在上一篇关于ADK一等公民Context的文章中,我们探讨了上下文是智能体运行的灵魂。而承载这一切的核心容器,正是那个功能强大的InvocationContext。不过,为了在安全性与易用性之间找到最佳平衡,ADK对其进行了精细化的“拆分”,为不同应用场景提供了粒度各异的专用上下文对象。
要理解这种细致的分类,需要先回顾ADK的一个核心理念:发送给大模型的“工作上下文”,本质上是一个更丰富、有状态系统的编译视图。
“上下文编译器”
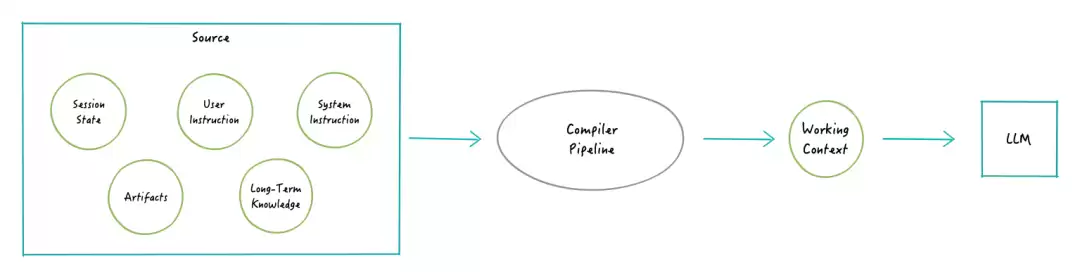
用软件工程的老话说,编译器是将高级语言源码转变为机器码的工具,过程中还要进行优化、类型检查和安全检查。ADK运行时执行的任务与此如出一辙,它就像一个“上下文编译器”。它把交互过程中产生的各种“源码”——包括持久的会话状态、临时的用户输入、检索到的外部资料、长期记忆库以及系统指令——统统“编译”成针对当前执行阶段量身定制的特定上下文对象。
这个“编译”过程必须为智能体系统的不同组件提供不同的接口(这一点在之前的文章中也曾提及)。打个比方,负责渲染系统提示词的指令提供者所需的访问权限,与一个用来修改数据库的工具,或一个用于验证用户授权的回调,是完全不同的。ADK的四种主要上下文类型——InvocationContext、ReadonlyContext、CallbackContext 和 ToolContext——正好代表了这些不同的接口。每种类型都严格遵循最小权限原则,确保各个组件只在自己该负责的“一亩三分地”内操作,最大限度地减少潜在错误或安全漏洞的“爆炸半径”。
从智能体的演变看必要性
其实,从智能体框架的发展轨迹来看,也能理解这种分离架构的必要性。早期的框架往往简单粗暴地将整个应用状态放到一个单一对象里,然后把那个“上帝对象”传递给每个函数。这样做就会带来一系列麻烦:
- 观察者效应:一个本来只想读取状态的函数(比如决定使用哪条提示词),一不小心就修改了状态,导致后续轮次的行为变得不可预测。
- 安全漏洞:那些不太受信任的组件竟然能对系统核心配置或用户身份凭证等敏感信息拥有不受限制的访问权限,这无异于给攻击者留了后门。
- 认知过载:开发者即便只是在专心处理一个小而孤立的任务,也得硬着头皮管理整个“数据宇宙”,这显然令人不堪重负。
ADK的解决思路很清晰:在上下文类型之间,将状态的可见性和可变性划分清楚。
核心对象模型
ADK的上下文架构建立在一个严格的类层次结构之上,该结构控制着功能如何继承。这不仅仅是一个实现细节,更是上述安全性和稳定性的结构性保障。
| 上下文类型 | 角色 | 继承 / 基类 | 主要作用域 | 可变性 |
|---|---|---|---|---|
| ReadonlyContext | 不可变基础 | 基类 | 指令提供者 | 不可变(状态只读) |
| CallbackContext | 观察者与拦截器 | 继承自 ReadonlyContext | 生命周期钩子(before/after agent、before/after model、before/after tool) | 可变(状态读/写) |
| ToolContext | 效应器与执行器 | 继承自 CallbackContext | 工具函数 | 可变(认证、长期记忆、工件) |
| InvocationContext | 全局编排器 | 独立 / 综合 | 智能体核心逻辑 | 完全访问(会话、服务、控制流) |
每个上下文类型,无论具体能力如何,都包含跟踪执行流程所需的基本元数据:
- 调用 ID:当前请求-响应周期的唯一标识符。这能确保日志、错误和状态更改始终可以关联到特定的用户轮次。
- 智能体名称:当前正在运行的智能体的身份。特别是在多智能体系统中,当执行从一个“路由器”传递到“专家”时,知道谁在执行与知道正在发生什么同样重要。
这种共享的身份信息保证了即使上下文对象从指令阶段的 ReadonlyContext “变形”为执行阶段的 ToolContext,操作的“血统”也是清晰可追溯的。
ReadonlyContext:不可变基础
ReadonlyContext 是面向组件的上下文层次结构的根基。它的设计理念深深植根于函数式编程原则,特别是将副作用和纯逻辑分离。
InstructionProvider: TypeAlias = Callable[[ReadonlyContext], Union[str, Awaitable[str]]]
这就是 ReadonlyContext 的典型用法:提供给 InstructionProvider 函数。
class LlmAgent(BaseAgent):
...
instruction: Union[str, InstructionProvider] = "'
...
当初始化一个智能体时,其 Instruction 参数可以是一个静态字符串,也可以是一个可调用函数。如果是函数,ADK 运行时在每一轮开始时调用它,并传入一个 ReadonlyContext,然后从 state 中获取信息来动态生成指令。
class ReadonlyContext:
...
@property
def invocation_id(self) -> str:
"""The current invocation id."""
return self._invocation_context.invocation_id
@property
def agent_name(self) -> str:
"""The name of the agent that is currently running."""
return self._invocation_context.agent.name
@property
def state(self) -> MappingProxyType[str, Any]:
"""The state of the current session. READONLY field."""
return MappingProxyType(self._invocation_context.session.state)
...
幂等性与观察者效应
ReadonlyContext 虽然也公开了会话状态,但将其包装在一个只读视图中,允许检索但严格禁止修改。这背后的目的就是防止观察者效应。举个例子,在很多动态智能体系统中,InstructionProvider 是必不可少的:
“你是一个智能辅助智能体,用户当前处于勿扰模式,有 3 个待办任务。你的职责是帮助用户有效地管理这些任务,包括列出任务、设置优先级、提供提醒、建议完成步骤、跟踪进度,并根据用户的输入更新任务状态。”
这条指令需要读取状态才能生成。如果提供给这个指令生成器的上下文是可变的,开发者一个不留神就可能写出类似 if user.status == 'do_not_disturb': user.clear_all_tasks() 的代码。这种操作仅仅在“观察”时就已经把状态改了。而 ReadonlyContext 的不可变性保证了运行时可以多次重新生成指令,而不会意外改变智能体的记忆或执行轨迹。
CallbackContext:可观察的过渡
沿着能力阶梯向上,CallbackContext 扮演了ADK“拦截器”的角色。
class CallbackContext(ReadonlyContext):
...
self._state = State(
value=invocation_context.session.state,
delta=self._event_actions.state_delta,
)
def state(self) -> State:
"""The delta-aware state of the current session.
For any state change, you can mutate this object directly,
e.g. `ctx.state['foo'] = 'bar'`
"""
return self._state
...
CallbackContext 直接继承自 ReadonlyContext,保留了所有身份和读取能力,但扩展了API以支持:
- 可变状态访问:重写了
state属性,返回一个可变的State对象。这意味着在回调中可以修改会话状态,这些修改会被记录为delta,以便后续更新 Session。 - 工件管理:与 Artifact Service 交互的方法,用于处理文件/工件。
- 凭据管理:与 Credential Service 交互的方法,用于处理认证信息。
- 记忆管理:与 MemoryService 交互,可以将当前 Session 的事件保存到长期记忆服务中。
CallbackContext 的主要架构目标是通过面向切面编程的理念,实现“纵深防御”。在复杂的智能体工作流中,仅靠大模型是不够的。回调提供了一个确定性的、基于代码的强制层,包裹着模型那概率性的输出。
ADK 定义了几个注入 CallbackContext 的特定生命周期钩子:
- before_agent_callback
- after_agent_callback
- before_model_callback
- after_model_callback
- before_tool_callback
- after_tool_callback
这些回调共同构成了ADK的可观测性和可控制性基础,让开发者可以在不修改核心业务逻辑的前提下灵活地扩展智能体的行为。例如,对于 agent 相关的钩子,before 用于“预判与拦截”,after 用于“补充与收尾”,两者结合赋予了开发者对智能体执行流的精细控制。
ToolContext:安全执行边界
ToolContext 是上下文中最专业、也最强大的一个。它是专门为“效应器”设计的——也就是智能体调用去与外部世界交互的那些工具和函数。它代表着智能体离开文本生成的安全区,去对现实系统执行操作的边界。
ToolContext 继承自 CallbackContext。这条继承链在架构上意味深长:
ReadonlyContext的能力:它知道谁调用了它(身份)。CallbackContext的能力:它可以改变状态并保存工件(可变性)。ToolContext的能力:它添加了用于 I/O 和外部交互的特定方法。
class ToolContext(CallbackContext):
...
def actions(self) -> EventActions:
return self._event_actions
def request_credential(self, auth_config: AuthConfig) -> None:
if not self.function_call_id:
raise ValueError('function_call_id is not set.')
self._event_actions.requested_auth_configs[self.function_call_id] = (
AuthHandler(auth_config).generate_auth_request()
)
def get_auth_response(self, auth_config: AuthConfig) -> AuthCredential:
return AuthHandler(auth_config).get_auth_response(self.state)
async def search_memory(self, query: str) -> SearchMemoryResponse:
"""Searches the memory of the current user."""
if self._invocation_context.memory_service is None:
raise ValueError('Memory service is not a vailable.')
return await self._invocation_context.memory_service.search_memory(
app_name=self._invocation_context.app_name,
user_id=self._invocation_context.user_id,
query=query,
)
...
它的特有功能包括:
- 认证:提供方法让工具可以动态处理OAuth流程和安全API的访问,将认证逻辑从工具的业务逻辑中解耦出来。
- 记忆搜索:使工具能够主动查询智能体的长期记忆库(例如向量数据库),以获取相关上下文。这让工具可以说“找到我们上周讨论的记录”,而不需要大模型去胡乱猜测文件路径。
- 事件动作:访问
actions属性可以让工具发出系统性变更的信号,比如跳过调用LLM来总结函数响应,或者通过requested_tool_confirmations请求用户介入。
安全边界:模型参数 vs. 开发者上下文
使用 ToolContext 能够实现模型提供的参数与开发者提供的上下文的严格分离,这直接解决了提示注入和幻觉的风险。
当大模型调用工具时,它根据训练和当前的提示词生成参数。但这些参数本质上就是不可信输入。它们源于一个概率模型,且很容易被恶意用户操纵。然而,ToolContext 是由框架注入的,模型根本“看不到”也“改不了”它。这种分离创造了一种基于能力的安全性。ToolContext 使用的是可信的开发者上下文,而不是大模型生成的、不可信的指令。
弥合差距:无状态工具问题
传统上,工具被认为是不带状态的纯函数:输入 -> 输出,无法对更广泛的会话上下文做出反应。但 ToolContext 让工具具备了状态感知能力。例如,工具可以从 ToolContext 中获取 session_id,然后使用这个ID去外部API获取数据,将完整的写入 state 中,最后只向LLM返回一个简短摘要,从而减少token消耗。
InvocationContext:全局编排器
ReadonlyContext、CallbackContext 和 ToolContext 是为特定组件设计的专用视图,而 InvocationContext 则是执行周期上的“上帝对象”,它代表了单轮运行期间运行时的综合状态。
InvocationContext 直接传递给所有智能体父类的 _run_async_impl 方法。它是核心智能体逻辑与运行时环境交互的接口。其关键组件覆盖了智能体有效运转的方方面面:
session:对完整Session对象的引用,包含完整事件历史、当前状态和所有交互数据。agent:对当前运行智能体自身的引用,允许逻辑检查其自身配置。branch:调用的分支路径。invocation_id:当前轮次的唯一 ID。user_content:来自用户的原始、未处理的输入。- 对已配置基础设施服务的直接引用:
artifact_service(工件服务)、session_service(会话服务)、memory_service(记忆服务)、credential_service(凭据服务)。 end_invocation:一个布尔标志,可以通过它向运行时发信号立即停止处理。
编排循环
InvocationContext 是整个编排过程的载体。当ADK运行时开始一轮交互时,它会实例化这个上下文,然后交给根智能体。
总结
Google ADK 的上下文架构,代表了构建AI智能体的一种成熟的系统工程方法。它坚决摒弃了早期大模型开发中那种“单一可变状态”的模式,转而强制执行一套符合既定软件工程原则的规范结构。
ReadonlyContext为指令生成带来了函数式编程的安全性。CallbackContext为智能体生命周期带来了面向切面的可观察性。ToolContext为外部执行带来了基于能力的安全。InvocationContext为运行时循环带来了分布式系统的编排能力。
对开发者而言,深入理解并熟练运用这些上下文类型,正是从构建“玩具”原型迈向打造生产级系统的关键一步。它让你能够构建出在设计上安全、推理上幂等、执行上可观察的智能体。上下文不再仅仅是智能体“知道”什么,它严格定义了智能体“是”什么,以及它能安全地做什么。
参考资料
[1] 特定生命周期钩子: https://google.github.io/adk-docs/callbacks/types-of-callbacks/




