刚踏入职场时,我曾一度认为,高级工程师之所以写代码快,全凭更聪明的头脑。
随着亲手参与的项目不断增多,我才彻底意识到事实并非如此。
许多资深工程师在编写代码时,既不过度堆砌复杂算法,也不刻意炫耀设计模式。他们的代码具有一个肉眼可见的共性:简洁、清晰、易于维护。这些编码习惯单独看来并不复杂,但组合在一起,就能显著提升整个项目的代码质量。
今天,我就来分享从他们身上学到的 7 个经典编码模式。这些技巧并不局限于某种特定语言,文中的示例主要使用 Go 语言来演示。

1. 用早返回(Early Return)减少嵌套
新手写代码时,很容易陷入层层嵌套:
func CreateUser(name string) error {
if name != "" {
if len(name) <= 20 {
fmt.Println("create user")
return nil
} else {
return errors.New("name too long")
}
} else {
return errors.New("name empty")
}
}逻辑本身没有硬伤,但随着条件分支的增多,代码就像长歪的树一样不断向右偏移,可读性大幅下降。
高级工程师通常采用更优雅的处理方式:
func CreateUser(name string) error {
if name == "" {
return errors.New("name empty")
}
if len(name) > 20 {
return errors.New("name too long")
}
fmt.Println("create user")
return nil
}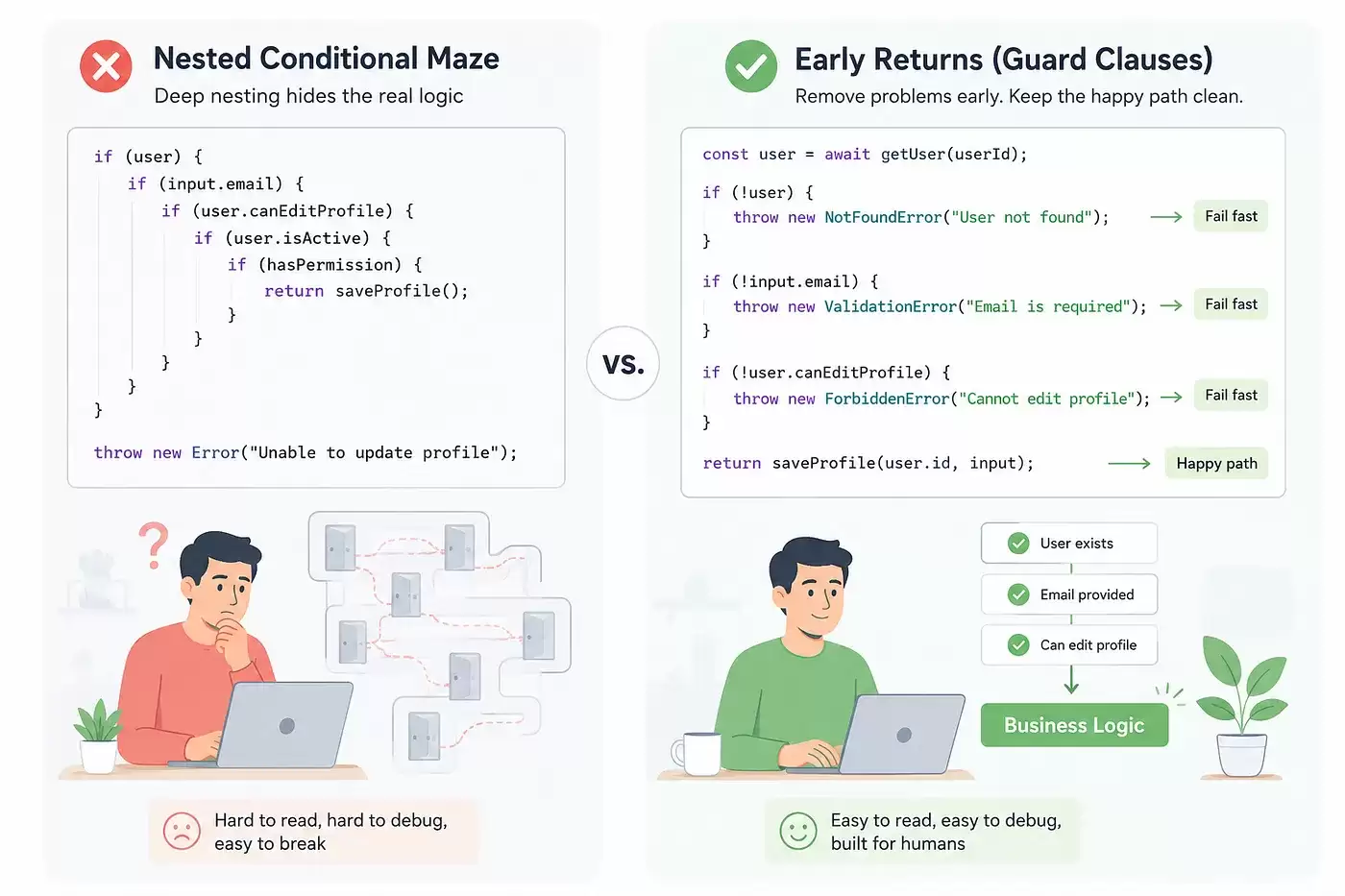
这种写法的好处不言而喻:嵌套层次更少,代码更易读,错误路径一目了然。Go 标准库中大量采用这种写法,最经典的莫过于 if err != nil { return err }。
资深工程师心里很清楚:读代码的成本远高于写代码。他们在下笔时,会优先考虑别人在高压环境下理解这段逻辑的难度。当然,这并非要求绝对禁止嵌套。在某些场景下,比如解析器、树遍历或复杂业务流程,嵌套结构反而能直观地反映层级关系。关键在于一个度——嵌套一旦超过三层,大概率就该考虑重构了。
2. 给复杂逻辑起个名字
很多人习惯直接写条件:
if user.Age >= 18 &&
user.Status == "active" &&
user.EmailVerified {
...
}刚写完时觉得挺简单。半年后再回头看,脑袋里只剩下一堆问号:为什么是 18?为什么必须是 active?验证邮箱又是为了什么?业务意图早就淹没在代码里了。
高级工程师更倾向于封装:
func CanPurchase(user User) bool {
return user.Age >= 18 &&
user.Status == "active" &&
user.EmailVerified
}调用的时候就变成了:
if CanPurchase(user) {
...
}代码读起来就像自然语言一样流畅。在资深工程师眼中,命名绝不只是表面功夫。很多开发者习惯用技术属性命名,比如 data、result、item、resp,看着简洁,但随着系统迭代,调试成本会急剧膨胀。而按照业务含义命名,业务语义不会因为代码实现的变更而失效,阅读和调试成本自然大幅降低。好的函数名,本身就是最好的注释。
3. 让非法状态无处藏身
新手常见的写法:
type User = {
id?: string;
email?: string;
role?: string;
status?: string;
};问题在于,把所有字段都变成可选,仅仅是为了让 TypeScript 不报错。这根本不是类型安全,这是在向编译器投降。比如,用户 id 不存在的情况,在业务逻辑中根本就不该出现。
资深工程师不只满足于处理非法状态,他们从代码设计层面就让非法状态难以容身。在动态语言中,可以借助数据校验、构造函数、工厂函数或严谨的运行时检查来实现同样的思路。工具的选择是次要的,关键是习惯的养成。更好的方式是用类型系统精确建模业务状态:
type DraftUser = {
email: string;
role: "admin" | "member";
};
type SavedUser = {
id: string;
email: string;
role: "admin" | "member";
status: "active" | "disabled";
};这样做的好处有三个:可读性更好,修改更便捷,还能有效降低出错概率。
4. 让函数只做一件事
很多代码喜欢这样组织:
func ProcessOrder(order Order) error {
validate(order)
save(order)
sendEmail(order)
updateInventory(order)
generateInvoice(order)
writeLog(order)
return nil
}看着很省事,但违反了单一职责原则。任何一个环节发生变化——库存逻辑变了、邮件逻辑变了、发片逻辑变了——都得来修改这个函数。
高级工程师偏好拆分:
func ProcessOrder(order Order) error {
if err := validate(order); err != nil {
return err
}
if err := saveOrder(order); err != nil {
return err
}
return completeOrder(order)
}每个函数只负责一个明确的目标,测试起来也更轻松。
5. 不要重复自己(DRY)
项目中经常出现这种代码:
func GetUser(id int) {
db.Query(...)
}
func GetOrder(id int) {
db.Query(...)
}
func GetProduct(id int) {
db.Query(...)
}逻辑几乎完全一样,只是操作的对象不同。这就是典型的重复代码。高级工程师会抽象出公共部分:
func QueryByID(table string, id int) {
...
}或者封装一个统一的 Repository 结构体进行管理。
不过也要注意,DRY 不代表要过度抽象。有些人看到两段相似的代码就想合并,结果写出了 HandleEverything(...) 这样的巨型函数,反而更难维护。经验表明,三次重复以上再考虑抽象,通常是比较稳妥的原则。
6. 错误信息要有上下文
Go 开发中一个常见的问题:
return err日志里只留下一句 connection failed,然后就没了下文。哪个服务失败了?哪个接口出的问题?哪个数据库连接超时?完全无从得知。
高级工程师通常会这样写:
if err != nil {
return fmt.Errorf(
"create user failed: %w",
err,
)
}输出变成了 create user failed: connect database timeout,定位问题的速度直接拉满。Go 1.13 引入 %w 之后,这种写法已经成为业内的最佳实践。可以说,好的错误信息,价值不亚于一套完善的监控系统。

7. 牢记代码首先是写给人看的
有些程序员喜欢炫技。比如:
result := lo.Filter(
lo.Map(
users,
func(u User, _ int) User {
return transform(u)
},
),
func(u User, _ int) bool {
return valid(u)
},
)看起来确实挺高级。但对团队新人来说,理解起来可能费点劲。如果改成这样:
var result []User
for _, user := range users {
transformed := transform(user)
if valid(transformed) {
result = append(result, transformed)
}
}虽然代码长了一些,但所有人都能看懂。资深工程师真正关注的是“一年后还能不能看懂”,而不是“今天能不能秀技术”。代码的第一读者永远是人。在做优化时,他们会兼顾变更的可观察性,确保改动范围可控、回滚方案清晰,而不是只顾着把本地环境跑通。
最大的特点不是技术,而是减少惊讶
刚入行时总以为,高级工程师的标配是复杂架构、高级设计模式、炫酷的代码。后来发现恰恰相反。真正资深的人往往更克制,他们更懂得如何减少惊讶。他们会主动避免不必要的抽象、不必要的框架、不必要的设计模式——因为他们见过太多项目在后期失控。他们深知,软件最大的成本从来不是编写,而是维护。一个能稳定运行三年的系统,远比一个设计完美但没人敢改的系统更有价值。




