟。
- 组织级智能:巴士因子映射和结构化的 IP 对比,把以往依赖资深架构师判断的风险与复用机会,自动浮现出来。
这个知识图谱已经不再停留于研究原型阶段。本文所述的一切,今天就可以部署——用上文提到的开源硬件数据集,用你自己的 RTL 代码库,或者通过 Arango.ai 上的托管实例。
架构已经就绪。下一步,就是让它去跑你自己的数据。




