商汤的日日新SenseNova U1系列最近迎来了一位新成员——U1-8B-MoT-Interlea ved图文交错增强版模型。这次模型专门针对图文交错创作与生成场景做了专项强化,说白了,就是让AI能更好地完成绘本、故事书、多页PPT、图文教程这类需要连续多页创作的任务。之前多模态模型在生成多轮内容时总是会犯“角色形象飘移、画风断裂、图文脱节”的老毛病,这次算是冲着这些痛点来的。
核心突破:从“单张高质量”到“连贯图文长序列”
SenseNova U1图文交错增强版的核心能力,简单说就是:能够在长内容场景中持续输出风格统一、叙事连贯、图文高度对应的多页结果。它不再只是生成一张孤立的单图,而是端到端地给你一套完整的、可以直接拿来用的图文内容序列。
这次升级主要集中在四个方向:
1、叙事一致性与角色连贯性大幅提升
模型在长周期创作中的叙事连贯性、角色一致性和画风统一性有了明显进步。故事线从第一页到最后一页始终被严格遵循,人物形象保持一致,彻底解决了此前多轮生成中角色形象“走调”的核心痛点。
2、图文对应关系增强,告别“图文脱节”
经过专项训练,模型大幅改善了图像内容与文字描述之间的语义对齐能力。生成的画面能更准确地呈现文本描述的复杂场景、动态动作以及物体间的空间关系,“文不对图”的情况明显减少。
3、视觉质量与Artifact明显改善
针对人物结构、文字渲染、页面排版等容易翻车的高频高难区域做了定向优化,显著降低了生成物中的视觉瑕疵(Artifact),让复杂图文混排的内容更加自然、稳定和可用。
4、全新能力:多页PPT自动生成
新版本首次支持了多页PPT的自动生成。模型能够智能从输入内容中提取要点,自行完成排版设计与文字渲染——说白了,你把大纲扔给它,它就能帮你把一整套PPT做出来。
能力对比:四大场景实测表现
下面通过实际案例,直观看看SenseNova-U1-8B-MoT-Interlea ved图文交错增强版在各类图文创作任务中的表现:
场景一:教程类内容生成
• 任务场景:生成带有步骤说明与配图的图文指南。这类场景的关键痛点在于:步骤必须清晰,图文需严格语义对齐,画面逻辑要干净实用。
• 原版模型表现:生成的果蔬图像虽然比较真实,但搅拌步骤的配图出现了违背物理逻辑的“星云漩涡”;而且生成步骤较为繁琐,家庭实操实用性偏低。
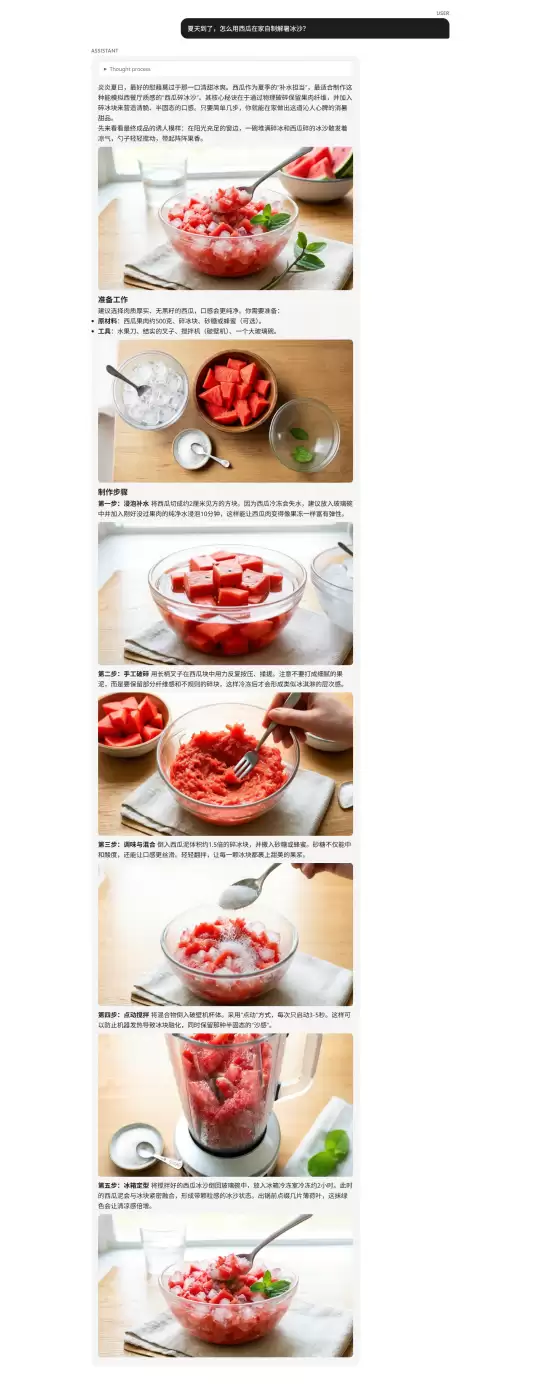
• 增强版模型优势:西瓜图像更真实自然,没有锯齿状的视觉瑕疵;搅拌动作完全符合真实物理逻辑;步骤也精简实用,更贴近真实操作场景。

原版
让长内容创作从此一气呵成
从单张图像的惊艳“盲盒”,到跨越连续多页、逻辑严密、画风如一的“完整图文内容创作”,SenseNova U1图文交错增强版模型的推出,标志着多模态AI连续内容创作正式跨入高实用性、高稳定性的全新阶段。
无论是让步骤严丝合缝的图文指南,还是需要角色和情节完美连贯的儿童奇幻绘本,亦或是追求视觉排版层次的商业演示PPT——它都用强大的指令遵循与极致的视觉质量,给出了令人惊艳的答卷。它让AI真正告别了碎片化的单图拼凑,走向了完整、长篇、端到端的连续叙事。




