2026年,智能体(Agent)技术正式迈入大规模普及阶段。随之而来的,是一个引发技术与学术圈深度关注的全新议题——Token(词元)被浪费的问题。
今年4月,小米MiMo大模型负责人罗福莉在社交媒体X上发布动态,直指OpenClaw这类Agent工具存在明显的低效问题。她的判断非常明确:全球算力的供应速度已经无法跟上Agent带来的Token需求爆发。
她详细阐述了背后的逻辑——像OpenClaw这样的工具,每次用户对话都会触发多轮低价值的工具调用。每一轮都被当作独立的API请求发出,产生极其冗长的上下文(通常超过10万Token)。即使有缓存命中,这种操作方式依然造成严重浪费。极端情况下,甚至会影响其他请求的缓存命中率。
Token浪费(在技术圈和学术平台中常被称为Token Waste)并非某个产品独有的问题。它是Agent能力进化过程中无法绕开的瓶颈。
《财经》统计了GitHub上与“Token Waste”相关的问题讨论数量。目前至少已有5200个,其中仅2026年第一季度就涌现出4150个。越来越多的开发者在实际业务中正面临如何管控Token浪费的挑战。
同样,《财经》还统计了全球最大预印本论文平台arXiv上关于“Token Waste”的论文。自2025年1月以来,与此直接或间接相关的论文至少有92篇,而2026年第一季度就贡献了38篇。学术界也在加紧研究Token浪费的成因及应对策略。
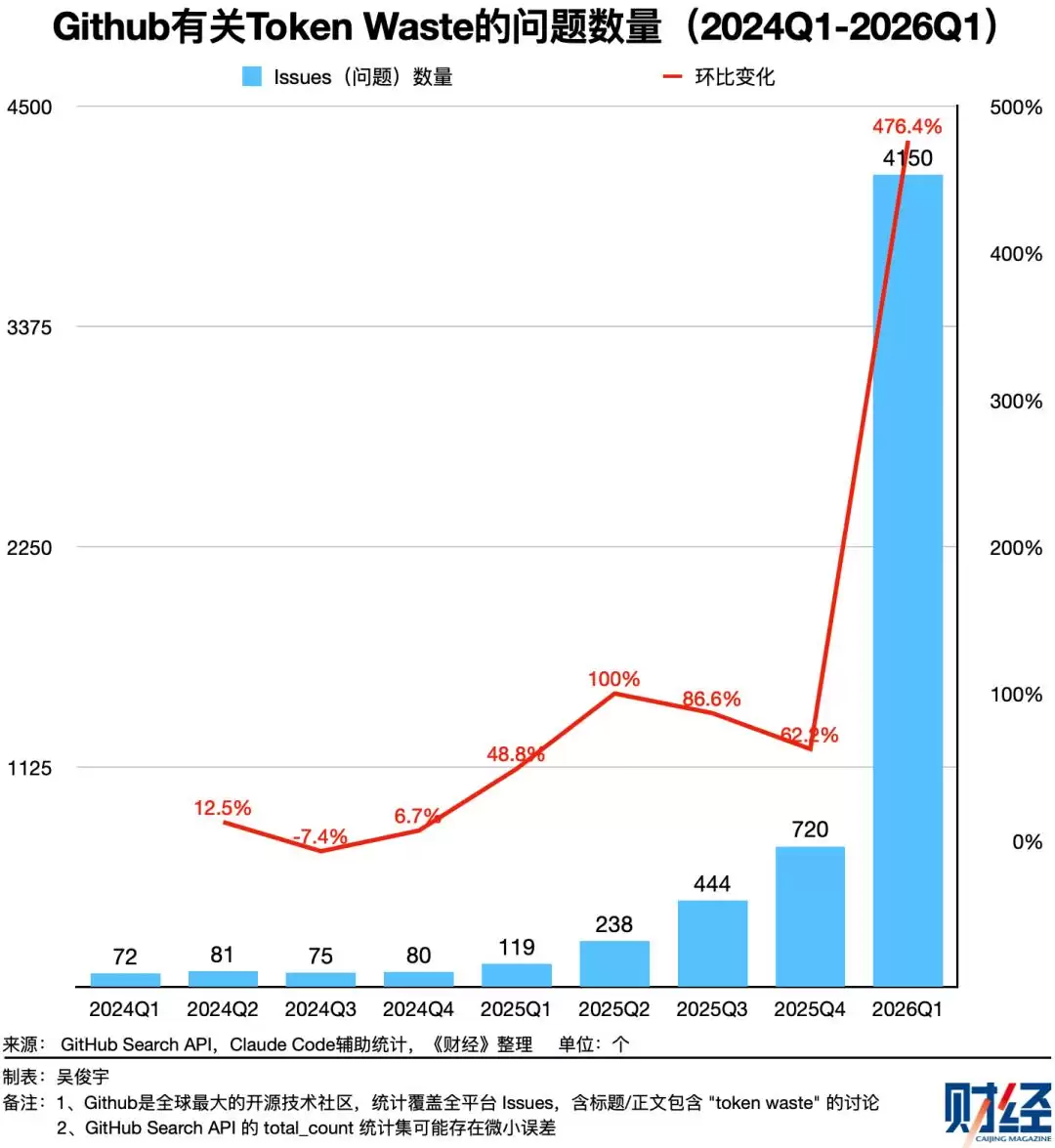
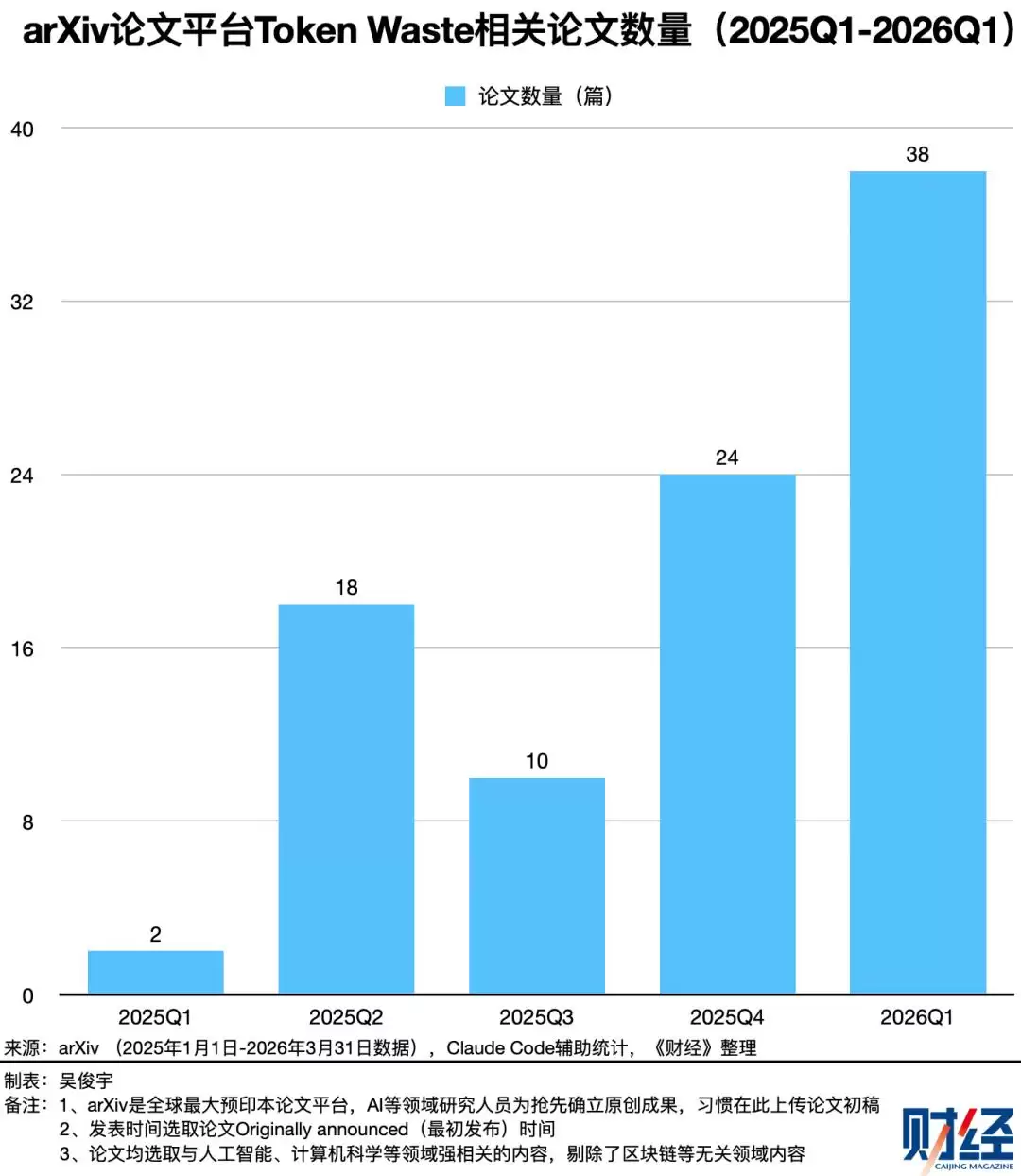
开发者和研究者普遍认为——Agent在处理复杂多轮任务时,历史文件、对话记录会不断堆积,导致大量无用、冗余、过期的信息反复生成并重复计算。Token消耗因此呈现指数级增长,而其中可能有30%至60%的Token被白白浪费掉了。
Token浪费带来的商业影响是:算力消耗的飞轮已经启动,但上下游的良性商业循环尚未建立。上游的模型公司(比如美国的OpenAI、Anthropic,中国的月之暗面、MiniMax、智谱),以及应用公司(例如全球最大的独立AI代码生成平台Cursor),虽然营收在增长,却仍然处于亏损状态。下游的开发者和企业客户,Token账单不断膨胀,而且很难进行精准预判。
不过,多位企业开发者和算法工程师对《财经》表示,不必因Token浪费而感到悲观。事实上,企业、开发者都在尝试为Agent装上更优的“脚手架”——通过优化Agent框架等方式来减少Token浪费。
因为在技术发展的早期阶段,没有浪费就没有进步。Token浪费推动了试错,而试错将推动Agent在技术演进与市场选择中不断走向成熟。
01
Token究竟是如何被浪费的?
Agent当前的框架还不够完善,Token很容易被低效消耗。
当下的Agent,简单来说,就像一匹尚未完全被驯服的“野马”。这匹“野马”在执行任务时到处乱闯,不会总是沿着最短路径前行——Token消耗有时会偏离最优方案。
很多时候,它并不清楚哪些问题与当前任务直接相关,于是只能把所有文件都读取一遍。随着对话轮次增加,上下文不断累积,缓存的计算负担也越来越重。用户每次输入后,Agent甚至需要重新计算完整的对话记录和文件数据。这导致Token成本呈指数级增长。
Agent工具的Token消耗量远高于过去的AI对话工具。百度智能云大模型平台总经理忻舟在2025年12月曾对《财经》表示,Agent系统执行的是系列任务。任务执行过程中,模型会不断用代码规划任务、调用工具并记录执行状态,每个步骤都可能触发新的模型调用。一次对话可能只消耗数千Token,但一次任务就可能消耗数万甚至数十万Token。
今年3月,一位名为shelvenzhou的开发者在GitHub上进行了基准测试,记录了自己日常使用OpenClaw时的Token消耗情况——第一轮对话Token成本为0.0050美元;第五轮对话Token成本升至0.0665美元,是第一轮的13.3倍;第10轮达到了0.13美元,是第一轮的26倍。
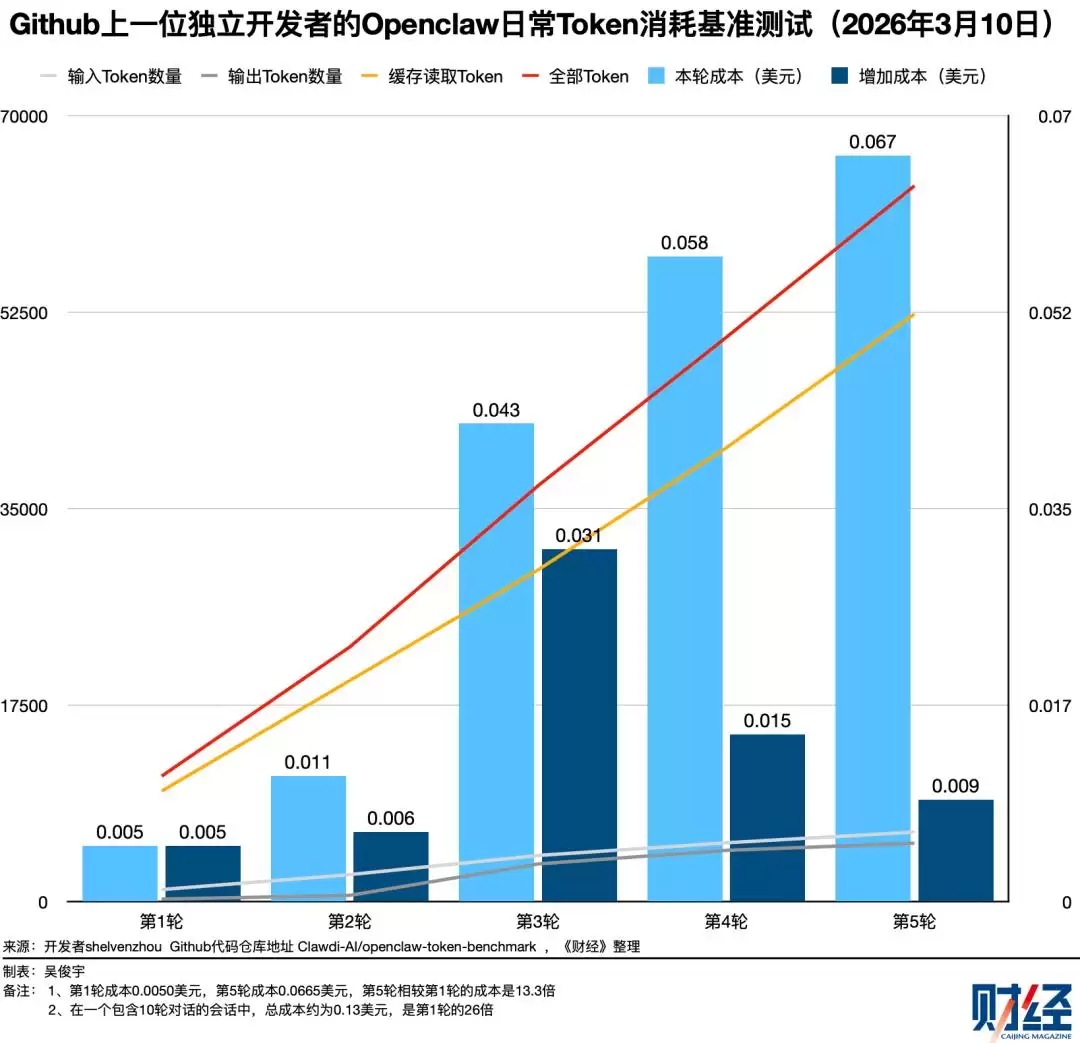
类似的情形在《财经》团队的工作流中也曾出现。今年3月,《财经》尝试用Cursor统计财报数据——阅读20份亚马逊财报PDF,统计最近20个季度AWS的营收与利润,并生成表格。
Cursor使用OpenAI的GPT-5.3-Codex模型自动运行了近30分钟。任务并未一次成功——它逐一尝试了四种路径,每次失败后重新寻找新路径、自动编写新代码,历经十余轮最终完成统计。整个过程耗费了130万Token,占20美元/月Token用量的约5%。但人工复核后发现,个别季度的数据仍然存在错误——任务完成了,结果却无法使用。
这次失败的财报统计任务,耗去了近30分钟和约7元的Token费用。那么,这130万Token到底是如何被消耗掉的呢?
实际任务中,1个中文字符约等于0.6个Token,1个英文字符约等于0.3个Token。亚马逊每份季度财报通常有50页,超过10万字符,对应约3万Token。
一位算法工程师对《财经》解释说,Cursor并不会把20份PDF从头到尾全部读完,而是根据任务提取关键句子并理解,然后自动编写代码将所有季度数据汇总。编写代码的过程同样消耗Token。在Agent多轮调用中,由于上下文反复传递以及多种路径尝试,Token消耗被进一步放大,最终达到130万Token以上的量级。
这种个人办公任务其实还算相对简单。放到企业生产系统中,任务执行时间更长、复杂度更高,会演变为持续性的Token成本。
今年3月末,Lumigo & Vexp联合创始人尼古拉·阿莱西(Nicola Alessi)在技术社区记录了自己编程Agent一周的Token消耗情况。他估计其中70%的Token被浪费了。
他的代码Agent使用了Claude Sonnet 4.6模型,在一个拥有超过200个文件的严肃生产场景中运行。他强调这不是普通的试验项目。
尼古拉·阿莱西长期监测发现,平均每次提问,Agent会发起23次工具调用——先扫描全部文件,再按编程语言过滤一遍代码,然后逐一打开文件、读取内容,如此循环超过20轮,才终于开始处理实际问题。这20轮循环中,每次对话平均消耗约18万个Token,而真正与问题相关的Token不超过5万个。
按此数据计算,Token浪费率高达72%。以Claude Sonnet 4.6的定价计算,每次对话平均浪费的Token费用约在1美元左右。单次对话浪费1美元看似不多,但在大规模部署和持续高频调用下,会逐渐累积成巨额算力支出。
员工动辄数万甚至数十万的大型科技公司,尤其是技术部门,工程师的月Token费用甚至已经超过万元。如果做好成本优化,每年有望节省千万元级别的算力成本。
一家员工超过30万人的国际科技巨头内部人士对《财经》表示,他所在的公司为每个人提供无限量的Token。他的工程师同事长期使用Claude系列模型编写代码,一周Token成本高达2000至3000美元。
一家员工超10万人的中国科技公司技术人员对《财经》表示,他在云基础设施部门,日常使用Claude Opus 4.6模型编写代码,每周Token成本高达3000元。
一家员工约5万人的互联网硬件公司人士对《财经》表示,公司已经为全员配备了Agent办公或AI代码生成工具,由于使用自研模型,因此员工Token额度不限。在他看来,Agent造成的Token浪费几乎习以为常。他日常办公中有30%至50%的Token因为Agent工程不够完善而被浪费了。
02
究竟是谁在为浪费的Token买单?
Agent造成的浪费使得Token消耗量变得难以预测,这甚至影响了整个市场的蛋糕分配。
从技术层面看,Token浪费是Agent框架不成熟所导致的。但从产业结构角度分析,它更像技术发展早期的成本传导——“算力-模型-应用”之间的蛋糕尚未划分清楚,成本不断向下游传导,最终由企业客户承担。
在过去的数字化转型阶段(2024年之前),市场蛋糕划分相对清晰。云厂商提供算力资源,SaaS公司提供软件产品,企业客户按需采购,三者边界分明、角色清晰。当时,企业IT成本相对可预测,可以根据业务规模规划云资源,还能与云厂商签订长约以获取折扣。软件采用订阅制,按年/月订阅座席付费,成本相对固定。
2025年之后,AI落地速度加快,蛋糕逐渐分配不均。云厂商分走了大部分收入与利润,模型厂商收入快速增长却普遍亏损,SaaS公司转售Token呈现出“管道化”趋势。
产业链最末端的企业CTO/CIO面对的不再是云和软件订阅账单,而是一种类似流量管控和动态限速的混合计费账单。Token账单变得难以预测。
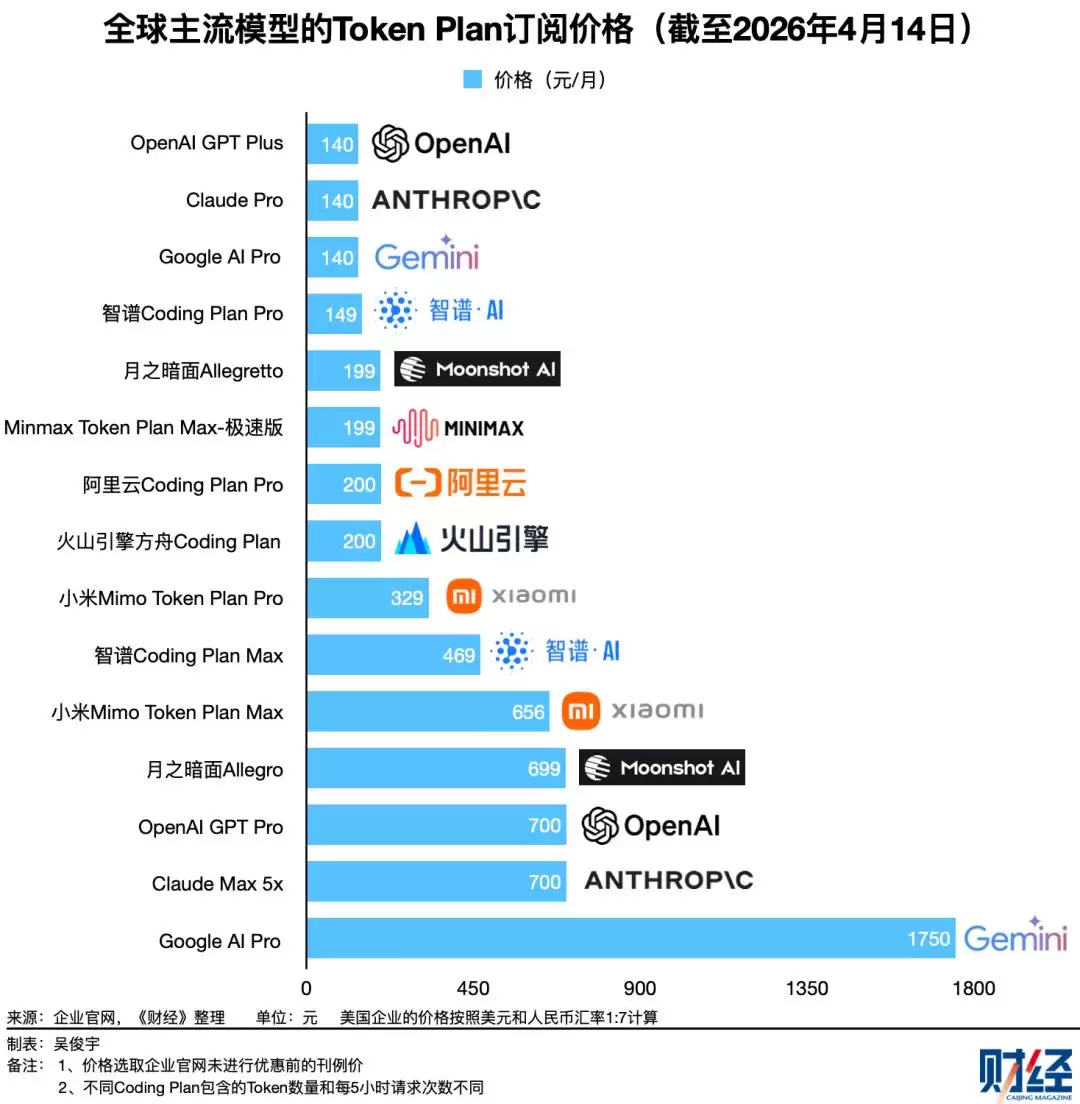
其一,Agent任务执行过程本身就会导致Token消耗波动剧烈。不同Agent框架的成熟度不同,Token消耗量差异也十分显著。
今年4月,一款名为Hermes的Agent迅速走红,在开发者社区的口碑很快超过了OpenClaw。Hermes会将经验自动生成Skill(技能),减少反复低效的试错过程,Token消耗相对更少。4月12日,一位开发者在Reddit社区记录称,他用OpenClaw和Hermes处理同一任务,OpenClaw在10分钟内消耗了200多万Token,而Hermes仅消耗了50万Token。
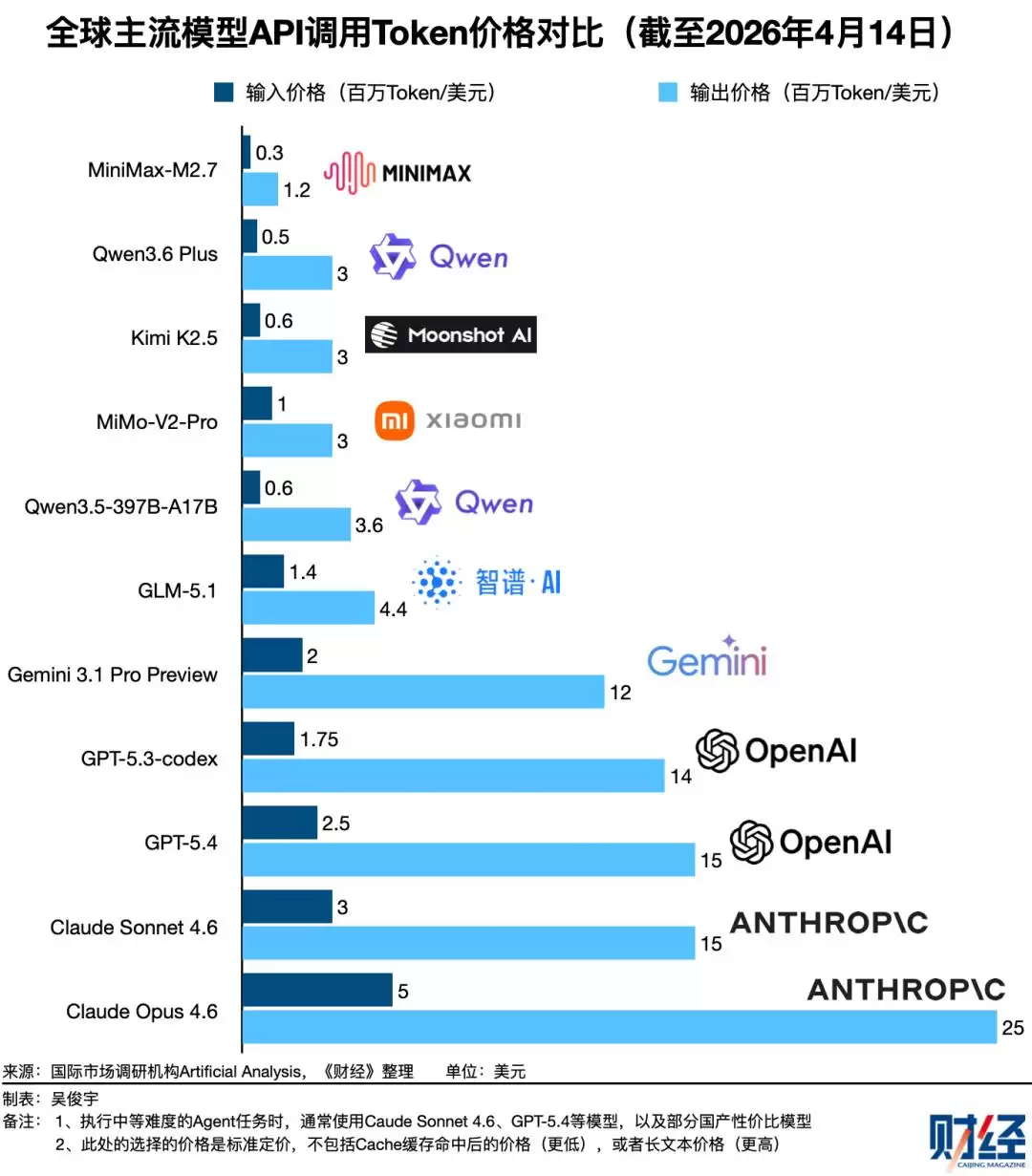
其二,不同模型之间的性能与定价差异明显。即使性能相近,Token定价差距仍然显著,这让成本评估变得更加复杂。
目前在开发者中口碑最好的Claude Sonnet 4.6、GPT-5.4,其Token定价普遍是国产模型的3到10倍。国产同级别模型之间,Token定价差距也在1到3倍之间。如何根据具体场景选择合适的模型,对企业来说决策成本很高。
其三,Token套餐(Coding Plan或Token Plan)虽然看似价格固定,但套餐内的Token额度、并发数量、缓存计费规则差异明显。套餐用尽后的超额费用、降级策略也各不相同。企业很难在纸面上提前对比评估真实成本。
目前大多数Token套餐以5小时为刷新周期,限制用户时间窗口内的最大调用次数或最大Token额度。一旦5小时内使用超额,系统会触发限速、排队或降低模型性能等机制。这个机制原本是为了尽可能公平地分配算力资源,却让企业提前算账变得更难了。
这一系列问题使得企业的IT预算编制变得困难。《财经》了解到,一些头部零售、制造企业正在尝试独立编制专门的Token预算。
一位服务了多家头部零售、制造企业的企业级大模型服务商CEO今年3月对《财经》表示,企业普遍处于AI焦虑期。这些Token预算正在蚕食传统软件、外包开发的预算份额。不过,目前很难精确计算Token预算的ROI。
企业客户付出了更高的Token成本,带动了模型厂商、应用厂商收入的快速增长。但作为供给方,模型厂商和应用厂商并没有想象中那么赚钱。
美国和中国的模型创业公司普遍处于亏损状态。在美国,OpenAI 2026年2月ARR(年度经常性收入)超过250亿美元,预计要到2030年才能实现盈利。Anthropic 2026年3月ARR超过300亿美元,预计最早2029年盈利。
在中国,月之暗面2026年2月收入超过了2025年全年,到2026年3月ARR甚至超过1亿美元。MiniMax 2025年营收0.79亿美元(约5.6亿元),2026年2月ARR超过1.5亿美元(约10.5亿元)。智谱2025年营收7.2亿元,2026年3月模型API的ARR达到17亿元,同比增长60倍。
不过,这三家公司也都在亏损。月之暗面的亏损规模尚未披露。MiniMax 2025年经调整后的净亏损为2.5亿美元(约17.5亿元),智谱2025年经调整后的净亏损为31.8亿元。
新兴的AI应用公司普遍亏损,甚至成了封装Token的管道——接入模型公司的API,将Token转售给客户。软件原本的定价权转移到了云厂商和模型公司手里。
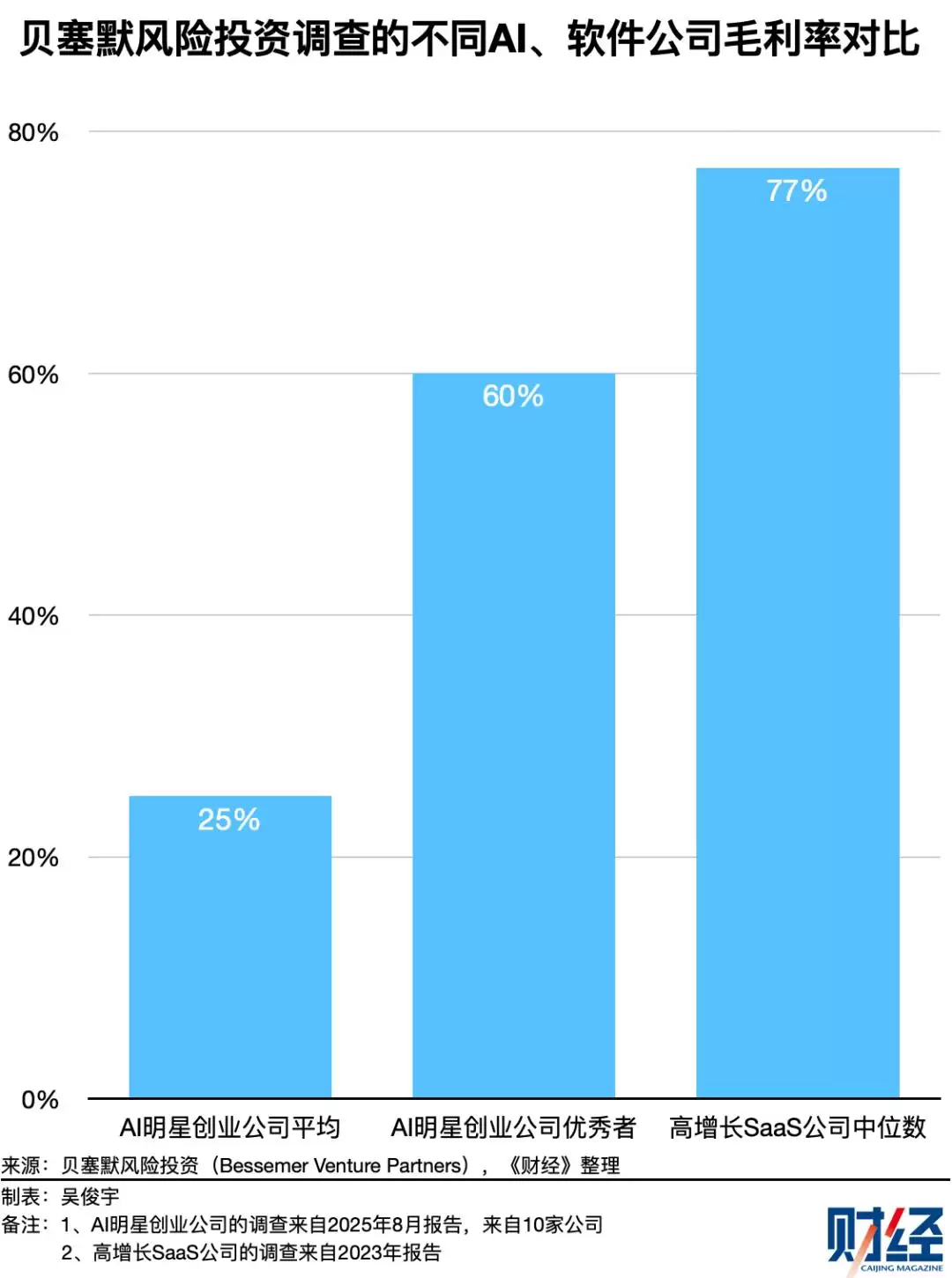
美国知名投资机构贝塞默风险投资(Bessemer Venture Partners)长期关注SaaS和AI赛道。该机构2025年调查了10家AI明星创业公司,发现这些公司平均毛利率仅为25%,部分表现优秀的公司平均毛利率约60%。
而根据贝塞默风险投资2024年的调查,高增长SaaS公司毛利率中位数约为77%。换句话说,AI应用相比过去的SaaS软件,毛利率大幅下滑。
最典型的案例是Cursor。它在2026年2月年化收入超过20亿美元。但美国市场调研机构AI Funding Tracker 2026年2月报告称,Cursor 2025年亏损规模至少在1.5亿美元。Cursor几乎所有收入都用于调用Anthropic、OpenAI的模型,还要支付员工工资、办公场所等其他运营费用。
全球最大的SaaS公司,比如Salesforce、Adobe、ServiceNow,同样在面临AI相关毛利率下降的问题。SaaS软件毛利率长期维持在80%左右,一直被视为高毛利的好生意,但现在情况正在发生变化。
Salesforce管理层在2025年12月公开表示,在Agent业务快速扩张阶段,公司短期内可以接受这部分业务的利润率承受压力。
Adobe管理层在2026财年一季度财报电话会(2026年3月12日)表示,Firefly和Express这两款生成式AI应用会带来更高的Token成本,可能影响公司利润率。
ServiceNow管理层在2025年四季度财报电话会(2026年1月28日)表示,预计2026年订阅毛利率为82%,将略微下滑,AI相关的算力投入是主要影响因素。
综上所述,Token消耗虽然在增长,但至少在模型公司、应用公司、企业客户这里都还没有真正形成正循环。这些成本在层层传导的产业链中被不断放大和转移。
03
如何从Token浪费中榨出利润?
减少Token浪费,本质上是在为“算力-模型-应用-企业客户”整个产业链降低无效成本,进而释放出利润空间。只有这样,“Token经济”的飞轮才能真正加速转动。
当前减少Token浪费的主流技术方案包括两大类:一是KV Cache(键值缓存),二是Agent工程。
KV Cache是什么?简单来说,就是把模型已经计算过的上下文结果缓存起来,避免在生成新Token时重复计算整个上下文。这正在成为模型公司榨取利润空间的关键技术。
今年4月,一位中国大模型创业公司人士对《财经》表示,他们销售的Token套餐本身几乎不赚钱,利润空间主要来自KV Cache的命中率。KV Cache命中得越多,模型厂商的实际计算成本就越低,利润空间就越大。
OpenAI的开发者技术文档显示,通过KV缓存,输入Token成本最高可以下降90%。一位云计算厂商智能算法负责人2025年12月曾对《财经》表示,利用KV缓存等技术,他们能把推理成本降低到原来的10%到20%。
Agent工程,就是把Agent的调度、记忆、模型路由、上下文裁剪和工作流管理打造成一套可控的系统工程。目的是减少Agent不必要的重复计算、工具调用、思考推理和空转循环。这在今天也被称为Harness——这个词的字面意思是缰绳和马具。
这是云厂商、模型公司、应用公司都在优化的方向。腾讯集团高级执行副总裁、云与智慧产业事业群CEO汤道生今年4月发表文章称,人工智能正式进入Harness时代。Harness是缰绳,它把大模型这股原始力量转化为可控的、可预期的、可协作的能力……驯服一匹野马,需要一副趁手的缰绳和一个知道目的地的骑手。
汤道生发现,在腾讯内部,同样的模型能力下,不同的脚手架设计——比如给模型调用什么工具、如何做分层上下文工程、如何管理长记忆、如何设计工作流——对实际使用效果和Token成本有着很大影响。
Agent工程成熟与否,直接决定了同一项任务的Token消耗量,从而直接影响企业的Token成本。
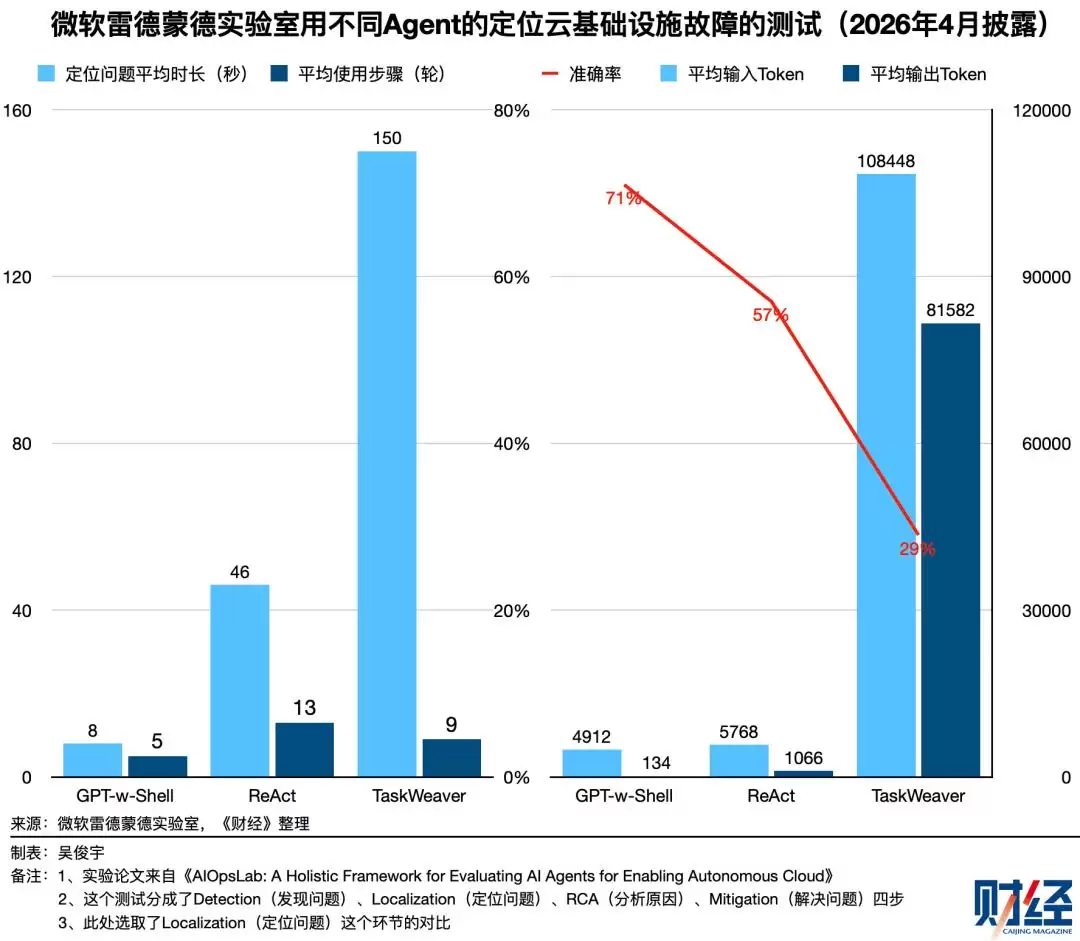
微软雷德蒙德实验室今年4月披露了一个案例,利用不同Agent对云基础设施进行自动故障处理。在使用同一模型定位故障问题这个环节,不同Agent的Token消耗差距明显。表现最好的GPT-w-Shell,在71%正确率下仅消耗约5000个Token;ReAct在57%正确率下消耗了6800个Token;TaskWeaver正确率仅29%,Token消耗却高达19万。
2026年初,浙江大学计算机辅助设计与图形学国家重点实验室研究团队向ICLR(机器学习领域三大顶级会议之一)提交了一篇论文,标题为《Stop Wasting Your Tokens》。研究团队提出,通过在Agent系统中引入一个“监督Agent”,可以在不改变模型结构的前提下实时识别错误、低效行为与冗余上下文,从而减少无效计算。实验结果显示,该方法在保持任务成功率的同时,将Token消耗平均降低了30%。
微软的工程实践、浙江大学的试验,都还属于控制Token浪费的早期阶段。随着技术成熟,这些经验会逐步落地到更多公司。
未来一段时间,谁能用更少的Token完成同样的任务,谁就能拥有更高的利润空间,也会拥有更确定的未来。
上文提到的互联网硬件公司人士对《财经》表示,没有必要因Token浪费而感到悲观。这是Agent在当前发展阶段必经的过程。他所在的公司正投入大量精力做Agent工程,不单是为了节省Token成本,更是为了提升任务准确率。在当下,提效远比降本重要。
2010年以后移动互联网起步,流量浪费和流量焦虑曾一度让用户担忧,但今天已经没人关注这些问题了。Token浪费的情况与此类似。Token浪费推动了试错,试错推动了优化,优化最终会推动“算力-模型-应用-企业客户”整个产业链走向成熟。
“Token经济”的正向循环也将在这个过程中逐渐形成。




