不得不承认,微软开源的 VibeVoice 项目为语音合成领域注入了全新活力。作为一款先进的 AI 语音生成框架,它专为生成具有丰富表现力的长篇幅、多说话人对话音频而设计,完美契合播客、有声书等自然聊天场景的应用需求。该项目旨在攻克传统 TTS(文本到语音)系统长期面临的三大技术瓶颈:模型可扩展性不足、跨段落的说话人音色一致性难以维持,以及多轮对话转换生硬不自然的问题。
目前,VibeVoice 提供了两个核心的语音合成模型变体。其一是长篇幅多说话人对话模型,能够合成时长最高达 90 分钟、包含最多 4 个不同说话人的对话或单人语音,显著超越了以往模型通常仅支持 1-2 个说话人的处理能力上限。其二是实时流式 TTS 模型,它能够在约 300 毫秒的极低延迟内产出第一段可听语音,并原生支持流式文本输入,专为需要即时语音反馈的实时交互应用(如智能语音助手)打造。
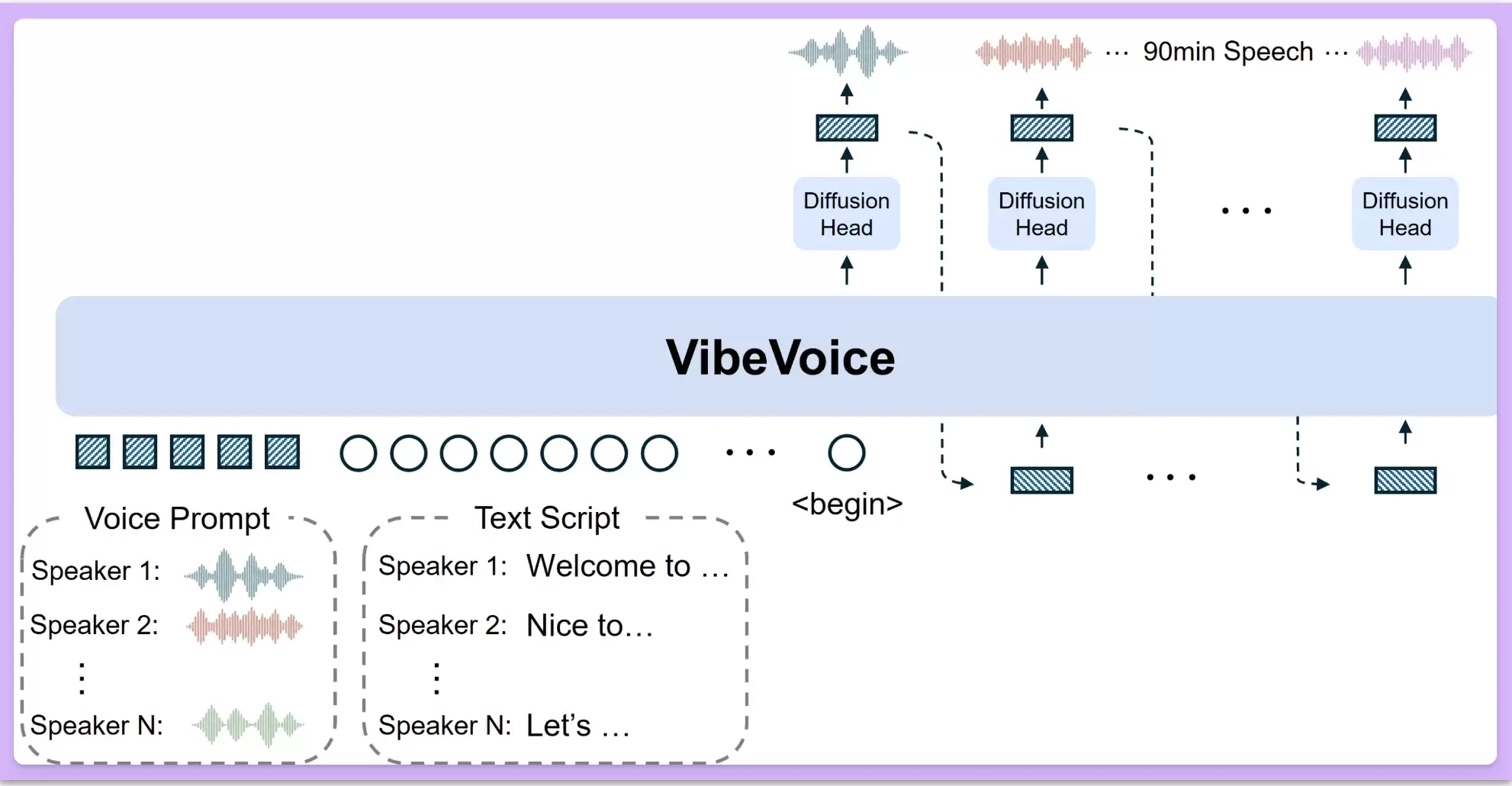
VibeVoice 的核心技术突破在于其采用了一套工作在超低帧率(7.5 Hz)下的连续语音分词器。简单来说,这项创新在确保合成音频高保真度的同时,极大提升了处理长序列音频数据的计算效率,有效避免了生成长音频时可能出现的性能瓶颈。项目采用创新的“下一词元扩散”生成框架:首先利用大语言模型(LLM)深度理解文本上下文与对话逻辑流,再通过扩散模型头来精细合成高保真度的声学特征细节。两大模块协同工作,共同实现了优质的多说话人语音合成效果。
快速开始与安装指南
若希望快速体验 VibeVoice 的语音生成能力,最便捷的方式是直接使用官方提供的 Google Colab 在线笔记本,可免去复杂的本地环境配置步骤。若需要在本地服务器或开发环境中部署,则需按步骤完成环境搭建。
第一步是克隆项目代码仓库并安装必要的 Python 依赖库。强烈建议使用 Python 虚拟环境(如 venv 或 conda)进行操作,以避免与系统全局的包环境产生冲突。
git clone https://github.com/microsoft/VibeVoice.git
cd VibeVoice
pip install -r requirements.txt安装所需时长取决于您的网络速度与硬件配置。完成依赖安装后,即可通过 Python 脚本加载预训练模型并开始进行 AI 语音合成的推理任务。
模型使用详解与配置
VibeVoice 针对不同应用场景提供了特化的模型,理解每个模型的核心能力与输入输出格式是高效使用的前提。长篇幅对话模型更适合生成播客对谈、有声读物、虚拟角色对话等长内容;而实时流式模型则定位于需要极低延迟语音响应的交互式 AI 应用。
基础语音生成任务的代码调用结构示例如下。您需要提前准备好输入文本和对应的说话人身份标识配置。
from vibevoice import VibeVoicePipeline
# 加载长篇幅对话模型
pipeline = VibeVoicePipeline.from_pretrained("microsoft/VibeVoice-long-form")
input_text = "你好,欢迎收听本期的科技播客。今天我们讨论的主题是人工智能语音合成的最新进展。"
speaker_ids = [0, 1] # 例如,两个不同说话人交替发言
# 生成音频
audio_output = pipeline.generate(input_text, speaker_ids=speaker_ids)实时流式 TTS 模型的使用方式有所不同——它被设计为接收连续的文本流输入。项目文档中提供了基于 WebSocket 通信协议的完整示例,可以快速启动一个实时语音合成演示服务。
python demo/websocket_server.py --model_path ./models/realtime-0.5b不同任务对模型参数的要求各异。下表清晰地对比了两种核心模型的关键特性与典型应用场景:
| 特性 | 长篇幅多说话人模型 | 实时流式 TTS 模型 |
|---|---|---|
| 主要用途 | 播客、对话模拟、长内容生成 | 实时交互、语音助手、流式响应 |
| 最大时长 | 约 90 分钟 | 支持持续流式输入 |
| 说话人数 | 最多 4 人 | 单人 |
| 首次语音延迟 | 依赖生成长度 | ~300 毫秒 |
| 输入模式 | 完整文本 | 流式文本块 |
| 输出模式 | 完整音频文件 | 流式音频块 |
高级功能扩展与多语言支持
除了对英语和中文的稳定高质量合成,VibeVoice 近期已扩展增加了对九种语言的实验性说话人支持,覆盖德语、法语、西班牙语、日语、韩语等主流语种,其多语言语音合成能力正不断拓宽。
该项目另一个引人注目的亮点,是能够生成包含自发歌唱元素的语音。这在常规的 TTS 系统中颇为罕见,为创造性的音频内容制作带来了新的可能。
此外,VibeVoice 在处理复杂的多人交替长对话方面表现出色,能够有效维持同一说话人音色在不同段落间的一致性,并保障对话流的自然与流畅。要充分发挥这些高级功能,关键在于构建结构合理的输入文本与精确的说话人身份序列。例如,对于需要特定风格(如歌唱、耳语)的段落,可以在输入文本中进行隐式描述或显式风格标记,模型将基于训练数据中的模式进行模仿与生成。
潜在风险、伦理边界与使用限制
技术能力越强大,随之而来的责任也越大。VibeVoice 所生成的高质量合成语音,若遭恶意滥用——例如用于制造深度伪造音频进行欺诈、传播虚假信息或进行身份冒充——将可能造成严重的社会危害。因此,所有使用者必须确保输入文本的合法性与真实性,严格核查生成内容的准确性,并承诺不以任何误导性或有害的方式使用其产出内容。
同时,模型本身也存在明确的技术局限性。它当前仅专注于纯净语音的合成,不处理背景环境噪音、背景音乐或其他附加音效。现有的对话模型亦未显式建模或生成真实对话中可能出现的语音重叠片段。对于英语和中文之外的其他语言输入,其合成结果的稳定性和质量可能存在不可预期的波动。
这些局限性也解释了为何项目团队强调,VibeVoice 目前主要定位于研究与开发目的,在未经充分测试、安全评估与针对性开发前,不建议直接用于生产环境或商业应用。遵守当地法律法规,在分享任何 AI 生成的语音内容时明确标注其合成来源,是每一位使用者应遵守的基本伦理与实践准则。
AI 语音技术的演进日新月异,从项目在 GitHub 上的星标增长趋势即可看出全球开发者社区对其抱有的高度关注。作为一个开放源代码的研究框架,VibeVoice 的未来发展依赖于社区的积极协作、负责任的实验探索以及建设性的反馈。无论是尝试其在线实时语音合成演示,还是探索其在超长文本生成上的能力边界,每一次负责任的测试都在帮助我们共同界定这项前沿技术的可能性,并为其构建稳健的伦理应用框架。




