2026年2月5日,HashiCorp联合创始人、Terraform的发明者Mitchell Hashimoto,在个人博客上贴出了一篇文章,标题是《My AI Adoption Journey》。文章走到第五步时,他写下了一个新词:Harness Engineering(驾驭工程)。
六天后的大年初四,也就是2月11日,OpenAI的Ryan Lopopolo在官方博客迅速跟进,发表了《Harness Engineering: Leveraging Codex in an Agent-First World》,并且给出了一套经典公式。
紧接着,又过了几周,Martin Fowler在自己那个做了二十年的博客上,洋洋洒洒写下一篇长文,把Harness Engineering的理论体系彻底串联了起来。
从命名到定义再到完整的框架,前后加起来也就不到一个月的时间。这大概是AI领域“从提出概念到形成共识”最快的一次收敛。
今天这篇文章,咱们就把这个被视作2026年最重要的工程概念,彻底讲清楚。
一、为什么Prompt Engineering不够用了?
先聊一个挺扎心的现状。
你可能花了两小时调试一个prompt,让Claude完美地完成了某个任务。那一刻,你感觉一切都是那么美好。可一转身,你把同样的prompt丢给第二个任务——它立刻重蹈了之前的覆辙。
问题的根源在于:Prompt Engineering解决的是“单次交互”,而Agent需要解决的是“持续可靠”。
| 维度 | Prompt Engineering | Harness Engineering |
|---|---|---|
| 解决的问题 | “这句话怎么说?” | “怎么让它永远不犯这个错?” |
| 作用范围 | 单次交互 | 整个系统生命周期 |
| 失败模式 | 单次输出质量差 | 长期质量退化 |
| 实现方式 | 调措辞、加示例 | 搭约束、建反馈、自动化 |
| 可维护性 | 手动、per-task | 自动、持续 |
用Mitchell Hashimoto的原话来说就是:你不是在调prompt,你是在建系统。
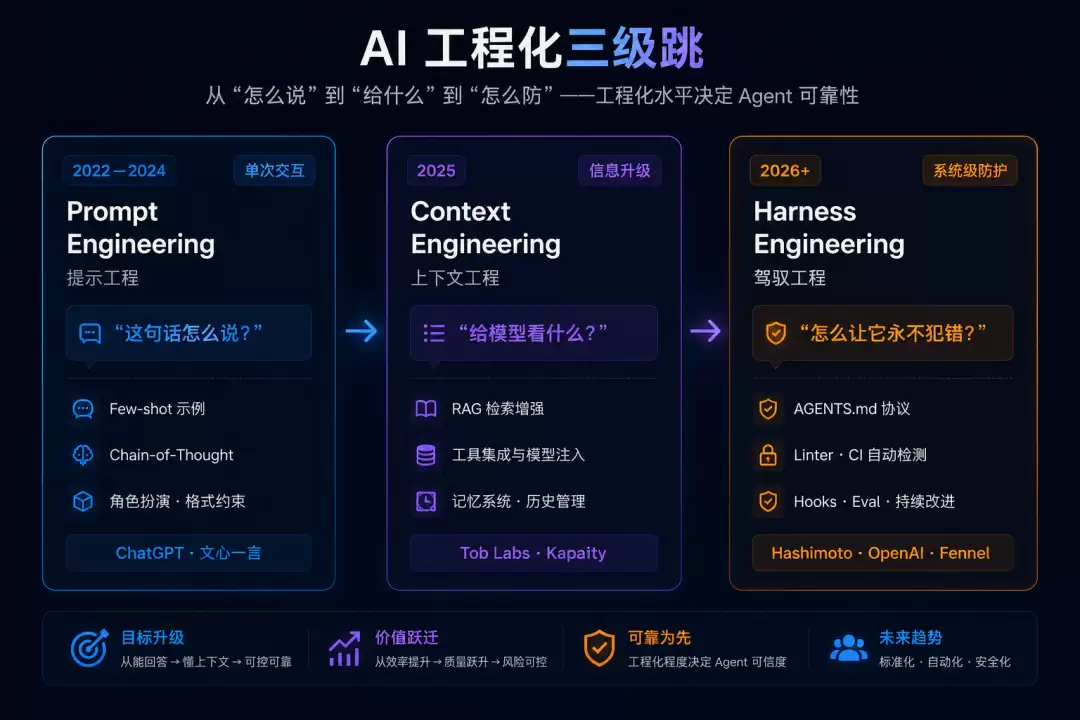
二、概念辨析:Prompt vs Context vs Harness
2026年,有三个带着“Engineering”的概念满天飞,很容易混淆。一次性说清楚:
Prompt Engineering(提示工程)—— “怎么说”
2022-2024年的主角。核心问题:这句话怎么措辞,才能让模型给出最好的回答?技巧包括Few-shot示例、Chain-of-Thought、角色扮演、输出格式约束。
Context Engineering(上下文工程)—— “给什么”
2025年6月,Shopify的CEO Tobi Lutke发了一条推特,引发广泛讨论。一周后,Karpathy跟帖跟进。核心问题:给模型看什么信息,才能让它理解任务并正确执行?技巧包括RAG检索、工具调用结果注入、对话历史管理、记忆系统。
Harness Engineering(驾驭工程)—— “怎么防”
2026年2月的主角。核心问题:怎么让Agent在长期运行中保持可靠、可维护、可改进?技巧包括AGENTS.md约束文件、自定义Linter、结构化测试、CI管道、生命周期Hook、自动化纠错机制。
三者的关系其实很简单:Harness > Context > Prompt。Prompt是一句话,Context是一个信息包,Harness是一整套系统——它包含了Context和Prompt,但还额外加上了约束、检测、反馈和持续改进机制。
三、Martin Fowler的Harness框架:Guides + Sensors
Martin Fowler的文章为Harness Engineering构建了一个非常优雅的分类体系:Guides(引导)和Sensors(传感器)。
Guides(前馈控制)—— 事前预防
在Agent行动之前,通过文档、规范、约束来引导它的行为。
| Guide类型 | 示例 | 说明 |
|---|---|---|
| AGENTS.md / CLAUDE.md | 项目级指令文件 | 告诉Agent“在这个项目里,你应该怎么做” |
| 架构文档 | 层级依赖规则、模块边界 | 告诉Agent“这些边界不能越” |
| 编码规范 | 命名约定、错误处理模式 | 告诉Agent“代码应该长什么样” |
| Bootstrap脚本 | 环境初始化、依赖安装 | 确保Agent从正确的起点开始工作 |
Sensors(反馈控制)—— 事后检测
在Agent行动之后,通过检测工具发现问题并触发修正。Fowler把它分成两类:
计算型传感器(确定性、毫秒级):类型检查器(TypeScript tsc)、Linter(ESLint、Pylint)、单元测试/集成测试、自定义结构化测试(比如“controllers/目录下的文件不能import models/”)。
推理型传感器(非确定性、较慢):LLM作为代码审查员(“AI审AI”)、视觉回归截图对比、语义一致性检查。
关键洞察:先上计算型传感器。它们快、准、便宜。推理型传感器作为补充,不要作为主力。

三种Harness类型
Fowler进一步把Harness分成了三类:
| Harness类型 | 目标 | 成熟度 | 示例工具 |
|---|---|---|---|
| 可维护性Harness | 代码质量、风格一致性 | 高 | Linter、类型检查、测试 |
| 架构适应度Harness | 层级边界、依赖规则 | 中 | ArchUnit、自定义结构测试 |
| 行为Harness | 功能正确性、业务逻辑 | 低(最难) | Eval驱动开发、端到端测试 |
四、OpenAI的实战案例:100万行代码,0%人工编写
OpenAI的Ryan Lopopolo团队用Codex构建了一个生产级应用,留下了目前为止最极端的Harness Engineering案例。
关键数据
| 指标 | 数值 |
|---|---|
| 代码量 | ~1,000,000行 |
| 人工编写比例 | 0% |
| 人工review比例 | 0% |
| 团队规模 | 3人起步,最终7人 |
| 开发周期 | 5个月 |
| 合并PR数 | ~1,500 |
| 人均日PR | 3.5 |
| AGENTS.md文件数 | 88个 |
| 单次Codex运行最长时长 | 6小时(无人值守) |
1500个PR,没有人工review,全部由自动化Harness保障质量。 这句话值得反复读。
他们怎么做到的?
第一招:6层架构约束
他们把代码库分成6层,每一层只能依赖下面的层:
1. UI层(React组件)
2. ↓ 只能调用
3. Runtime层(运行时状态管理)
4. ↓ 只能调用
5. Service层(业务逻辑服务)
6. ↓ 只能调用
7. Repo层(数据访问仓储)
8. ↓ 只能调用
9. Config层(配置管理)
10. ↓ 只能调用
11. Types层(类型定义)这些约束不是写在文档里让Agent“遵守”的——而是通过自定义Linter硬编码成了检测规则。Agent一旦越层调用,CI直接失败。
第二招:88个AGENTS.md文件
不是一个大而全的文件,而是88个分布式指令文件。每个子组件、每个模块都有自己的AGENTS.md,只包含该模块相关的约束。为什么不用一个文件?因为OpenAI发现:单个全量文件“可预见地失败了”——它挤占了任务相关的上下文空间。
第三招:渐进式信息披露
顶层AGENTS.md只有~100行,充当“目录”,指向结构化的docs/目录。Agent需要什么信息,按需去读,而不是一次性全部塞进上下文。
核心哲学
这就是Harness Engineering的终极目标:把人的判断标准固化成自动化规则,让Agent在没有人类监督的情况下也能产出高质量代码。
五、量化证据:同一个模型,换套Harness,效果差10倍
说到这里,可能有人会问:Harness真的有这么大影响吗?
来看一组数据:
| 实验 | 无Harness / 基础Harness | 优化后Harness | 提升倍数 |
|---|---|---|---|
| Can.ac准确率测试 | 6.7% | 68.3% | 10.2倍 |
| LangChain Terminal Bench 2.0 | 第30名 | 第5名(+13.7分) | 排名跳升25位 |
| Princeton研究 | 基线 | +64% solve rate | 1.64倍 |
Can.ac的实验最为震撼。同一个模型、同样的权重、同样的任务——唯一的变量是Harness。 准确率从6.7%直接飙到68.3%。
这意味着什么?意味着在2026年,模型选择已经不是第一重要的事了。你怎么用它,比你用哪个模型重要10倍。
六、Karpathy的CLAUDE.md:16万Star的“驾驭手册”
Andrej Karpathy在2026年1月发布了一份CLAUDE.md文件,基于他从“80%手写代码”到“80%Agent生成代码”的实战经验,提炼了4条核心准则。
这份文件被开源社区整理成了GitHub仓库,截至2026年5月已有16.1万Star,成为年度增长最快的开源项目之一。
四条准则
准则1:编码前先思考(Think Before Coding)
准则2:极简优先(Simplicity First)
准则3:外科手术式修改(Surgical Changes)
准则4:目标驱动执行(Goal-Driven Execution)
Karpathy的关键洞察:这4条准则让AI编码准确率从65-70%提升到了91-94%。
七、实战指南:怎么搭建你的Harness?
7.1 第一步:写好你的指令文件
这是成本最低、效果最立竿见影的Harness组件。
# CLAUDE.md (或 AGENTS.md / .cursorrules)
## 项目概述
本项目是一个供应链管理系统,使用 Node.js + React + PostgreSQL。
## 架构规则
- src/controllers/ 只能调用 src/services/,不能直接访问 src/models/
- 所有数据库操作必须通过 src/repositories/ 层
- 前端组件不允许直接调用 API,必须通过 src/hooks/ 层
## 编码规范
- 使用 TypeScript strict mode
- 函数名使用 camelCase,类名使用 PascalCase
- 错误处理:业务异常用自定义 AppError,系统异常直接 throw
- 不要添加未要求的功能、注释或类型注解
## 测试规则
- 每个新函数必须有对应的测试
- 测试文件放在 __tests__/ 目录,命名为 *.test.ts
- 使用真实数据库连接,不要 mock
## 常见错误(每条都是踩过的坑)
- ❌ 不要在 controller 中直接写 SQL
- ❌ 不要使用 any 类型
- ❌ 不要把环境变量硬编码在代码中7.2 第二步:搭建计算型传感器
// .claude/settings.json — 生命周期Hook配置
{
"hooks": {
"PostToolUse": [
{
"matcher": "Write|Edit",
"command": "npx eslint --fix $FILE && npx tsc --noEmit"
}
],
"PreCommit": [
{
"command": "npm test -- --bail"
}
]
}
}每次Agent写完代码,自动跑Lint和类型检查。每次提交前,自动跑测试。Agent犯的错在提交之前就被拦截了。
7.3 第三步:建立“错误→规则”的反馈循环
这是Harness Engineering最核心的实践:
Agent犯错
↓
你发现了
↓
分析根因:是缺少约束?还是缺少检测?
↓
如果是缺少约束 → 更新 CLAUDE.md
如果是缺少检测 → 添加 Linter规则或测试
↓
Agent永远不会再犯同样的错误Mitchell Hashimoto的原则:每一个Agent错误都是改进Harness的机会。 不要只是修复这次的错误,而是要确保这类错误永远不会再发生。
7.4 第四步:Eval驱动开发
搭建一套评估基准,持续衡量Harness的效果:
# 从真实失败案例中收集20-50个任务
# 每次修改Harness后,跑一遍eval
# 跟踪通过率变化
eval-results/
├── baseline.json # 基线:无Harness,通过率62%
├── v1-agents-md.json # 加了CLAUDE.md,通过率78%
├── v2-linter.json # 加了Linter hook,通过率85%
├── v3-arch-tests.json # 加了架构测试,通过率91%
└── v4-eval-driven.json # Eval驱动迭代,通过率94%八、开发者角色的转变:从写代码到写规范
Gartner预测,到2026年底,75%的开发者将把更多时间花在编排和架构上,而不是写代码上。
Harness Engineering推动了一个根本性的角色转变:
| 传统开发者 | Harness时代开发者 |
|---|---|
| 写代码 | 写规范(Spec) |
| 手动测试 | 设计评估基准(Eval) |
| Code Review | 维护Harness(Guides + Sensors) |
| 修Bug | 分析错误模式,更新约束规则 |
| 关注“怎么实现” | 关注“怎么验证” |
OpenAI的总结最到位:你的价值不再是“写得一手好代码”,而是“搭得一手好Harness”。
写在最后
2026年的AI工程圈有一句话越来越流行:没有人会买一台裸发动机然后期望它自己开到目的地。 但大量团队正在做的事情就是——拿着一个裸模型,扔给它一句prompt,然后期望它产出生产级代码。
Harness Engineering不是一个新技术,它是一种工程纪律。它要求你:
- 每发现一个Agent错误,就固化一条规则
- 每增加一个约束,就配套一个检测
- 每次迭代,都用Eval来衡量效果
Mitchell Hashimoto、OpenAI、Martin Fowler、Karpathy——这些人在2026年2月几乎同时指向了同一个方向。这不是巧合,而是整个行业到了这个阶段的必然收敛。
模型能力趋同后,Harness就是你的护城河。
同一个Claude Sonnet,你用得好是94%准确率,用得差是6.7%。差距不在模型,在Harness。
2026年最值钱的技能,不是会调prompt,不是会选模型,而是——会搭Harness。




