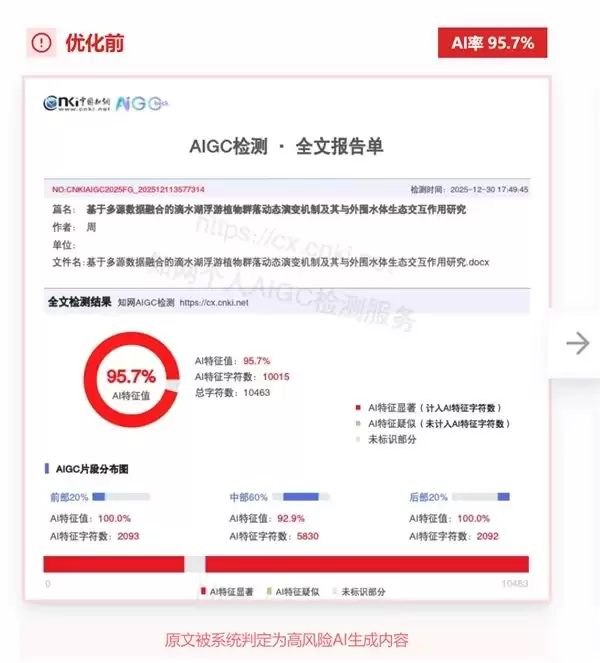
为了帮你解决“越改AI率越高”的难题,我们整理了最新降AI攻略。有些同学改了整整两天,AI检测率反而从45%涨到了52%——这种情况在小红书上引发热议,几百条回复里,一半是同样崩溃的经历,另一半分享了各种有效方法。不过,按那些方法改完,花1天时间就把AI率降到了28%。
这种现象听起来荒诞,却真实发生在大量论文作者身上。更诡异的规律是:你改得越认真、越仔细、越努力,AI检测率反而涨得越快。
为什么会出现这种情况?这篇文章将一次性讲清楚背后的原理与应对策略。
为什么论文AI率越改越高?
一、同义词替换方法基本失效
2025年之前,检测系统主要盯着词汇层面的特征。把“此外”换成“另外”,把“研究表明”改成“有研究指出”,确实能骗过当时的算法。但2026年的知网AIGC不再只看单个词了。
现在的检测逻辑是多维度的:词级、句级、段落级、篇章级,四个层次同时分析。你在词级做的所有替换,对句级和段落级的模式几乎没有影响。更糟糕的是,大量同义词替换会破坏文本的词频自然分布。人类写的文章,某些词会反复出现,形成习惯性的词汇偏好;而AI生成的文章,词汇分布更均匀、更整洁——同义词替换之后,这种均匀分布不但没有消失,反而因为替换本身的机械性,在某些局部产生了新的规律性特征,被检测系统识别为经过处理的AI文本。

二、用AI改AI的恶性循环
“用豆包帮我润色一下,语气更自然点。”这是最常见的操作,也是最致命的错误。
问题不在于豆包润色得不好,而在于:你用一个AI系统去修改另一个AI系统生成的文本,然后用检测系统去判断结果是否像人写的。这个闭环从逻辑上就是死结。豆包的润色风格有自己的特征模式——句子长度的分布、连接词的使用频率、段落的起手方式。当你把AI生成的文本交给豆包润色,它会把原文本的AI特征部分保留、部分替换,同时叠加上自己的AI写作特征。两层AI特征叠加的结果不是互相抵消,而是累积。检测系统在这种叠加模式面前反应尤其敏感,因为它见过太多这种处理痕迹——经过AI润色的AI文本已成为检测系统标准训练集之一。
三、局部修改破坏全文风格一致性,制造新的可疑信号
人类写的文章有一种内在的风格统一性。这种统一性不是刻意为之,而是同一个人在同一段时间写作时自然产生的节奏、语气、句式偏好的一致性。当你对文章进行局部手动修改时,修改过的段落和未修改的段落之间会产生风格断裂。前两段是标准的AI式平铺直叙,第三段你改成了口语化的短句,第四段又回到了AI式的结构完整句——这种风格的跳跃不是人类写作时的正常变化,而是一种特殊的不连续性。2026年的检测系统专门针对这种不连续性进行了优化训练。风格断裂在检测算法中是一个强阳性特征——它不降低AI率,反而主动拉高AI率,因为这种模式几乎只在人工修改AI文本的场景下出现。
你以为在降低AI率,实际上是在创造一个新的检测点。
AI痕迹的本质:不是某个词,是整篇文章的写作风格特征
AI痕迹不存在于任何单一的词、句子或段落。它是整篇文章在多个维度上同时呈现的统计规律——检测系统通过这种规律判断文本的生成来源。这意味着,所有只针对局部的修改——换词、换句、局部重写——都不能从根本上改变这个节奏。它们改变的是具体的音符,但乐曲的节拍结构没有改变,检测系统依然能听出来。
理解了以上原理,正确的处理路径就清晰了。降AI不是一个词一个句子的事,而是要同时调整信息密度的不均匀性、句子长度的随机变化范围、段落风格的自然起伏、连接词和过渡语的使用频率,以及整体的呼吸节奏。这些调整之间还需要相互协调:如果只改信息密度而不改句式,检测系统会发现两个维度之间的不一致性,反而产生新的可疑信号。
比话的技术方案:Pallas NeuroClean 2.0 引擎如何处理
比话(bihuapass)专门适配知网AI,其底层引擎Pallas NeuroClean 2.0的设计逻辑正是针对上述问题从架构层面给出的解法。动态语义熵平滑是其中的核心模块。语义熵是一个衡量信息密度分布均匀性的指标——AI文本的语义熵非常低,因为信息分布过于均匀。动态语义熵平滑会主动识别全文的信息密度分布,然后对高密度区域和低密度区域分别进行差异化处理,最终让全文的信息密度曲线呈现出人类写作特有的不规则起伏。
这解决了手动修改永远解决不了的问题:信息密度维度上的AI特征。RLHF(基于人类反馈的强化学习)机制确保处理后的文本不只是不像AI写的,而是像人写的。这两件事不是等价的。去除AI特征和模拟人类写作特征,是两个方向的工作,需要分别优化。RLHF通过大量人类写作样本的反馈训练,让引擎在去除AI模式的同时,主动叠加人类写作的统计特征,包括自然的风格不一致性、可控的信息密度波动,以及真实人类写作中存在的合理瑕疵。

全文优化:Pallas引擎不在词级别工作,而是把文本作为一个整体的统计对象进行分析和重建。这意味着它处理的正是检测系统判断的真实维度——全文的节奏、密度、风格分布,而不是在检测系统已经不怎么关注的词汇层面做表面工夫。
AI率越改越高的根本原因,是手动修改在错误的维度上做了错误的事。词级别的操作对付不了篇章级别的检测逻辑。如果你的论文还在越改越高的循环里,那问题不在于你不够努力,而在于努力的方向从一开始就错了。




