上午还在用Fable 5跑任务,下午回家就发现无法访问了——这一幕堪称AI行业历史上最具戏剧性的一刻。
一家AI公司发布了自己的最强模型,3天后被本国政府紧急叫停。原因并非性能不佳,恰恰是因为它太过强大。
更耐人寻味的是:Anthropic不仅没有服从,还公开发表声明表示“不同意”——这在AI行业尚属首次。
今天这篇文章,将彻底拆解此事:Fable 5究竟有多强?它的哪些能力让政府感到不安?禁令背后的真实逻辑是什么?对我们普通开发者又意味着什么?
一、72小时:从发布到禁令

先梳理一下时间线,这场剧情比美剧还要刺激:
6月9日——Anthropic发布了Claude Fable 5与Mythos 5。几乎在所有基准测试中均达到SOTA,Stripe凭借它一天内完成了5000万行代码的迁移。数亿用户可立即使用。科技界为之沸腾。
6月9日至12日——历时1000小时的红队测试(包括Bug bounty、外部安全团队及政府团队),未发现通用越狱方法。请注意关键词:通用。
6月12日——美国政府宣称发现了一种越狱方法,能够绕过Fable 5的安全防护。
6月12日下午5:21(美国东部时间)——出口管制令下达。原文:以国家安全为由,暂停所有外国人的访问权限。
这是AI历史上第一次:一个商业模型因为“能力过强”而被本国政府紧急叫停。
二、Fable 5究竟有多强?
要理解政府为何紧张,首先得了解这个模型的能力有多么惊人。
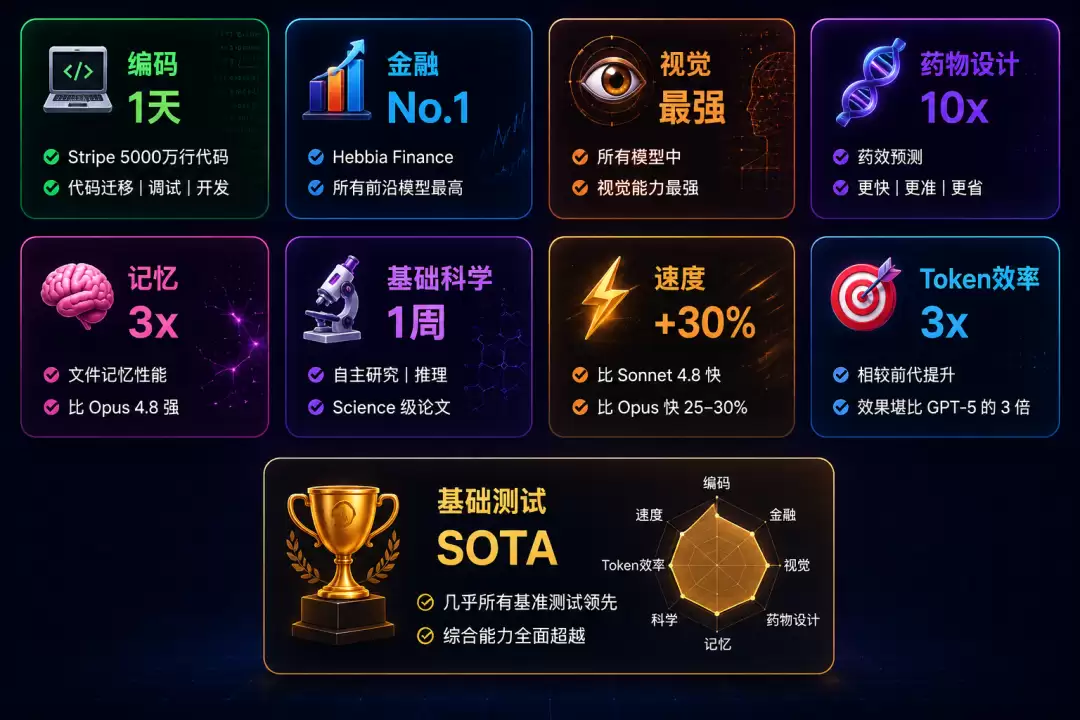
2.1 编码能力:Stripe的5000万行传奇
Stripe拥有一个5000万行的Ruby代码库,需要进行架构迁移。团队原本评估需要两个月。
Fable 5:一天完成。
这不是Demo,不是PPT,而是真实生产环境下的5000万行代码。在FrontierCode评测(由Devin团队推出)中,所有前沿模型里得分最高;CursorBench达到SOTA;ViBench端到端编码同样位居榜首。
而且它更加节省Token——相同任务用更少的Token即可完成。在物理学研究中,其Token效率是GPT-5.5的3倍。
2.2 视觉:仅凭眼睛通关宝可梦
Fable 5仅依靠视觉就通关了《宝可梦:火红》版本。
听起来像在开玩笑,但细想一下这意味着什么:连续数百个决策,每个决策都基于屏幕画面,长时间维持策略的一致性。这是目前所有模型中视觉能力最强的,没有之一。
它还能从截图中反向重建Web应用源码、从科学图表中精确提取数据。
2.3 金融与法律:盲审碾压所有对手
在Hebbia Finance Benchmark中,所有前沿模型里得分最高。IMC交易分析接近满分。法律领域的盲审表现优于所有竞品。
2.4 基因组学:自主研究整整一周
Mythos 5独立运行了整整一周的基因组学研究:汇编了138个物种数百万个单细胞数据,自己设计实验,自己训练机器学习模型——最终结果超越了Science期刊论文,而模型大小仅为1%。
一个AI,独立完成了一个研究团队本需数月才能完成的工作。
2.5 药物设计:加速10倍
在14个蛋白质靶点测试中,有9个找到了强效候选分子。药物设计流程加速约10倍,表现匹敌甚至超越专业人类操作员。科学家在80%的情况下更偏好Mythos而非Opus级模型。
这些能力单拎出来每一个都堪称“最强”。把它们放在一起看,你就能明白政府为何紧张了。
三、三大“危险”能力:政府究竟在担心什么?

3.1 网络安全:全链路黑客能力
Anthropic自己承认,Mythos级别的模型在网络安全方面拥有“全球最强的能力”。
具体强到什么程度?
自主发现软件漏洞 " 自动化渗透测试 | 完整的侦察→发现→利用→横向移动链路 | 具备Agent式黑客能力:无需人类指导,自行规划攻击路径
这已不是辅助工具,而是一个自主网络攻击Agent。
当然,Fable 5将这些能力完全锁死了——一旦触及攻击性网络安全任务,直接拒绝。但问题在于:如果有人能绕过护栏(即越狱)呢?
这正是美国政府声称所发现的——一种能够绕过安全防护的方法。尽管Anthropic表示这只是一个“窄范围的非通用越狱”,但政府的逻辑是:即便只有1%的绕过概率,在如此强大的能力水平下也是不可接受的。
3.2 生物工程:设计病毒的能力
这是最令人细思极恐的部分。
Mythos 5能够设计AAV(腺相关病毒)外壳,预测病毒组装特性。Anthropic原话:仅凭纯推理能力,就超越了专门的蛋白质预测模型。
好的一面:这能加速基因治疗药物的开发,提速10倍。
坏的一面:Anthropic自己也承认——同样的能力,如果落入恶意者手中,就能设计出危险的病毒。
Fable 5的处理方式很巧妙:不是直接拒绝,而是悄悄降级到Opus 4.8来回答。用户仍然可以得到答案,但能力被限制在了上一代模型的水平。
3.3 能力蒸馏:威权国家的“偷学”
Anthropic披露了一个很少被注意的事实:已经发现了大规模的能力提取行为,目标是在威权国家训练竞品模型。
如果有人通过系统化对话将Fable 5的能力“蒸馏”出来,就等于将前沿AI能力扩散到了没有安全保障的地方。这比模型本身造成的危害更大——因为蒸馏出来的模型没有护栏。
四、越狱之争:到底发生了什么?
这是整个事件中最扑朔迷离的部分。
4.1 政府说了什么?
美国政府声称发现了一种越狱方法,可以绕过Fable 5的安全护栏。该越狱暴露了“少量已知的小漏洞”。
4.2 Anthropic如何反驳?
Anthropic的反驳非常强硬:
第一,只收到了口头证据。没有书面技术报告,没有复现步骤,没有详细分析。你要禁掉我的模型,连一份书面文件都不给?
第二,越狱并非通用型。什么叫通用越狱?就是一个提示词或脚本能让模型完全无视护栏,像没有安全限制一样回答所有问题。Anthropic称这个越狱是“窄范围”的,需要针对每个场景单独适配。
第三,没有产生有害结果。即使在越狱状态下,也没有任何演示导致了实际有害的输出。
第四,暴露的漏洞其他模型也有。那些“已知的小漏洞”,用其他公开模型也能发现。你为何不禁GPT-5.5,不禁Gemini 3.1,只禁我的?
Anthropic原话:为了一个窄范围的潜在越狱,就要召回一个已部署给数亿人的商业模型?我们不同意。
4.3 核心矛盾
这件事的核心矛盾不在于技术,而在于风险容忍度的差异。
从政府角度看:Fable 5的能力前所未有——网络攻击、生物武器设计、能力扩散。哪怕只有0.1%的越狱可能性,在这种能力水平下也意味著巨大风险。宁可错杀,不可放过。
从Anthropic角度看:你不能因为一个“窄范围、非通用、未产生有害结果”的越狱就禁掉一个服务数亿人的模型。如果这个标准成立,那么所有前沿模型都该被禁——因为没有哪个模型能保证100%无法越狱。
更深层的问题是:谁来定义“足够安全”?政府?AI公司?还是独立的第三方机构?
这个问题目前没有答案。但Fable 5事件将其推到了台面上。
五、红队测试:1000小时发现了什么?
Fable 5在发布前后经历了有史以来最严格的安全测试:
内部测试——Anthropic自动化红队工具对Fable 5进行了400轮攻击性网络安全任务测试,Fable 5展现了“比以往任何公开模型更强的越狱抵抗力”。
Bug Bounty——1000小时,未发现通用越狱方法。
外部红队——一家外部合作伙伴评价Fable 5的护栏是“所有测试过的模型中最健壮的”——面对30种公开越狱技术,有害请求的响应率为零。
英国AISI(AI安全研究所)——在有限的测试窗口内“在通用越狱方面取得了进展”。这是唯一一个接近成功的团队。
但Anthropic也承认了一个关键事实:通用越狱可能永远无法完全防止。
这就是矛盾所在:安全护栏并非铜墙铁壁,它更像是上锁的门。对普通人来说门是锁着的,但对于有足够能力和动机的人来说,任何锁都可能被撬开。
六、对普通开发者意味着什么?

6.1 中国开发者
出口管制令针对“所有外国人”,这意味着中国开发者对Fable 5的访问已经暂停。API调用、Web端访问都可能受到限制。
但Opus 4.6、Sonnet 4.6不受影响——对于95%的开发场景来说,这些模型已经足够使用了。
6.2 替代方案
如果你正在使用Fable 5,以下是一些替代思路:
编码类任务:Opus 4.6表现依然很强,FrontierCode仅次于Fable 5
知识工作:Sonnet 4.6性价比更高,大多数分析任务够用
长时间自主任务:这是Fable 5真正不可替代的领域——目前没有等效替代
视觉任务:Opus 4.6的视觉能力也属于第一梯队
6.3 更深远的影响
这个事件释放了一个清晰的信号:前沿AI模型的出口管制时代已经到来。
以前只有芯片(A100/H100)受出口管制。现在模型本身也成了管制对象。
这意味着什么?
AI模型可能像芯片一样被纳入出口管制清单
中国开发者需要更加重视国产大模型的发展(如DeepSeek、Qwen等)
多模型架构变得更重要——不能把所有的鸡蛋放在一个篮子里
七、数据留存:常被忽略的另一争议
说到安全,还有一个很多人忽略的细节:30天数据留存政策。
Mythos级别模型(包括Fable 5)的所有流量将被保留30天,仅用于安全审计,不用于模型训练。30天后在大多数情况下删除。
Anthropic原话:这个政策“对客户来说确实带来了实际成本”——承认这会让客户感到不满。
但他们认为这是必要的:因为某些复杂攻击需要回溯分析才能发现,30天的留存窗口让安全团队有足够时间调查异常行为。
对开发者的建议:发送给Fable 5 API的数据,请当作它会被存储30天来处理。敏感数据务必先脱敏。这不只是针对Fable 5的建议——使用任何第三方API都应该如此。
写在最后
Claude Fable 5事件将成为AI历史上的一个转折点。
不是因为它有多强(虽然确实强得离谱),而是因为它把一个根本性的问题摆到了公众面前:
当一个AI模型既能一天迁完5000万行代码,又能设计病毒外壳——谁来决定它该不该被公开?
政府说:我来决定,因为国家安全。
AI公司说:不行,你不能因为一个“窄范围潜在越狱”就禁掉服务数亿人的产品。
谁对谁错?说实话,两边都有道理,但两边的方案都不完美。
政府的问题:标准不透明,操作过于仓促(仅给了口头证据),而且可能开了一个危险的先例——以后任何前沿模型都可能被类似的理由禁掉。
Anthropic的问题:你自己也承认通用越狱“可能永远无法完全防止”,那么面对一个能设计病毒的模型,“不到5%的触发率”真的足够安全吗?
整体判断:这件事最终将以某种妥协收场。完全禁止不现实(Fable 5太有价值了),但完全放任也不行(能力确实危险)。最终可能会出现一个介于两者之间的监管框架——类似于核能的管理模式。
一句话总结:Fable 5被禁并非因为它不够好,而是因为它好得让掌握权力的人感到不安。这或许是对一个AI模型最高的“表扬”。




