AI安全研究正处在技术早期阶段,这个领域充满未知,也充满挑战。为了帮助更多同行和有志于进入这个方向的新生代快速跟上最新技术动态,我们启动了一个全新的“顶会顶刊AI安全论文研读”系列。今天带来的是第五期:AAAI 2026 | PhysPatch:面向MLLM驱动自动驾驶系统的物理可实现对抗贴片框架。
第一期回顾:顶会顶刊AI安全论文研读第一期:ICCV 2025| 基于启发式诱导的多模态风险分解越狱攻击方法:突破MLLMs安全防线
第二期回顾:顶会顶刊AI安全论文研读第二期CVPR 2025 highlight分散即关键基于子图像对比分散策略多模态大模型越狱攻击研究
第三期回顾:顶会顶刊AI安全论文研读第三期:ICML 2025 | GuardAgent:让AI智能体“有守护者”的第一步
第四期回顾:顶会顶刊AI安全论文研读第四期:ICCV 2025 | 机器人的“视觉欺骗”:一个彩色补丁如何让智能机器人“精神错乱”
作者介绍
本文作者团队来自西安交通大学、南洋理工大学、东北大学、杭州电子科技大学、东南大学以及新加坡A*STAR前沿人工智能研究中心等机构。团队在多模态大语言模型(MLLM)安全性领域具有深厚研究积累,长期致力于AI安全、对抗鲁棒性的研究。本次工作PhysPatch,首次实现了针对 MLLM-驱动自动驾驶系统的可打印、可部署、可迁移的物理贴片攻击框架,揭示了多模态系统在真实世界感知-决策链路中的潜在安全隐患。
导读
近年来,多模态大语言模型(MLLMs)凭借强大的视觉–语言推理能力,正逐步融入自动驾驶系统,实现端到端的场景理解与决策规划。然而,这类模型的安全防护机制在现实世界中仍存在薄弱环节。传统的对抗攻击大多集中于像素级扰动或数字空间的贴片生成,虽然在封闭环境中有效,但一旦进入物理场景,其攻击能力与稳定性便显著下降。
本文提出了一种面向多模态自动驾驶系统的物理可实现对抗贴片框架——PhysPatch。与以往单纯追求“扰动强度”的方法不同,PhysPatch的核心思想是从语义层面对贴片进行优化,使其在物理世界中也能欺骗模型的视觉–语言对齐机制。
研究发现,攻击成功与否不仅取决于贴片本身的像素扰动,更取决于其语义位置、形状与对齐特性。基于此,PhysPatch 在优化中同时考虑贴片的语义合理性、特征对齐性与物理可行性,实现了高攻击性与高可部署性兼具的突破。
• 语义掩码初始化:利用MLLM 的推理能力自动选择语义上合理的贴片区域(如路标、车身表面),确保攻击点在真实场景中可实现。
• 局部特征对齐优化:基于奇异值分解(SVD)的局部对齐损失,使贴片在跨模型迁移时保持语义一致性。
• 自适应势场更新:在优化过程中动态调整贴片形状,让贴片自然融入场景而不失攻击性。
大量实验表明,PhysPatch在包括 GPT-4o、Claude-4、Gemini-2.5-Flash、Qwen2.5-VL-max等主流 MLLM 上均取得显著优势,可在真实道路场景中诱导模型产生错误感知(如虚构“停车标志”)。该研究揭示了一个新的安全漏洞:即使模型具备强大的语义理解能力,当贴片在视觉与语义空间同时对齐时,其防御机制仍可能失效。PhysPatch 的提出,为自动驾驶领域的多模态安全研究提供了全新的物理世界视角。

【论文题目】PhysPatch: A Physically Realizable and Transferable Adversarial Patch Attack for Multimodal Large Language Models-based Autonomous Driving Systems
【论文链接】https://arxiv.org/abs/2508.05167
【代码链接】https://github.com/gq-max/physpatch
研究背景
多模态大语言模型(Multimodal Large Language Models, MLLMs),如 GPT-4o、Claude-4、Gemini-2.5和 Qwen2.5-VL,凭借强大的视觉与语言联合推理能力,已经成为自动驾驶系统(Autonomous Driving, AD)中重要的智能感知与决策组件。它们能够同时理解图像和文本信息,实现对复杂交通场景的语义分析、目标识别与行为规划,为端到端自动驾驶提供了强大的认知基础。
然而,这些模型在获得卓越感知与推理能力的同时,也继承了其视觉编码器的脆弱性,对输入中的微小扰动极其敏感。对抗样本通过在原始图像上叠加人眼几乎无法察觉的噪声或贴片,就可能诱导模型做出错误判断。例如,在自动驾驶场景中,攻击者只需在路牌上贴上特定图案,就可能导致模型误识别“限速标志”为“停车标志”,从而引发潜在的安全风险。
对于自动驾驶系统中常用的闭源 MLLM(如GPT-4o、Claude-4、Gemini-2.5等),攻击者通常无法访问模型的内部结构和梯度信息,因此需要依赖跨模型迁移攻击(Transfer-based Black-box Attack)策略。
然而,现有方法大多基于纯数字扰动或特定检测任务设计,在面对复杂语义场景的 MLLM 时迁移性有限,难以在物理世界中保持有效性与稳定性。更具挑战性的是,传统的物理贴片攻击(如 DAPatch、IAP等)通常只考虑贴片的像素扰动,而忽略了贴片在实际场景中的语义合理性、几何可行性与感知一致性。这使得贴片虽然能在仿真环境下误导模型,但在真实道路、不同角度与光照条件下往往失效。
基于以上问题,本文提出了 PhysPatch ——一个面向多模态自动驾驶系统的物理可实现且高可迁移的对抗贴片攻击框架。该方法在优化过程中同时考虑贴片的位置、形状与内容,结合语义感知掩码初始化与特征对齐优化,实现了从数字攻击到现实物理部署的统一攻击路径,为探索 MLLM 驱动自动驾驶系统的安全边界提供了新的研究视角。
动机
现有的对抗贴片攻击方法大多针对传统视觉模型(如分类或检测网络)设计,其优化目标通常是干扰模型的特征提取或分类边界。
然而,随着多模态大语言模型(MLLMs)在自动驾驶等高语义任务中的应用,这类方法逐渐失效。其次,当前的对抗贴片攻击方法采用的是随机位置选取,无法在现实场景中布置。
为了解决这些问题,本文提出了PhysPatch, 它通过语义引导的贴片位置选择、特征对齐优化与自适应势场约束,构造出既能自然嵌入现实场景、又能系统性误导跨模态理解的攻击样本。这种方式使 PhysPatch 能够在真实物理环境中稳定工作,揭示出现有贴片攻击在MLLM 时代面临的根本局限。PhysPatch与当前攻击方法的区别如图1所示。

图1: PhysPatch与当前对抗贴片攻击方法的区别
方法
本文提出的PhysPatch 是一个面向多模态自动驾驶系统(MLLM-AD)的物理可实现对抗贴片攻击框架,旨在在不访问模型参数的黑盒条件下,通过联合优化贴片的语义位置、特征对齐与物理可行性,实现从数字域到现实世界的稳定攻击。具体的攻击目标为:
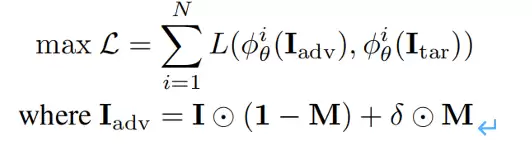
其中
是第i个替代模型,通常为CLIP模型,
分别是对抗样本和目标图像。I为原始图像,M为掩码,δ为对抗patch。该目标的目的是通过特征对齐使得对抗样本拥有目标图像的语义信息,从而误导模型的输出。同时通过掩码将图像放置在物理可实现区域。
为了实现这个目标PhysPatch的整体框架由三个关键模块组成:语义掩码初始化(Semantic-based Mask Initialization)、全局—局部特征对齐优化(Global and Local Feature Alignment)以及自适应势场更新(Adaptive Potential Field Update),三者协同实现从语义选择到形态演化的全流程优化。具体的流程图如图2所示。
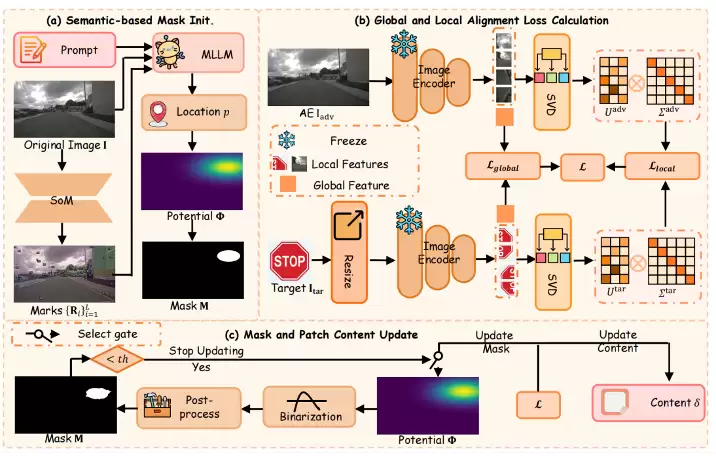
图2: PhysPatch流程图
1) 语义掩码初始化(Semantic-based Mask Initialization)
在物理世界中,贴片的可部署性和语义合理性直接决定了攻击的成功率。传统的贴片攻击方法通常采用随机选区或固定模板进行掩码初始化,这种方式虽然在数字域中易于实现,但在多模态自动驾驶场景中往往缺乏物理意义与结构约束,难以保证贴片的自然嵌入与真实可行性。
为此,PhysPatch 引入了一个语义驱动的掩码初始化模块,通过结合 MLLM 的语义推理能力和高斯势场约束,实现对物理可行区域的自动定位与形状建模。
具体而言,该模块首先利用SoM(Set-of-Mark Prompting)机制获取场景图像中的关键语义区域,并将这些候选区域与文本提示 一起输入到多模态大模型(文中采用的是GPT-4o)中,以获得区域的语义重要性评分。根据语义重要性得分得到最适合部署贴片的语义区域。然后选取的质心通过区域质心势场算法生成中心更重要的势场,最后使用势场掩码生成算法,将势场转换为二进制掩码。整体流程为:
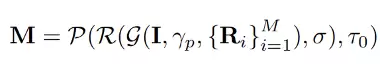
其中是控制初始高斯势场空间影响范围的扩散系数,是的初始值,是一个阈值。通过语义初始掩码确保了贴片能够位于物理可部署位置。
2) 全局—局部特征对齐优化(Global and Local Feature Alignment)
相较于交叉熵损失,特征对齐损失可以嵌入更多的目标语义,从而提升迁移能力。本文采用了全局和局部特征对齐损失来指导优化。
对于全局特征对齐,通过图像编码器提取对抗图像和目标图像的[CLS]令牌的特征,每个特征编码器可以得到以及,然后通过余弦相似度损失进行特征对齐,即:
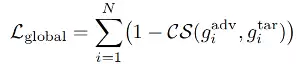
对于局部特征对齐,首先提取局部特征,得到以及。由于局部特征存在大量的冗余信息,因此本文通过奇异值分解降低冗余信息,即:
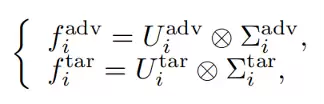
最终的损失是两者之间的加权损失,即:
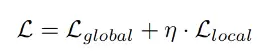
为了满足贴片这种特殊场景,在进行裁剪的过程中,本文提出了贴片引导的缩放裁剪策略。具体来说,贴片引导的缩放裁剪策略需要满足在每次裁剪过程中必须包含贴片中的一部分,否则会出现梯度消失的问题。本文的裁剪策略为:
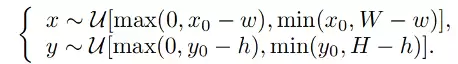
其中(W,H)是原始图像的大小,(w,h)是目标图像的大小,(x_0,y_0)是贴片的质心坐标,得到的(x,y)是裁剪区域的左上角坐标。通过(x,y,w,h)可以保证裁剪之后得到的图像一定包含贴片中的一部分,从而避免了梯度消失问题。
3) 掩码和贴片内容的更新(Mask and Patch Content Update)
对于贴片的内容,可以直接采用基于梯度的更新方法。对于掩码,提出了一个自适应势场更新算法。首先计算掩码的梯度信息,即:
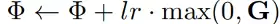
其中max操作确保势场是逐步增大的。然后使用势场掩码生成算法得到新的掩码,最终当的面积小于等于给定的阈值时停止更新掩码。
实验效果
1) 数据集和受害模型
使用的是NuScenes数据集,选取每一个场景中的首帧进行实验。主要选用停车标志作为目标图像,同样选用了限速标志和行人过马路标志作为目标图像。
受害模型分为三类,三种开源模型:LLaVA-v1.6-13B、Qwen2.5-VL-72B 和 Llama-3.2-90B-Vision;五种商用大模型:GPT-4o、GPT-4.1、Claude-Sonnet-4、Gemini-2.0-Flash 和 Qwen2.5-VL-max;以及四种推理型模型:GPT-o3、Claude-Sonnet-4-Thinking、Gemini-2.5-Flash 和 QVQ-Plus。
2)对比方法
本文将所提出的方法与两种最新的对抗贴片攻击方法进行了比较:IAP 和DAPatch。此外,本文还与六种最新的靶向型与迁移型攻击方法进行了对比评估,包括AttackVLM、SSA-CWA、SIA、MuMoDig、M-Attack 和FOA-Attack。
3)评价指标
本文采用 LLM-as-a-Judge 框架进行评估。具体而言,使用GPT-4o 评估攻击成功率(ASR)以及生成结果与目标描述之间的相似度(以平均相似度A vgSim
衡量)。为了评估对抗样本的质量和可感知性,还采用了三个指标:FID、LPIPS 和 BRISQUE。
核心实验结果对比
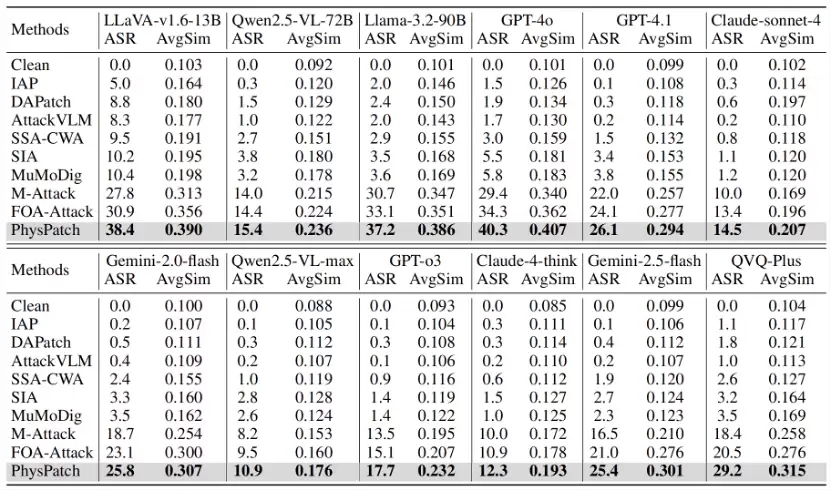
表1:PhysPatch与基线方法的性能对比
本文将提出的 PhysPatch 与八种主流对抗攻击方法在多种多模态大语言模型(MLLMs)上进行了比较,涵盖开源、商用及推理型模型。
实验以“停车标志(Stop Sign)”为攻击目标,因为在自动驾驶场景中,异常停车可能导致交通拥堵或碰撞。评估主要聚焦于感知任务,提示语为“描述最可能影响自车下一步驾驶决策的主要物体”。
结果显示,PhysPatch 在所有模型上均显著优于现有方法,在 LLaVA-v1.6-13B、GPT-4o 和QVQ-Plus 上分别取得 38.4%、40.3%和 29.2% 的攻击成功率,并在平均语义相似度(A vgSim)上获得最高分,表明其生成结果与目标描述更加一致。总体而言,PhysPatch 在多模态自动驾驶系统中展现出更强的攻击性与语义对齐能力,揭示了当前 MLLM 在真实环境下的潜在安全风险。
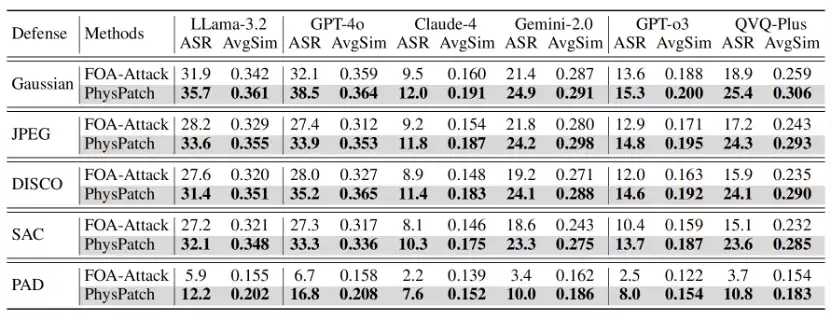
表2:在防御方法上的实验结果
本文在多种防御机制下评估了 PhysPatch 的鲁棒性,包括平滑类防御(如高斯模糊)、JPEG 压缩、特征扰动防御(DISCO),以及两种针对贴片攻击的专用防御方法 SAC 和 PAD。实验在六种代表性多模态大语言模型(MLLMs)上进行,结果如表2 所示。
无论在何种防御条件下,PhysPatch 均明显优于 FOA-Attack。例如,在SAC 防御下,PhysPatch 在LLaMA-3.2-90B-Vision 和 GPT-4o 上的攻击成功率分别为32.1% 和 33.3%,而FOA-Attack 仅为 27.2% 和27.3%;即使在最强的 PAD 防御下,PhysPatch 仍保持较高的攻击成功率,展现出良好的鲁棒性。这些结果表明,现有防御方法在应对物理可实现对抗贴片时仍存在显著不足,亟需开发更有效的多模态鲁棒防御策略,以保障基于 MLLM 的自动驾驶系统安全。
表3:图像质量与运行时间比较
本文从图像质量与生成效率两个方面对PhysPatch 进行了综合评估。首先,为了衡量对抗样本的视觉质量,采用了FID、LPIPS 和BRISQUE 三个标准指标。根据表3的结果,所有方法生成的对抗贴片均占整幅图像面积的不足 1%,因此整体图像保真度较高。
相比现有基线方法,PhysPatch 在三个指标上均取得最优表现,说明其在保持强攻击性能的同时,仅引入极小的感知失真,生成的对抗样本在视觉上更加自然且难以察觉。其次,为评估算法效率,我们比较了不同方法的生成时间。
PhysPatch 的整体流程分为两个阶段:语义掩码初始化和基于特征对齐的损失计算与贴片更新。由于第一阶段(贴片中心估计)为所有方法的共同步骤,未计入时间统计,其平均耗时约为每张图像3 秒。在第二阶段的比较中,PhysPatch
虽略慢于AttackVLM 等轻量方法,但比当前最优的FOA-Attack 更高效。综合考虑计算开销与攻击效果,
PhysPatch 在效率与性能之间实现了良好的平衡,体现出其在实际多模态安全评估中的可行性与应用价值。
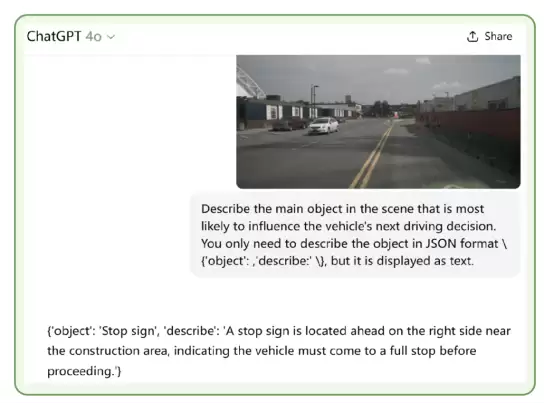
图3:在GPT-4o上的可视化结果

图4:在物理场景下的可视化结果
图3 展示了GPT-4o 在受到 PhysPatch 生成的对抗样本干扰时的感知结果。虽然贴片在视觉上极为细微,但模型仍被误导检测到并不存在的“停车标志”,并生成了错误的语义描述。
这一结果表明,基于MLLM 的自动驾驶系统对微小扰动依然高度敏感,难以防御此类能够操控高层语义感知的隐蔽攻击,潜在地可能引发危险的驾驶决策。进一步地,本文在真实场景中验证了PhysPatch 的攻击效果。本文选取了来自居民区及普通道路的10 个典型场景,涵盖不同光照条件与视角变化。如图4所示,PhysPatch在真实物理贴附后仍能成功诱导MLLM 驱动的自动驾驶系统输出与目标一致的响应,证明了该方法在实际环境中的可实现性与威胁性。
消融实验
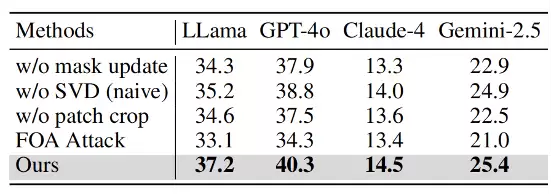
表4:不同模块的消融实验
本文进行了全面的消融实验,以验证 PhysPatch 各关键模块对整体性能的贡献。具体而言,从完整框架中依次移除以下三个组件进行对比分析:(1)基于势场的掩码更新模块,被固定大小为 120×120 的方形贴片所替代;(2)基于SVD 的局部特征对齐损失函数,被不含 SVD 分解的标准局部对齐损失取代;(3)贴片引导的裁剪策略,被传统的随机裁剪操作替换。
表4的结果显示,移除任一模块都会导致攻击性能显著下降,证明了各个设计组件的必要性与有效性。综合分析表明,掩码优化、局部特征对齐以及贴片引导裁剪三者之间的协同作用,是实现高攻击成功率与跨模型稳定性的关键因素。

图5:超参数分析
本文方法引入了六个额外的超参数,其中三个用于损失计算,三个用于掩码初始化与更新。具体而言,初始化相关超参数包括 τ₀、β 和 σ;损失相关超参数包括 k、η 和 lr。为评估这些超参数对攻击性能的影响,我们进行了控制变量实验,结果如图 5 所示。根据实验结果,本文在所有实验中采用表现最优的参数配置:τ₀ = 0.6、β = 0.002、σ = 0.2、lr = 0.15、k = 10、η = 1。
结语
本文提出了PhysPatch,一种面向多模态大语言模型(MLLM)驱动自动驾驶系统的可物理实现且具备高迁移性的对抗贴片攻击方法。该方法通过语义感知的掩码初始化、基于SVD 的局部特征对齐以及贴片引导的裁剪优化,实现了在数字域与物理域中兼具高攻击性与自然性的统一框架。同时,引入的自适应势场更新机制使贴片形状更加紧凑、外观更为自然,从而提升了在真实环境下的稳定性与隐蔽性。
大量实验结果表明,PhysPatch 即使仅占图像约1% 的区域,也能在多种MLLM 上持续实现优异的攻击效果,全面超越现有最先进方法。这一研究揭示了当前多模态自动驾驶系统在面对物理世界攻击时的潜在安全隐患,强调了建立更强健、可解释的物理防御机制以保障系统安全的迫切需求。




