真的。
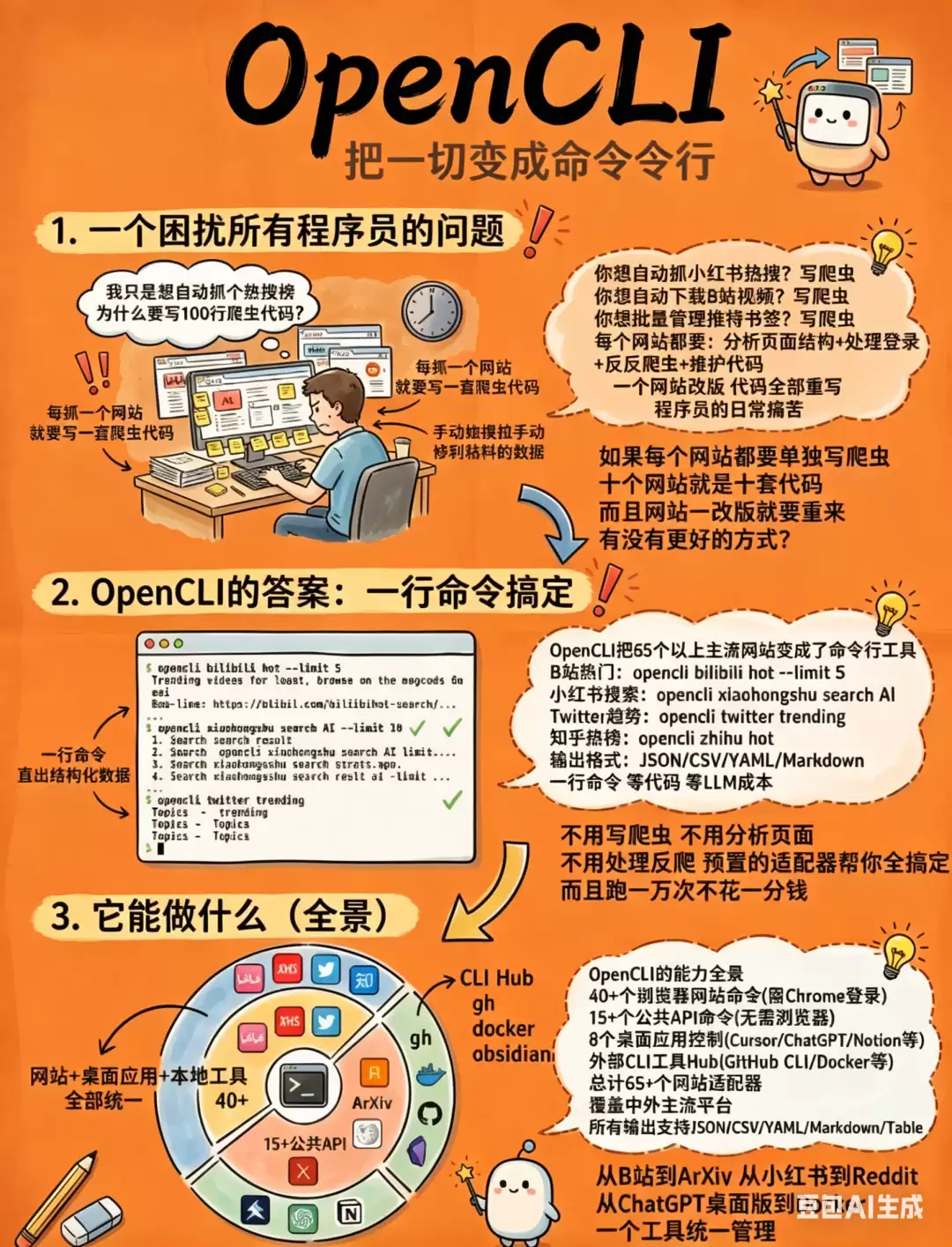
这两天集中看了几篇关于 OpenCLI 的文章。坦白说,一开始心里是打了个问号的——这类号称“浏览器自动化”的工具,多半是看起来很美,装起来麻烦,实际用起来又很玄学。但一路读下来,发现这玩意儿有点意思。
GitHub 上 12.5k 颗 Star,79 个平台适配器,零 API 费用。
它不是单纯在“自动化”的赛道上内卷,而是在补齐一个关键环节——AI 的“双手”。过去,AI 能说会道,但真正干活还得靠人。现在,OpenCLI 给 AI 装上了一双能看、能拿、能操作浏览器的手。
为什么今天的 AI,像个聪明的“嘴炮王”?
这话听着糙,但理不糙。你让 AI 写份方案,它能洋洋洒洒;让它分析竞品,也能讲得头头是道;可一旦让它真正去干点实事——比如去知乎看热榜,它说不联网;去小红书抓笔记,它说没权限;去 B 站找素材,它拿不到你登录后的数据;让它帮你存一篇公众号文章,它直接“失明”。
说白了,过去很多 AI,大脑(模型)已经足够强大,但缺乏执行力的“手臂”和“手指”。所以只能站在旁边给你出主意,真正搬砖的,还是你。这种感觉,确实挺烦人的。
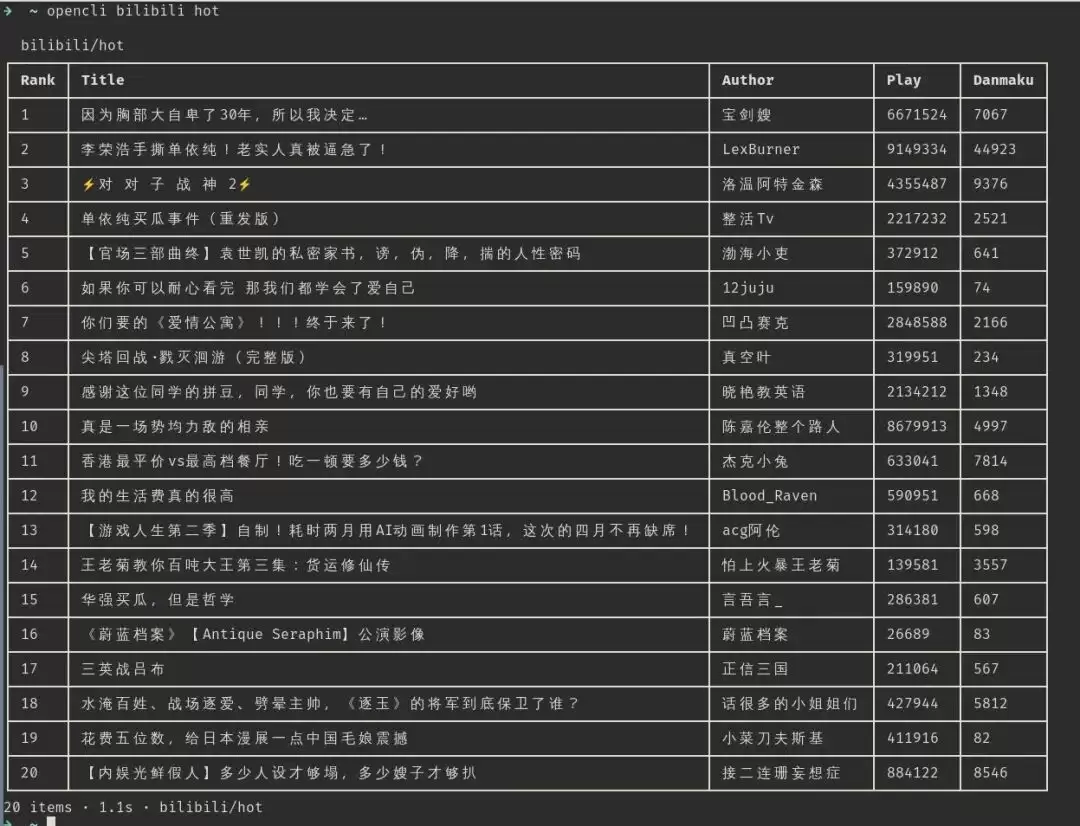
再看看 OpenCLI 能做到什么? 一条命令,就能把 B 站的热榜扒下来。
OpenCLI 的高明之处:不重新造浏览器
这是它最聪明的设计哲学。许多传统的浏览器自动化工具,总想着自己再开一个全新的浏览器实例,然后用户就得陷入一套“登录 → 鉴权 → Cookie → 验证码 → 风控 → 页面结构一变就重来”的地狱式流程,这体验确实让人劝退。
OpenCLI 的思路完全不同。它目前有 430 个内置命令,覆盖 70 个平台,并且还在持续迭代。
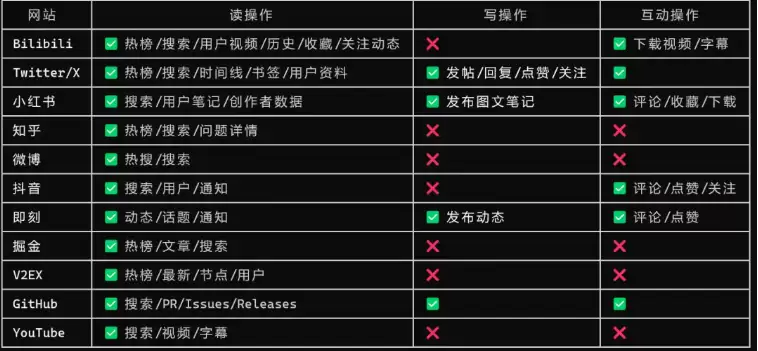
它的逻辑是:既然你的 Chrome 浏览器已经登录了,那就直接复用你的登录态。你 Chrome 里登录着知乎,它就去知乎拿数据;你登录着 B 站、小红书、微信读书,它就复用这些会话继续操作。平台看到的,就是一个正常用户在操作。
这一下,过去最令人头疼的鉴权、风控、页面结构变化问题,直接被绕过去了。不是“自动化能力更强了”,而是它终于开始尊重并利用真实用户的操作环境了。这个思路,才是本质上的不同。
它真正打开的,是“登录后的世界”
这一点,很多人可能还没反应过来。AI 能访问公开网页,没什么稀奇。真正有价值的信息,往往藏在私人空间里——你的收藏夹、历史记录、关注列表、登录后才看得到的创作者数据、你的书架和划线、你的后台。
这些东西,才是真正贴近你工作流、具有独特价值的“私域数据”。过去 AI 碰不到,现在 OpenCLI 这套思路一上来,就等于把这扇门踹开了一条缝。从这一步开始,AI 看到的,不再只是“互联网”,而是你自己的互联网视角。这个变化,非常猛。
和 Playwright MCP 有什么区别?
这个也得说清楚。Playwright MCP 当然很强,但它的本质是让大语言模型实时“看着”页面,一步步判断下一步怎么操作。这既慢,又消耗 Token,而且一旦流程长、页面复杂、状态多变,失败率就容易飙升。
OpenCLI 的路子不同。它是事先把每个平台的数据接口封装成一条固定命令,执行时不经任何 AI 推理,直接取数,直接返回结构化结果。
打个比方:Playwright MCP 是让 AI 临场发挥,灵活但风险高;OpenCLI 是给 AI 发了一本写好的操作手册,稳定且高效。对于真实的、需要长期跑的工作流来说,后者的可靠性至关重要。
它能干什么?三个真实场景
场景一:每天的信息聚合早报
以前想看知乎、B 站、即刻的热榜汇总,需要一个个手动打开。现在一条命令就能同时拉回数据,让 AI 整理成一份早报。甚至可以设成定时任务,早上八点自动跑,吃早饭时直接看结果。
场景二:YouTube 视频字幕一键提取
遇到一个 49 分钟的英文采访,不想慢慢看?直接让 AI 调 OpenCLI 把字幕全抓下来存成 Markdown,然后翻译、提炼要点、生成摘要。以前一小时,现在五分钟。
场景三:公众号文章本地存档
想把公众号文章存成 Markdown 留档?以前要手动复制排版,现在一行命令搞定:
opencli weixin download --url 文章链接 --output ./weixin图片也会一并下载保存到本地。
实操命令速查:装完第一天能干什么
不要只停留在概念层面,直接上手跑这些命令,五分钟就能感受到差异。
基本范式:
opencli <平台> <动作> [参数] [--format json]▍拉热榜
# B 站热门视频
opencli bilibili hot --limit 10
# 知乎热榜
opencli zhihu hot --limit 20
# HackerNews(无需登录,直接跑)
opencli hackernews top --limit 10
# 三个一起拉,输出给 AI 整理早报
opencli bilibili hot -f json && opencli zhihu hot -f json && opencli hackernews top -f json▍搜索平台内容
# 小红书搜关键词
opencli xiaohongshu search query="AI工具"
# B 站搜视频
opencli bilibili search --keyword "Claude Code" --limit 10
# Twitter/X 搜话题
opencli twitter search "OpenCLI" --limit 15 -f json▍拿你的私人数据(需提前在 Chrome 登录对应平台)
# B 站观看历史
opencli bilibili history --limit 20 -f json
# Twitter 书签
opencli twitter bookmarks --limit 20 -f json
# 知乎文章下载成 Markdown
opencli zhihu download --url "文章链接" -o ./zhihu▍存档 & 下载
# 公众号文章转 Markdown 存本地(图片一并保存)
opencli weixin download --url "文章链接" -o ./weixin
# B 站视频下载(依赖 yt-dlp)
opencli bilibili download --bvid "BV号"
# 小红书笔记下载(图片/视频)
opencli xiaohongshu download --url "笔记链接"
# Twitter 媒体下载
opencli twitter download --url "推文链接"▍发内容(写操作,执行前务必确认好内容)
# 发一条推文
opencli twitter post --text "今天用 OpenCLI 效率翻倍了"
# 小红书发笔记
opencli xiaohongshu publish --title "标题" --content "正文"
# 回复某条推文
opencli twitter reply --url "推文链接" --text "回复内容"▍浏览器直接操控(高级用法)
不只是读数据,OpenCLI 还能直接操控浏览器页面:
opencli open "https://example.com" # 打开页面
opencli click "按钮选择器" # 点击元素
opencli type "输入框" "内容" # 输入文字
opencli screenshot # 截图
opencli eval "document.title" # 执行 JS这意味着任何网页上的操作,理论上都可以被脚本化。
▍查看所有支持的命令
opencli list或者运行诊断确认一切正常:
opencli doctor直接让你的 Claude 或其它 AI Agent 说:“帮我用 opencli 查一下 B 站今天的热榜”,它会自己选命令、自己跑、自己整理结果。这才是接进 Agent 的正确姿势。
对于跑 Agent 工作流的人,它值钱在哪?
值钱在它不是一个孤立工具,而是可以被接入 Agent 流水线里的一个环节。
自动抓热点 → 自动搜平台内容 → 自动整理成 Markdown → 自动交给内容助理写稿 → 自动交给 SEO 助理做判断 → 自动交给复盘助理看效果。
一旦浏览器动作被命令化,整个工作流就活了。它不再是“我问一句,AI 回一句”的问答模式,而是“我下一个任务,AI 去环境里把活干回来”。这个差距,是问答时代和 Agent 时代的本质差异。
更值得关注的是,它连 Electron 应用那条路都在探索。 Cursor、Notion、ChatGPT 桌面版…… 这些桌面应用,OpenCLI 也在尝试接入。
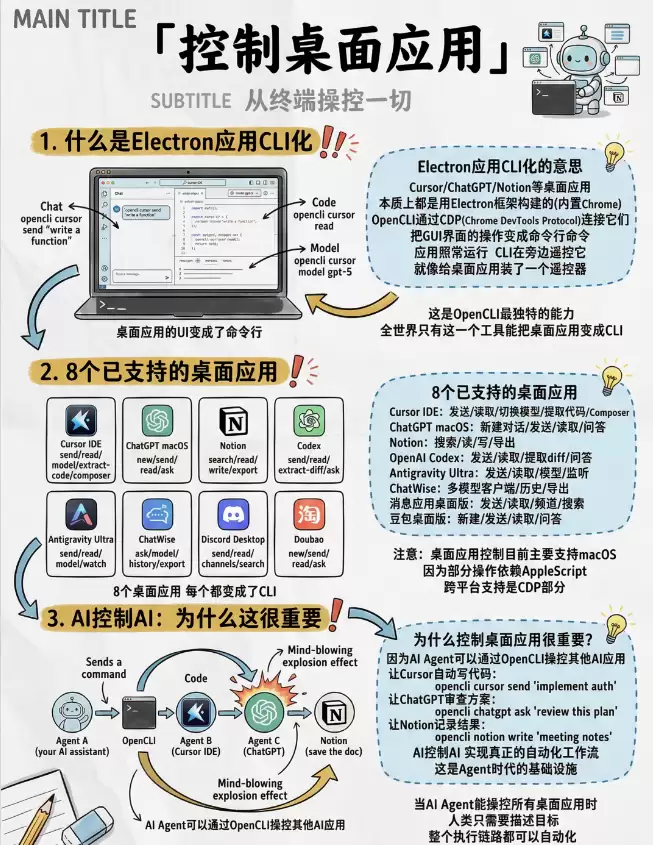
一个 Agent 可以去调另一个 AI 工具,那整个空间就完全不一样了。不是你在一个窗口里手动切来切去,而是它们自己串起来干活。你只负责定目标,剩下的,让工具链自己跑。这才是“数字分身”该有的样子,不然顶多算个“数字玩具”。
适合哪三类人?
第一类:内容创作者。 平时要搜选题、找素材、看热门内容、收集案例,很多重复动作都可以命令化。
第二类:运营和数据整理的人。 以前手动翻页、复制、截图、下载,现在可以批量做,省很多时间。
第三类:AI 工作流玩家。 如果本身就在折腾 Agent 和自动化,这个工具非常值得研究——它相当于给 AI 多接了一双“能操作网页的手”。
怎么安装?10 分钟搞定
安装共三步,照着做就行。
第一步,装 Node.js(需要 20 以上版本)。 去 nodejs.org 下载 LTS 版本,装完验证:
node -v
# 显示 v20.x.x 就对了第二步,全局安装 OpenCLI 本体:
npm install -g @jackwener/opencli装完跑一下,看看有没有命令列表出来:
opencli list第三步,装 Chrome 扩展做浏览器桥接。 去项目 GitHub Releases 页面下载 opencli-extension.zip,解压后:
- Chrome 地址栏输入
chrome://extensions/ - 右上角开启「开发者模式」
- 点「加载已解压的扩展程序」,选择解压后的文件夹
装完跑一下诊断:
opencli doctor输出全绿,就能开始用了。
为什么这不是一个小工具,而是一个信号?
因为现在模型本身已经够强了。大多数人今天卡住,不是卡在模型不够聪明,而是卡在模型接不上真实环境。你会看到一种荒诞的局面:AI 写方案写得飞起,你自己打开浏览器、搜索、登录、复制、整理,最后 AI 动嘴,你动手。这像话吗?
真正下一阶段应该是:人类负责定目标,AI 尽可能多地完成中间执行。从这个角度看,OpenCLI 补的根本不是一个命令行工具位,而是 AI 从会说、到会做,中间缺的那一段执行力。这段一旦补上,很多事情的天花板会被直接抬高。
最后一句话
有人说得很准:以前 AI 会说。现在它开始会看、会拿、会调、会跑。再往后,它就会越来越像一个真正能替你赚钱、替你提效、替你跑流程的数字分身。
不是浏览器该不该自动化的问题,是——AI,终于开始真的下场干活了。




