过去一周,整个 AI 圈被一个叫 SkillOpt 的项目彻底刷屏了。
它有多火?GitHub 开源一周,Star 数突破 3400;36氪、网易、腾讯等科技媒体头版报道;无数 AI 工程师连夜跑实验,结果一致:“震撼,完全碾压人类手写”。
但最令人震惊的不是这些数字,而是它提出的一个碘伏性观点:Agent 的能力,不取决于模型本身,而取决于它的“技能文档”。
当所有人都在卷更大的模型、更贵的算力时,微软用一份 2000 字的纯文本文件,给了整个行业一记响亮的耳光。
而对于我们这些做政企 AI Agent 的人来说,SkillOpt 的出现,可能意味着一个时代的结束,和另一个时代的开始。
别再手写 Skill 了!你花 3 天写的,不如 AI 训练 1 小时
如果你做过 Agent 开发,你一定有过这样的痛苦经历:为了让 Agent 能正确处理一个财务报销流程,你花了整整 3 天时间,写了一份长达 5000 字的 Skill 文档。你反复打磨每一个细节,规定了每一步该做什么、遇到异常该怎么处理、输出格式是什么样的。然后你满怀期待地让 Agent 去跑任务,结果发现:它总是漏掉你写的某条规则,它会误解你的意思,做出完全错误的操作,它在这个案例上表现很好,换一个案例就彻底崩了,你改了一个问题,又引出了三个新问题。
你不断地修改、测试、再修改、再测试,陷入了无尽的循环。最后你发现,你不是在做 AI 开发,你是在做“AI 保姆”。

这就是过去一年 Agent 开发的真实写照:我们本来是想让 AI 帮我们干活,结果反过来,我们在花大量精力教 AI 怎么干活。而 SkillOpt 的出现,彻底终结了这种荒诞的局面。
SkillOpt 到底是什么?用大白话讲清楚
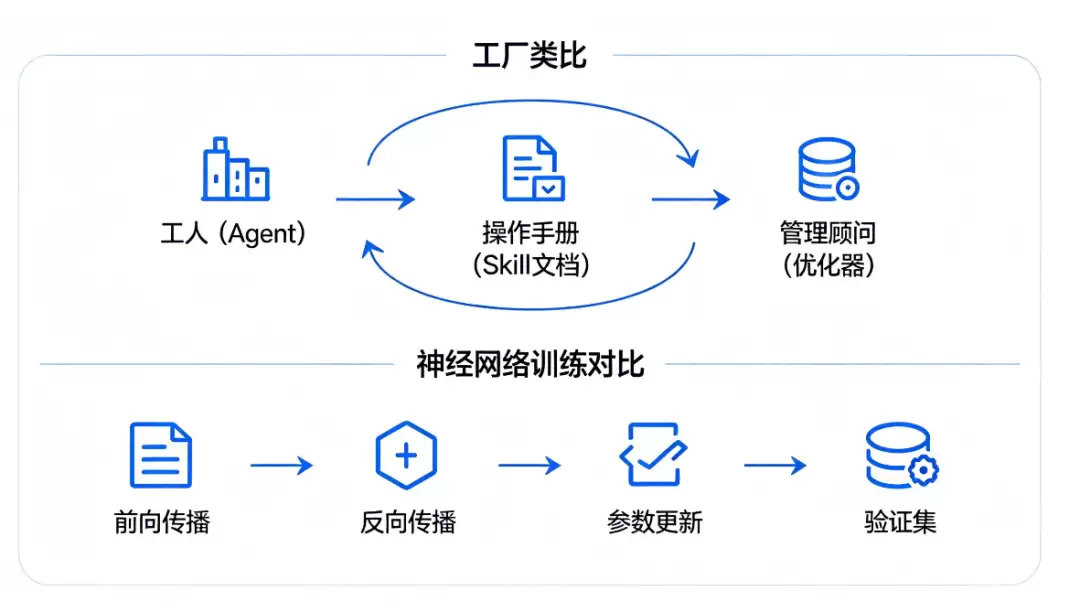
SkillOpt 的核心思想简单到离谱:把 Agent 的技能文档当成神经网络的“权重”,用训练神经网络的方法来训练它。
你可以把整个过程想象成一个工厂:工人——就是你平时用的 Agent(GPT、Claude、通义千问都可以);操作手册——就是你写的 Skill 文档;管理顾问——就是 SkillOpt 的优化器模型。工人按照操作手册干活,管理顾问不干活,他只看工人哪里做错了,然后去修改操作手册。修改完之后,工人再按照新的手册干活,管理顾问再看哪里还有问题,再改。如此反复,直到操作手册变得完美。
这个过程和训练神经网络一模一样:
- 前向传播:Agent 带着当前的 Skill 去执行任务
- 反向传播:优化器分析成功和失败的轨迹,提出修改建议
- 参数更新:修改 Skill 文档
- 验证集:在新的任务上测试,确保没有过拟合
最神奇的是,整个过程不需要修改模型的任何一个权重。你用的还是原来的 GPT-5.5,还是原来的 Claude 3.7,只是给它换了一份更好的操作手册,它的能力就会得到质的飞跃。
碾压级的实验结果:52 项评测全优
SkillOpt 的效果有多好?看看微软的实验数据就知道了。微软在 7 个目标模型、6 个基准测试、3 种执行环境,总共 52 个评测组合中测试了 SkillOpt。结果是什么?全部获得最优或并列最优成绩。
一些具体的数字:
- GPT-5.5 在直接聊天模式下,六个基准测试的平均得分从 58.8 分提升到了 82.3 分,整整提高了 23.5 分
- 一个 4B 参数的小模型,经过 SkillOpt 优化后,能力超过了没有优化的 70B 大模型
- 企业文档任务,只需要一次成功的编辑,得分就提升了 39.0 个百分点
更可怕的是,SkillOpt 训练出来的 Skill,具有极强的可迁移性。把在 Codex 环境里训练的电子表格技能,直接拿到 Claude Code 环境里用,得分从 22.1 分飙升到 81.8 分,涨幅高达 59.7 分。这意味着,你训练出来的一个好 Skill,可以在不同的模型、不同的环境中通用。
SkillOpt 为什么是政企 AI 的“救星”?
很多人看到 SkillOpt,第一反应是“这对开发者太友好了”。但客观来看,SkillOpt 最大的价值,是在政企市场。
政企 AI Agent 一直面临着三个无解的难题:数据安全问题——不能把数据上传到公有云,不能微调大模型;定制化需求高——每个政府部门、每个国企都有自己独特的业务流程;人才短缺——懂 AI 又懂政企业务的人少之又少。而 SkillOpt,完美地解决了这三个问题。
第一,不需要微调模型,数据绝对安全。政企对数据安全的要求有多高,不言而喻。任何需要把数据上传到公有云、或者需要微调模型的方案,在政企市场几乎都是死路一条。而 SkillOpt 的整个训练过程,完全可以在本地部署。你不需要把任何业务数据发送给第三方,也不需要修改模型的任何权重。所有的优化都发生在那份纯文本的 Skill 文档上。这对于政企来说,简直是致命的吸引力。
第二,把定制化成本降低 90%。过去,为一个政企客户定制一个 Agent,需要一个团队花几个月的时间。其中 80% 的工作,都是在手写各种业务 Skill。有了 SkillOpt 之后,这个过程会发生翻天覆地的变化:你只需要写一个最基础的 Skill 版本(可能只需要 1 小时),然后用客户的历史业务数据去训练它,训练几个小时之后,你就会得到一个比人类手写好得多的 Skill。如果业务流程变了,你只需要用新的数据重新训练一下就行。定制化成本直接降低 90%,交付周期从几个月缩短到几天。
第三,让不懂 AI 的人也能训练 AI。SkillOpt 最大的贡献,是把 AI 能力的门槛降到了最低。过去,你需要是一个资深的提示词工程师,才能写出一份好的 Skill。现在,你只需要有业务数据,就能训练出一个优秀的 Agent。一个在政府部门工作了 10 年的老科员,他可能不懂什么是大模型,什么是神经网络,但他知道什么是正确的业务流程,什么是错误的操作。他只需要把过去的业务案例整理出来,交给 SkillOpt,就能训练出一个比他自己还懂业务的 AI Agent。这才是真正的“AI 民主化”。
现在就能用:政企 SkillOpt 落地实操指南
说了这么多,你可能已经迫不及待想试试了。这里整理了一份最简单的政企 SkillOpt 落地实操指南,你今天就能用起来。
第一步:选择适合的业务场景。SkillOpt 最适合的是标准化、流程化、有明确成功标准的任务。在政企场景中,这些场景的效果最好:公文处理(会议纪要生成、通知起草、文件审核)、财务报销(发片识别、报销单审核、预算控制)、行政审批(申请材料审核、流程流转、结果通知)、知识库问答(政策解读、办事指南、常见问题解答)、数据处理(报表生成、数据统计、异常检测)。不适合的场景:开放式写作、主观评价、需要创造性的任务。
第二步:准备训练数据。训练数据是 SkillOpt 的核心。你需要准备:10-100 个历史业务案例(越多越好),每个案例都要有明确的输入和输出,最好能有成功和失败的案例对比。不需要标注得特别精细,只要能判断任务是否成功就行。
第三步:写一个基础 Skill。不需要写得很完美,只要把基本的流程和要求说清楚就行。比如一个会议纪要 Skill,你只需要写:

第四步:运行 SkillOpt 训练。现在 SkillOpt 已经开源了,你可以直接从 GitHub 下载代码。它支持所有主流的大模型,包括 Azure OpenAI、OpenAI、Anthropic Claude、通义千问等。而且自带了一个可视化的 WebUI,你可以直观地看到训练过程和每一步的改进效果。训练过程非常简单,你只需要:配置你的大模型 API 密钥,导入你的训练数据和基础 Skill,设置训练参数(学习率、批次大小、训练轮数),点击“开始训练”。然后你就可以去喝杯咖啡,几个小时之后回来,就能得到一个训练好的最优 Skill。
第五步:部署和持续优化。训练完成后,你会得到一个 best_skill.md 文件。你只需要把这个文件交给你的 Agent,它的能力就会立刻提升。而且,这个过程是可以持续的。随着 Agent 处理越来越多的任务,你可以不断地用新的案例去训练它,让它变得越来越聪明。
写在最后:SkillOpt 正在改写 AI 时代的护城河
SkillOpt 的出现,给整个 AI 行业带来了一个灵魂拷问:如果一份 2000 字的文本文件,就能让一个小模型反超比它大二十倍的大模型,那么这个行业里真正值钱的东西,到底是什么?
过去,我们认为大模型是护城河,算力是护城河,数据是护城河。但 SkillOpt 告诉我们,这些都不是真正的护城河。真正的护城河,是那些沉淀在具体业务场景中的、经过无数次实践验证的、可复制的技能知识。
对于政企市场来说,这意味着什么?这意味着,未来的竞争,不再是谁的模型更大、谁的算力更强,而是谁拥有更多、更好、更适合政企业务场景的 Skill。谁能率先把政府部门、国企的各种业务流程,转化为一个个可训练、可优化、可迁移的 Skill,谁就能在未来的政企 AI 市场中占据绝对的主导地位。而现在,这个机会刚刚出现。




