上个月我与一位测试总监交流时,他提到团队已经利用大模型+Skills成功实现了某个核心场景的自动化生成。然而,仅仅两周后,他便果断将该Skill强制下线了。
原因非常直接:生成的测试用例要么粒度把控不当,要么过于粗略,导致边界条件遗漏;要么过于细致,每次执行都因环境波动而反复失败。更令人困扰的是,同一个Skill上午运行正常,到了下午就完全失效。
这种现象并非个例。过去几个月中,我调研了十余个团队在Skills测试中的落地实践,发现大家遇到的障碍惊人相似。今天我们不谈抽象概念,直接分享实战中踩过的坑,并总结出四条关键原则。
一、看似美好的Skills,落地时却不堪一击
第一个陷阱:粒度拆分失当。
有人将“测试整个下单流程”写成一个单一的Skill。结果,大模型面对这个庞大的意图,生成了一个包含登录、选品、加购、下单、支付、查订单的超级脚本。中间任何一个环节的环境数据出现偏差,整个用例就会宣告失败。更糟糕的是,这个Skill几乎无法复用——只要更换商品类型,就必须重写全部内容。
第二个陷阱:稳定性难以保障。
同一个Skill,今天还能准确生成Playwright脚本,明天面对同样的自然语言输入,生成的脚本中元素定位器却发生了变化。这并非大模型随机波动,而是因为没有对输出施加必要的约束。测试的本质追求确定性,而大模型的天性则是概率性。这对矛盾若不加以解决,Skill就只是徒有其表的玩具。
许多人将Skills视为“提示词模板”的升级版,直接塞入数百行描述,期望大模型自行领悟。结果呢?能用,但不可控;能跑,但不稳定。
请牢记这句话:Skills落地最大的阻碍并非大模型能力不足,而是你尚未学会如何为它划定清晰的边界。
二、本质是意图与执行之间的“粒度鸿沟”
这些陷阱为何会出现?核心原因只有一个:意图的粒度与执行能力不匹配。
人类给出的测试意图高度抽象,比如“测试登录失败场景”。但执行层面需要具体步骤:定位用户名输入框、输入特定格式的用户名、定位密码框、输入密码、点击登录按钮、等待响应、验证错误提示。
传统测试框架依赖脚本桥接这一鸿沟。脚本中每一步都写得非常死板。而在Skill模式中,桥接任务交给了大模型。然而,如果你不为大模型提供充分的结构化指引,它就只能依靠猜测。在不同时间、不同上下文下,猜测出的结果自然难以一致。
本质问题在于:Skills需要将人的意图拆解为标准化的“原子操作”,再由大模型根据当前系统状态动态组装。如果没有人来完成这个拆解工作,结果必然陷入混乱。
另一个稳定性问题的根源:输出格式缺乏约束。大模型返回的测试脚本格式飘忽不定,有时是Python,有时是JavaScript,甚至混入Markdown标记。解析器遇到意外格式,就会直接崩溃。
三、四条核心原则:拆粒度、控稳定性、定边界、强反馈
经过多轮重构,我总结了四条关键原则。每一条都来自生产环境的真实教训。
原则一:Skill的粒度 = 一个不可再分的业务验证点
一个Skill应该承担多少任务?答案非常明确:一个Skill只做一件事,而这件事是一个业务上不可再分的验证点。
举例来说:
- 错误的粒度:“测试订单流程” → 过于宽泛,包含多个验证点
- 正确的粒度:“验证已登录用户添加商品到购物车后,购物车数量增加1”
为什么要坚持这一点?因为只有达到这个粒度,你才能像搭积木一样自由组合。每个积木职能清晰,才能拼出复杂场景。如果一个Skill内部已经包含了登录、选品、加购,你就无法将它与其他“验证不同支付方式”的Skill组合,因为登录动作会重复执行。
记住这个判断标准:Skill的粒度应当小到你可以确信它不会失败——除非被测系统本身确实存在缺陷。
原则二:用输出格式强制约束,而非依赖大模型自觉
解决稳定性问题最直接的方法:不给大模型自由发挥的空间。
在每个Skill的核心指令中,必须明确指定输出格式。不是用自然语言说“请输出JSON”,而是直接给出JSON Schema,并明确告知大模型:不符合Schema的输出被视为无效,需要重试。
我的团队具体做法是:在每个Skill的第三层(完整执行层)中,放置一个 output_schema.json 文件。大模型在生成前必须读取该文件,生成的输出会经过一个校验器。不通过就回退重新生成,最多重试3次。
实际测试表明,这个机制能够将输出格式的稳定性从70%直接提升至98%以上。
原则三:每个Skill必须有独立的环境预检和回滚
另一个常见的崩溃场景:Skill执行中途失败,留下了脏数据。下次再运行同样的Skill,由于环境状态不一致,结果就完全不同了。
解决方案是:每个Skill在执行前,先调用一个“环境预检”脚本,确认前置条件都已满足(比如测试用户已存在、购物车为空)。执行后,无论成功还是失败,都调用“回滚”脚本清理数据。
请注意,这个预检和回滚逻辑不应写在Skill的主流程中,而应作为Skill的“基础设施”独立出来。Skill只需声明自己依赖的环境状态,具体的检查和清理工作由框架完成。
原则四:将大模型的决策过程暴露出来,而非当作黑盒
很多人将Skill当作黑盒使用:输入一句话,输出一个脚本。当输出不正确时,完全不清楚中间发生了什么。
更好的做法是:让Skill在执行时输出一个“决策日志”,记录每一步的推理过程。例如:“识别到登录场景→加载login Skill→从上下文获取用户名密码→选择使用Playwright的fill方法→定位器策略是text=登录”。
这份日志的价值在于:当用例失败时,你能快速定位问题根源是意图理解错误,还是执行层面的故障。更重要的是,你可以将这些失败案例重新加入Skill的示例中,形成一个持续进化的闭环。
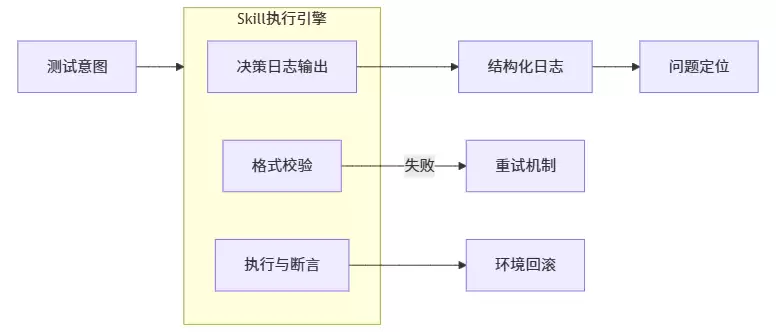
四、一个踩坑案例的重构过程
分享一个真实案例。某团队编写了一个名为“测试商品搜索”的Skill。意图描述是:输入关键词,验证搜索结果包含该关键词。
第一版直接写了200多字的自然语言指令,没有进行粒度拆分,也没有格式约束。结果如何?同一个关键词“手机”,有时大模型生成的脚本使用CSS选择器,有时使用XPath。而且搜索结果页的分页逻辑没有被处理,导致断言失败率高达30%。
重构过程如下:
- 按原则一进行拆分:拆分为三个子Skill——“输入搜索词”、“点击搜索按钮”、“验证结果列表包含关键词”。每个子Skill独立测试并通过。
- 按原则二增加约束:输出必须是Playwright Locator格式的JSON,包含selector和strategy字段。不符合Schema的自动重试。
- 按原则三增加环境预检:执行前清空搜索历史,执行后无需回滚(因为搜索是只读操作)。
- 按原则四暴露决策:每次生成时输出所选择定位器策略的原因。
重构之后,这个Skill的稳定性从70%直接跃升至95%。更关键的是,拆分出来的三个子Skill可以被其他场景复用。测试“筛选商品”时,直接复用“点击搜索按钮”和“验证结果列表”即可,完全不需要重新编写。
五、对你的实际帮助
对在校学生:从现在开始,不要只局限于学习测试理论。去了解Skills这种新范式如何重塑测试的执行方式。你不需要成为提示词专家,但需要掌握“意图拆解”和“边界定义”这两项核心能力。在未来两三年内,这两项能力将成为测试工程师的基本功。
对初级工程师:你当前的焦虑不应该是“会不会用大模型”,而是“为什么我用大模型生成的测试不稳定”。答案就在这里:因为没有为大模型提供结构化的约束。掌握这四条原则,你编写的Skill稳定性将实现质的飞跃。
对中级工程师:你面临的已不再是单个Skill的编写问题,而是如何设计一套Skills体系,让整个测试团队实现复用。这里的核心是定义好每个Skill的契约——输入输出格式、依赖的环境状态、失败时的回滚策略。将这些契约沉淀为规范,比编写十个Skill更具长远价值。
六、最后给你一个问题
当你的Skill在CI里运行失败时,你是直接去修改Skill的指令,还是先去查阅它输出的决策日志?
如果答案是前者,那么你的Skills会越改越混乱,因为你正在用打补丁的方式应对大模型的概率性行为。
更好的做法是先查看决策日志,确认大模型在哪个环节错误理解了意图。然后将这个失败案例作为“反例”补充到Skill的指令或示例中。这样,同样的错误就不会重复发生。
你现在维护的测试Skill,是否已经建立了这样一个“失败案例回灌”的机制?如果没有,你打算从何处开始着手?




