财务月末对账、电商订单汇总、行政考勤统计、销售数据透视——这些日常场景,每天都在消耗大量人力在Excel里反复进行同样的操作。手动处理不仅效率低下,还极易出错:数字莫名其妙变成科学计数法、单元格定位偏移、大文件一打开就卡死、WPS和Office之间格式不兼容……
更棘手的是,很多企业(尤其是金融、政务、军工)的数据根本不能出本地。常规的云端自动化工具在这种环境里完全使不上劲,内网离线的Excel自动化方案成了刚需。
这篇文章基于实际项目经验,从六个维度拆解Excel自动化的技术实现,覆盖从开发到交付的完整链路。话不多说,直接上干货。
一、揭秘Excel自动化为何成为企业刚需
上述场景只是冰山一角。你会发现,凡是重复、规则明确、容错率低的操作,Excel自动化都能派上大用场。关键是,它还能把人的精力解放出来去做分析决策。
二、六大核心场景与解决方案
2.1 数据写入:精准定位单元格,避免覆盖错位
典型问题:用程序往Excel里写数据时,经常写到错误的单元格,或者把已有的内容给覆盖了。
根因分析:大多数失败都出在坐标计算逻辑上。比如用openpyxl的时候,行号是从1开始计数的,但很多人习惯性地按0起始处理,一下子全乱了。
解决方案:
from openpyxl import load_workbook
def safe_write_excel(file_path, sheet_name, row, col, value):
"""
安全写入 Excel,自动处理行列边界
row: 行号(从1开始)
col: 列号(从1开始)或列名如 'A', 'B'
"""
wb = load_workbook(file_path)
ws = wb[sheet_name]
# 统一处理列号
if isinstance(col, str):
col_idx = openpyxl.utils.column_index_from_string(col)
else:
col_idx = col
# 边界检查:如果目标行不存在,自动扩展
max_row = ws.max_row
if row > max_row:
for _ in range(row - max_row):
ws.append([])
ws.cell(row=row, column=col_idx, value=value)
wb.sa ve(file_path)
return True
使用示例:在第5行B列写入订单金额
safe_write_excel("report.xlsx", "Sheet1", 5, "B", 12800.50)
关键技巧:写入前先做边界检查,避免IndexError。对于批量写入,建议先构造二维数组,再用append()一次性写入——比逐单元格写入快10倍以上。
2.2 格式错乱修复:数字变科学计数法、日期显示异常
典型问题:
- 长数字(如订单号20250622001)写入后变成2.02506E+10
- 日期写入后显示为整数(如45000)
- 货币格式丢失,小数位不统一
解决方案:
from openpyxl.styles import numbers
def format_cell(ws, row, col, value, cell_type='text'):
"""
按类型写入并设置格式
cell_type: text / number / date / currency / percentage
"""
cell = ws.cell(row=row, column=col)
cell.value = value
if cell_type == 'text':
cell.number_format = '@' # 强制文本格式,防止科学计数法
elif cell_type == 'number':
cell.number_format = '0.00'
elif cell_type == 'date':
cell.number_format = 'YYYY-MM-DD'
elif cell_type == 'currency':
cell.number_format = '¥#,##0.00'
elif cell_type == 'percentage':
cell.number_format = '0.00%'
return cell
使用示例:写入订单号(强制文本,防科学计数法)
format_cell(ws, 2, 1, "202506220011234", 'text')
format_cell(ws, 2, 3, 15800.50, 'currency')
format_cell(ws, 2, 4, "2026-06-22", 'date')
核心原则:写入长数字前,务必设置单元格格式为@(文本),这是防止科学计数法最可靠的方式。日期写入时,如果是字符串,先转换为datetime对象再写入,格式才会正确识别。
2.3 大数据处理:万行级 Excel 不卡顿的读写策略
典型问题:超过5万行的Excel文件,用openpyxl打开内存占用飙升,保存一次要等几分钟。
根因分析:openpyxl是DOM式解析,整个文件加载到内存。对于大文件,需要换用流式读写方案。
解决方案:
方案A:读取大数据用 read_only 模式
from openpyxl import load_workbook
def read_large_excel(file_path):
"""流式读取,内存占用极低"""
wb = load_workbook(file_path, read_only=True, data_only=True)
ws = wb.active
for row in ws.iter_rows(min_row=2, values_only=True):
# 逐行处理,不加载全部数据
order_id, amount, date = row[0], row[1], row[2]
process_row(order_id, amount, date)
wb.close()
方案B:写入大数据用 write_only 模式
from openpyxl import Workbook
def write_large_excel(output_path, data_generator):
"""流式写入,适合万行级数据"""
wb = Workbook(write_only=True)
ws = wb.create_sheet("订单汇总")
# 写入表头
ws.append(["订单ID", "金额", "日期", "状态"])
# 逐行写入,内存友好
for record in data_generator:
ws.append([
str(record['id']), # 强制文本
record['amount'],
record['date'].strftime('%Y-%m-%d'),
record['status']
])
wb.sa ve(output_path)
方案C:超过10万行,改用 pandas + xlsxwriter
import pandas as pd
def export_with_pandas(df, output_path):
"""pandas 大数据导出,自动优化"""
with pd.ExcelWriter(output_path, engine='xlsxwriter') as writer:
df.to_excel(writer, sheet_name='数据', index=False)
# 获取 workbook 和 worksheet 对象
workbook = writer.book
worksheet = writer.sheets['数据']
# 设置列宽自适应
for i, col in enumerate(df.columns):
max_len = max(df[col].astype(str).map(len).max(), len(col)) + 2
worksheet.set_column(i, i, max_len)
性能对比:
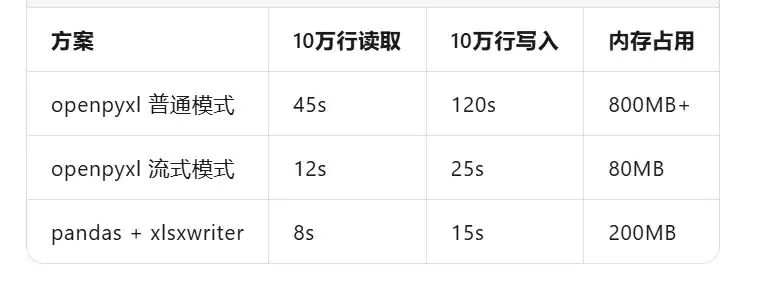
建议:5万行以下用openpyxl,5-20万行用流式模式,20万行以上直接用pandas+xlsxwriter或者导出CSV再转Excel。
2.4 WPS 兼容:国产办公环境下的格式适配
典型问题:用Office生成的Excel,在WPS打开时格式错位、公式失效、宏无法运行。
根因分析:WPS对Office的兼容性总体不错,但在以下场景有差异:
- 条件格式(尤其是数据条、色阶)
- 部分高级函数(如LET、LAMBDA)
- VBA宏(WPS需专业版才支持)
解决方案:
生成 WPS 兼容的 Excel 时,避免使用高级特性
def create_wps_compatible_excel(output_path, data):
from openpyxl import Workbook
from openpyxl.styles import Font, PatternFill, Alignment, Border, Side
wb = Workbook()
ws = wb.active
ws.title = "数据报表"
# 表头样式(WPS 完全兼容的基础样式)
header_font = Font(name='微软雅黑', size=11, bold=True, color='FFFFFF')
header_fill = PatternFill(start_color='4472C4', end_color='4472C4', fill_type='solid')
header_align = Alignment(horizontal='center', vertical='center')
thin_border = Border(left=Side(style='thin'),
right=Side(style='thin'),
top=Side(style='thin'),
bottom=Side(style='thin'))
# 写入表头
headers = ["订单号", "客户", "金额", "日期"]
for col, header in enumerate(headers, 1):
cell = ws.cell(row=1, column=col, value=header)
cell.font = header_font
cell.fill = header_fill
cell.alignment = header_align
cell.border = thin_border
# 写入数据
for row_idx, record in enumerate(data, 2):
ws.cell(row=row_idx, column=1, value=str(record['order_id']))
ws.cell(row=row_idx, column=2, value=record['customer'])
ws.cell(row=row_idx, column=3, value=record['amount'])
ws.cell(row=row_idx, column=4, value=record['date'])
# 数据行也加边框
for col in range(1, 5):
ws.cell(row=row_idx, column=col).border = thin_border
# 设置列宽
ws.column_dimensions['A'].width = 20
ws.column_dimensions['B'].width = 15
ws.column_dimensions['C'].width = 12
ws.column_dimensions['D'].width = 15
# 冻结首行(WPS 完全支持)
ws.freeze_panes = 'A2'
wb.sa ve(output_path)
print(f"WPS 兼容文件已生成:{output_path}")
WPS 兼容 checklist:
- ✅ 使用基础字体(微软雅黑、宋体、Arial)
- ✅ 避免使用 Office 365 专属函数
- ✅ 条件格式用纯色填充替代渐变
- ✅ 不依赖 VBA 宏(改用 脚本)
- ✅ 文件后缀统一用 .xlsx(WPS 对 .xls 兼容性更好,但 .xlsx 也正常)
2.5 日期函数:跨系统日期格式统一处理
典型问题:不同系统导出的日期格式五花八门——2026/06/22、22-06-2026、20260622、Jun 22, 2026,统一处理时经常报错。
解决方案:
from datetime import datetime, timedelta
import re
def parse_any_date(date_str):
"""
智能解析各种日期格式
支持:YYYY-MM-DD, YYYY/MM/DD, DD-MM-YYYY, YYYYMMDD, 中文日期等
"""
if date_str is None or date_str == '':
return None
# 已经是 datetime 对象
if isinstance(date_str, datetime):
return date_str
date_str = str(date_str).strip()
# 尝试多种格式
patterns = [
('%Y-%m-%d', r'^\d{4}-\d{2}-\d{2}$'),
('%Y/%m/%d', r'^\d{4}/\d{2}/\d{2}$'),
('%d-%m-%Y', r'^\d{2}-\d{2}-\d{4}$'),
('%Y%m%d', r'^\d{8}$'),
('%m/%d/%Y', r'^\d{2}/\d{2}/\d{4}$'),
]
for fmt, pattern in patterns:
if re.match(pattern, date_str):
try:
return datetime.strptime(date_str, fmt)
except ValueError:
continue
# 处理中文日期:2026年06月22日
cn_pattern = r'(\d{4})年(\d{1,2})月(\d{1,2})日'
match = re.match(cn_pattern, date_str)
if match:
year, month, day = map(int, match.groups())
return datetime(year, month, day)
# 处理 Excel 序列号(如 45000)
try:
excel_num = float(date_str)
if 30000 < excel_num < 60000: # Excel 日期序列号范围
return datetime(1899, 12, 30) + timedelta(days=int(excel_num))
except ValueError:
pass
raise ValueError(f"无法解析日期格式:{date_str}")
# 使用示例
dates = ["2026-06-22", "2026/06/22", "22-06-2026", "20260622", "2026年06月22日"]
for d in dates:
print(f"{d} -> {parse_any_date(d)}")
日期处理黄金法则:
- 读取时统一转换为datetime对象
- 写入时统一格式化为YYYY-MM-DD
- 跨系统对接时,用ISO 8601标准格式(YYYY-MM-DDTHH:MM:SS)
2.6 批量报表生成:从模板到多文件自动化输出
典型问题:每月要生成几十份格式一致的报表(如各部门月度汇总、各区域销售报表),手动复制模板、改数据、另存为,重复且易错。
解决方案:
import os
from openpyxl import load_workbook
def batch_generate_reports(template_path, data_list, output_dir):
"""
基于模板批量生成报表
data_list: [{'dept': '销售部', 'month': '2026-06', 'total': 150000, ...}, ...]
"""
os.makedirs(output_dir, exist_ok=True)
for idx, data in enumerate(data_list):
# 加载模板
wb = load_workbook(template_path)
ws = wb.active
# 替换模板中的占位符
# 假设模板中单元格有类似 {{dept}} 的占位符
for row in ws.iter_rows():
for cell in row:
if cell.value and isinstance(cell.value, str):
# 简单替换
for key, val in data.items():
placeholder = f"{{{{{key}}}}}"
if placeholder in str(cell.value):
cell.value = str(cell.value).replace(placeholder, str(val))
# 动态填充数据区域(如明细表)
if 'details' in data:
start_row = 5 # 假设明细从第5行开始
for detail in data['details']:
ws.cell(row=start_row, column=1, value=detail['item'])
ws.cell(row=start_row, column=2, value=detail['qty'])
ws.cell(row=start_row, column=3, value=detail['price'])
ws.cell(row=start_row, column=4, value=detail['qty'] * detail['price'])
start_row += 1
# 保存
output_name = f"{data['dept']}_{data['month']}_报表.xlsx"
output_path = os.path.join(output_dir, output_name)
wb.sa ve(output_path)
print(f"已生成:{output_path}")
# 使用示例
report_data = [
{
'dept': '销售部',
'month': '2026-06',
'total': 158000,
'details': [
{'item': '产品A', 'qty': 100, 'price': 500},
{'item': '产品B', 'qty': 80, 'price': 800},
]
},
{
'dept': '市场部',
'month': '2026-06',
'total': 92000,
'details': [
{'item': '推广A', 'qty': 50, 'price': 1200},
{'item': '推广B', 'qty': 30, 'price': 900},
]
}
]
batch_generate_reports("template.xlsx", report_data, "./output_reports")
三、从脚本到交付:EXE 打包与内网离线部署
上述脚本在开发环境跑通了,但交付给业务人员时还有几个问题:
- 业务电脑没有 环境
- 脚本依赖的库需要逐个安装
- 代码裸露在外,容易被误改
解决方案:打包为独立 EXE
使用 PyInstaller 打包
pip install pyinstaller
打包命令:
pyinstaller --onefile --windowed excel_automation.py
进阶:用 RPA 工具的可视化流程 + 扩展
优势:
- 可视化编排降低维护成本
- 支持将流程打包为 EXE,业务人员双击运行
- 可自定义软件界面(Logo、标题、主题色)
- 支持授权控制(有效期、设备绑定、使用次数)
- 支持 API 触发和定时执行
- 数据全部本地存储,满足内网离线要求
内网离线部署 checklist:
- 部署包通过加密 U 盘或专用摆渡机传入内网
- License 本地验证,无需联网
- 运行日志本地存储,不上传第三方服务器
- 流程数据完全本地闭环
四、AI 增强:让 Excel 自动化更智能
2026 年的 Excel 自动化已经不止于规则引擎。结合大模型的 OCR 和意图理解能力,可以实现:
- 发片识别:扫描件/PDF 发片 → OCR 提取 → 自动填入 Excel
- 智能分类:非结构化文本(如邮件、聊天记录)→ 大模型解析 → 结构化写入 Excel
- 异常检测:自动识别数据中的异常值并标红提醒
实现方式:通过 HTTP API 调用本地或私有化部署的大模型服务,费用按实际调用量计费,比订阅制更透明可控。
五、RPA 工具选型:谁更适合 Excel 自动化交付
脚本适合开发阶段,但企业级交付往往需要更完整的工具链。目前市面上支持 Excel 自动化的 RPA 方案不少,选型时建议关注以下几点:
- EXE 打包能力:能否将流程打包为独立可执行文件,业务人员无需安装任何环境
- 授权控制:是否支持有效期、设备绑定、使用次数等授权机制
- API 触发:是否支持 HTTP 接口调用,方便对接内部系统
- 内网离线:数据是否完全本地存储,不依赖云端服务
- WPS 兼容:对国产办公环境的适配程度
- AI 集成:是否支持接入私有化大模型,实现 OCR 和智能识别
以某主流国产RPA工具为例,它在上述几个维度表现比较均衡:支持API触发、EXE打包、自定义界面、内网离线使用、授权控制、定时执行,且AI功能采用用户自行对接各平台API的方式,费用更可控。对于个人开发者、工作室和中小企业来说,这种按量付费、数据本地的模式,比订阅制更灵活。
当然,具体选型还是要看实际场景。如果是纯脚本级需求,Python足够;如果需要可视化维护、交付给非技术人员、或者涉及内网离线部署,RPA工具的EXE打包和授权能力会省心很多。
六、总结与选型建议
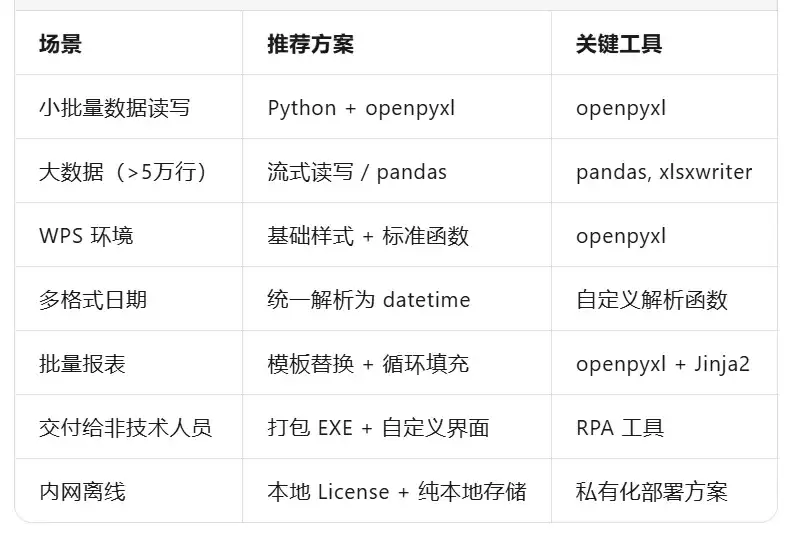
Excel 自动化的本质不是替代人工,而是把重复、规则明确、易出错的操作交给程序,让人专注于分析和决策。选对工具、写对代码、做好交付,才能真正让自动化产生价值。




