今年3月,腾讯发布了《2026年AI人才报告》,其中一项数据格外引人注目:AI辅助编程工具能够将通用型开发任务的效率提升约50%。
这一消息迅速在测试行业从业者群体中引发热议。
引发讨论的并非这50%的效率提升本身,而是测试作为保障“执行质量”的关键防线,当执行者自身的工作流程也被加速,防线的可靠性还能维持多久?
更令人不安的还在后面。中国信通院的数据显示,到2026年,预计已有70%的企业测试用例将由AI生成。Claude Code和Codex等工具,早已超越了单纯的代码编写辅助角色;它们能够自主生成代码、自动修复缺陷,并进行持续迭代。Tricentis发布的《2026年质量转型报告》进一步揭示了严峻的现实:全球有60%的组织,已将未经充分测试的代码直接投入生产环境。
开发效率成倍增长,而留给测试的窗口期却被压缩至两三天。代码规模急剧膨胀,可用于验证的时间却在同步缩短。
这已不是某个特定工具带来的问题,而是整个工程模式正在经历结构性变革。
许多人已经察觉到:测试的执行层面正在被快速重构。测试用例可实现自动生成,自动化脚本能智能编写,甚至Bug的定位也依赖于模型推理。
那么,留给测试工程师的核心价值还有哪些?
这个问题,近来被行业反复探讨。
一、AI编程工具正在重塑执行层
让我们先看一组数据。
在SWE-bench Verified排行榜上,顶级AI编程工具解决真实GitHub问题的成功率,已从2023年的48.5%飙升至78.8%。这意味着AI独立完成实际开发任务的能力,在两年内几乎翻了一番。
工具层面的竞争同样激烈。Claude Code以77.4%的SWE-bench得分领跑,Cursor紧随其后,得分为76.8%。其中最为引人注目的是Claude Code的Computer Use功能——AI能够自主启动应用程序、复现bug、修复代码并验证结果,整个过程无需离开终端。
只需一条指令,AI即可独立完成“启动应用→复现问题→代码修复→结果验证”的完整闭环。
这对测试行业意味着三大趋势正在成为现实:
测试用例生成。过去依赖人工分析需求、设计边界条件并整理用例,现在AI能够基于需求直接生成完整的测试集。
自动化脚本编写。以往需要编写代码、调试框架和处理兼容性,现在AI可以直接生成可运行的脚本,并自动修复运行错误。
Bug定位。传统的做法需要反复复现问题、检查日志、分析根因,如今AI能分析调用链、日志和上下文信息,快速定位问题根源。
结论非常直接:测试的执行层正在被高效压缩。
但这还不是最令人担忧的。真正的问题在于——AI生成的代码表面上看起来没有问题。编译能够通过,常规流程也能顺利运行。然而,一旦遭遇异常场景、并发竞争或数据一致性问题,就可能暴露出深层次的缺陷。这些缺陷在代码审查阶段很容易被忽略,因为人类开发者倾向于信任AI给出的整洁代码。
速度已经提升,那么质量又由谁来保障?
二、本质变化:从“编写代码”到“指导AI工作”
行业变革的本质,是研发流程的范式转移。
腾讯云将企业AI Coding实践划分为三个阶段:
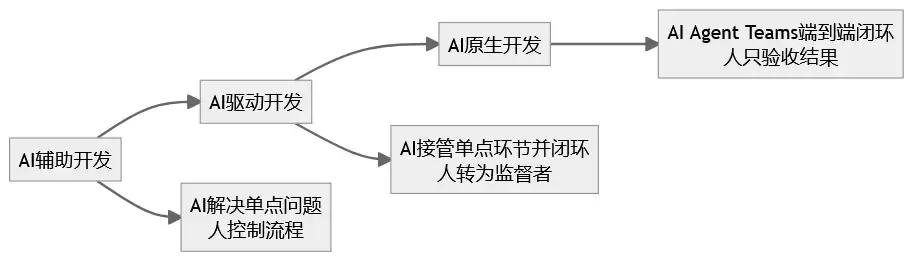
到2026年,我们正从第一阶段向第二阶段过渡。
这一转变的核心是能力重心的迁移。
过去的能力重心在于:掌握编程语言、开发框架和工具链,能够编写可运行的代码。
新的能力重心则转向:深入理解业务流程、抽象问题本质、设计规则体系、精准判断AI产出质量,以及构建可复用的能力封装。
说得更直白一些:当AI能够独立完成整个项目时,决定最终输出价值高低的关键,依然是人的判断力。
测试工程师的核心价值正从“编写用例”跃升为“设计生成系统”。两者的区别在于:前者关注“如何做”,后者关注“为何这样做”以及“如何确保始终做对”。
可被截图传播的观点句①:测试的执行层正在被快速压缩,但决策层正在被放大。
三、核心机制:Skill究竟是什么
理解了“为何发生变化”,我们再来看“通过什么来实现变化”。
Skill是Anthropic于2025年10月推出的功能,本质上是一个包含指令、脚本和资源的文件夹。当Claude模型需要时,会加载这些资源以完成特定任务。
它与传统提示词工程的区别体现在三个关键词:自动调用、渐进式加载、可执行代码支持。
通俗地说,Agent Skills是专门为大模型准备的可复用能力包。过去,为模型下达任务时需要一次性提供完整背景信息。有了Skills,你可以将某个领域的知识提前整理好,打包成一个“技能”,模型在使用时按需读取。
简单理解:为AI配备一本随用随查的操作手册。
其核心机制是“渐进式披露”(Progressive Disclosure):
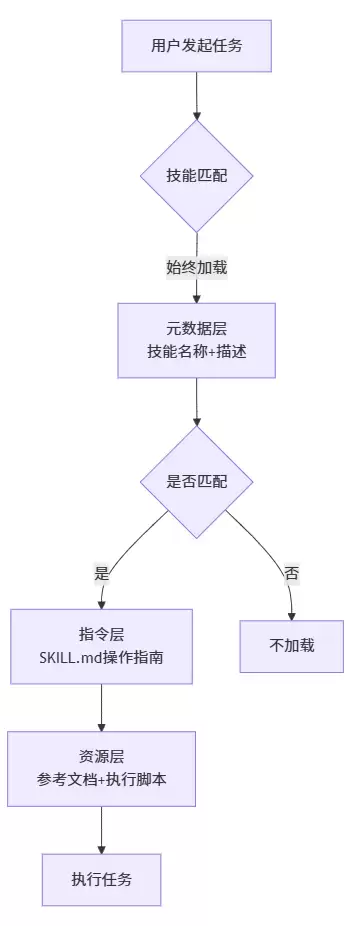
第一层:元数据层——始终加载。仅加载技能名称和描述,模型据此判断是否匹配当前任务。
第二层:指令层——按需加载。匹配成功后,才读取SKILL.md中的操作指南。即使装载了100个技能,对话开始时也不会撑爆上下文窗口。
第三层:资源层——深度加载。包含参考文档和执行脚本。
这套机制解决了一个核心问题:将资深工程师的经验沉淀下来,转化为可复用、可传递的能力。
可被截图传播的观点句②:Skill的本质不是让AI更聪明,而是将人的经验转化为AI可执行的资产。
四、8个典型场景:哪些项目最适合使用Skill
并非所有测试工作都适合引入Skill。以下8个场景已经在实际项目中得到验证,它们共同具备“流程长、信息多、重复性强、依赖上下文”的特点。
场景1:测试用例生成
适用于需求文档标准化程度高的项目。输入需求文档,Skill能够自动输出覆盖等价类、边界值、异常流的初版用例。人工仅需补充特有业务规则。
某电商项目,输入标准化需求文档后,AI在30秒内输出初版用例,人工补充“满减叠加逻辑”等特有规则后即可直接进入评审。
其本质是将测试设计方法论(等价类、边界值、场景法)拆解为标准化工作流。
场景2:自动化脚本生成
适用于UI稳定、交互模式固定的项目。通过自然语言描述测试意图,Skill能够自动生成符合PageObject规范、包含完整断言的Playwright脚本。
Webapp Testing Skill是Anthropic官方推出的工具,你只需告诉AI“测试登录功能”或“验证表单提交流程”,它就能自动完成相应测试。
其本质是将脚本编写经验封装成可复用模板。
场景3:Bug定位与日志诊断
适用于日志规范、调用链清晰的项目。Skill结合MCP协议连接日志平台,自动完成“查日志→找关键信息→扫描代码→定位问题”的完整闭环。
得物技术的/log-diagnosis Skill就是典型实践。
其本质是将排查经验转化为可执行的诊断流程。
场景4:接口测试编排
适用于业务流程固定、接口依赖复杂的项目。将“登录”“下单”“支付”等每个步骤变成独立的Skill,AI根据一句话指令自动编排执行顺序和参数传递。
其本质是将接口串联逻辑从代码硬编码转变为可配置的工作流。
场景5:测试数据构造
适用于对数据合法性要求高的项目。Agent根据字段描述生成候选数据,随后调用数据校验Skill检查其合法性(如手机号格式、身份证校验位、业务关联约束)。
其本质是将数据生成逻辑和校验规则分离,实现生成与校验的闭环。
场景6:回归测试用例选择
适用于变更频繁、回归集庞大的项目。代码变更后,Skill根据变更影响范围自动推荐需要执行的回归测试用例,并生成优先级排序。
其本质是将回归策略从“全量执行”转变为“精准打击”。
场景7:代码审查与质量检查
适用于多人协作、代码规范要求高的项目。Skill在PR阶段自动审查代码,检查规范符合度、潜在风险以及测试覆盖率。
其本质是将Reviewer的经验固化为一套可自动执行的检查清单。
场景8:测试报告生成
适用于需要定期输出质量报告的项目。Skill自动汇总测试执行数据、缺陷趋势和覆盖率变化,生成结构化报告。
其本质是将数据汇总和分析逻辑从人工整理转变为自动化流水线。
一个核心判断:哪些项目不适合Skill?
需求频繁变动、UI频繁重构、业务逻辑缺乏文档的项目,不宜直接使用Skill。Skill的前提是流程可定义、规则可沉淀、经验可复用。如果你自己都无法清晰描述“怎么测”,那么任何工具都无法帮到你。
五、工程落地:避免这3个常见误区
误区1:将Skill当作普通提示词使用
许多人在接触Skill时,第一反应是“这不就是一个高级提示词吗”。
这是最大的误解。
提示词是一次性的。每次对话都需要重新输入、调整和验证。而Skill是可复用的。一次定义,反复调用,版本可控。
更关键的区别在于执行能力。提示词只能生成文本。Skill可以调用脚本、连接MCP、操作外部系统。Claude Code接入MCP后,可以调用GitHub、数据库、浏览器、API,甚至企业内部平台。AI不仅能够回答问题,还能调用工具、嵌入工程链路、执行实际任务。
本质区别:提示词是“告诉AI怎么做”,Skill是“让AI自己会做”。
误区2:Skill之间缺乏治理
裸调Skill与工程化Skill之间的区别,就像临时脚本与CI/CD流水线的区别。
裸调方式:人写提示词,AI输出脚本,人复制粘贴到框架中。速度快,但每一轮对话都是独立的,没有版本约束,没有上下文锁定,出问题时只能从聊天记录中回溯。
工程化方式:将Skill视为流水线中的一个“生成步骤”。具备固定的输入源、参数化模板、审批节点和质量阈值,执行完毕后自动进入下一环节。
可被截图传播的观点句③:Skill是大脑,而流水线是让大脑可靠行动的脊椎。
误区3:Skill不进行迭代
Skill不是一次性资产。它需要像代码一样拥有版本、经过测试、持续迭代。
一个可验证的Skill应包含评估用例,并定期运行评估以验证其效果是否退化。当业务规则发生变化时,Skill需要同步更新。当发现新的缺陷模式时,Skill需要补充相应规则。
六、最后一个问题
两个月前,我为某个团队提供Skill落地咨询。他们的测试负责人问了一个问题,我认为它比任何技术问题都更值得深思:
“如果有一天,AI能够自动生成所有测试用例、自动执行所有测试脚本、自动定位所有Bug,那么测试工程师的价值究竟在哪里?”
答案是:当AI能够完成所有执行层面的工作,测试工程师唯一剩下的、也是唯一不可替代的价值,就是定义“什么是对的”。
定义测试策略、设计验证体系、判断AI产出质量、构建可复用的能力资产——这些才是未来测试工程师真正的核心竞争力。
测试正从执行者转变为质量决策者。
最后一个问题留给你:
在你当前的测试体系中,有多少工作是可以被Skill接管的?你准备从哪个场景开始着手?




