一款能够自动检索数据、撰写深度分析并绘制专业金融图表的AI金融分析师正式登场!
近日,中国人民大学高瓴人工智能学院推出了一款面向真实金融投研场景的多模态研报生成系统——玉兰·融观(Yulan-FinSight)。该系统能够生成图文并茂的专业研究报告,全面覆盖从数据采集到视觉呈现的完整流程。
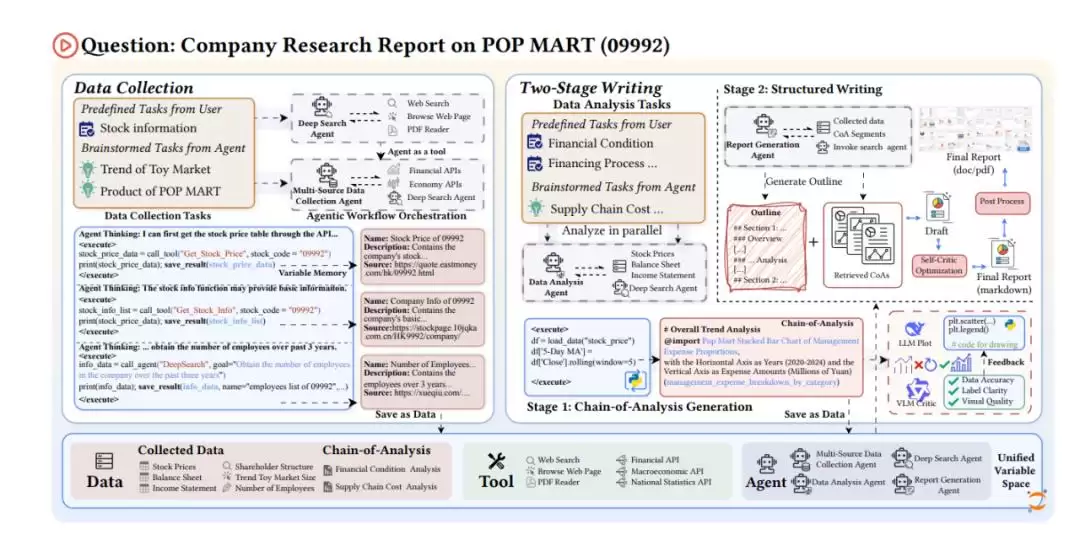
面对用户的研究需求,FinSight能够智能拆解任务,自动从互联网及金融数据库中搜集股价、财务报告、新闻资讯等多源异构数据,并生成包含“发展历程”、“核心业务架构”、“竞争格局”等章节的万字级图文分析报告。
△
该系统在AFAC 2025金融智能创新大赛挑战组的1289支队伍中脱颖而出、荣获冠军,并在多项评测中展现出超越GPT-5 w/Search、OpenAI Deep Research及Gemini-2.5-Pro Deep Research的卓越性能,其金融分析与写作能力已接近人类专家水准。

以下为您带来详细解读。
为何通用AI难以胜任金融研报?
问题的核心并非模型“不会写作”,而是金融行业的研究报告本身就是一项高度结构化、逻辑严密且依赖多模态可视化的专业级任务。其涉及的多重流程,远非简单的问答或文本生成所能比拟。
金融投研对数据的整合能力、分析深度及表达形式的要求,远超通用任务。具体而言,现有通用AI系统主要面临以下三大挑战:
1、领域知识与数据割裂:
通用搜索系统难以有效融合股价、财务报表等结构化金融数据,以及新闻、公告等非结构化信息。由于缺乏统一的数据表示与多智能体协作分析机制,系统往往只能对单一信息源进行浅层处理,难以形成系统性的金融洞察。
2、专业可视化能力缺失:
金融研报高度依赖图表来传递高密度信息。然而,现有模型大多只能生成静态图片或简单折线图,无法支持多维对比、事件标注等专业金融图表需求。同时,图文之间缺乏严格的数据一致性约束,图文无关甚至信息矛盾的情况时有发生。
3、缺乏“迭代式研究”能力:
绝大多数系统仍采用固定的“先检索、后生成”流程,研究路径一旦确定便难以调整。而人类分析师恰恰相反,他们会根据中间发现不断修正研究重点。这种基于中间结果的动态策略调整能力,正是当前通用AI系统普遍欠缺的。
FinSight的核心思路:模拟金融分析师的工作模式
为突破上述局限,FinSight并未简单地“堆砌模型”,而是从认知流程入手,模拟人类金融专家的工作方式,并提出了三项关键技术创新。
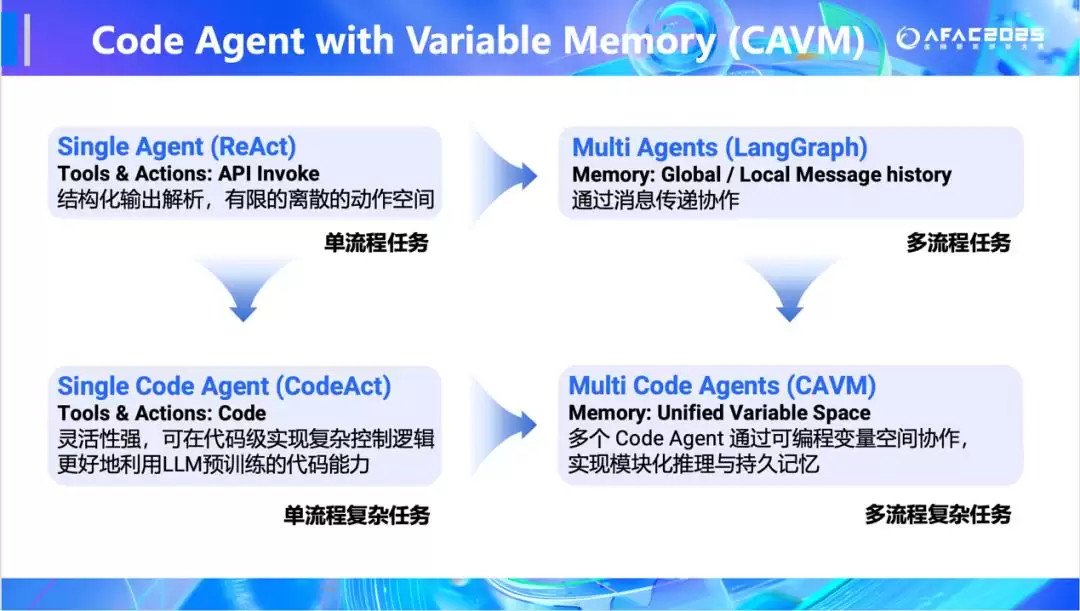
核心架构:代码驱动的可变内存智能体架构
△
FinSight底层采用了一种全新的、名为Code-Driven Variable-Memory(CA VM)的多智能体架构。现有Agent架构本质上受限于对话式记忆范式,即以消息或任务进度等历史作为状态载体。当任务复杂度与流程长度增长时,这种方式容易暴露出表达能力与可控性的结构性瓶颈。
CA VM将这一范式重构为代码驱动的变量记忆空间。系统不再以自然语言对话作为协作媒介,而是将数据、工具与中间推理结果统一映射为可读写的程序变量,由多个Code Agent通过共享变量空间完成协同推理。通过将“记忆”从消息序列提升为可操作的变量结构,CA VM使得复杂任务得以显式建模、持续修正与模块化组合,为长时程、多流程的专家级推理提供了必要的结构支撑。

△
在这一设计中,数据、工具和智能体被统一抽象为可编程变量空间:财务报表、行情数据、新闻文本作为数据变量;搜索、分析、绘图等能力作为工具变量;不同功能的Agent通过Python代码进行调度与协作。这种“以代码为中枢”的设计,使系统能够高效处理大规模异构金融数据,并支持复杂的多流程任务协作。
视觉突破:迭代式视觉增强机制
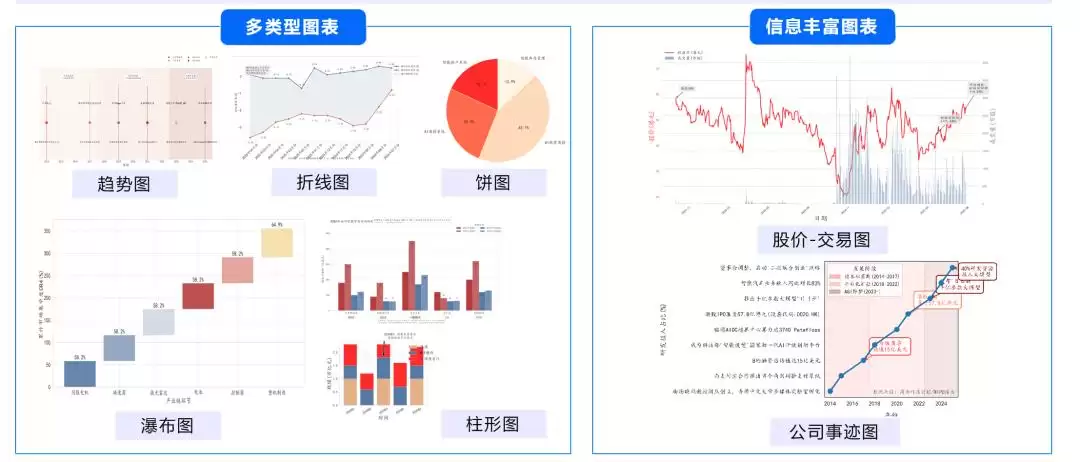
针对金融图表生成中普遍存在的专业性与可信度问题,研究团队提出了Iterative Vision-Enhanced Mechanism,将绘图过程建模为一个可迭代优化的视觉生成问题。
△
该机制采用了Actor–Critic协作范式:文本大模型作为Actor,负责生成可编译、可执行的绘图代码,充分发挥其在代码生成与逻辑控制上的优势;而视觉语言模型则作为Critic,直接对图像进行视觉层面的审视,从数据完整性与整体美观性等维度提供反馈。
这一设计的精髓在于优势互补:语言模型擅长编码与思考,却难以获取真实的视觉反馈;视觉模型具备强大的感知与判别能力,但在复杂代码生成上能力受限。通过将二者解耦并置于闭环中,系统在测试阶段通过多轮“生成—评估—修正”实现持续优化,使绘图质量随迭代次数自然提升。
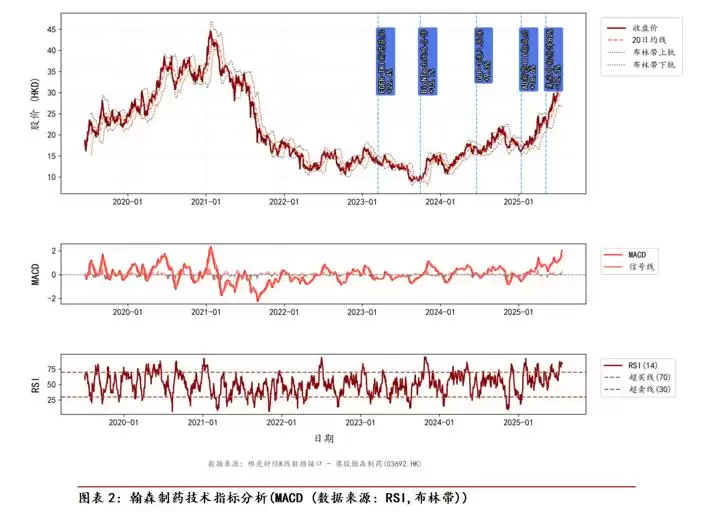
△
最终,系统能够稳定生成包含双轴对齐、事件标注以及复杂结构的专业金融图表,将原本一次性生成的静态结果,转化为一种测试时可扩展的过程。
两阶段写作框架:先分析,再成文
在写作层面,FinSight并不试图一次性生成完整的长篇研报,而是将研报写作重构为“分析—整合”的两阶段过程。
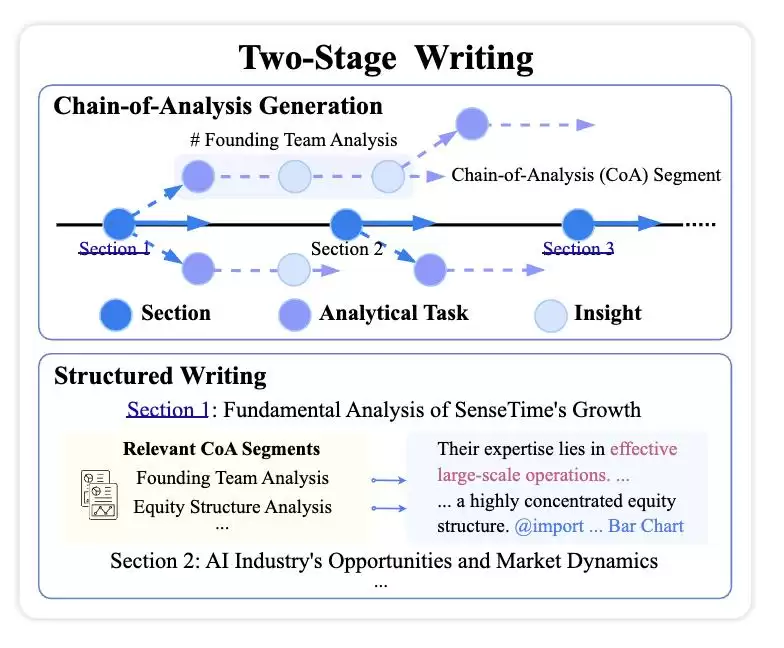
△
首先,系统生成一组“分析链”(Chain-of-Analysis,CoA):每条分析链对应一个明确的子任务(如公司历程、财务分析、竞争对手分析、风险因素等),在局部范围内完成证据收集、关键判断与核心结论提炼。这一步骤的必要性在于,一份研究报告往往由多个子问题耦合构成,若直接端到端生成长文,很难兼顾所有分析的准确性和深度。
随后,系统以这些CoA作为“骨架”,将分散的洞察在全局层面进行组织与编排,生成大纲并分章节逐步撰写。在保证章节结构与论证链条连贯的同时,将文本叙述、数据引用与图表呈现进行对齐,最终合成为一份逻辑自洽的长篇报告。这种“先分析、后写作”的策略,有效避免了长文常见的逻辑松散问题,使报告在篇幅超过2万字时仍能保持结构清晰、论证深入。
为了进一步保证长篇研报中的事实准确性与图文一致性,研究团队在写作阶段还引入了一种生成式检索(Generative Retrieval)机制。不同于传统“先检索、后生成”的后处理做法,该方法将检索过程嵌入写作本身:模型在生成具体段落时,会根据当前的分析链与写作上下文,动态生成数据和图片的索引标识符,再通过后处理统一嵌入。这样一来,引用的准确性和图文的一致性得到了最大程度的保证。
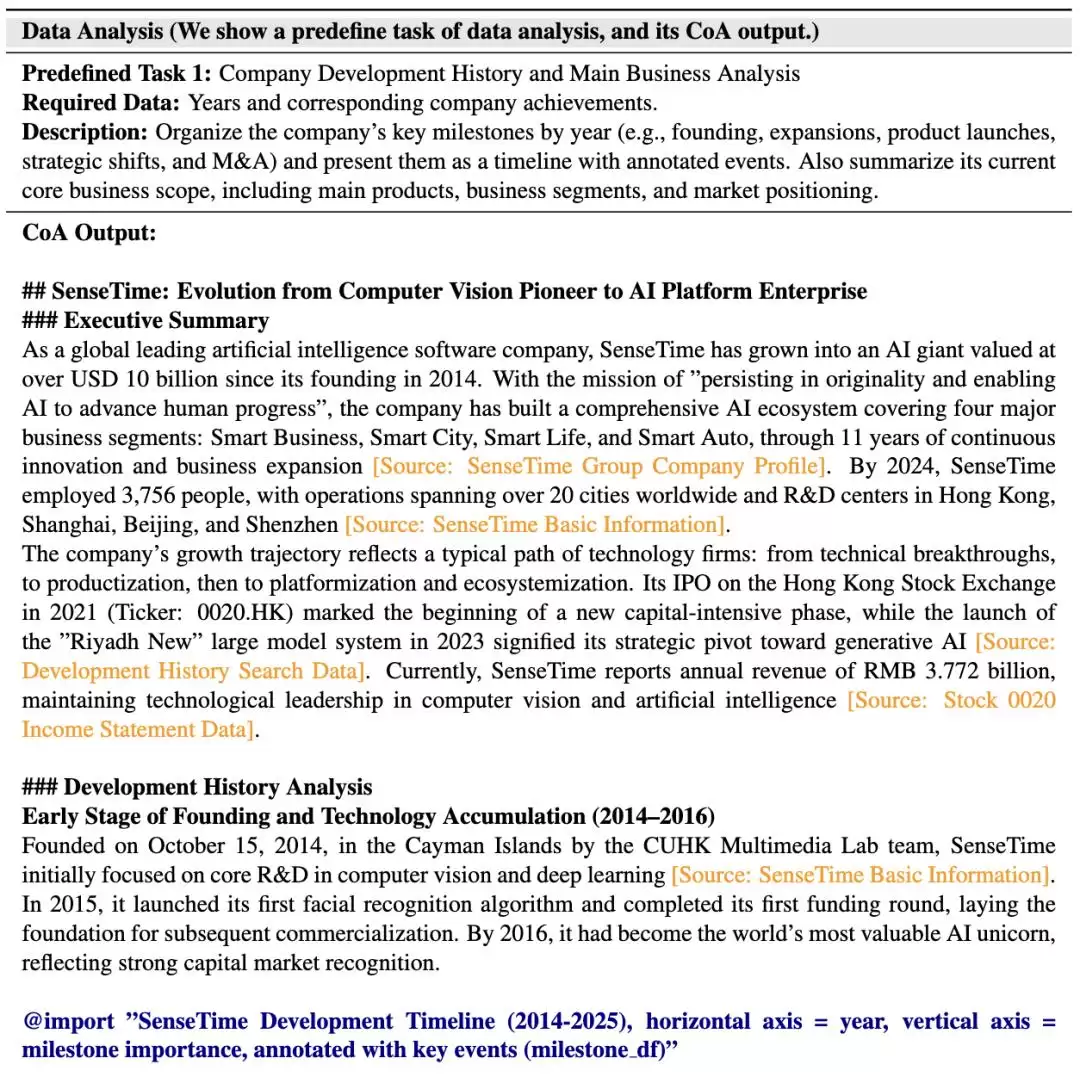
△
通过这种方式,FinSight能够在长篇写作过程中持续对齐文本叙述、数据来源与可视化结果,有效避免了常见的事实错配与图文脱节问题,从而在报告篇幅不断扩展的情况下,依然保持整体逻辑与证据链的稳定性与一致性。
实验结果:全面超越现有Deep Research系统
研究团队在涵盖公司研究与行业研究的高质量基准测试中,对FinSight进行了系统评估。
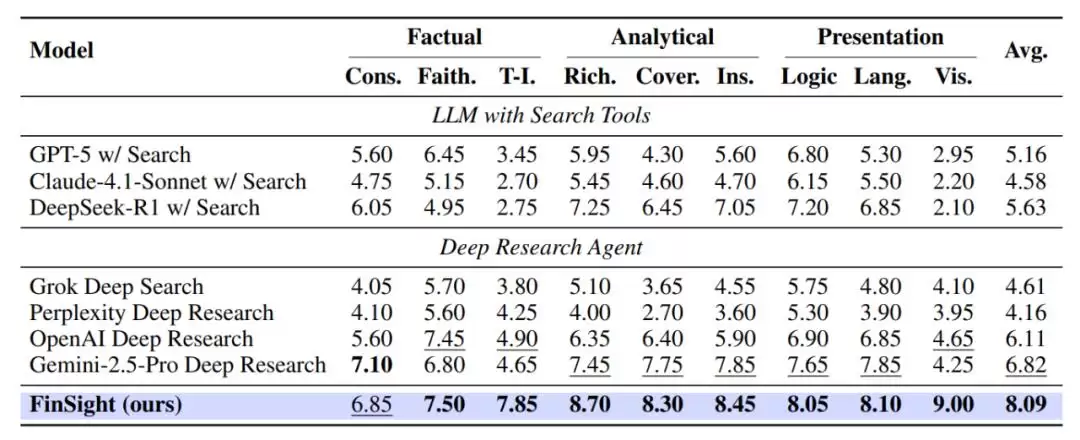
结果显示,FinSight在事实准确性、分析深度与呈现质量三项核心指标上均显著优于Gemini-2.5-Pro Deep Research与OpenAI Deep Research,综合评分达到8.09。在可视化维度上,得益于迭代式视觉增强机制,FinSight获得9.00的评分,明显领先对比系统,充分体现了其在专业金融图表生成能力上的有效提升。
而迭代式绘图的效果分析同样令人瞩目:
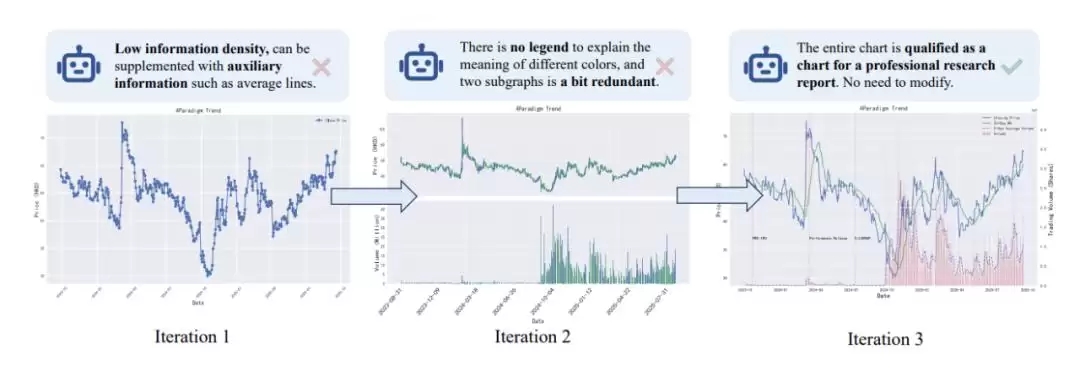
在长文本生成场景中,系统生成的研报平均长度超过20000字,包含50余张图表与结构化数据引用,且随着篇幅增长,报告质量保持稳定,未出现显著退化。
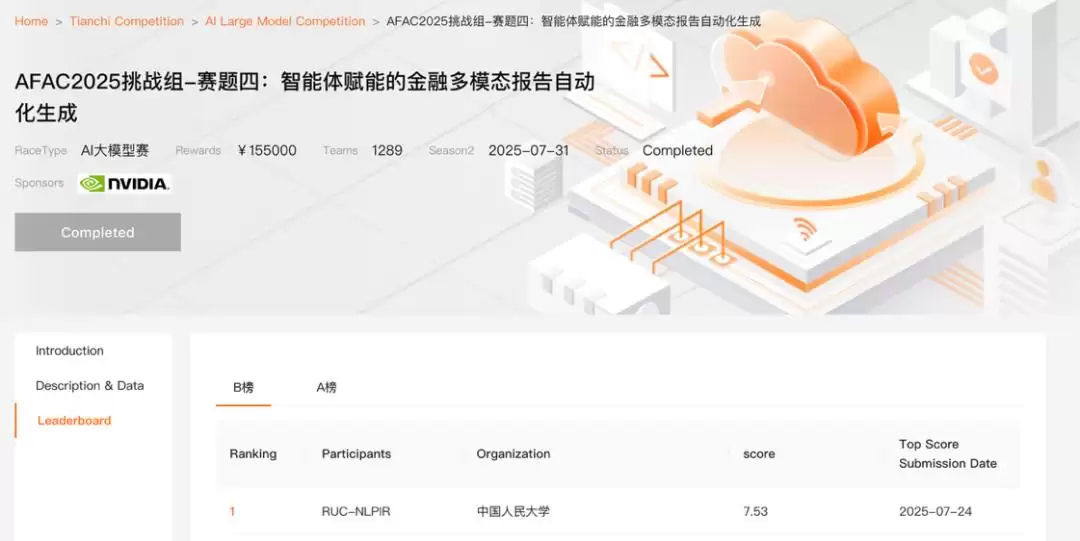
此外,在AFAC 2025金融智能创新大赛中,FinSight在来自企业与高校的1289支参赛队伍中排名第一,荣获挑战组赛题四冠军,进一步验证了其在真实场景中的实用性与鲁棒性。
FinSight不仅仅是一个金融工具,它更展示了Agent架构在高复杂度垂直领域中的巨大潜力。通过统一数据、工具与智能体,并引入视觉与写作的多阶段闭环,AI系统首次在金融投研这一“专家密集型”场景中,展现出接近人类分析师的工作能力。
这一范式的意义远不止于金融。它表明,在那些高度依赖专业知识、长时程推理与多模态表达的“专家密集型”场景中,AI系统不再只是信息汇总器,而是开始承担起类似人类专家的工作方式:分解问题、验证假设、修正结论,并最终形成可被审阅与追溯的完整成果。
从这个角度来看,FinSight更像是一个起点。随着Agent架构的不断成熟,未来的科研分析、法律研判、医疗决策等复杂领域,或将逐步迎来以专家级AI Agent为核心的新一代生产力形态。




