近日,深圳市大数据研究院四项重要科研成果被第43届国际机器学习大会(ICML)录用。这四篇论文覆盖了零阶优化、大模型微调、长视频推理等多个前沿方向,方法创新突出。本文将逐一解读,看看这些工作究竟解决了哪些实际难题。
会议介绍
ICML是人工智能领域公认的顶级学术会议,与NeurIPS、ICLR并称机器学习三大顶会,属于CCF A类推荐会议。本届ICML共收到23,918篇有效投稿,录用率约为26.6%,竞争极为激烈。会议涵盖机器学习基础理论、深度学习、优化方法、可信机器学习等核心方向,同时关注计算机视觉、语音识别等应用领域。
论文简介

AdaMeZO: Adam-style Zeroth-Order Optimizer for LLM Fine-tuning Without Maintaining the Moments
关键词:大语言模型微调、零阶优化、优化器、内存效率
摘要:大语言模型微调在特定任务上效果显著,但传统的基于反向传播的一阶优化方法需要计算并存储梯度,显存开销巨大,资源受限设备难以应对。已有的零阶方法MeZO仅通过前向传播就能微调,大幅降低了显存需求,但其更新方式类似SGD,无法感知不同参数维度的损失曲率差异,收敛速度偏慢。直接引入自适应优化器如Adam虽然能提升收敛效率,却需额外存储与模型参数规模相同的动量信息,零阶优化的内存优势不复存在。
针对这一矛盾,论文提出AdaMeZO——一种融合Adam风格的零阶优化器。其核心思路是利用截断历史梯度构造近似的一阶和二阶矩估计,同时引入更细粒度的伪随机数生成器状态缓存机制。仅在更新参数时按块原地重建历史随机方向,无需在显存中长期维护完整动量向量。这样既保留了MeZO的低显存优势,又赋予了类似Adam的自适应预条件更新能力,能更好地适应复杂损失函数中不同曲率的区域。
理论分析表明,在非凸优化假设下,AdaMeZO能以O(1/√T)的速率收敛到平稳点附近。在RoBERTa、OPT、LLaMA等模型及多种NLP任务上的实验显示,AdaMeZO在多个任务上优于MeZO及相关强基线,达到相同终止损失时最多可减少约70%的前向传播次数;实际额外显存仅约7%,远低于需要显式存储矩估计的方法(50%–100%)。这项研究为低显存环境下的LLM高效微调开辟了新途径。
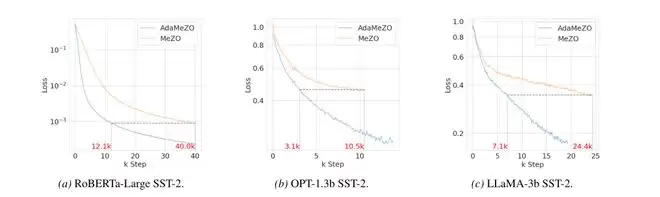
图1:AdaMeZO与MeZO在SST-2任务上的损失曲线对比。AdaMeZO在RoBERTa-large、OPT-1.3B和LLaMA-3B上达到MeZO终止损失时,前向传播次数分别减少69.75%、70.48%和70.90%。
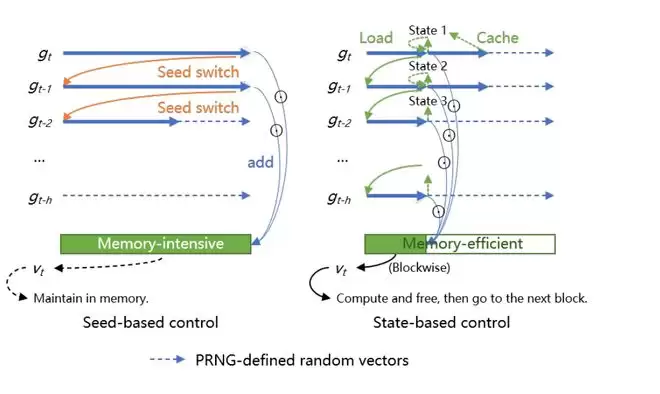
图2:AdaMeZO的分块矩估计机制。基于PRNG状态缓存的分块控制可在计算并释放一、二阶矩后进入下一参数块,从而减少额外显存。
论文第一作者蔡智捷与共同第一作者陈浩泷为深圳市大数据研究院-香港中文大学(深圳)联合培养博士生,通讯作者为深圳市大数据研究院研究员朱光旭博士。

Romberg-Extrapolated Zeroth-Order Gradient Estimator: Higher-Order Bias Reduction with Preserved Leading Directional Variance
关键词:零阶优化、梯度估计、龙贝格外推
摘要:在许多现代学习与优化场景中,梯度计算成本太高甚至不可获得,只能通过函数值查询来估计梯度。标准梯度估计存在偏差与方差之间的权衡,现有改进方法难以同时优化两者。本文提出Romberg-ZOGE方法,通过多尺度两点估计结合Romberg外推,在降低偏差的同时保持方差不增。
理论上,Romberg-ZOGE可实现高阶偏差缩减,且不增加主导方差。对于确定性函数评估,它在多个半径上构造两点估计并加权,将偏差从O(r²)降至O(r^(2R+2)),而主导方向方差与标准两点估计器一致。针对ZO-SGD的随机函数查询,同次梯度估计的多查询共享随机样本,噪声可在差分与外推过程中抵消,避免额外放大,收敛复杂度不劣于基线。
实验覆盖三类场景:合成函数实验中,R=2时偏差呈接近O(r⁶)下降,远优于标准两点估计器的O(r²),且主导方差与基线相近;优化实验中,相同查询预算下收敛更快更稳定;无线网络优化任务中,提升了平滑分位数频谱效率目标值;OPT-1.3B的SST-2黑箱prompt tuning任务中,取得最低训练损失及最高验证、测试准确率。结果表明,Romberg-ZOGE既具备理论优势,又能为实际黑箱优化带来稳定收益。
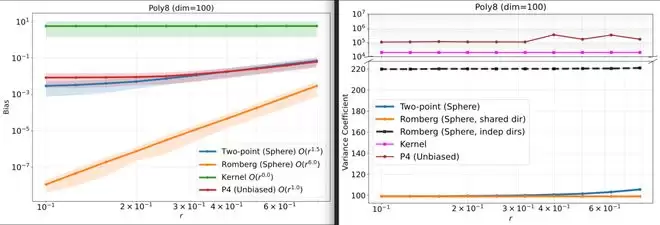
图3:Romberg-ZOGE在不同半径下的偏差下降曲线(合成函数实验)。
论文第一作者董洪成为深圳市大数据研究院-香港中文大学(深圳)联合培养博士生,通讯作者为深圳市大数据研究院副研究员蒲文强博士,共同作者包括深圳市大数据研究院副研究员赵立成博士、周睿博士,香港中文大学(深圳)人工智能学院尹峰教授。

Think in Cloud, Look at Edges: Semantic-Driven Query Decomposition for Efficient Video Reasoning
关键词:长视频理解、边云协同、语义驱动查询分解、关键帧选择、多模态大模型
摘要:长视频理解长期面临带宽、时延与精度的矛盾:纯云端方案能力强但上传成本高,纯边缘方案响应快但推理能力有限。现有边云协同方法往往将复杂问题压缩成一个单一语义向量进行相似度检索,容易产生“语义淹没”问题——逻辑上关键但不突出的证据被显著的视觉线索所掩盖。本文提出SCOPE框架,采用“云端思考、边缘观察”的范式:云端大模型将用户问题分解成带有依赖关系和重要性权重的DAG观测计划,边缘侧据此进行预算分配、并行语义匹配与关键帧选择,仅上传高价值的证据帧。
在Video-MME和LongVideoBench数据集上的实验显示,SCOPE在严格帧预算下稳定优于Uniform、Top-K、AKS等基线;在16帧设置下能达到与纯云端相同的66.04%准确率,同时将端到端时延从154.22秒降至23.94秒,降幅约85%。这项研究为资源受限场景中的长视频高效推理提供了一种可部署的边云协同新范式。
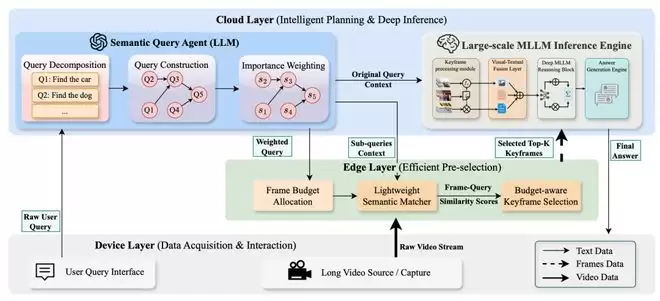
图4:SCOPE总体框架。云端大模型先生成结构化观测计划,边缘侧依据计划完成预算感知关键帧选择,并将证据帧上传云端进行最终推理。




