话不多说,先带大家观看一段精彩演示视频。
这段流畅的游戏操作,几乎媲美顶尖技术玩家的实战画面。特别是《茶杯头》中那套连贯的躲避、跳跃、踩踏和灵魂技能衔接,令人自叹不如。如果拥有这样的反应速度与操作水平,玩《丝之歌》时也绝不会轻易“红温”。
最令人惊叹的是,上面这段视频中的所有操作,完全由AI自主完成。
与传统游戏自动化脚本截然不同,这是一个完整的通用大模型,不受单一游戏限制,能够驾驭市面上几乎所有类型的游戏。
那么,今天的主角——来自英伟达(NVIDIA)的最新开源基础模型 NitroGen 正式登场。该模型的训练目标是精通1000款以上游戏——无论是角色扮演(RPG)、平台跳跃、战术竞技(吃鸡)、竞速类游戏,还是2D、3D类型,统统不在话下!

模型直接以游戏视频帧为输入,输出真实的手柄操作信号,天然适配所有支持手柄的游戏。NitroGen 支持后训练(post-training),这意味着当它面对一款从未见过的新游戏时,无需从零学习规则,仅需少量微调或轻量适配即可快速上手,真正具备跨游戏泛化的潜力。

论文地址: https://nitrogen.minedojo.org/assets/documents/nitrogen.pdf
代码链接: https://github.com/MineDojo/NitroGen
预训练模型: https://huggingface.co/nvidia/NitroGen
数据集: https://huggingface.co/datasets/nvidia/NitroGen
模型配方
英伟达研究团队发现,原本为机器人设计的 GR00T N1.5 架构,只需极少改动即可适配机制差异极大的各类游戏。
NitroGen 的设计融合了三项关键要素:
1. 互联网规模的视频-动作数据集:通过从公开可获取的游戏视频中自动提取玩家操作构建而成;
2. 多游戏基准评测环境:用于系统性评估模型在不同游戏之间的泛化能力;
3. 统一的视觉-动作策略模型:采用大规模行为克隆进行训练。
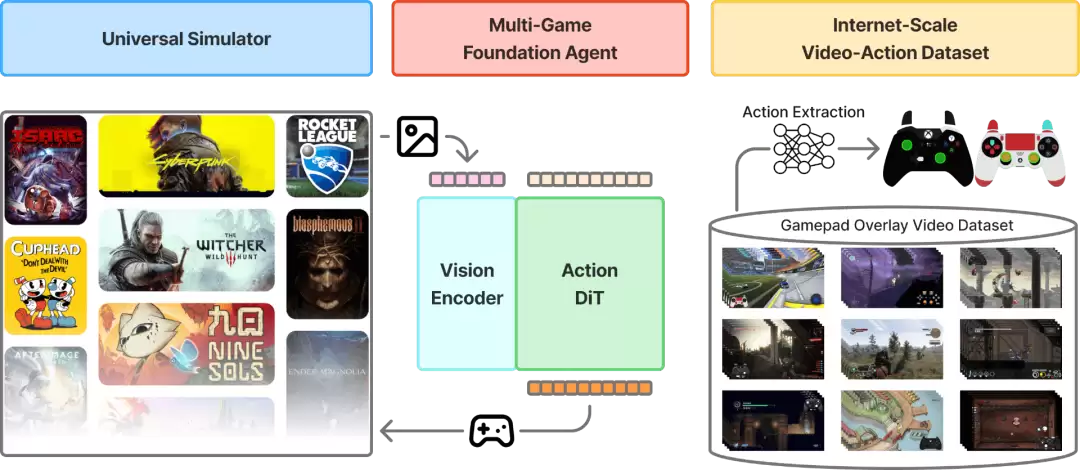
总体概览
NitroGen 由三个核心组件构成:
1. 多游戏基础智能体:一个通用的视觉-动作模型,能够接收游戏观测(如视频帧),并生成对应的手柄操作指令,实现跨多款游戏的零样本游玩能力;同时可作为基础模型,供新游戏进一步微调与适配。
2. 通用模拟器:一个环境封装层,使任意商业游戏都可以通过 Gymnasium API 进行控制,从而统一不同游戏的交互接口,支持大规模训练与评测。
3. 互联网规模的数据集:目前规模最大、类型最丰富的开源游戏数据集之一,来源于40,000小时的公开游戏视频,覆盖1,000余款游戏,并自动提取并生成对应的动作标签。
互联网规模多游戏视频动作数据集
通过从屏幕显示中提取玩家的实时手柄操作来获取动作信息,这类显示被称为“输入叠加层(input overlays)”。
研究团队收集了大量公开可获取的、带有“手柄操作叠加显示”的游戏视频。这些叠加层高度多样,给数据处理带来显著挑战:不同内容创作者使用的手柄类型差异较大(如Xbox、PlayStation或其他控制器),叠加层的透明度各不相同,同时视频压缩还会引入各种视觉伪影。
对于每一段收集到的视频,研究团队会采样25帧图像,并使用SIFT与XFeat特征,与精心整理的模板集合进行关键点匹配,以此定位手柄在画面中的位置。随后,基于模板匹配的结果,对视频中的手柄区域进行定位与裁剪。
数据整理过程本身就很有意思:研究团队发现,玩家非常乐于展示自己的操作技巧,常常会在视频中叠加实时显示的手柄输入。于是团队训练了一个分割模型,自动检测并提取这些手柄显示区域,将其转换为“专家级动作标签”。
随后,研究团队会把这一区域在视频中遮挡掉,防止模型通过“偷看答案”的方式走捷径。在训练过程中,GR00T N1.5的一个变体使用扩散Transformer,从4万小时的像素级输入直接学习到动作输出。
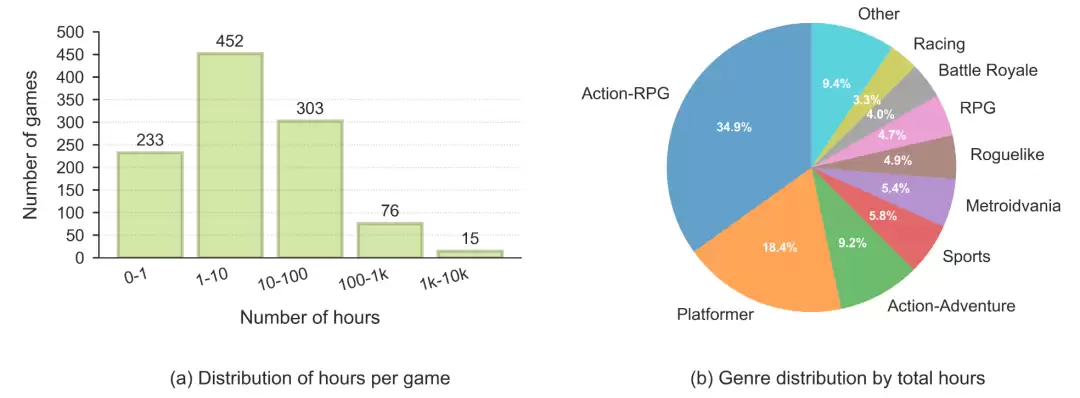
NitroGen 数据集在不同游戏与类型上的分布情况
在完成数据筛选后,该数据集共包含40,000小时的游戏视频,覆盖1,000余款游戏。
(a)单游戏数据时长分布:从每款游戏对应的视频时长来看,数据覆盖范围广泛——846款游戏拥有超过1小时的数据,91款游戏拥有超过100小时的数据,其中还有15款游戏的累计数据量超过1,000小时。
(b)游戏类型分布:从游戏类型来看,动作RPG占比最高,占总时长的34.9%;其次是平台跳跃类,占18.4%;再次是动作冒险类,占9.2%;其余数据分布在多种不同游戏类型之中。
超强操作
实验结果表明,NitroGen 在多种不同类型的游戏场景中均表现出较强能力,包括:3D动作游戏中的战斗对抗,2D平台跳跃游戏中的高精度操作,以及程序生成世界中的探索任务。
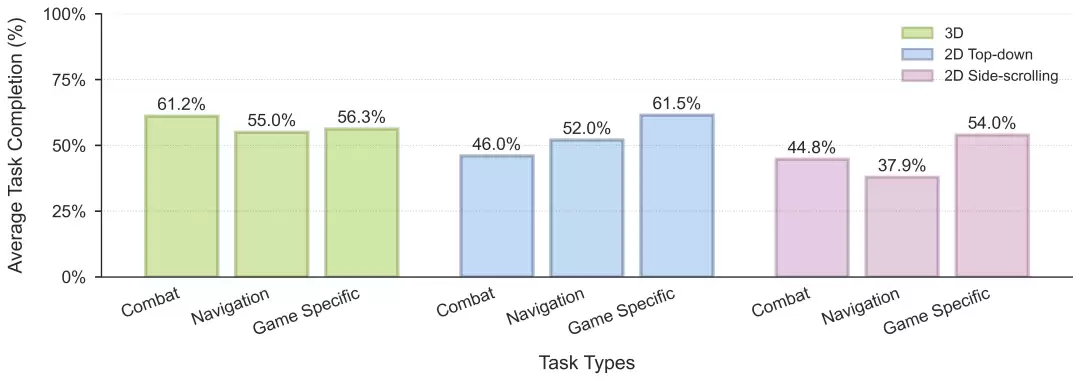
NitroGen 500M 模型在不同游戏上的预训练结果
使用 Flow-Matching 的 GR00T 架构,在完整的 NitroGen 数据集上训练了一个5亿参数的统一模型。评估在行为克隆预训练完成后进行。对于每一款游戏,研究团队在3个不同任务上进行测试,每个任务执行5次 rollout,并统计平均任务完成率。
在未进行任何额外微调的情况下,尽管模型仅基于噪声较大的互联网数据集进行训练,NitroGen 仍然能够在多种游戏中完成非平凡的任务,覆盖了不同的视觉风格(如3D、2D俯视视角、2D横向卷轴)以及多样的游戏类型(平台跳跃、动作RPG、Roguelike等)。
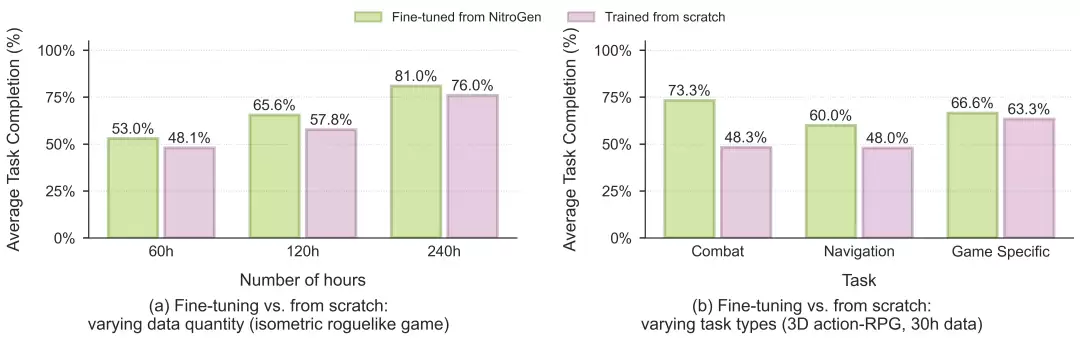
后训练实验结果
更重要的是,NitroGen 能够有效迁移到从未见过的新游戏。在相同任务设定下,其任务成功率相比从零开始训练的模型,最高可实现52%的相对提升。
这项工作足以“杀死比赛”。
通用机器人的基础
NitroGen 只是一个起点,模型能力仍有很大的提升空间。研究团队在此次工作中有意只聚焦于无需深度思考、快速反应的“玩家直觉式运动控制”。
据英伟达机器人总监 Jim Fan 表示,他们的目标是打造通用型具身智能体:不仅能掌握现实世界的物理规律,还能适应一个由无数模拟环境构成的“多元宇宙”中的所有可能物理规则。
这就是为什么众多交互大模型都对电子游戏的操作念念不忘。电子游戏具备相当完整的世界和交互体系,每个游戏都是一个非常复杂完善的模拟环境,模型能够实现通用的游戏操作,离操作机器人进行真实世界交互也就更进一步。
英伟达已开源发布该模型的数据集、评测套件以及模型权重,以推动通用具身智能体方向的进一步研究。
今天,机器人学是AI中“最难问题的超集”。明天,它可能只会成为具身AGI巨大潜在空间中的一个子集、一个点。
那时,只需要用自然语言提示,请求一个机器人“游戏手柄”即可。




