数据库实例运行的稳定性,往往取决于那些潜藏细节能否被及早发现。
连接数是否在悄然增长、会话是否存在异常堆积、等待事件集中在哪些环节、哪条SQL语句正在消耗大量资源、是否有会话被锁死、undo表空间与长事务的风险累积程度如何——这些关键信息分散在实例状态、会话、SQL、锁与事务的各个角落,若靠人工逐一排查,很容易遗漏真正的隐患。

当业务日益依赖自动化交付与AI辅助开发时,Oracle恰恰需要一个更主动、更直接的诊断入口。
Oracle 巡检,先看哪些风险
Oracle的性能问题通常沿着一条清晰的扩散链条展开:会话数上升,背后可能是应用连接池配置不当,也可能是批量任务集中执行;高消耗SQL一旦出现,CPU、I/O和buffer gets便会随之飙升;锁等待一旦发生,十有八九是某个事务忘了提交。
只看单个指标往往难以洞察全局,但如果将这些现象放在同一个诊断上下文中审视,就离真实故障现场更近了一步。
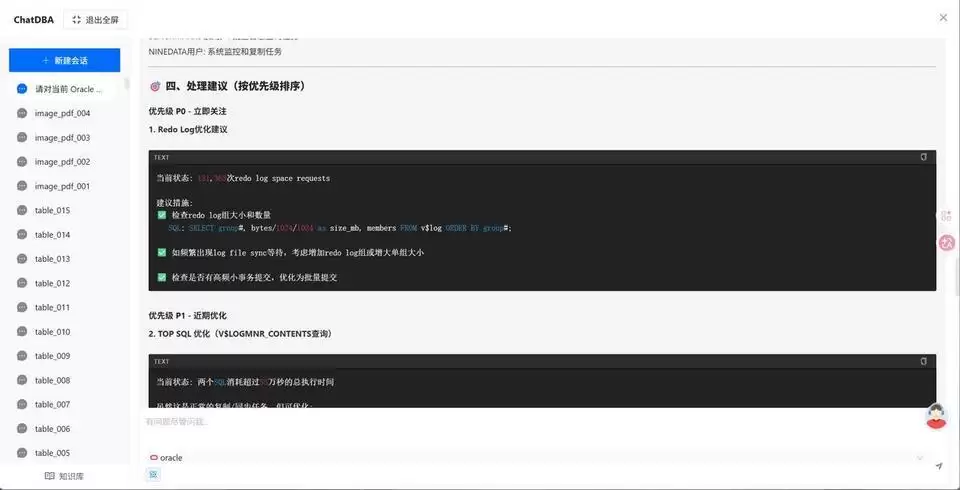
NineData ChatDBA正是为此而生——它围绕当前Oracle数据源的上下文,梳理实例运行状态,然后将异常会话、慢SQL、等待事件、锁等待、长事务以及后续处理建议,按风险优先级逐一呈现在你面前。
别只给指标,要给能判断的结论
Oracle巡检跑完一圈后,会话、等待事件、SQL_ID、执行计划、锁、undo、事务状态——这些信息对非DBA人员来说,很容易变成一堆“看到了却不知道怎么办”的原始数据。
ChatDBA的做法,是把这些线索组织成更易于判断的问题:当前是否存在异常会话?有没有一直在运行的SQL?是否存在高消耗SQL、执行计划异常,或者资源高度集中于某条SQL?
是否存在锁等待?阻塞源是谁?是否有疑似死锁的风险?是否出现长事务、大事务,或者undo表空间已经感受到压力?当前应该先止损,还是继续观察,或者直接进入SQL优化和索引治理——ChatDBA都会给出明确方向。
巡检完,最好能继续走向治理
巡检的价值从来不是在一张列表上看到指标,而是在发现风险后,还能继续深入治理。
如果ChatDBA发现了异常会话,你可以接着追问:哪些会话需要优先处理?如果发现了高消耗SQL,可以直接沿着慢SQL治理或SQL智能优化的路径深入。如果有锁等待,继续分析阻塞源和等待会话——这一切都顺理成章。
如果发现长事务,还能进一步评估:是直接提交、回滚,还是终止会话更合适?这样一来,Oracle巡检就不再是一次性的“查一遍”,而是一条连续的路径:先发现问题,再定位影响,最后给出处理与治理方向。
真到操作时,可以这样问 ChatDBA
操作非常简单。先登录 NineData 控制台,进入 ChatDBA——这一步的目的,就是先打开 Oracle 巡检的入口。

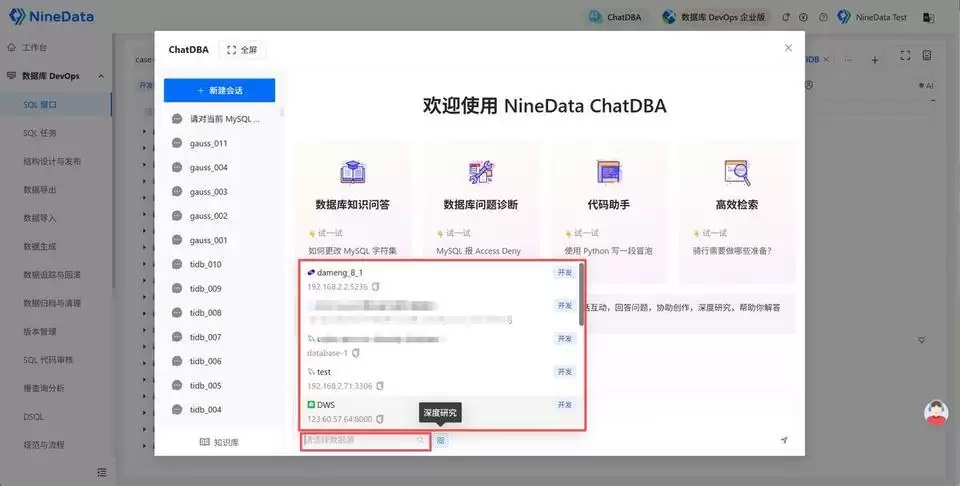
接着选择需要巡检的 Oracle 数据源。如果希望上下文看得更全面,可以同时勾选“深度研究”,让 ChatDBA 更完整地分析实例状态。
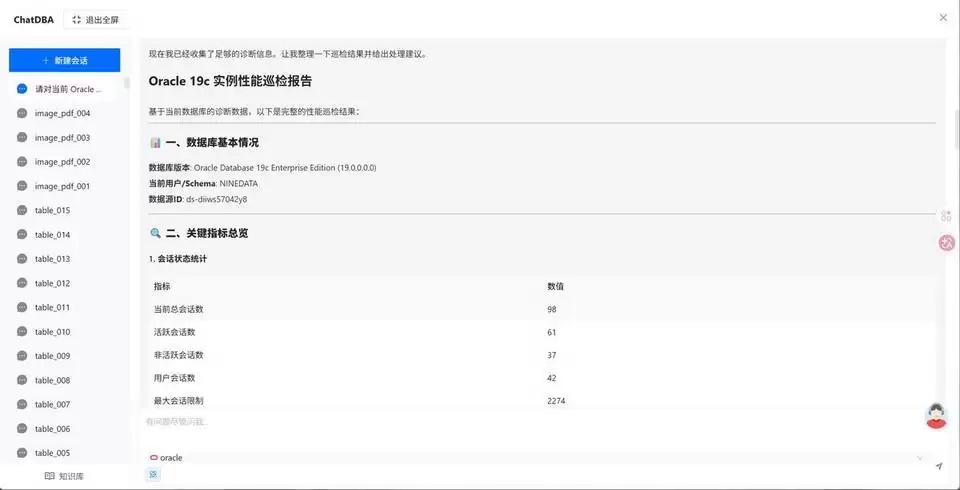
然后在对话框里直接输入巡检需求即可。例如:请对当前 Oracle 实例做一次性能巡检,重点关注异常会话、高消耗 SQL、等待事件、锁等待和长事务,并按风险优先级给出处理建议。
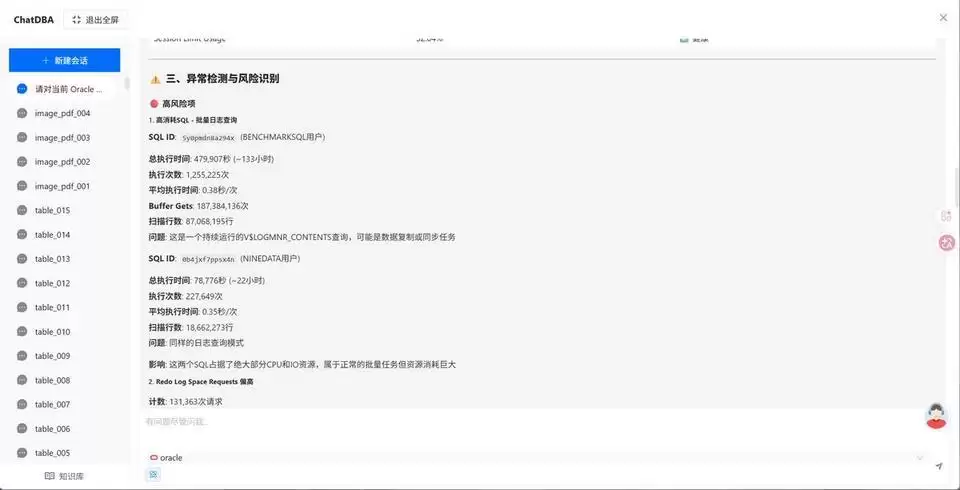
结果返回后,重点先看风险摘要、可疑会话、SQL线索、等待事件和处理建议。如果已经出现阻塞链路或长事务,就顺着上下文继续追问,让结论更加明确。
最后一句
Oracle 实例巡检,说到底,就是在业务变慢之前提前捕捉到风险信号。
NineData ChatDBA 把分散在会话、SQL、等待和事务里的线索汇总成清晰的结论,帮助团队更早发现问题、更快进入治理动作。




