MCP,全称Model Context Protocol,说白了,就是一套让AI工具能跟外部世界打交道的标准接口。有了它,AI才能去连搜索引擎、读代码仓库、抓网页内容、操作浏览器、查编程文档……没有它,AI能做的不过是在本地文件里翻翻,或者在终端上跑几条命令。有了它,它就能去互联网上搜索、去GitHub上读议题、去抓取网页内容、去查最新的库文档。
很多人兴冲冲装了一堆MCP Server就开干,从来没认真想过:到底该装哪些?密钥怎么管?出问题了从哪开始查?结果就是——Server越装越多,上下文被工具列表挤得满满当当;密钥明文写在配置文件里,跟着Git到处传播;某个Server挂了,完全不知道从哪下手。能用,但远没到好用。
这篇东西,按五个核心模块逐个拆解。每个模块都会说清楚:该配什么、为什么这么配、怎么判断用得好。已经在用MCP的,读完可以直接动手优化配置。刚接触的,建议先去看官方的基础教程,搞清楚基本概念,再回头理解它在整个体系里的位置。
一、协议原理 — MCP到底是什么
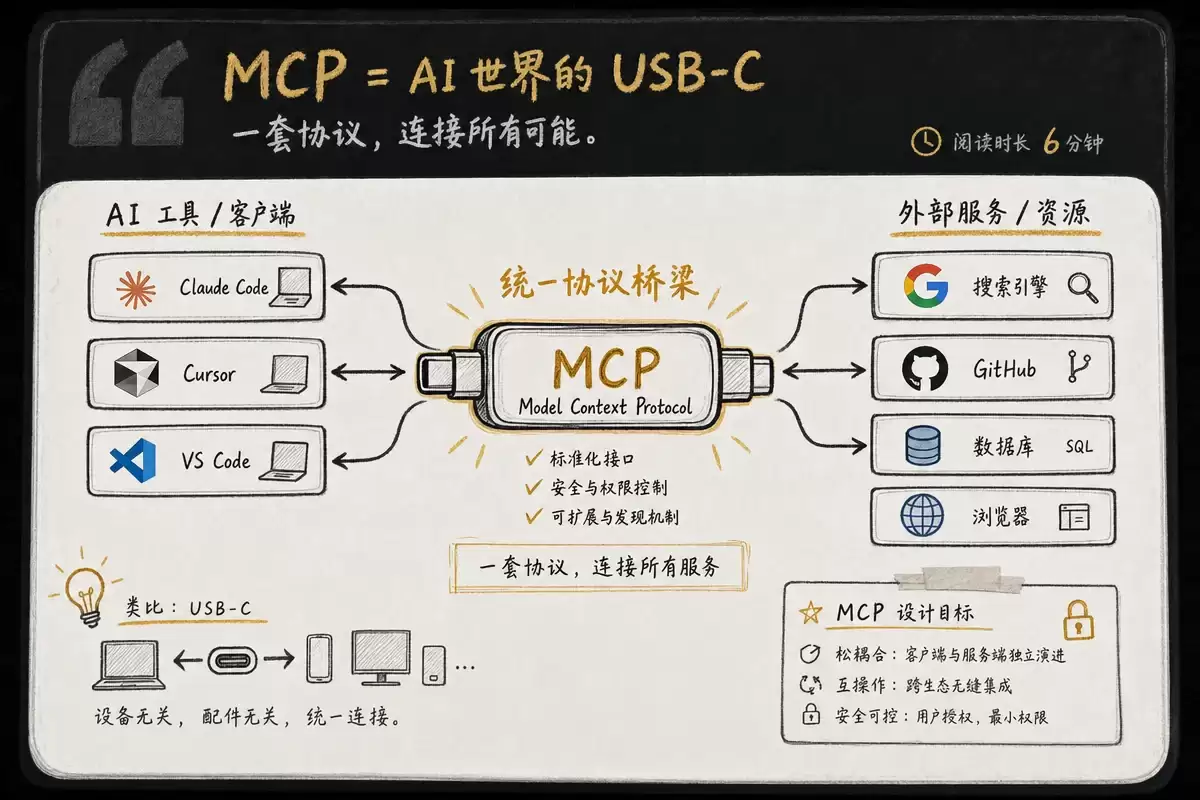
在MCP出现之前,每个AI应用要连接外部服务,都得单独写一套适配层。Claude要读GitHub是一套代码,ChatGPT要读GitHub又是另一套。每增加一个AI工具或一个外部服务,集成工作量就成倍增长——经典的N×M问题,谁也逃不掉。
MCP的解法很直接:定义一套标准协议,让所有AI应用(客户端)和所有外部服务(服务器)都按同一个规范通信。就好比USB-C接口——让所有电子设备用同一根线连接。一个MCP Server写一次,Claude Code、Cursor、VS Code都能用。
三个角色和两层架构
MCP遵循客户端-服务器架构,包含三个核心参与者:
宿主(Host):运行AI模型的应用程序,像Claude Code、VS Code、Cursor这些都是。客户端(Client):宿主内部创建的组件,每个客户端维护与一个Server的专用连接。比如Claude Code连GitHub Server时,会实例化一个客户端对象;连Firecrawl Server时,又实例化另一个。它们互不干扰。服务器(Server):向客户端提供数据和可执行能力的程序,可以跑在本地,也能跑在远程。
传输层面,MCP支持两种机制。标准输入输出(stdio)用于本地进程通信,零网络开销,Server生命周期跟随宿主进程,绝大多数个人开发者都走这条路。流式HTTP(Streamable HTTP)用于远程服务器通信,支持多客户端并发,集成OAuth 2.1认证,只有当你把Server当产品来部署时才需要考虑。
三大原语
MCP通过三个原语定义Server能向AI提供什么:
工具(Tools)——AI可以主动调用的函数。每个工具都需要定义名称、自然语言描述和输入参数的JSON Schema。AI根据用户请求自行判断并调用对应工具。资源(Resources)——AI可以读取的数据源,提供只读数据访问,每个资源有唯一的URI和MIME类型。由应用程序控制何时获取。提示词模板(Prompts)——预定义的交互模板,由用户主动触发,比如一个「代码审查」模板可以按特定维度检查代码。
这里有个关键点要搞清楚:MCP和传统API的区别。传统API是给程序员用的——得读文档、写代码、处理错误、管理认证。MCP是给AI用的——AI自己发现工具、理解参数、调用执行、处理结果。这个设计差异决定了MCP协议里必须包含工具的自然语言描述(description字段),让语言模型能判断什么时候该用什么工具。传统API的文档是写给人看的,MCP的描述是写给AI看的。
传输方式怎么选
两种方式的选择其实很简单:
用标准输入输出的场景:Server只需要给一个用户用(你自己的Claude Code、Cursor)、Server需要访问本地文件系统或数据库、对启动速度有要求、不需要多客户端同时连接。用流式HTTP的场景:Server部署在云端供团队多人使用、需要标准HTTP认证、需要水平扩展承载高并发。
实际使用中,个人开发者的Server几乎都走标准输入输出——简单、快速、不需要管网络和认证。
二、常用Server推荐 — 该装哪些、不该装哪些

不是越多越好
每个MCP Server的工具列表和描述都会占用上下文空间。装了15个Server、每个暴露5个工具,就是75个工具描述永久塞在窗口里。AI在决定用哪个工具时会产生选择困难——就像面前摆了75把不同的扳手,每次都得花时间辨认该用哪把——推理速度变慢,有时甚至选错工具。
推荐策略是「最小集常驻 + 按需启用」:保留3-5个高频使用的Server常驻配置,其余注释掉,需要时再解开。判断标准很简单:一周内用不到两次的,就不该常驻。
推荐配置清单
以下是基于社区热度和实际验证的推荐清单,按优先级排序:
| MCP Server | 解决什么问题 | 为什么选它 | 优先级 |
|---|---|---|---|
| bra ve-search | 搜索互联网获取最新信息 | 中英文搜索效果好,免费额度足够个人日常使用 | 必装 |
| github | 操作代码仓库(拉取请求、议题、代码搜索) | 一个Server覆盖GitHub全部操作,省去手动切到浏览器 | 必装 |
| context7 | 查询编程库的最新API文档 | AI的训练数据可能过时,context7确保查到的是当前版本的用法 | 推荐 |
| firecrawl | 抓取网页内容并结构化 | 对Ja vaScript渲染的单页应用友好——现代网站很多是SPA架构,页面内容由Ja vaScript动态生成,普通抓取工具只拿到一个空壳,firecrawl能等Ja vaScript执行完再抓取 | 推荐 |
| chrome-devtools | 控制浏览器(含登录态操作) | 需要访问已登录页面的内容时,这是唯一选择 | 按需 |
这五个覆盖了日常开发90%的外部工具需求。做数据分析可以按需加PostgreSQL或SQLite;做项目管理可以加Notion或Linear。但不要一开始就全装上。
全局配置原则
在配置任何Server之前,先明确三条铁律:
固定版本安装,禁用动态下载。永远不要在配置中写npx -y 或npx 。每次启动都可能访问npm注册中心,带来2-5秒冷启动延迟。正确做法是全局安装后直接指向二进制路径。凭据与配置分离。API密钥永远不写在配置文件里。使用环境变量注入或独立的密钥文件(权限设为600)。最小权限原则。文件系统Server只开放特定目录白名单,GitHub Server使用细粒度令牌只授予必要仓库的权限。
配置文件在哪
不同客户端的MCP配置文件位置不同:Claude Code在~/.claude.json(用户级)或.mcp.json(项目级);Claude Desktop在~/Library/Application Support/Claude/claude_desktop_config.json;VS Code在.vscode/mcp.json。格式都是JSON,配置结构基本一致。
具体Server的配置要点
Bra ve Search——先全局安装@anthropic/mcp-server-bra ve-search,配置中command指向全局安装后的二进制路径,env中注入BRA VE_API_KEY环境变量。免费Key在bra ve.com/search/api申请。
GitHub——先全局安装@modelcontextprotocol/server-github,env中注入GITHUB_PERSONAL_ACCESS_TOKEN。安全提示:必须使用细粒度令牌,只授予特定仓库的必要权限,绝对不要用传统令牌。
Context7——先全局安装@context7/mcp-server,不需要API Key。使用时先调用resolve-library-id确认库的标识符,再调用query-docs获取文档。
Firecrawl——先全局安装firecrawl-mcp,env中注入FIRECRAWL_API_KEY。实战技巧:对于Ja vaScript渲染的页面,在抓取参数中添加waitFor: 5000(等待5秒),确保动态内容加载完成。
Chrome DevTools——先全局安装@anthropic/mcp-server-chrome-devtools,args中加上--auto-connect参数。使用前需要在Chrome地址栏输入chrome://inspect/#remote-debugging启用远程调试。注意Chrome 144以上版本的--auto-connect模式使用内置协议,curl测试返回404是正常的。
把配置MCP想象成装修工具间:最常用的3-5把工具挂在墙上随手拿(常驻),其余的放进柜子需要时再拿出来(注释掉),工具间钥匙别挂在门外(密钥别明文写配置)。
多客户端共用的注意事项
如果你同时使用Claude Code和Cursor,两者可以连接相同的Server——因为每个客户端会独立实例化自己的客户端对象。但要注意:同一个标准输入输出的Server不能被两个客户端同时启动(进程冲突),它们会各自启动独立进程,不共享状态。Chrome DevTools Server比较特殊——它连接的是同一个Chrome实例,两个客户端同时操作可能冲突,建议同一时间只让一个客户端使用。远程Server(流式HTTP)天然支持多客户端并发,不存在这个问题。
三、自建开发思路 — 现有Server不够用怎么办
当现有的开源Server不能满足需求时,你需要自己写一个。MCP提供了多语言软件开发工具包,让开发过程非常直接。
选择SDK
| 语言 | 包名 | 适用场景 |
|---|---|---|
| TypeScript | @modelcontextprotocol/sdk | Node.js生态,最成熟 |
| Python | mcp | 数据处理、AI/ML场景 |
| Go | github.com/modelcontextprotocol/go-sdk | 高并发服务 |
开发流程的核心三步
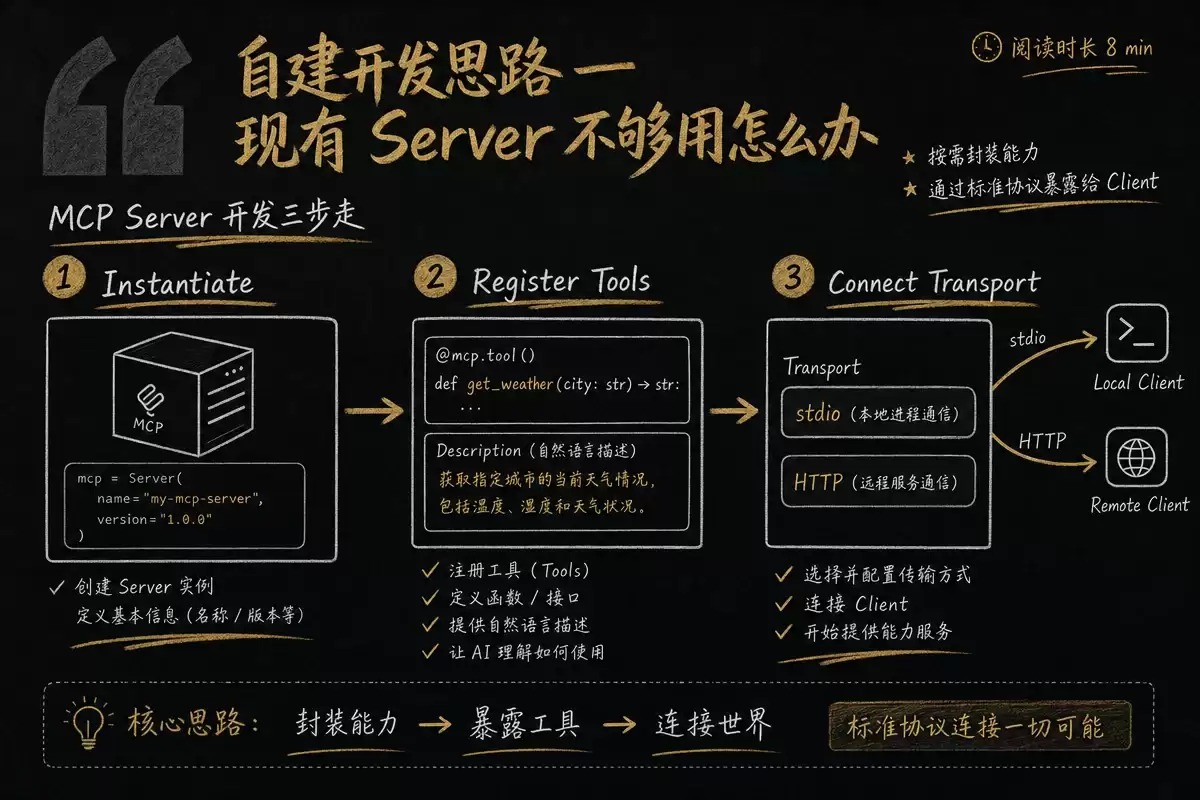
不管用哪种语言,开发一个MCP Server的核心流程都是三步:
第一步:实例化Server。从对应SDK导入Server类,实例化时传入Server的名称和版本号。第二步:注册工具。定义每个工具的名称、自然语言描述(告诉AI这个工具做什么)、输入参数(用JSON Schema或Zod声明参数类型)和处理函数(接收参数并返回执行结果)。这里的描述是整个Server最关键的部分——描述写得不好,AI就不知道什么时候该用这个工具。好的描述读起来像一个条件判断语句:满足条件就触发,不满足就跳过。第三步:连接传输层。创建标准输入输出传输实例,把Server和传输层连起来,Server就开始监听来自客户端的JSON-RPC消息了。
整个过程不到50行代码。
开发MCP Server就像开一个窗口服务——先挂牌子(实例化)、再定义你能办什么业务(注册工具)、最后打开窗口等客户来(连接传输层)。每个业务要写清楚"什么人来办什么事"的描述,不然排队的人不知道该不该到你窗口。
TypeScript和Python的差异
TypeScript版用server.tool()方法注册工具,用Zod定义参数。Python版用装饰器风格——@server.list_tools()定义工具列表,@server.call_tool()实现调用逻辑。Python版的优势是与数据处理和机器学习生态无缝衔接——如果你的工具需要调用pandas、scikit-learn之类的库,Python是更自然的选择。
除了工具,还能暴露什么
一个完善的Server通常不只有工具:资源(Resources)——只读数据源,由应用程序控制何时获取。调用server.resource()方法,传入资源名称、URI和异步读取函数。比如暴露项目的README文件让AI随时查阅。提示词模板(Prompts)——由用户主动触发的预定义交互模板。比如一个「代码审查」模板接收代码片段,生成一条预设好审查维度的用户消息。适合封装团队的标准化工作流程。
远程部署
如果你的Server需要被多个客户端同时使用,或者部署在云端,传输层从标准输入输出换成流式HTTP传输(StreamableHTTPServerTransport),挂载到Express之类的HTTP框架上即可。工具注册部分完全不变。客户端配置时,不再写command和args,而是改成type: "http"加url字段指向你部署的端点。
四、调试排障 — 出了问题从哪开始查
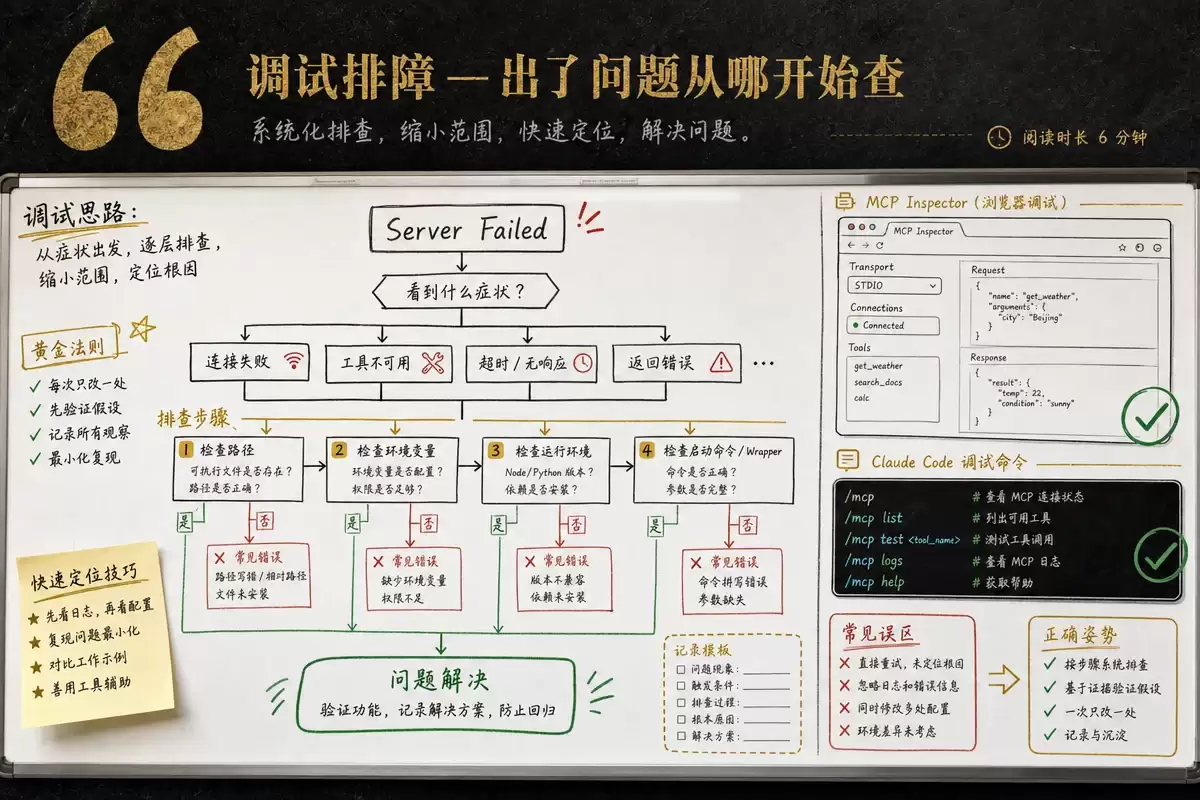
MCP Inspector
MCP Inspector是官方提供的可视化调试工具。通过npx @modelcontextprotocol/inspector加上你的Server入口文件路径即可启动。它提供浏览器界面,可以查看Server暴露的所有工具、手动构造参数执行调用、实时查看请求和响应消息、检查错误信息。
一个关键的调试经验:如果Inspector能正常连接并显示工具列表,但客户端(如Claude Code)连不上,问题一定出在客户端配置——检查路径、参数和环境变量。
Claude Code内置调试
Claude Code内置了几个实用的调试命令:claude --mcp-debug启动时开启调试模式,显示详细的连接信息;claude mcp list查看所有已安装Server及其状态;claude mcp get 查看某个Server的具体配置;在会话内输入/mcp可以实时查看当前所有连接的状态。
四个最常见的问题
Server启动失败(状态显示Failed)——按这个顺序排查:确认命令路径存在且可执行(which 或test -x )→ 确认环境变量正确注入(手动在终端执行同样的命令试一次)→ 确认Node.js或Python在PATH中 → 如果用了包装脚本,确认脚本内的PATH包含必要路径。
配置修改后不生效——MCP配置只在客户端启动时加载。修改后必须完全退出客户端再重新打开。在Claude Code中,就是/exit后重新运行claude。这是新手最容易踩的坑之一——很多人改完配置后用/clear清空会话以为就够了,其实/clear只清空对话上下文,不重新加载MCP配置。必须完全退出再重启。
Chrome DevTools会话死锁——在长会话中操作多个标签页时,如果某个被选中的标签页被关闭(特别是OAuth弹窗自动关闭时),所有chrome-devtools工具都会返回错误,包括list_pages本身。应对方式:操作前先list_pages记录所有标签的标识符,弹窗流程后立即select_page回主标签。死锁后唯一恢复方式是退出Claude Code重开会话。
搜索类Server频繁报错429——原因是触发了速率限制。Bra ve Search等API对免费计划有每秒请求数限制。解决方式:搜索类MCP串行调用,调用间隔至少2秒,不要在同一个提示词中触发多个并行搜索。
五、安全实践 — MCP的最高优先级
MCP赋予AI操作真实系统的能力,安全是最高优先级。一个配置不当的MCP Server可能让AI读到你的SSH私钥、把密钥写进日志、甚至操作生产数据库。
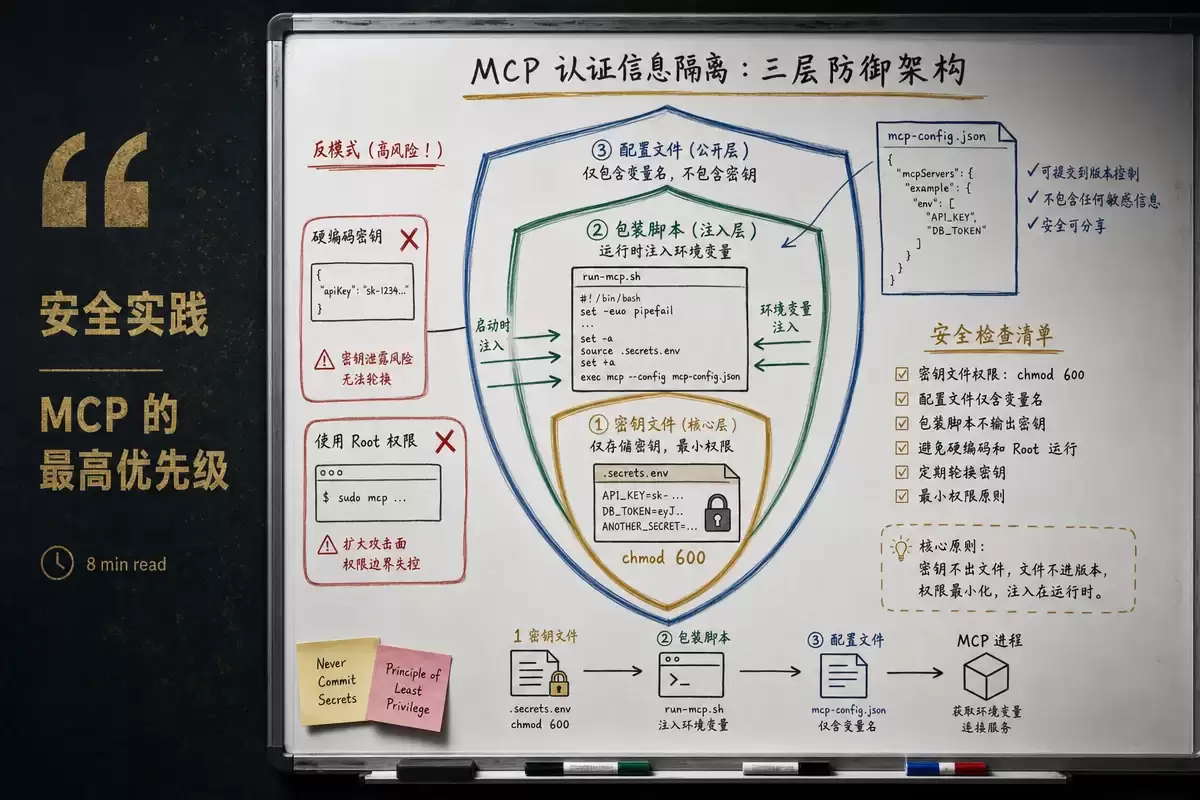
凭据隔离
绝对禁止在配置文件中硬编码API密钥。配置文件可能被提交到Git、被同步工具散播、或被其他工具读取。
正确做法分三步:第一步:创建独立密钥文件。在~/.config/secrets/目录下创建一个.env文件,把所有API密钥以KEY=VALUE格式写入,然后用chmod 600设置为仅所有者可读写。第二步:编写包装脚本。创建一个中间脚本,作用是:读取(source)密钥文件、导出(export)对应的环境变量、然后透传启动真正的Server命令。第三步:配置文件引用包装脚本。MCP配置中command不直接指向Server二进制,而是指向包装脚本,args中传入真正的Server路径。这样密钥永远不出现在配置文件中。
令牌权限最小化
| 服务 | 正确做法 | 错误做法 |
|---|---|---|
| GitHub | 细粒度令牌(Fine-grained PAT),只授权特定仓库 | 传统令牌(Classic Token),全权限 |
| 数据库 | 只读账号,限定特定表 | root账号 |
| Bra ve Search | 免费密钥,按需付费 | 共用企业主密钥 |
文件系统白名单
任何涉及文件操作的MCP Server,必须通过命令行参数显式限定可访问的目录——在args中逐一列出允许访问的具体目录路径。Server只能操作这些白名单内的文件。绝不能开放根目录或用户主目录。
把文件系统白名单想象成出入证——员工的门卡只能进自己部门的楼层,不能进机房。MCP Server也一样,只给它访问它需要的目录,不给它「全楼通行证」。
OAuth 2.1认证(远程Server)
MCP规范要求远程Server使用OAuth 2.1认证。所有客户端必须使用PKCE,令牌必须短生命周期加刷新令牌轮换,必须验证受众(audience)字段防止跨服务器重放攻击。对于本地标准输入输出的Server,安全性依赖操作系统的进程隔离和文件权限。
供应链安全
MCP生态有一个容易被忽视的风险:第三方Server的供应链安全。当你安装并运行一个社区Server时,实际上是在你的机器上执行了一个你不完全了解的程序,并且授予了它访问你的密钥、文件系统或数据库的权限。
降低风险的做法:优先使用官方参考实现(modelcontextprotocol/servers仓库里的Server经过Anthropic审查)→ 锁定版本(全局安装具体版本号,不用@latest)→ 审计代码(对于小众Server,在安装前检查其源码是否有可疑的网络请求)→ 网络隔离(只需要本地操作的Server,确认它没有向外发请求的行为)。
常见误区与反模式
在实际使用MCP的过程中,有几个容易踩的坑值得提前规避:
| 误区 | 后果 | 正确做法 |
|---|---|---|
| 把Server当万能接口,试图替代完整后端API | 职责膨胀,Server变成难以维护的单体应用 | Server只负责「让AI能做某件事」——比如GitHub Server让AI读写议题,而不是重写一个Git客户端 |
| 配置大量Server但不常用 | 浪费进程资源,工具列表过长占用令牌,AI选择工具时犹豫不决 | 只常驻3-5个高频Server,其余按项目或任务临时启用 |
| 在Server内硬编码业务逻辑 | 几百行业务代码塞进Server,维护成本急剧上升 | Server只做协议转译和权限控制,复杂逻辑放在独立的后端服务里,Server通过内部API调用 |
| 忽略错误处理,直接抛异常 | AI收到不友好的错误信息,无法判断下一步行动 | 在工具调用的响应中用isError: true标记失败,内容里给出清晰的错误描述和修复建议 |
| 没有做输入验证,完全信任AI传入的参数 | AI可能传入超长字符串、特殊字符或越界值,造成安全漏洞 | Server端独立验证路径白名单、字符串长度、数值范围——参数的JSON Schema定义是给AI看的文档,Server端的验证才是安全防线 |
生态与展望
MCP已被Claude Code、Claude Desktop、ChatGPT Desktop、VS Code(Copilot)、Cursor、Windsurf、Cline等主流AI编程工具原生支持。GitHub上的awesome-mcp-servers仓库已收录数百个社区Server,覆盖开发工具、数据库、云服务、通信协作、搜索与数据、自动化、AI平台等领域。
MCP协议本身也在快速演进。MCP规范候选版引入了无状态协议核心、扩展框架、长时间异步任务、MCP Apps(在AI客户端内运行的交互式应用)等特性。Agent间通信也被纳入路线图——MCP不再只是AI连工具,还将成为Agent之间的通信标准。
MCP正在成为AI应用的基础网络层。就像HTTP协议让所有浏览器能访问所有网站一样,MCP让所有AI工具能连接所有外部服务。现在是掌握它的最好时机——协议还在快速迭代期,越早形成配置习惯,后续升级越平滑。




