在AI图像生成与编辑领域,云端大模型长期占据主导地位,但其高延迟和对云端算力的依赖,使移动端部署面临挑战。近日,字节跳动智能创作实验室推出DreamLite模型,参数量仅0.39B,却能在小米14等手机上,1秒内完成1024×1024分辨率图像的生成或编辑。此举直接突破了端侧AI图像处理的技术瓶颈。

相关链接:
- 论文:https://arxiv.org/abs/2603.28713
- 主页:https://carlofkl.github.io/dreamlite
- 仓库:https://github.com/ByteVisionLab/DreamLite
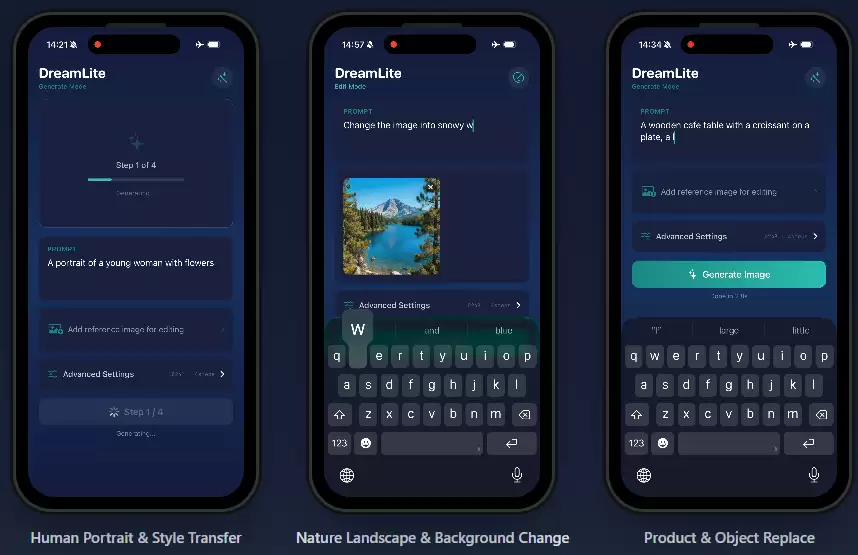
论文解读

DreamLite直指端侧AI图像处理的两大痛点:高延迟与功能单一。以往的端侧模型要么仅支持图像生成,要么需额外部署编辑模型,导致系统臃肿、资源占用高。而DreamLite通过统一模型同时实现生成与编辑功能,核心依赖轻量化架构、In-Context条件统一机制、任务渐进式联合预训练,以及后训练优化与步数蒸馏等关键技术。
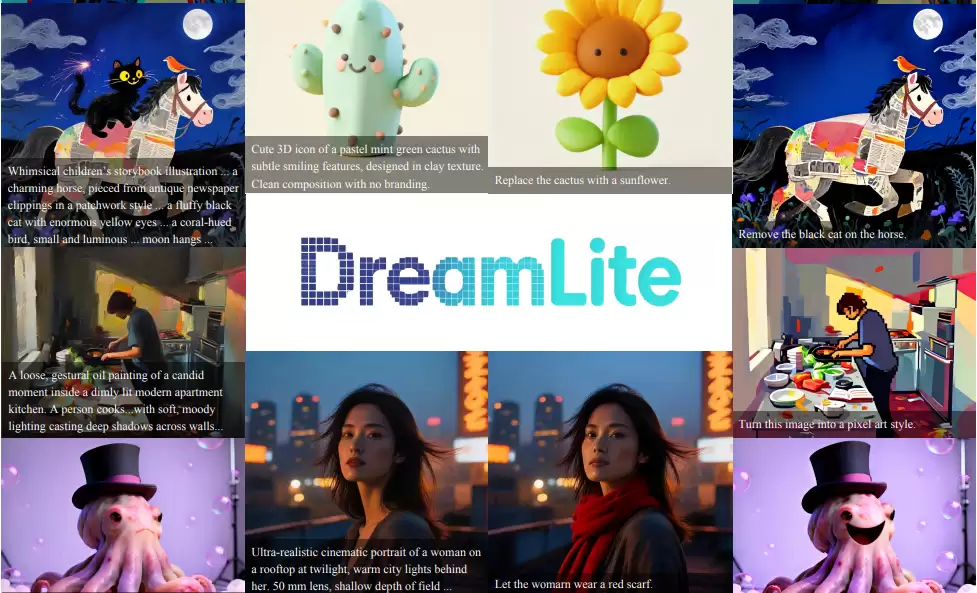
技术方案

轻量化架构设计
DreamLite基于SnapGen大幅精简,压缩了U-Net骨干网络。具体措施包括:减少Transformer模块数量、缩减通道维度、去除高分辨率阶段的Self-Attention、引入深度可分离卷积与Multi-Query Attention。最终参数量从2.5B降至0.39B。编码部分采用极轻量的TinyVAE(仅2.5M参数),文本编码器选用Qwen3-VL-2B,在显著降低计算量的同时,保持了优秀的性能表现。
In-Context条件统一机制
这一设计颇具创新。DreamLite未沿用传统的InstructPix2Pix方案,而是在latent空间中,将目标图像与条件图像沿宽度方向水平拼接。通过空间维度拼接与任务token路由,无需额外参数即可实现任务统一。进行文生图时,条件面板放置空白图像;进行图像编辑时,则放置源图像。任务token([Generate]与[Edit])充当轻量级路由器,精准指引模型执行对应操作。
任务渐进式联合预训练
预训练分三个阶段:首先训练T2I,随后激活In-Context条件进行编辑训练,最后融合T2I与编辑数据统一训练。此过程采用前景聚焦掩码,有效解决编辑任务中目标区域过小、背景梯度信号过强的问题,确保模型对微小编码变化足够敏感,训练过程更加稳定。
后训练优化与步数蒸馏
- 后训练优化:结合监督微调(SFT)与强化学习(RL),进一步提升模型的稳定性与性能。
- 步数蒸馏:利用Distribution Matching Distillation (DMD2)将采样步数压缩至4步,实现快速推理,同时保持较好的生成质量。
实验评估

图像生成实验
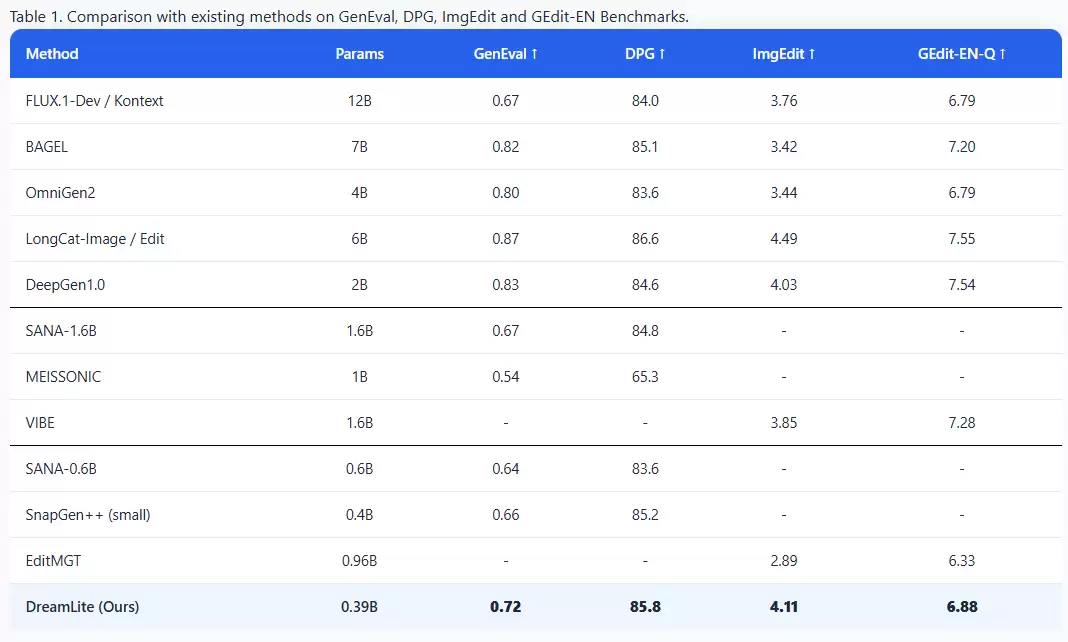
在GenEval与DPG基准测试中,DreamLite分别获得0.72和85.8的成绩,不仅领先所有端侧模型,甚至超越FLUX.1-Dev 12B、SANA-1.6B等服务器端大模型。在颜色属性、位置子项上同样表现优异,充分证明了其在复杂场景、风格控制及多物体关系处理方面的强大能力。
图像编辑实验
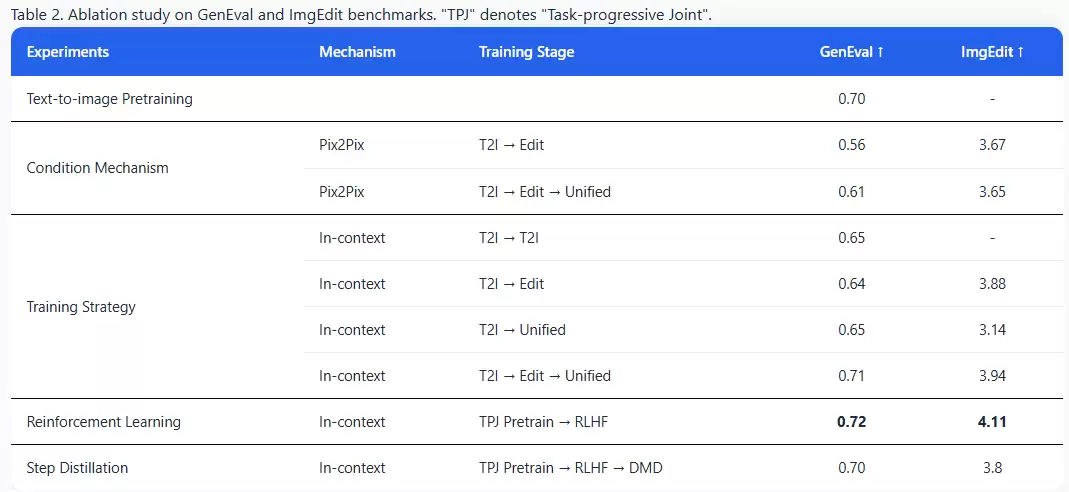
在ImgEdit基准上,DreamLite取得4.11分,超过FLUX.1 Kontext-Dev 12B与BAGEL 7B等大模型;GEdit-EN基准也达到6.88分。消融实验进一步验证了In-Context条件统一机制、任务渐进式联合预训练及后训练优化的有效性,每项设计都为性能提升做出了切实贡献。
总结
DreamLite凭借轻量化架构、In-Context条件统一、渐进式联合预训练及后训练优化等创新设计,在端侧AI图像处理领域交出了令人瞩目的成绩。多基准测试中的优异表现,结合移动端设备的实时处理能力,表明其技术路线选择稳健可靠。随着代码与模型权重陆续开源,端侧AI图像生成与编辑的普及速度,或许将远超我们的预期。




