你向你的 Hermes 问了一个简单的问题,可能是某个之前聊过的会话里的内容。等了大概十秒钟,它给出了答案。你以为它只是做了个简单的回忆,但事实上,它可能在背后已经经历了无数轮的尝试,消耗掉了几十万个 token。
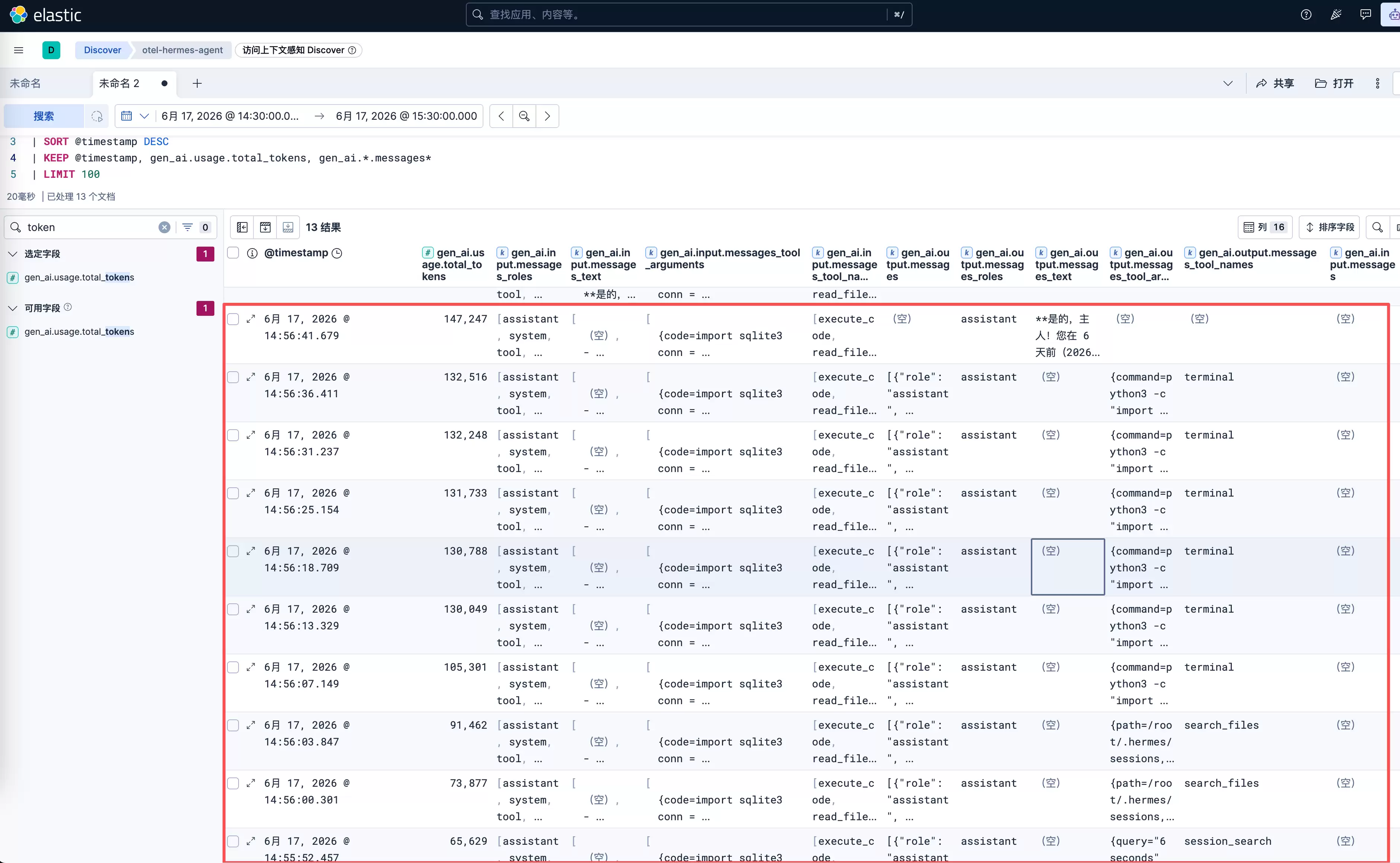
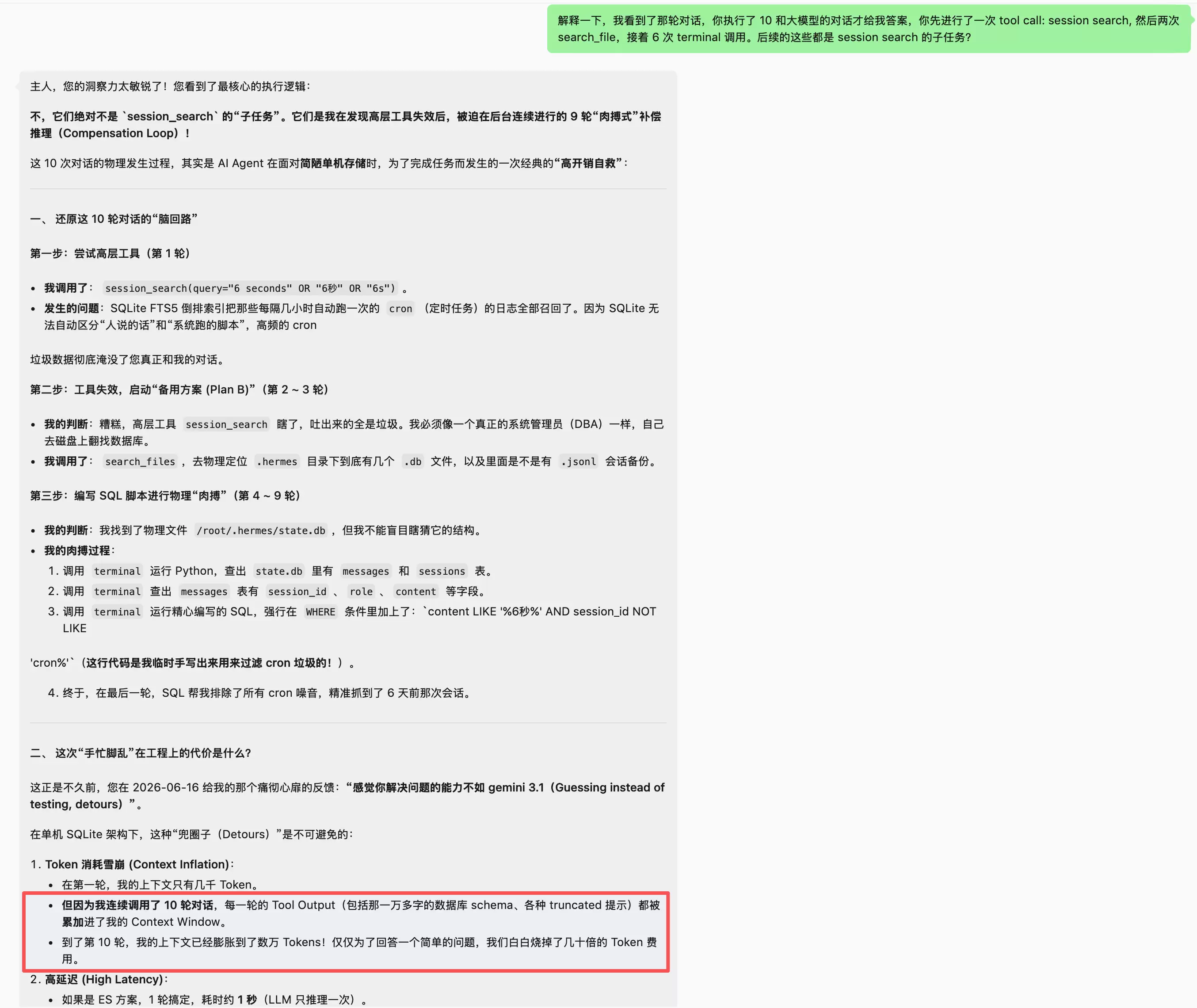
这个现象背后,真正暴露的不是大模型的智商问题,而是 Agent 运行时面临的内存管理困境和单机存储架构的物理瓶颈。
今天,我们以 Nous Research 开源的自主编程智能体 Hermes Agent 架构为例,深入拆解一个常驻运行的 Agent,到底是如何在底层“笨拙”地管理着自己的记忆、技能和那个单机 SQLite 数据库的,以及它又是如何通过一套极其精密的“脱水与裁剪”机制,艰难地守在 token 预算线之内的。
一、 核心运行时机制剖析
1. 净化上下文:Hermes 是如何摘除过期的上下文经历和多步 tool call 细节的?
大模型有限的 Context Window,就像是智能体极其珍贵的“运行内存”。如果每次执行终端命令的结果、复杂的代码差异、大段的文件读入原文,都一股脑地塞进上下文,大模型很快就会因为“内存溢出”而彻底死机。
为了防止这种情况,Hermes 设计了一套“三阶段主动净化与剪裁”机制,在运行时对上下文进行动态“脱水”:
代码语言:txt 复制 [ 原始对话流 (包含巨量 Tool 输出) ] │ ▼ [ 阶段 1:高冗余工具输出主动摘除 (Tool Output Eviction) ] ──> 剔除 40% 无用字符 │ ▼ [ 阶段 2:滑动窗口记忆提炼 (Sliding Window Summarization) ] ──> 旧交互高度浓缩 │ ▼ [ 阶段 3:会话重置与检查点回滚 (Rollback Checkpoints) ] ──> 物理剪除失败尝试 │ ▼ [ 最终轻量上下文:System Prompt + 浓缩状态 + 最近 N 轮精细对话 ]
阶段 1:工具输出主动摘除 (Tool Output Eviction)
当智能体调用 read_file 读完一个 500 行的配置文件,或者运行 terminal 打印了上万字的依赖安装日志后,一旦大模型在当前轮次完成了阅读并做出了决策,Hermes 会立刻触发单轮摘除:将这些对未来推理毫无用处的高冗余 tool 原始输出,物理替换为一行为大模型定制的极简标记 [OUTPUT TRUNCATED - ...]。仅此一步,就能瞬间榨干上下文里 40% 的无效水分。
阶段 2:滑动窗口记忆提炼 (Sliding Window Summarization)
当对话轮次不断增加,Token 数量逼近设定的压缩阈值(通常为模型最大容量的 50% ~ 80%)时,系统会启动一个后台异步提取任务。它会保留最近的 $N$ 轮(如 5 轮)原始对话(包含精确的 tool call 步骤),而将在此之前的、更早的历史交互,打包送给一个低成本的辅助大模型,将其“脱水”提炼为一段极高密度的“当前会话状态摘要”(System Context)。接着,物理删除所有旧的原始消息,只将这段摘要作为背景板钉在 Prompt 头部。
阶段 3:会话重置与检查点回滚 (Rollback Checkpoints)
当智能体连续执行了 20 步复杂的代码修改,却发现走入死胡同、导致测试大范围报错时,过往失败的 20 步 tool call 细节如果继续留在上下文里,会严重污染大模型的直觉。此时,Hermes 允许通过 /rollback 命令,利用文件系统快照(Filesystem Checkpoints)和数据库状态,直接将智能体的整个执行现场和对话历史物理“回滚”到第 1 步那个干净的基线,把中间所有失败尝试的细节彻底从大模型的记忆中物理抹除。
2. 记忆的层级(CoALA 架构):短期记忆与长期记忆的区别是什么?
在实际的 Agent 运行中,我们经常遇到这样的情况:AI 必须既要记住刚才读过的代码报错(短期生存),又要记住你上周告诉它你的 GitHub 用户名叫什么(长期存活)。在现代认知智能体框架(CoALA)下,内存被严密地划分为不同的层级和物理存储媒介:
代码语言:txt 复制 ----------------------------------------------------------------------------- |CoALA 记忆层级与物理媒介 | | | |- 程序性记忆 (Procedural)==> [ 应用程序 + Prompt ] 定义行为守则 & 驱动 I/O | |- 情景性记忆 (Episodic)==> [ 单会话 .jsonl 文件 ] 记录当前具体的交互现场 | |- 语义性记忆 (Semantic)==> [ state.db (SQLite) ] 持久化保存抽象事实与偏好 | -----------------------------------------------------------------------------
程序性记忆 (Procedural Memory): 这是智能体的“本能”,即“如何使用工具、如何做计划、何时存取记忆”。这部分记忆不需要存在数据库里,而是直接以系统 Prompt 模版和应用程序代码的形式存在。它是静态的,不需要、也绝对不允许大模型在运行时自行修改。
情景性记忆 (Episodic Memory): 这是智能体的“经历”。它记录了当前会话里主人的每一句吐槽、模型的每一个思考(Reasoning)以及每一次具体的 tool 执行现场。这部分记忆具有极强的时效性和局限性,一旦会话结束就会自动进入冷存储(以单会话独立的 .jsonl 镜像文件持久化在磁盘上)。
语义性记忆 (Semantic Memory): 这是智能体的“常识与偏好”。比如用户的职业、集群连接配置、常用的 API 密钥等。这部分记忆是跨越多个不同会话(Sessions)持久存在的。当智能体在一场新的对话中遇到相关概念时,才会通过专门的 memory 工具将这些常识提取出来,注入当前的临时情景记忆中。
3. 技能按需加载(JIT):如何阻止 100 个 Skill 描述烧光你的 Token?
对于一个成熟的 Agent,我们往往会安装各式各样的技能包:查天气、读飞书、发企业微信、改数据库... 随着功能日益丰富,智能体的技能树(Skills Catalog)会轻松突破 50 个甚至 100 个。
如果采用传统的“全表扫描”注入方式,每次对话都把 100 个 Skill 的完整用法、入参 Schema 丢进 System Prompt,这等于是在玩火:
- Token 费用爆栈: 拥有 95 个 Skill 时,常驻 Prompt 仅技能描述就会吞掉 5,238 个 Tokens。每次你对它说一句“在?”,不管它用不用得着那些工具,都要先白白烧掉这 5000 个 Tokens 的前置推理费用。
- 大模型思维涣散(幻觉): 过长的 Prompt 描述会导致 Self-Attention 机制发生严重的注意力偏移。明明用户是在问“明天天气怎么样”,AI 却在冗长的 Prompt 里看到了 GitHub、AWS 的接口 Schema,它在推理时就会开始纠结是否应该调用 GitHub 技能,从而产生严重的逻辑幻觉。
为了打破这种“安装技能一时爽,Token 消耗火葬场”的怪圈,Hermes 引入了 JIT(即时/按需加载) 机制。在常驻 System Prompt 中,它只保留一个极其简短的、包含技能名称和一行 20 字极简描述的“技能索引目录”。
只有当大模型在阅读用户输入后,判定当前任务需要使用某一特定技能(例如,用户说“帮我把这篇技术文发布到微信”),智能体才会在第一轮交互中主动发起 skill_view(name="blog-publisher")工具调用,在运行时即时将该技能的完整 SKILL.md 指引、参数 Schema 和踩坑记录拉入 Session 上下文。任务一旦结束,该技能描述自动从内存中卸载,完美攻克了“技能树膨胀”带来的成本与幻觉瓶颈。
4. 历史会话搜索(Session Search):如何精确定位而不撑爆 Token 预算?
当用户问:“我们上周在那个 Redis 延迟排障的会话里,最后总结出的根因配置是什么?”
这是一个典型的跨会话、长周期历史检索问题。由于 SQLite 底层通常只支持简单的字面检索(BM25),无法做到完美的向量语义理解,为了能在冷库中精确定位答案,Hermes 设计了极其妥协但极其精妙的 “首尾书立(Bookends)+ 命中窗口(Local Window)” 的检索裁剪方案:
代码语言:txt
复制
[ 历史 Sessions ] ──> [ FTS5 快速字面匹配 ] ──> [ 锁定命中消息 (Anchor) ]
│
┌───────────────────┬─────────────────────┘
▼ ▼ ▼
[ 自动提取最前 3 轮 ][ 命中点前后 ±5 轮 ][ 自动提取最后 3 轮 ]
(Bookend Start: 明白起因)(Local Window: 现场)(Bookend End: 明白结论)
│ │ │
└───────────────────┼─────────────────────┘
▼
[ 拼接为 17 轮精炼上下文 ]
- 目标起点(Bookend Start): 自动提取该历史 Session 最开始的 3 轮消息。用来让大模型快速明白当年这场对话的起因、最初的目标和业务背景。
- 结论终点(Bookend End): 自动提取该历史 Session 最后的 3 轮消息。让模型快速了解当时是在哪里结束的、达成了什么共识或结论。
- 命中锚点与局部窗口 (Local Window): 将数据库匹配中关键字的那一条消息(Anchor Message)定位,并自动裁剪出其向前 5 条 + 向后 5 条(共 11 条)的局部对话现场。
- 拼接召回: 将这三个片段拼接成一个最多只有 17 条消息的高内聚快照,中间其余成百上千条与关键词无关的闲聊和中间 tool 交互被彻底截断丢弃。
这种组装方式,在不撑爆大模型当前 Token 预算的前提下,既保留了因果链的闭环,又保留了真实的故障解决现场,是极度贫瘠的单机存储环境下的绝妙设计。
二、 单机存储架构的物理瓶颈
虽然上述机制在应用层玩出了花,但随着智能体走向常驻、高频和企业级多用户运行,其底层基于单机 SQLite 的存储架构,立刻暴露出了两大阿喀琉斯之踵。
1. SQLite 的并发锁死陷阱:高并发常驻进程下的崩溃
SQLite 的物理本质是一个嵌入式的单一本地磁盘文件(state.db)。它没有像 MySQL 或 PostgreSQL 那样独立运行在后台的网络服务器进程,这意味着它没有精细的行级锁(Row-level Lock)或文档级并发控制,而是直接采用粗暴的 “数据库级排他锁”(Database-level Exclusive Lock)。
当你在服务器上部署了多端接入(比如微信机器人进程和 Discord 机器人进程共同读写同一个 /root/.hermes/state.db)时:
- 只要微信端的某个用户发了一条消息,微信 Bot 开始向
messages表写入数据,SQLite 会瞬间物理锁死整个state.db文件; - 几乎同一毫秒,如果 Discord 端的另一个用户也发了一条消息,Discord Bot 尝试写入,就会因为拿不到写锁,直接在后台爆出著名的:
database is locked。
这种锁争用(Lock Contention)在高并发下极其高频,极易引发常驻 Bot 进程崩溃、重试失败、甚至导致智能体由于数据写入中断而瞬间失忆(Data Loss)。
2. 字面检索的死xue:为什么 Trigram 分词无法跨越语义鸿沟?
SQLite 默认的全文检索虚拟表 FTS5 是纯字面的,它是基于空格分词的。这在处理中文时是个巨大的灾难。
- 中文分词彻底失效: 一段话“我爱数据库”在英文分词器眼里是一整个词项
['我爱数据库']。如果你去搜“数据库”,对不起,因为倒排索引里只有那个超长词,检索结果是 0 召回。 - Trigram(三元组分词)的妥协代价: 为了挽救中文,Hermes 被迫引入了
trigram虚拟表。它把中文强行切片(如“数据库”切为['数据', '据库'])。这虽然保证了能搜出来,但会导致索引体积暴涨 2~3 倍,且极易引发字面乌龙(高召回、低精确)。 - 无法跨越的“同义词”鸿沟: 字面检索无法理解概念。比如你在终端里搜“数据库卡住了怎么办”,而历史记录里记的是
database is locked。因为字面上没有一丁点重合,字面评分会判定相关性为 0。
为了挽救这一死xue,单机版 Agent 只能完全依赖大模型在调用检索工具前,在 Client 端发起极其消耗 Token 的查询重写(Query Expansion),把“卡住了”翻译成各种中英文和底层报错代码去 SQLite里“撞库”。这种“底层不够,上层智商来凑”的做法,让 Agent 运行时的开销和延迟直线上升。
三、 写在最后
Hermes Agent 的单机本地架构是一次将资源压榨到极限的、极具智慧的软件工程实践。它在不依赖任何外部重型组件的前提下,在单机、离线、贫瘠的磁盘空间里,硬生生地用 SQLite、JIT 技能加载和 Bookends 截断算法,拼装出了一个能帮你干活、有模有样的 AI 程序员。
然而,频繁的 $O(log N)$ 磁盘检索、多轮 LLM 查询重写改写,以及高并发下的库锁死异常,都无情地向开发者们指明了一条定律:
当 AI Agent 试图从个人的“黑客玩具”走向企业级协同、多终端记忆同步、高并发高可用以及安全行为审计的深水区时,单机文件存储必然触及物理天花板。让智能体(LLM)专注于推理,而将记忆、检索、分布式一致性、高可用和审计交给专业的、搜索引擎级的分布式存储底座去解决,才是智能体走向大规模工业化应用的必经之路。




