如何获取 Gemini API 密钥?完整步骤指南
调用 Gemin 3 Pro 的 API 接口时,首要任务就是完成身份验证凭据的获取。所有密钥管理操作都在 Google AI Studio 平台内完成。登录官网后,侧边栏的“API Keys”选项卡便是你的操作入口。首次使用时,系统通常会引导你创建一个默认的 Google Cloud 项目,便于后续管理。
需要注意的是,API 密钥与特定的 Google Cloud 项目绑定在一起。如果你手里已有现成项目,可以通过“Import Projects”功能将其导入到 AI Studio 环境中。导入成功后,在 API Keys 页面点击“Create API key”,即可生成一串密钥字符。这串字符必须妥善保管——它是访问模型的唯一凭证,一旦泄露,配额可能被他人消耗殆尽。
密钥安全配置与环境变量设置
最推荐的做法是将密钥设置为系统环境变量,而不是硬编码在代码里。不同操作系统的设置方法略有差异,开发者可根据自身环境灵活选择。
Linux 或 macOS 用户,在 shell 配置文件(如.bashrc或.zshrc)中添加一行导出命令即可:
export GEMINI_API_KEY=YOUR_ACTUAL_API_KEY
运行source ~/.zshrc使配置立即生效。Windows 用户则需通过系统属性的环境变量对话框,新建一个GEMINI_API_KEY变量,填入密钥值。完成这些操作后,官方 SDK 会自动识别该环境变量,代码中的初始化逻辑将变得非常简洁。
准备开发环境与安装 SDK
谷歌提供了多种语言的官方 SDK,包括 Python、JavaScript、Go 和 Java。对于大多数开发者来说,Python SDK 上手最为轻松,功能也最为全面。安装过程非常直接,使用包管理器执行一条指令即可:
pip install -U google-genai
如果你是 JavaScript 开发者,也可以使用 npm 进行安装。安装完成后,就可以在项目中引入模块,开始调用 API 了。
npm install @google/genai
发起第一个 Gemini 3 Pro 文本调用
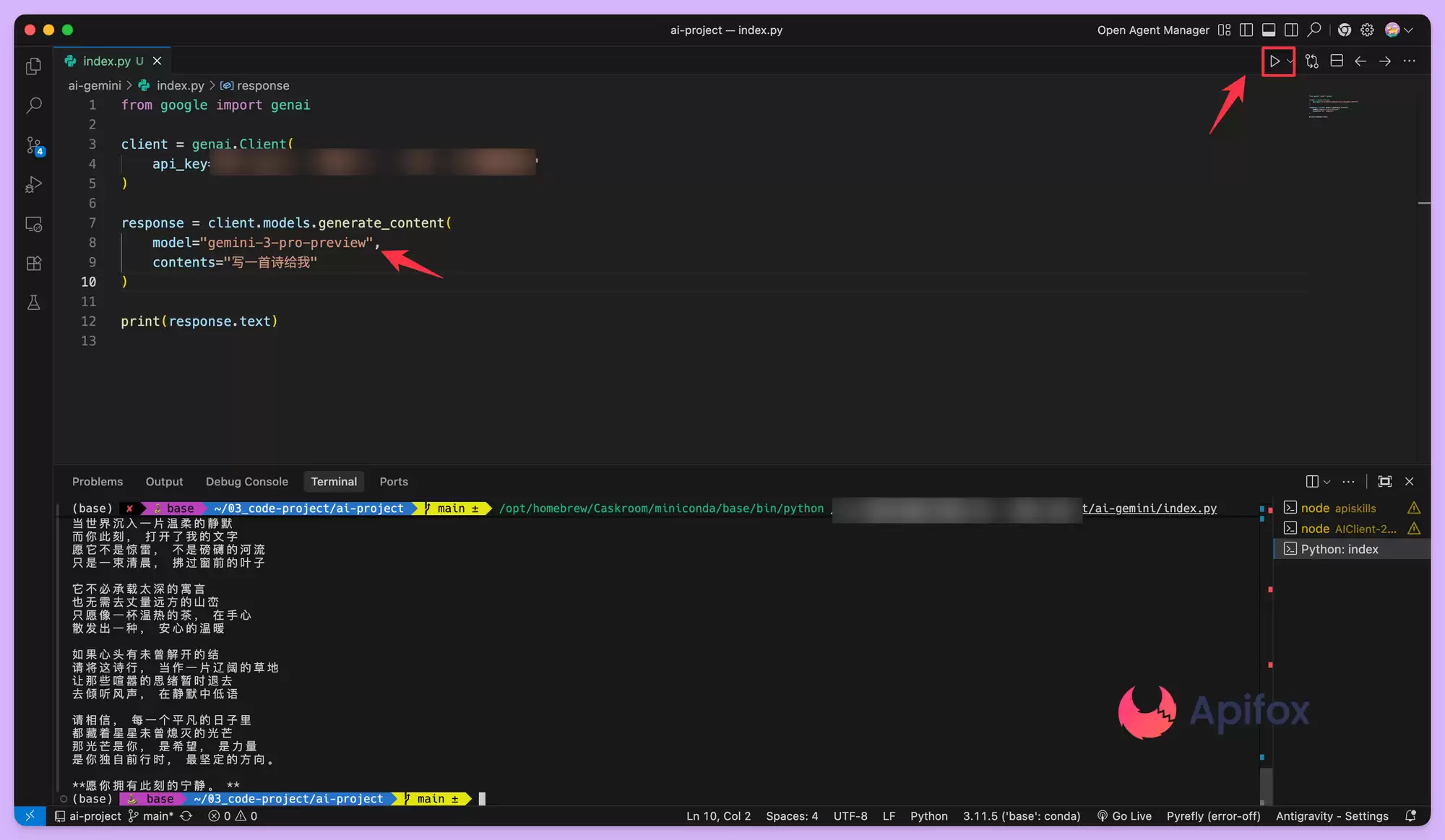
Gemini 3 Pro 是该系列中智能程度最高的模型,擅长处理复杂的逻辑推理任务。在代码中调用它时,需要指定正确的模型 ID——gemini-3-pro-preview。即使已经设置了环境变量,代码中仍需要实例化一个 Client 对象。
from google import genai
client = genai.Client()
response = client.models.generate_content(
model="gemini-3-pro-preview",
contents="写一首诗给我"
)
print(response.text)
这段代码利用了 SDK 的自动发现机制,它会自动寻找名为GEMINI_API_KEY的环境变量。返回的response.text属性包含了模型生成的最终文本。Gemini 3 系列具备原生推理能力,响应过程中可能包含内部的思考路径,细节丰富。
如果你不希望读取环境变量,而是直接在代码中传入 API Key,操作同样简单:实例化 Client 时显式传入apiKey参数,即可跳过 SDK 的自动发现机制。
from google import genai
client = genai.Client(api_key="YOUR_GEMINI_API_KEY")
response = client.models.generate_content(
model="gemini-3-pro-preview",
contents="写一首诗给我"
)
print(response.text)
核心参数与能力对比
Gemini 3 系列不只有 Pro 版本,还包含了主打速度的 Flash 版本和专门用于图像生成的 Image 版本。开发者在选择模型时,需要根据自身的业务场景、上下文窗口需求以及价格预算进行综合权衡。
Gemini 3 系列模型关键参数表
| 模型 ID | 输入上下文限制 | 输出限制 | 知识截止日期 | 主要能力特征 |
|---|---|---|---|---|
gemini-3-pro-preview | 1,048,576 tokens | 65,536 tokens | 2025年1月 | 最强推理、多步Agent任务、复杂编码 |
gemini-3-flash-preview | 1,048,576 tokens | 65,536 tokens | 2025年1月 | 高速度、低成本、Pro级别智能、适合聊天 |
gemini-3-pro-image-preview | 65,536 tokens | 32,768 tokens | 2025年1月 | 4K高质量图像生成、文字渲染、对话式编辑 |
控制模型的推理深度
Gemini 3 系列引入了一个新参数thinking_level(推理等级)。与之前版本不同,Gemini 3 会根据提示词难度动态调整内部推理过程。通过这个参数,开发者可以手动干预模型——是快速给出答案,还是进行更深入的思考分析。
如果追求极低的延迟,且任务相对简单,可以将thinking_level设置为low。但在处理复杂的数学证明、逻辑悖论或大规模代码分析时,默认的high设置(即动态模式)能让模型表现出更强的思维深度与推理能力。
from google import genai
from google.genai import types
client = genai.Client()
response = client.models.generate_content(
model="gemini-3-pro-preview",
contents="分析这道复杂的算法题:[代码题目]",
config=types.GenerateContentConfig(
thinking_config=types.ThinkingConfig(
thinking_level="high"
)
),
)
print(response.text)
需要特别说明的是,Gemini 3 Flash 还额外支持minimal和medium等级。minimal几乎等同于关闭推理过程,非常适合对响应时间极度敏感的即时聊天应用场景。
多模态输入与分辨率控制
Gemini 3 系列是原生多模态模型,支持文本、图像、视频、音频以及 PDF 文件的混合输入。针对视觉输入,API 提供了media_resolution参数。该参数决定了系统处理媒体文件时分配的 token 数量,直接影响识别精度和调用成本。
媒体分辨率推荐设置表
| 媒体类型 | 推荐设置 | 单帧/单页Token使用 | 适用场景说明 |
|---|---|---|---|
| 图像 (Image) | media_resolution_high | 1120 | 需要识别精细文字或微小细节 |
| PDF 文档 | media_resolution_medium | 560 | 标准文档理解与OCR识别 |
| 普通视频 | media_resolution_low | 70 (每帧) | 动作识别、场景描述 |
| 文本密集型视频 | media_resolution_high | 280 (每帧) | 视频中的文字提取或代码分析 |
通过在请求中显式指定分辨率,开发者可以精细化控制调用成本。例如,处理包含密集代码的截图时,建议手动将参数提升到high,确保模型能准确识别每一个符号和字符。
维护对话逻辑与 Thought Signatures
Gemini 3 接口调用中有一个高级特性——thoughtSignature(思维签名)。它是模型内部推理过程的加密表示。在多轮对话或工具调用场景中,必须将这些签名原样传回给模型,否则模型的逻辑推理能力会大幅下降,甚至在严格模式下可能导致 API 报错。
如果使用官方 SDK 内置的聊天对象,思维签名的传递是自动完成的。但假如是通过 REST API 自行构建历史记录,就必须从响应中提取thoughtSignature字段,并在下一次请求的历史序列中,将其包含在对应的model角色部分。这种设计确保了模型能够“记住”它在上一轮对话中未公开表达的思考逻辑,维持对话的连贯性。
图像生成与对话式编辑
调用gemini-3-pro-image-preview模型时,可以实现非常精细的图像生成效果。由于该模型内置了 Google Search Grounding 能力,它可以先联网搜索实时数据(比如今天东京的天气),然后再生成符合事实的图像。
from google import genai
from google.genai import types
client = genai.Client()
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents="生成一张当前伦敦天气的可视化海报",
config=types.GenerateContentConfig(
tools=[{"google_search": {}}],
image_config=types.ImageConfig(
aspect_ratio="16:9",
image_size="4K"
)
)
)
for part in response.parts:
if part.inline_data:
image = part.as_image()
image.sa ve('london_weather.png')
在图像编辑流程中,思维签名的重要性更加凸显。当提出修改建议(比如“把背景改成日落”)时,模型需要依赖上一轮生成的思维签名来理解原始图像的构图和光影逻辑,从而保证局部修改的连贯性与一致性。




