最近三个月,我奔波了四个项目,与不下二十个测试团队进行了深入交流。一个趋势越来越清晰:大部分团队已经开始使用“Skill”这个概念,但令人遗憾的是,90%的人只是把它当成了“脚本收集器”。
什么意思?举个例子:Skill A 专门测试登录,Skill B 专门测试下单,Skill C 专门测试支付。从表面看,实现了模块化。但一旦环境切换或者数据变更,就必须改代码、重新上线、等待发布流程。
这根本不是Skill,这只是给传统的脚本换了一个新名字。
更令人头疼的是,当业务方提出“帮我跑一下这十组参数的对比效果”时,你只能复制粘贴出十个Skill,或者写一个硬编码的循环。一周后需求变了,参数要调整,同样的工作流程又要再来一遍。
这已经不仅仅是效率问题了,这是在不断积累可怕的工程债务。
今天我们不绕弯子,直接分享一个已在生产环境多次验证的落地方案:数据驱动Skill。它的核心目标可以概括为一句话——只需一行配置,就能跑完十组参数,全程无需改动代码。
目录
一、当“可重用”变成了“可复制粘贴”
二、问题的本质是配置与执行没有解耦
三、一个数据驱动Skill的核心工作机制
四、传统脚本 vs 数据驱动:一个真实的压测对比案例
五、工程落地实践:三个最容易踩的坑
六、你现在手上那个Skill,数据是写死的吗?
一、当“可重用”变成了“可复制粘贴”
先说一个真实的企业级应用场景。
上个月,我帮一个电商团队做交付前的最终验证。他们有一个“下单链路Skill”,封装了登录、选品、加购、下单、支付五个核心步骤。听起来很标准,似乎很规范。
但当被问及“你们如何测试不同用户类型(新客、老客、会员、黑名单)的下单表现”时,负责人愣住了。他随后打开了一个文件夹。
里面赫然躺着七个不同版本的下单Skill:
order_flow_new_userorder_flow_viporder_flow_blacklistorder_flow_guest……
每个Skill的代码逻辑完全一致,区别仅仅体现在三个地方:用户类型、优惠券规则和超时时间。
这根本不是代码重用,这不过是复制粘贴的升级版本而已。
问题究竟出在哪里?他们把“业务参数”给写死在了Skill内部。每当需要新增一组参数,就不得不新建一个Skill。而每个Skill都要走一遍完整的发布、部署和测试流程。最终,维护成本根本不是O(n)级别的增长,而是可怕的O(n²)。
这个团队绝非个例。绝大多数人在设计Skill时,默认就把“数据”和“逻辑”绑定在了一起。原因很简单,因为一开始只需要跑一组参数,大家都觉得没必要拆开。等项目规模扩大到需要处理十组、二十组参数时,代码已经改不动了。
问题的本质不在于Skill这个工具本身不行,而是设计思路依然停留在陈旧的“脚本思维”阶段。
二、问题的本质是配置与执行没有解耦
拆开来看,一个Skill实际上只做两件事:
获取数据(参数) 按逻辑执行(步骤)
传统脚本思维的做法是:把数据直接写在代码里。
而数据驱动思维的做法是:把数据写在配置里,代码只负责执行。
这两种做法的差异,在项目规模很小的时候几乎可以忽略不计。三五组参数,直接写在代码里反而更直观。但是,一旦进入以下任何一种状态,两者之间的差距就是天壤之别:
参数组合数量超过10组 参数需要频繁调整(一周一次以上) 不同环境需要不同的参数集(开发/测试/生产) 业务方需要自己修改参数,但不能碰代码
根本原因在于变化的频率不同。业务参数的变化频率是以天为单位的,而执行逻辑的变化频率是以月为单位的。把两者写在一起,本质上就是用低频的代码发布节奏,去应对高频的业务参数变化需求。
核心的解决思路只有一个:让Skill接收一个标准化的输入结构,内部只专注于处理“怎么执行”,而完全不关心“执行什么”。
三、一个数据驱动Skill的核心工作机制
直接上架构设计。这是一个在生产环境中经过长期验证的三层结构。

配置层:只存储数据,不存储逻辑。每一组参数都是一个独立的条目,包含唯一标识、输入值、期望结果和环境标记。
解析器:负责读取配置信息,进行基础的校验工作(如参数类型、必填项、取值范围),然后逐组将数据喂给执行引擎。这一层不进行任何业务判断,只做格式和类型转换。
执行引擎:这是Skill真正的逻辑核心。它不关心数据从何而来,只关心当前拿到的是哪一组参数,然后严格按照步骤执行。同一个引擎,既可以运行配置里的第1组参数,也可以完美运行第10组参数。
结果收集器:将每一组参数的执行结果单独记录下来,最后按照配置分组输出一份详细的对比报表。这一步被很多人忽略,但它恰恰是数据驱动Skill的价值放大器——你不仅能一次性跑完多组参数,还能直观地看到哪组参数触发了什么样的行为。
在落地实践中,最关键的三个设计决策如下:
1. 参数协议必须固定无论底层配置采用什么格式(YAML、JSON、Excel),Skill的入口只认一种统一的结构。通常建议使用JSON Schema进行约束,示例如下:
{
"caseId":"TC001",
"params": {"userType":"vip","timeout":30},
"expect": {"code":200,"maxDuration":25}
}
2. 执行引擎必须设计成无状态的同一个Skill实例可以顺序执行完10组参数,每组参数执行完毕后都必须重置上下文。否则,第一组残留的变量会影响第二组的结果。
3. 配置要支持全局与局部覆盖采用全局配置 + 局部覆盖的机制。例如,默认超时时间为30秒,但如果某组特殊参数需要60秒,只需在那组参数中单独覆盖即可,无需复制整个全量配置。
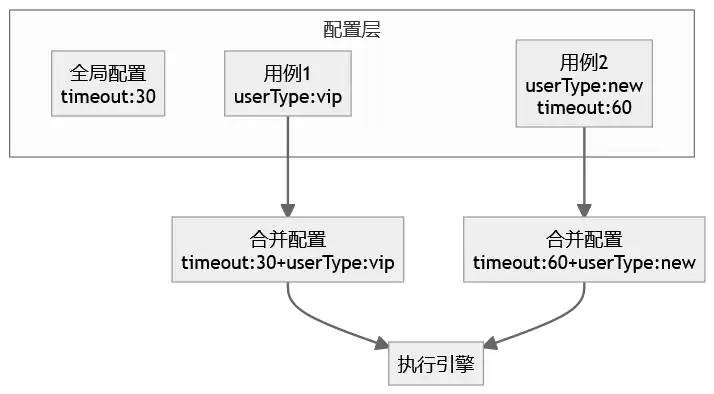
两个月前,一个提供金融服务的团队找到我们合作。他们的场景是:需要验证同一个风控Skill在100组不同用户画像下的表现(参数组合包括年龄、额度、历史逾期次数等)。
传统做法是:写一个for循环,在Skill内部遍历参数列表。代码量看似不大,但问题都留给了后期。
跑完一轮后,当发现第37组参数触发了超时,开发人员需要调试。但日志里看不到这组参数的完整上下文——因为传统的for循环把所有输出结果都混在了一起。他不得不重新跑一遍,并人工盯着第37组去打日志。
前前后后折腾了整整三个小时。
换成数据驱动Skill之后,情况完全不同:
100组参数都写在一个Excel里,由业务方自行维护 Skill逐组执行,每组独立输出日志文件,文件名自带caseId标识 执行完毕后,结果收集器自动生成一个对比表:清晰地标明哪几组通过,哪几组失败,以及失败时的具体参数是什么
问题定位时间从三个小时直接缩短到了五分钟。
核心观点:数据驱动Skill带来的核心价值,不是写代码速度的提升,而是问题定位效率的指数级改善。
另一个常常被忽略的巨大收益是:业务方从此可以自己调参了。
那个金融团队的业务分析师,后来开始自己修改Excel里的参数组合,然后直接跑回归验证。整个过程完全没有找开发人员帮忙。这并非是因为业务分析师突然学会了写代码,而是因为Skill的入口变得足够简单——仅仅是一个配置文件。
核心观点:衡量一个Skill是否真正做到了数据驱动,就看业务方能否在不改动代码的情况下,独立完成一次参数变更。
五、工程落地实践:三个最容易踩的坑
说完了如何设计,我们再聊三个在落地过程中亲眼目睹的典型陷阱。
陷阱一:配置文件越来越臃肿,变成了另一个维度的“意大利面条”
当参数组合达到上百组时,一个单一的YAML文件会变得非常难以维护。此时千万不要硬撑,应该引入配置分层策略:按业务模块拆分配置文件,Skill在启动时动态加载。
本质在于:数据驱动Skill自身也需要进行分层设计。配置文件本身也是一项工程产物,而不仅仅是纯文本。
陷阱二:忽略了参数之间的依赖关系
有时候,第5组参数依赖于第2组执行过程中产生的某个中间值。如果强行把参数组都设计成完全独立的,这种依赖关系就会断裂。
解决方案是在参数协议中增加一个dependsOn字段,用来指向另一组的输出。执行引擎需要具备简单的依赖解析能力。
但是,这个功能务必谨慎使用。基本原则是:能并行处理的就不要串行执行,能保持独立的就不要建立依赖。依赖关系越多,数据驱动的核心价值就会被稀释得越厉害。
陷阱三:结果收集做成了简单的日志堆砌
很多人跑完十组参数后,输出的是十个孤立的日志文件,然后就没有然后了。
结果分析是数据驱动Skill的闭环终点。如果没有结构化的结果对比,你就永远无法回答“哪组参数表现最好”“哪个阈值最稳定”这类关键问题。
正确的做法:结果收集器除了落日志之外,还必须输出一个CSV或JSON格式的汇总表,包含每组参数的输入、输出、耗时和状态码。这个汇总表可以直接导入到BI工具中进行可视化分析,或者喂给下一个Skill做二次处理。
核心观点:如果缺少结果对比,那么数据驱动Skill充其量只是一个高级版的for循环。
六、你现在手上那个Skill,数据是写死的吗?
回到文章开头提出的那个问题。
Skill这个概念本身并不新鲜。但绝大多数人在设计Skill时,都默认把它当成了一个“逻辑封装单元”。很少有人会主动问自己一个问题:数据和逻辑,到底要不要分开放?
并非所有场景都需要数据驱动方案。如果你只有一组参数,且半年都不变一次,那么把它们写在代码里完全没有问题。
但是,如果你已经出现了以下任何一种情况:
手头有多个参数相近、内容重复的Skill副本 业务方频繁找你修改参数 运行多组对比测试时,需要手动修改代码 不同的测试环境需要不同的参数集
那么,数据驱动方案就不再是一个“高级特性”,而是一个必须做出的选择了。
最后,留给你一个思考题。
请你现在就去看看你们团队最常用的那个Skill。尝试将代码里所有的业务参数(如URL、超时时间、用户类型、阈值、开关等)都抽出来,放在一个独立的配置文件里。然后,在不修改Skill原有代码的前提下,更换三组不同的参数去运行。
它能顺利跑通吗?
如果能,那么恭喜你,你们的设计已经走在了正确的轨道上。如果不能,那么请你认真思考一下——问题究竟是出在Skill本身的设计上,还是你们的发布流程限制了配置的独立变更?
这两个问题的答案,指向的是两种完全不同的改进路径。




