Elasticsearch 搜索引擎核心概念与实战入门
在当今的数据检索领域,Elasticsearch 作为一款分布式搜索引擎,无疑是开发者和技术团队的首选方案之一。它的核心机制是将复杂的数据结构序列化为 JSON 文档进行存储,而非传统关系型数据库的行列式表格。这就好比一个高度灵活的超大文件柜,每个抽屉都可以独立定义布局,极大提升了数据管理灵活性。更重要的是,当集群中部署了多个节点时,文档会自动分散存储在各个节点上,任何节点都能迅速响应查询请求,用户几乎感知不到延迟,实现近乎实时的全文检索体验。
为什么需要 Elasticsearch?应用场景与优势
当项目发展到一定规模,数据量激增时,传统关系型数据库的查询速度会显著下降,成为性能瓶颈。即便花费大量精力添加索引、优化 SQL 语句,依然难以满足高并发和低延迟的需求。此时,采用 Elasticsearch 这样的分布式搜索引擎,能够有效解决大规模数据检索的痛点。
Elasticsearch 环境准备与前置条件
要想动手尝试 Elasticsearch 操作,前提是你已经在 Docker 中成功安装并启动了 Elasticsearch 容器,且开放了对应端口。下面我们直接进入正题。
这里有个小建议:配合 Elasticsearch 官方文档一起学习,效果会更佳。
接口调试工具方面,推荐使用 Postman 或 Apifox 来发送 HTTP 请求,验证 Elasticsearch 的各项操作。
使用 Postman 进行 Elasticsearch 接口调试
添加员工(索引文档)
首先向索引库中写入几条数据,这样后续查询时才有内容可查。注意,添加数据使用的是 PUT 请求。
仔细看这个 URL 的结构:
- megacory:索引库名称
- employee:类型(Type)
- 1:文档 ID
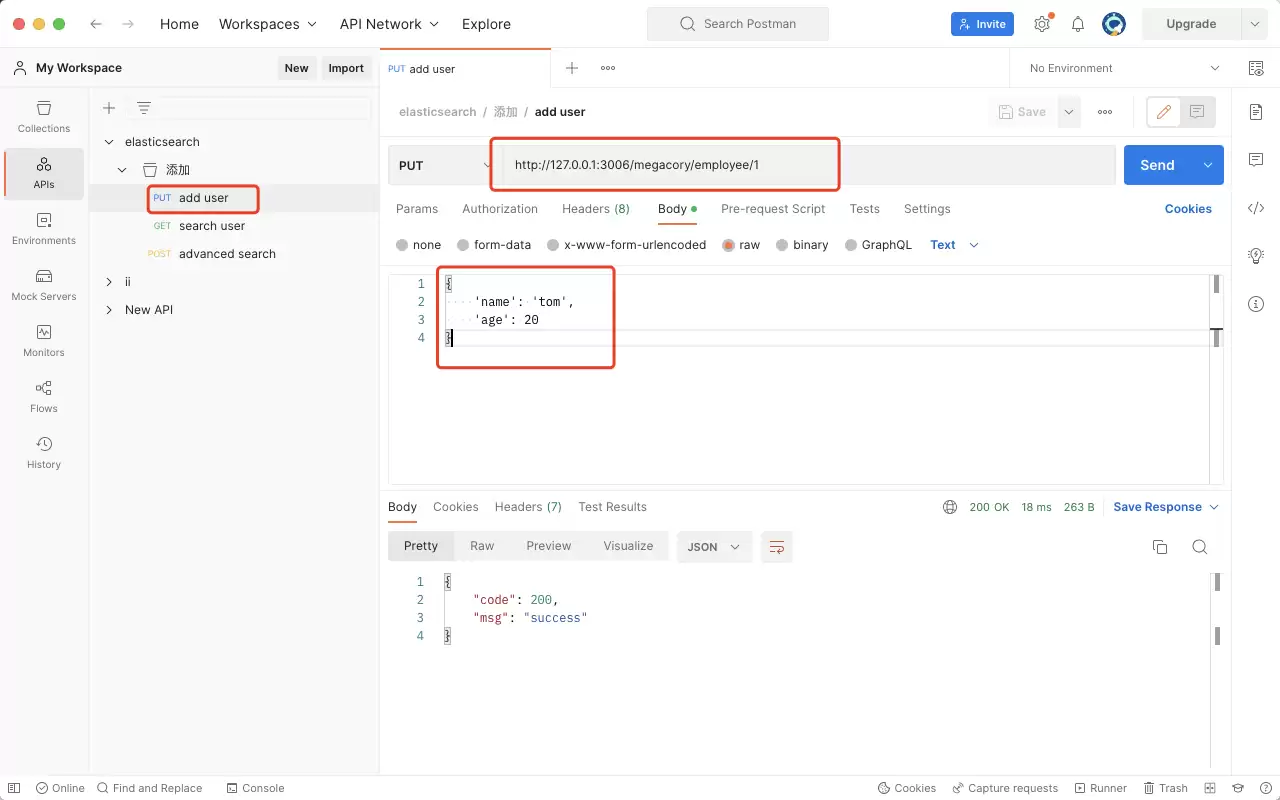
发送请求后,这条员工信息就成功存储到了 Elasticsearch 的“数据库”中。
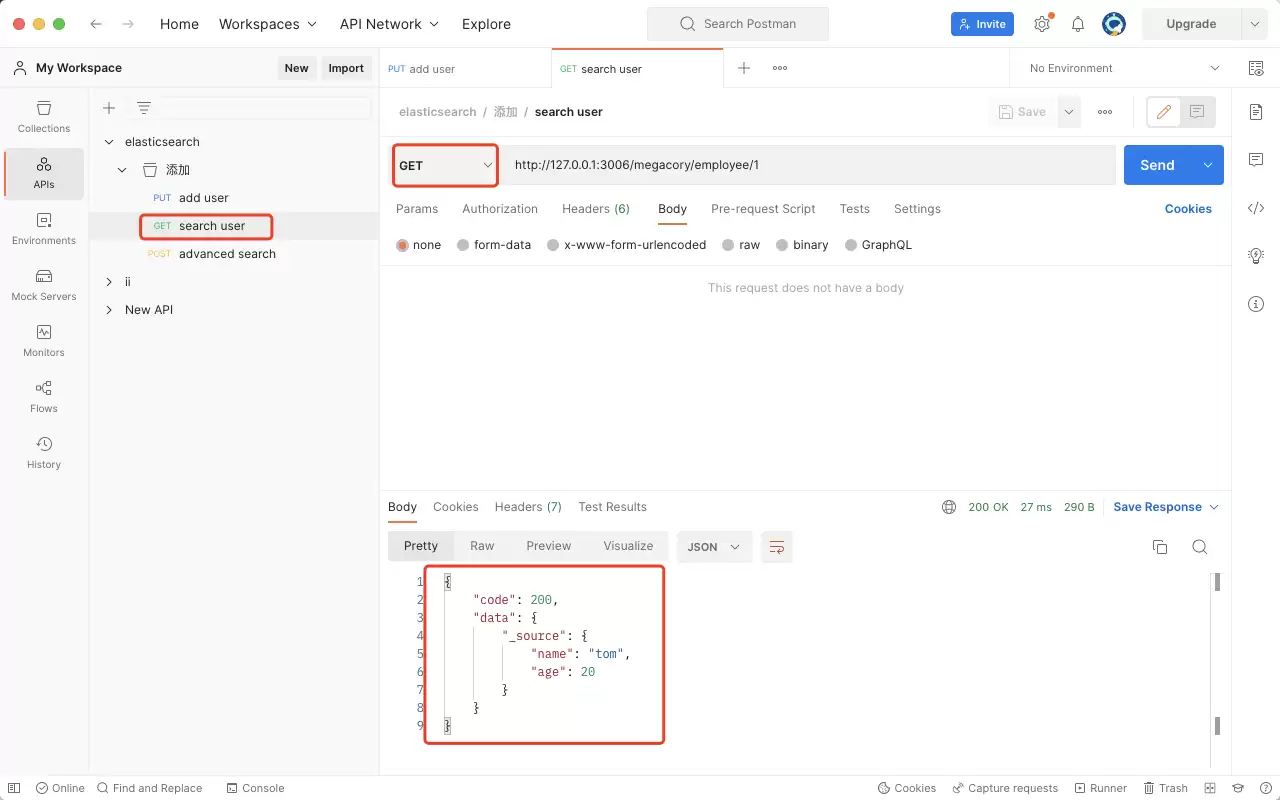
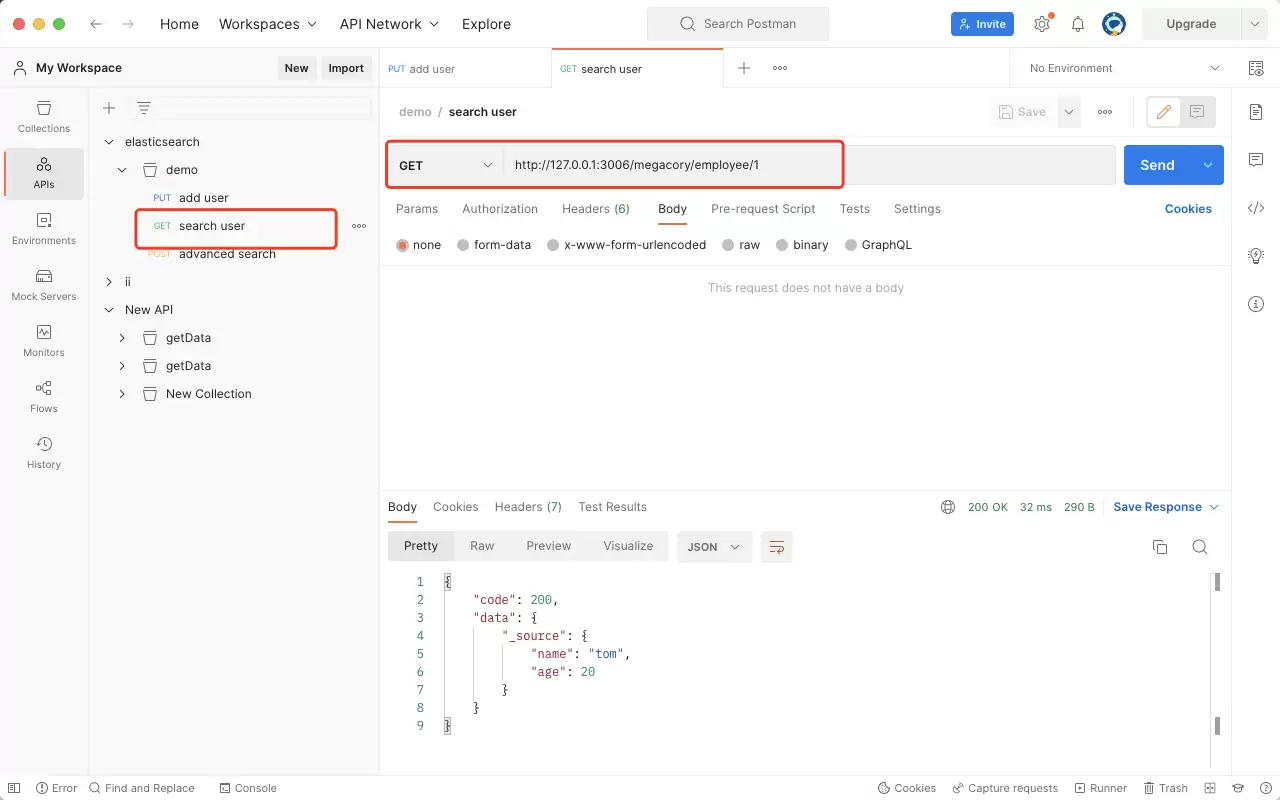
查询员工(根据 ID 获取文档)
查询操作更为简单,仅需一个 GET 请求即可完成。URL 格式与添加时完全一致:
- megacory:索引库
- employee:类型
- 1:文档 ID
即可返回对应员工的详细信息。
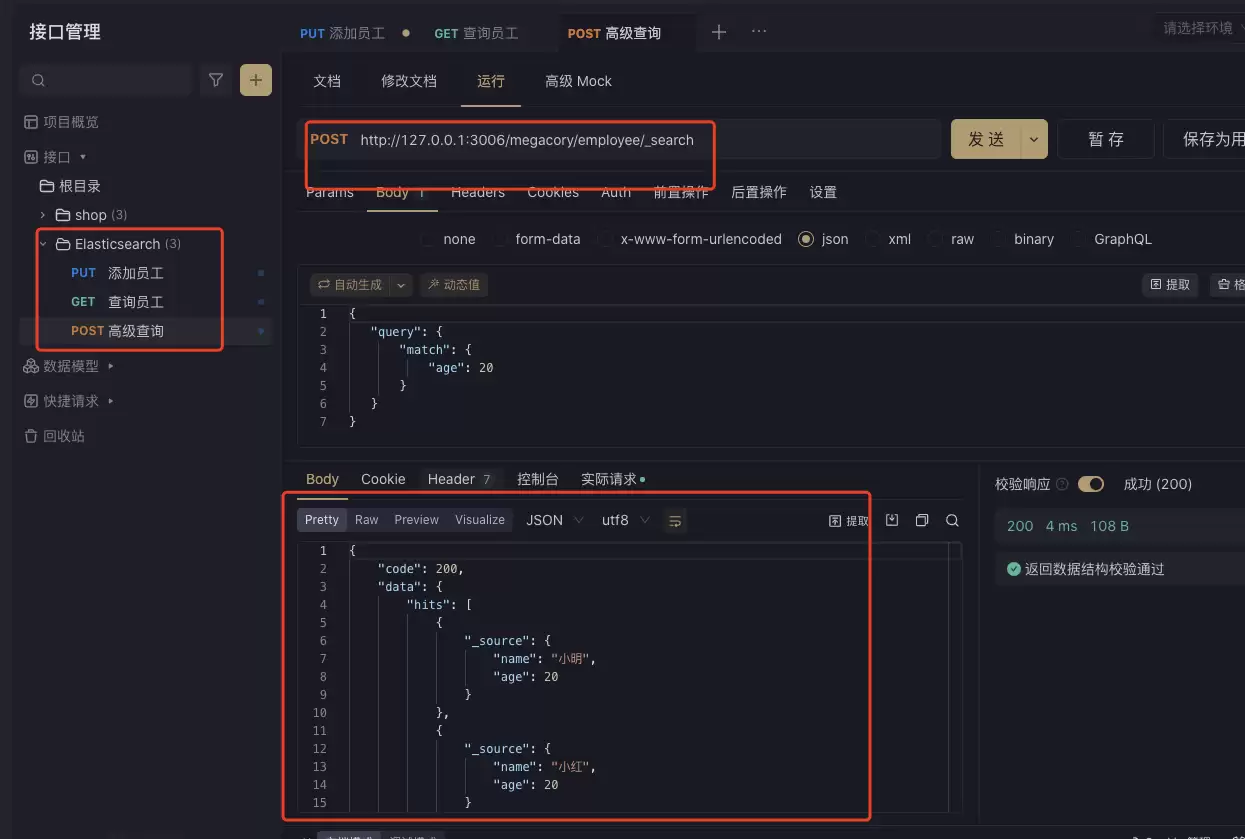
高级查询(条件搜索)
当数据量增大后,简单的 ID 查询已无法满足需求。例如,只想找出年龄为 20 岁的员工,该如何操作?使用 POST 请求结合查询条件即可完成:
- 请求方式:POST
- 接口地址:/megacory/employee/_search
- 请求参数(Body):
{ "query": { "match": { "age": 20 } }}
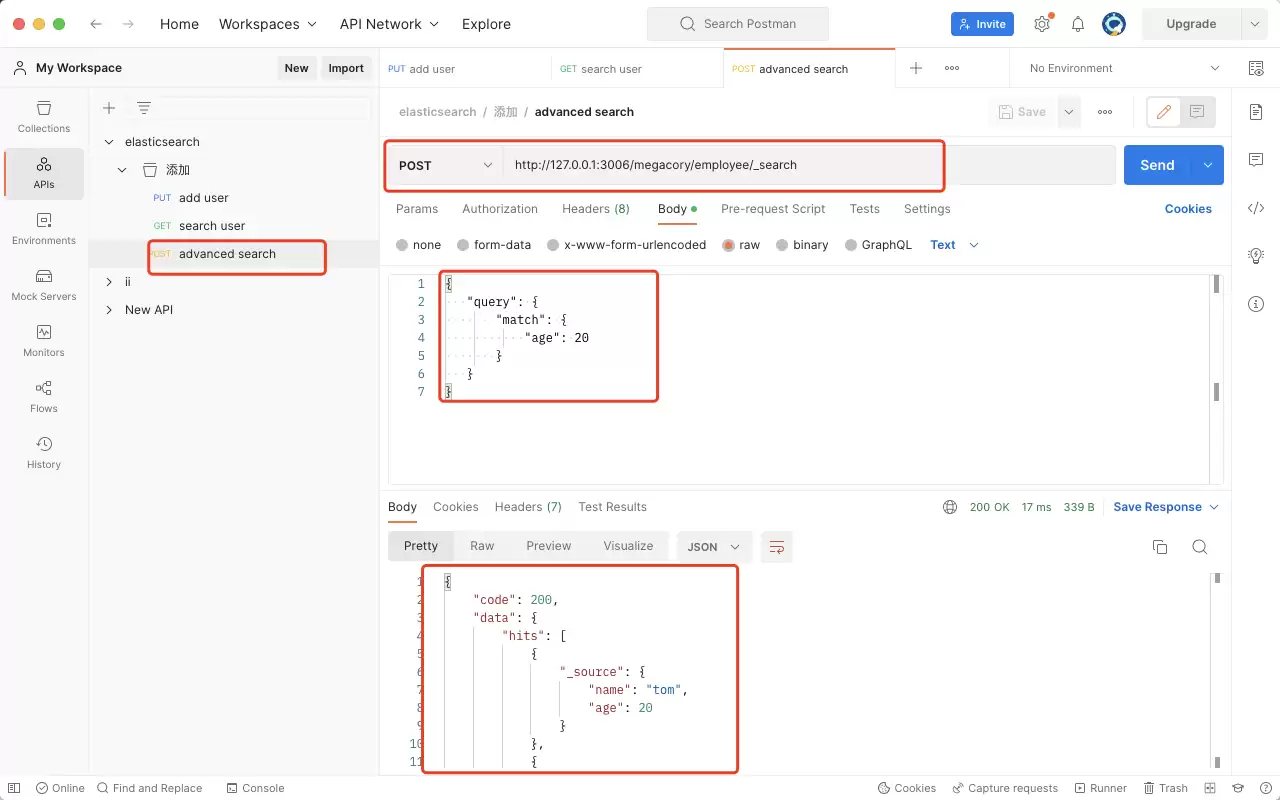
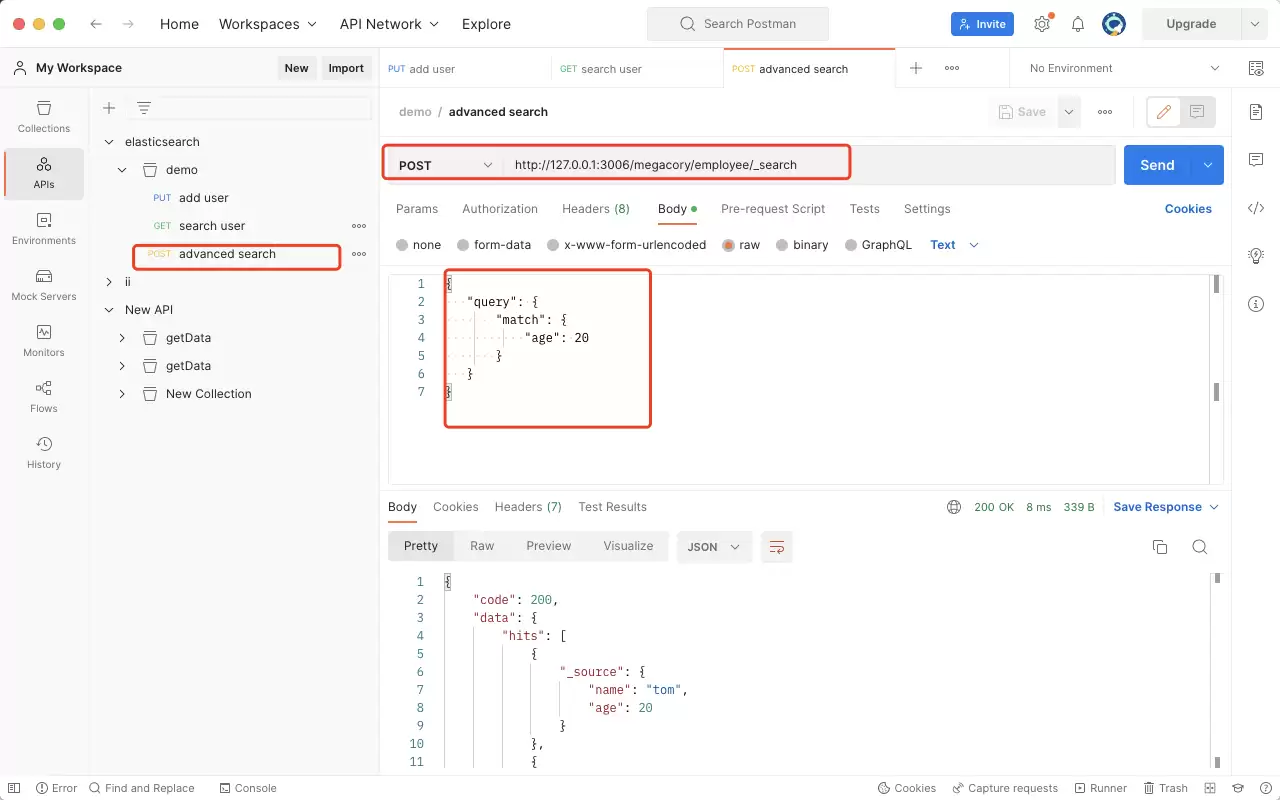
按照上述方式操作,返回的结果就全部是年龄为 20 的员工了。
使用 Apifox 进行 Elasticsearch 接口调试(中文界面友好)
如果你更习惯使用中文界面,Apifox 是一个不错的选择。它的操作逻辑与 Postman 几乎无缝衔接,上手毫无压力,同样支持 RESTful API 的调试。
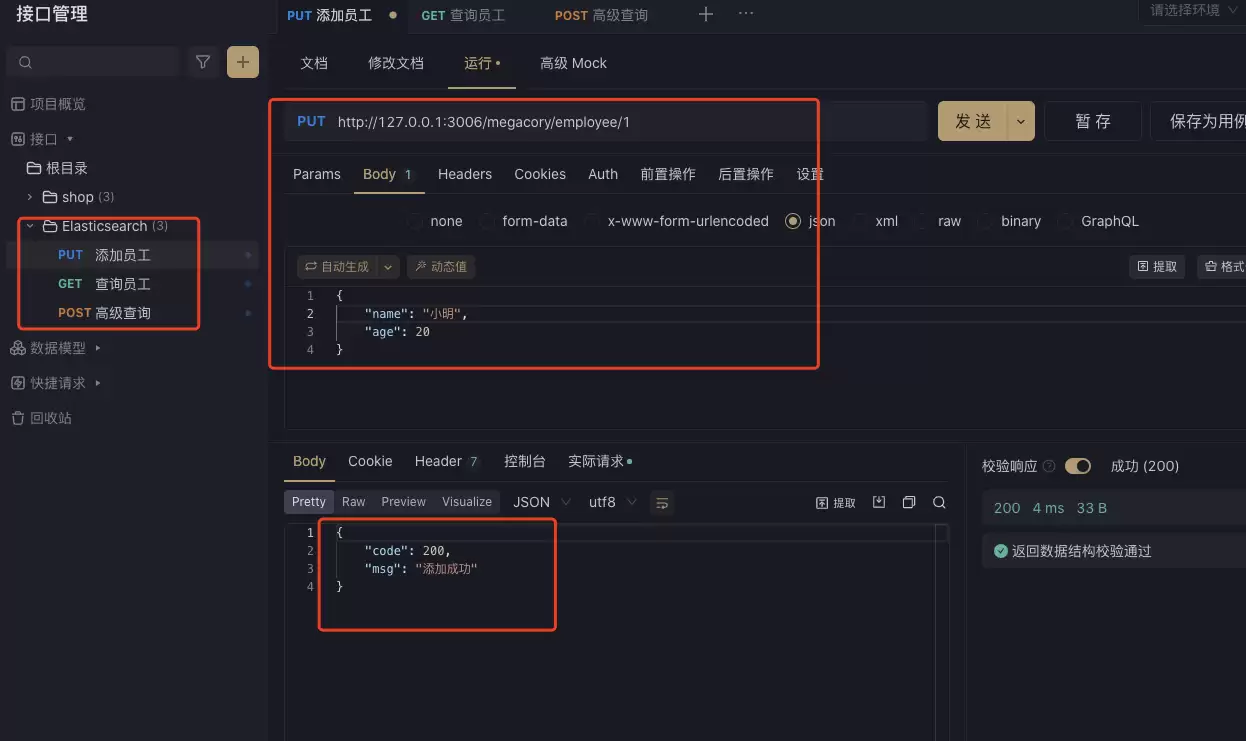
添加员工(Apifox)
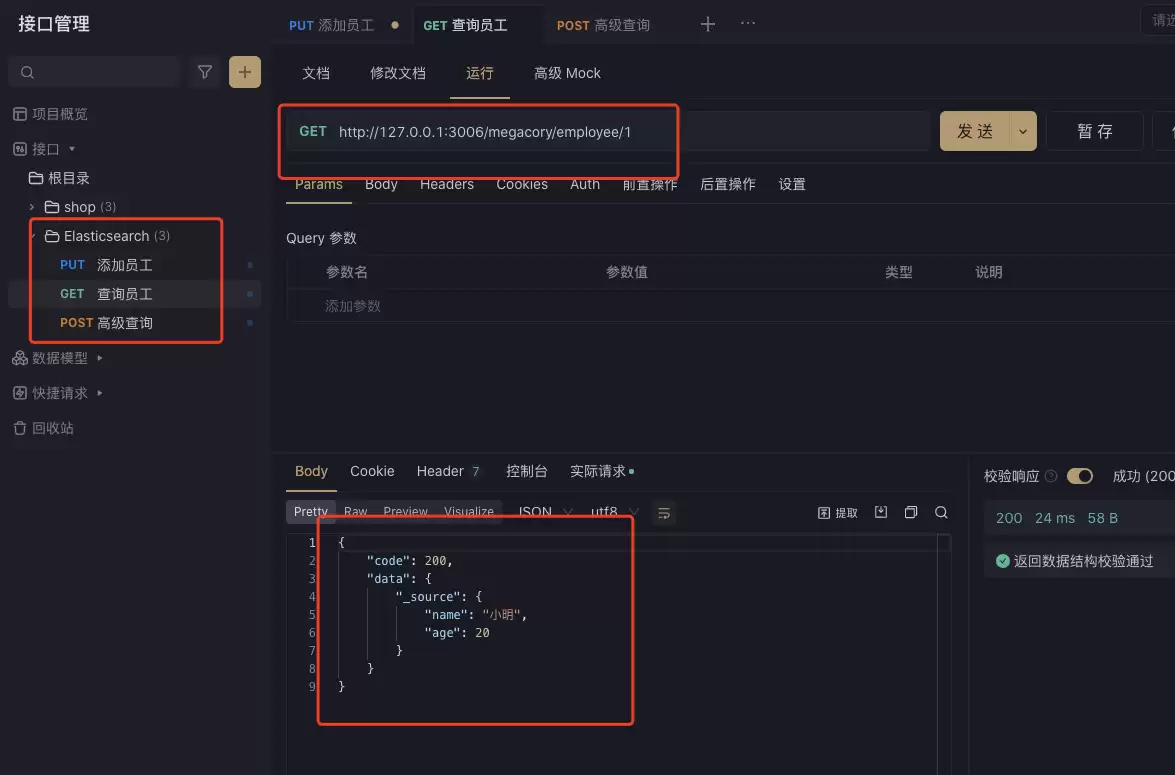
查询员工(Apifox)
高级查询(Apifox)
总结与进阶建议
本文通过 Postman 和 Apifox 两款工具,带领读者快速入门 Elasticsearch 的基本操作:添加员工、根据 ID 查询以及基于条件的高级检索。要真正掌握 Elasticsearch 的深度应用,建议结合官方文档进行系统性学习,并多加动手实践,逐步熟悉分词、聚合、索引优化等高级特性。
知识扩展:Postman 进阶用法
想了解更多 Postman 的使用技巧,比如:
- 如何在 Postman 中配置和使用证书(SSL/TLS)
- 如何在 Postman 中进行 HTTPS 请求的调试与测试




