时序分析中最令人困扰的,往往不是绘制曲线本身,而是隐藏在曲线背后的诸多疑点:未来几个数据点会如何变化?异常是否刚刚开始?更换设备数据后,是否仍需重新构建模型?TimechoAI 正好瞄准了这一方向。官方产品页将其定位为“基于 Timer 系列时序大模型”,支持自然语言问答、趋势预测、异常检测,并提供 Web、REST API、Python SDK 等多种接入方式。

先造一份能跑通流程的数据
直接使用真实设备数据固然理想,但在上手阶段,可以先利用一段包含周期与噪声的样例数据,将“清洗、预测、绘图、保存结果”这一系列操作跑通。
import numpy as np
import pandas as pd
rng = np.random.default_rng(42)
time_index = pd.date_range("2026-06-01 00:00:00", periods=7 * 24 * 4, freq="15min")
base = 55 + 8 * np.sin(np.arange(len(time_index)) / 12)
noise = rng.normal(0, 1.8, len(time_index))
pressure = base + noise
# 模拟一小段异常抬升
pressure[420:445] += np.linspace(0, 14, 25)
df = pd.DataFrame({
"time": time_index,
"pressure": pressure.round(3),
"motor_current": (12 + pressure / 18 + rng.normal(0, 0.3, len(time_index))).round(3),
"valve_opening": (45 + 12 * np.sin(np.arange(len(time_index)) / 30)).round(3),
})
df.to_csv("pump_pressure.csv", index=False)
print(df.head())
这份 CSV 包含一个目标变量 pressure,以及两个可能用作协变量的字段:motor_current 和 valve_opening。后续通过 TimechoAI 上传 CSV 时,可以先从纯目标变量预测开始,再尝试加入协变量。
上传前先把 CSV 清干净
官方页面指出,TimechoAI 支持手动输入、绘制曲线、上传 CSV,并且预测范围可自定义为 1 至 720 步。上传前建议在本地进行一次检查,重点关注时间戳、缺失值以及采样间隔。
from pathlib import Path
csv_path = Path("pump_pressure.csv")
df = pd.read_csv(csv_path)
df["time"] = pd.to_datetime(df["time"])
df = df.sort_values("time").drop_duplicates("time")
series = (df.set_index("time")["pressure"].asfreq("15min"))
print("rows:", len(df))
print("missing:", int(series.isna().sum()))
print("start:", series.index.min())
print("end:", series.index.max())
series = series.interpolate(limit_direction="both")
history = series.tail(256).round(4).tolist()
若发现缺失值较多,不建议直接送入模型。缺失集中在某一段时,插值操作会掩盖真实异常,进而影响后续预测与异常检测效果。
用目标变量跑一次预测
从 TimechoAI 官方产品图可以看到预测分析界面:完成预测后会展示推理耗时、预测点数、目标变量曲线和预测曲线,并提供导出入口。
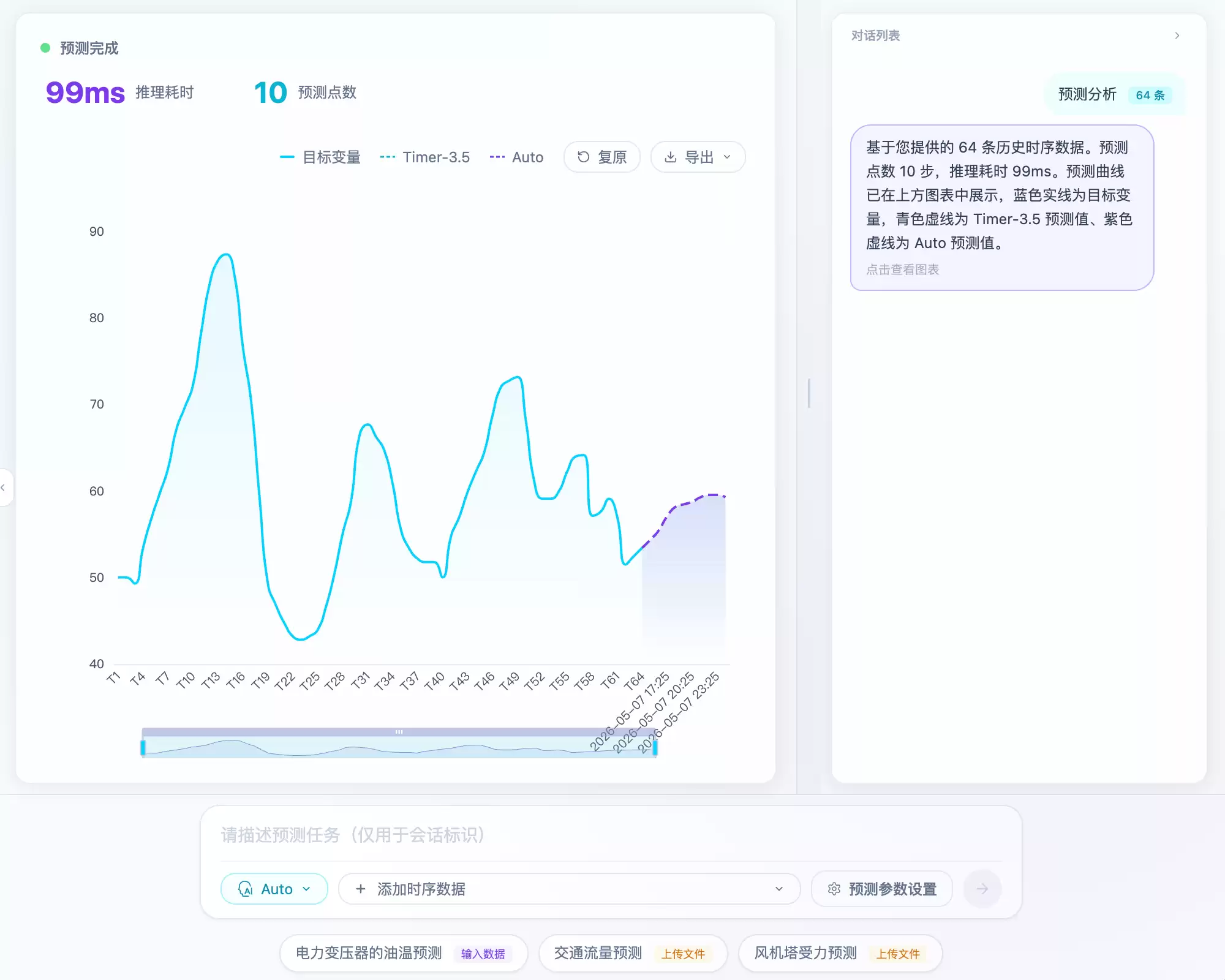
在网页端,可按照以下顺序操作:新增一段时序数据,选择目标变量,设置预测步数,然后观察曲线是否符合业务直觉。官方图中包含“预测参数设置”“添加时序数据”“上传文件”等入口,说明它不仅支持代码调用,还能先通过页面进行低成本验证。此时,让熟悉设备的人员先查看曲线更为合适,因为他们比开发人员更容易判断某段预测是否合理。
预测点数不能随意填写。15 分钟采样下,预测 32 步对应约未来 8 小时;预测 96 步对应约未来 1 天。采样粒度改变后,预测步数的业务含义也随之变化。许多时序分析出现问题的根源,并非模型接口未调通,而是“步数”这个参数在业务层面未明确。
若采用 REST API 接入,接口路径和字段名需以平台文档为准。代码中应将路径设为环境变量,避免将未确认的 endpoint 写死。
import os
import requests
BASE_URL = os.getenv("TIMECHOAI_BASE_URL", "https://ai.timecho.com")
API_KEY = os.environ["TIMECHOAI_API_KEY"]
FORECAST_PATH = os.getenv("TIMECHOAI_FORECAST_PATH", "/")
payload = {
"mode": "target_only",
"horizon": 32,
"time_unit": "15min",
"target": history,
}
resp = requests.post(
BASE_URL.rstrip("/") + FORECAST_PATH,
headers={"Authorization": f"Bearer {API_KEY}"},
json=payload,
timeout=30,
)
resp.raise_for_status()
result = resp.json()
print(result.keys())
在网页端体验时,实质上完成了三件事:准备历史数据点、设置预测步长、查看预测曲线。接口接入时,也应尽量保持这一结构,避免将数据清洗、模型调用、结果入库混在同一个函数中。
def build_target_only_payload(values, horizon=32, time_unit="15min"):
return {
"mode": "target_only",
"horizon": horizon,
"time_unit": time_unit,
"target": [float(v) for v in values],
}
payload = build_target_only_payload(history, horizon=32)
实际接入时,可以先将调用封装为一个轻量客户端。这样后续接口路径、鉴权头、超时策略发生变化时,只需修改一处。
class TimechoAIClient:
def __init__(self, base_url, api_key, timeout=30):
self.base_url = base_url.rstrip("/")
self.api_key = api_key
self.timeout = timeout
def post(self, path, payload):
resp = requests.post(
self.base_url + path,
headers={"Authorization": f"Bearer {self.api_key}"},
json=payload,
timeout=self.timeout,
)
resp.raise_for_status()
return resp.json()
client = TimechoAIClient(BASE_URL, API_KEY)
result = client.post(FORECAST_PATH, payload)
这一封装并未引入复杂设计,仅处理三件事:拼接 URL、携带 API Key、检查 HTTP 状态。预测逻辑、数据清洗、结果保存均不放入该类,否则后续排查将变得困难。
加协变量之前,先确认它真的有用
官方页面提到,TimechoAI 支持三种预测模式:纯目标变量、历史协变量、未来协变量。这一点至关重要,因为许多时序曲线并非独立变化。
例如,压力曲线可能受电机电流、阀门开度影响;能耗曲线可能受产量、班次、温度影响。协变量不能随意堆砌,而应先查看相关性及业务解释。
features = df.set_index("time")[["pressure", "motor_current", "valve_opening"]].asfreq("15min")
features = features.interpolate(limit_direction="both")
print(features.corr(numeric_only=True)["pressure"].sort_values(ascending=False))
构建带协变量的 payload 时,应将目标变量与辅助变量分开。历史协变量只存放已经发生的数据;未来协变量仅放置预测窗口内确实能提前获知的数据。
window = features.tail(256)
payload = {
"mode": "with_covariates",
"horizon": 32,
"time_unit": "15min",
"target": window["pressure"].round(4).tolist(),
"history_covariates": {
"motor_current": window["motor_current"].round(4).tolist(),
"valve_opening": window["valve_opening"].round(4).tolist(),
},
"future_covariates": {}
}
若后续获得排产计划、天气预报、节假日标记等未来已知信息,再将其放入 future_covariates。对于无法获取未来值的字段,不应强行塞入。
协变量有一个容易被忽视的限制:长度和时间轴必须对齐。目标变量采用 15 分钟一个点,协变量也需按相同粒度处理。若某个字段为小时级数据,最好先重采样至 15 分钟,再决定采用前向填充还是插值。这一步看似不起眼,却会直接影响模型看到的输入关系。
hourly_weather = pd.DataFrame({
"time": pd.date_range("2026-06-01", periods=7 * 24, freq="1h"),
"temperature": 28 + np.sin(np.arange(7 * 24) / 6),
})
weather_15min = (hourly_weather.set_index("time")
.asfreq("15min")
.ffill())
aligned = features.join(weather_15min, how="left").ffill()
print(aligned.tail())
如果协变量本身是预测值(如天气预报),也应在调用记录中标明来源。当主序列预测偏差增大时,才能判断是 TimechoAI 的预测结果不稳定,还是未来协变量本身已偏离实际。
预测结果最好画出来看
仅凭返回值很难判断模型是否跟上了趋势。将预测曲线、历史曲线、置信区间绘制在同一张图上,异常点和过度平滑都会明显呈现。
import matplotlib.pyplot as plt
def plot_forecast(series, prediction, lower=None, upper=None, freq="15min"):
history = series.tail(96)
future_index = pd.date_range(
history.index[-1] + pd.Timedelta(freq),
periods=len(prediction),
freq=freq,
)
plt.figure(figsize=(12, 5))
plt.plot(history.index, history.values, label="history", linewidth=2)
plt.plot(future_index, prediction, label="forecast", linewidth=2)
if lower is not None and upper is not None:
plt.fill_between(future_index, lower, upper, alpha=0.18, label="interval")
plt.legend()
plt.xticks(rotation=30)
plt.tight_layout()
plt.show()
# prediction 字段名以实际返回为准
prediction = result.get("prediction", [])
plot_forecast(series, prediction)
这一步不可省略。如果预测结果突然发散,或预测区间快速变宽,说明后续点只能作为趋势参考,不能直接用于触发强动作。
如需将图保存至报告或看板,可将 show() 替换为 sa vefig()。
def sa ve_forecast_png(series, prediction, output="forecast.png"):
history = series.tail(96)
future_index = pd.date_range(
history.index[-1] + pd.Timedelta("15min"),
periods=len(prediction),
freq="15min",
)
fig, ax = plt.subplots(figsize=(12, 5))
ax.plot(history.index, history.values, label="history", linewidth=2)
ax.plot(future_index, prediction, label="forecast", linewidth=2)
ax.legend()
ax.grid(alpha=0.25)
fig.autofmt_xdate()
fig.tight_layout()
fig.sa vefig(output, dpi=160)
plt.close(fig)
保存图片还有一个好处:同一曲线可以对比不同输入方式。纯目标变量、加入历史协变量、加入未来协变量分别保存一张图,哪个版本更稳定,肉眼很快就能判断。
数据集和模型管理也要一起看
TimechoAI 官方页面还提供了数据集相关能力:内置工业、能源、金融、气象、医疗等真实数据集,支持原生 TsFile,支持多设备、多测点、多粒度数据组织。这些功能虽不如预测按钮直观,但在实际项目中至关重要。
如果数据长期仅靠临时 CSV 传递,很快就变得混乱。可以在本地先约定好字段格式,再进入平台进行数据集管理。
schema = {
"time": "datetime64[ns]",
"pressure": "float64",
"motor_current": "float64",
"valve_opening": "float64",
}
for column, dtype in schema.items():
assert column in df.columns, f"missing column: {column}"
clean_df = df.astype({
"pressure": "float64",
"motor_current": "float64",
"valve_opening": "float64",
})
clean_df.to_csv("pump_pressure_clean.csv", index=False)
若数据原本存储在 IoTDB 或其他时序库中,可通过脚本拉取最近窗口,再转换为 TimechoAI 可接收的格式。下面用伪连接参数示意读取方式,真实主机、用户名、路径请根据自身环境填写。
from iotdb.Session import Session
session = Session("127.0.0.1", 6667, "root", "root")
session.open(False)
sql = """
SELECT pressure, motor_current, valve_opening
FROM root.factory.pump_01
WHERE time >= 2026-06-01T00:00:00
"""
dataset = session.execute_query_statement(sql)
rows = []
while dataset.has_next():
row = dataset.next()
rows.append({
"time": row.get_timestamp(),
"pressure": row.get_fields()[0].get_float_value(),
"motor_current": row.get_fields()[1].get_float_value(),
"valve_opening": row.get_fields()[2].get_float_value(),
})
session.close()
iotdb_df = pd.DataFrame(rows)
这一步的目的并非绑定特定数据库,而是将“数据来源”与“模型调用”分离。只要能整理成稳定的时间戳和数值列,后续便可按同一套流程进行预测。
模型管理也非装饰。官方页面提到可以管理训练任务、配置模型和训练超参数,并记录模型版本、训练参数与 Checkpoint 路径。仅做一次体验时可能感觉不到它的必要性;一旦涉及不同测点、不同数据窗口、不同参数反复尝试,就必须清楚每次结果来自哪一次配置。

本地系统也可同步保留一份调用记录,便于排查。
CREATE TABLE forecast_call_log (
id BIGINT PRIMARY KEY,
measurement VARCHAR(128) NOT NULL,
horizon INT NOT NULL,
time_unit VARCHAR(32) NOT NULL,
request_hash VARCHAR(64) NOT NULL,
model_name VARCHAR(128),
model_version VARCHAR(128),
status VARCHAR(32) NOT NULL,
created_at TIMESTAMP NOT NULL
);
调用前可计算一个请求哈希,保存至日志表。后续同一测点多次预测时,通过哈希能判断输入窗口是否完全一致。
import hashlib
import json
def request_hash(payload):
raw = json.dumps(payload, ensure_ascii=False, sort_keys=True)
return hashlib.sha256(raw.encode("utf-8")).hexdigest()
payload_hash = request_hash(payload)
print(payload_hash)
异常检测可以和预测放在一起
固定阈值只能处理“超过某个数”的情况,渐变型异常则更棘手。例如压力缓慢上升、电流长期漂移,绝对值可能尚未越线,但趋势已经发生变化。Timer 官方页面提到了异常检测能力,TimechoAI 产品页也将异常检测列为核心能力之一。
接口字段仍以官方文档为准,结构可如下拆分:
ANOMALY_PATH = os.getenv("TIMECHOAI_ANOMALY_PATH", "/")
payload = {
"series": series.tail(256).round(4).tolist(),
"window": 32,
"sensitivity": "medium",
}
resp = requests.post(
BASE_URL.rstrip("/") + ANOMALY_PATH,
headers={"Authorization": f"Bearer {API_KEY}"},
json=payload,
timeout=30,
)
resp.raise_for_status()
anomaly_result = resp.json()
异常结果建议至少保存三类信息:异常分数、异常区间、原始数据片段。仅保存一个“异常”标签,后续很难复盘。
def collect_anomaly_points(series, scores, threshold=0.8):
rows = []
tail = series.tail(len(scores))
for ts, value, score in zip(tail.index, tail.values, scores):
if score >= threshold:
rows.append({
"time": ts.isoformat(),
"value": float(value),
"score": float(score),
})
return rows
scores = anomaly_result.get("scores", [])
anomaly_points = collect_anomaly_points(series, scores)
print(anomaly_points[:5])
异常检测与预测可以结合使用。当异常分数连续升高时,再触发一次短期预测,观察未来几个点是否继续上升。这种方式比单独看阈值更精细,也不会将每次小波动都视为故障。
def should_forecast_after_anomaly(scores, threshold=0.8, min_count=3):
recent = scores[-8:]
hit_count = sum(score >= threshold for score in recent)
return hit_count >= min_count
if should_forecast_after_anomaly(scores):
payload = build_target_only_payload(series.tail(256).tolist(), horizon=32)
forecast_after_anomaly = client.post(FORECAST_PATH, payload)
这一判断十分朴素,但适合作为第一版规则。如果后续误报较多,再逐步加入阈值、连续次数、设备状态、工况标签等参数。
多条曲线不要一条条手工点
真实数据中通常不止一条曲线,而是一批设备、一批测点。网页端适合先观察效果,后续更适合使用脚本批量处理。
measurements = {
"pump_01.pressure": features["pressure"],
"pump_01.current": features["motor_current"],
"pump_01.valve": features["valve_opening"],
}
def build_batch_payload(measurements, horizon=32):
series_list = []
for name, s in measurements.items():
values = s.dropna().tail(256).round(4).tolist()
series_list.append({
"name": name,
"target": values,
})
return {
"mode": "batch_target_only",
"horizon": horizon,
"time_unit": "15min",
"series": series_list,
}
batch_payload = build_batch_payload(measurements)
批量任务最容易遗漏的是失败处理。某条曲线缺失严重、长度不够、字段格式不正确,都不应影响其他曲线的预测。
def validate_series(name, values, min_points=64):
if len(values) < min_points:
return f"{name}: points less than {min_points}"
if any(pd.isna(values)):
return f"{name}: contains NaN"
return None
errors = []
for item in batch_payload["series"]:
err = validate_series(item["name"], item["target"])
if err:
errors.append(err)
print(errors)
批量调用的结果也要分开保存。不要只保存一个 JSON 文件,否则单条曲线回溯时会非常麻烦。
def flatten_batch_result(batch_result):
rows = []
for item in batch_result.get("series", []):
name = item["name"]
for point in item.get("prediction", []):
rows.append({
"measurement": name,
"forecast_time": point["time"],
"predicted_value": point["value"],
"lower_bound": point.get("lower_bound"),
"upper_bound": point.get("upper_bound"),
})
return pd.DataFrame(rows)
把最小流程串成一个脚本
前面的代码分散在几个步骤中,实际运行时可以先整理成一个最小脚本。它只做四件事:读取 CSV,清洗时间轴,调用预测接口,保存结果。先让这个脚本稳定运行,再考虑协变量、异常检测和批量任务。
def load_series(path, column, freq="15min", tail=256):
df = pd.read_csv(path)
df["time"] = pd.to_datetime(df["time"])
df = df.sort_values("time").drop_duplicates("time")
s = df.set_index("time")[column].asfreq(freq)
s = s.interpolate(limit_direction="both")
return s.tail(tail)
def sa ve_prediction_csv(series, prediction, output="timechoai_prediction.csv"):
future_index = pd.date_range(
series.index[-1] + pd.Timedelta("15min"),
periods=len(prediction),
freq="15min",
)
out = pd.DataFrame({
"time": future_index,
"predicted_value": prediction,
})
out.to_csv(output, index=False)
return output
def main():
s = load_series("pump_pressure.csv", "pressure")
payload = build_target_only_payload(s.tolist(), horizon=32)
result = client.post(FORECAST_PATH, payload)
prediction = result.get("prediction", [])
sa ve_prediction_csv(s, prediction)
sa ve_forecast_png(s, prediction)
if __name__ == "__main__":
main()
这类脚本最适合放在验证阶段。它不追求复杂,但每一步都能单独检查:CSV 是否读对,时间轴是否补齐,接口是否返回预测数组,结果文件是否能被看板或报表读取。待这条流程跑通,再将 load_series() 替换为数据库读取,将 sa ve_prediction_csv() 替换为写入业务库,代码结构也不会混乱。
运行前可将几个变量写入环境变量,避免将密钥硬编码在脚本中。
export TIMECHOAI_BASE_URL="https://ai.timecho.com"
export TIMECHOAI_API_KEY="your_api_key"
export TIMECHOAI_FORECAST_PATH="/"
python run_timechoai_forecast.py
如果接口返回字段与示例不同,优先修改 prediction = result.get("prediction", []) 这一行。数据清洗、绘图、结果保存部分无需大规模改动。
这个最小流程运行后,可按三个标准判断是否值得继续深入。第一,预测曲线要能接上历史曲线,不能在预测起点突然跳到完全不相关的区间。第二,结果文件要能稳定生成,时间戳不能重复,也不能缺少预测步数。第三,同一份输入重复调用时,结果结构应保持一致,至少字段名、数组长度、时间顺序不能变。只要这三点没问题,再去加入协变量和异常检测就会稳定得多。
如果这三点中有一点不稳定,先不要扩展功能。将输入窗口、采样粒度、接口返回结构固定下来,再继续添加代码,排查成本会低很多。
验证阶段宁可慢一点,也不要一次性加入多个变量。
先让单变量流程稳定,再让协变量参与判断。
这样排查最省时间,也更稳妥。
收尾
TimechoAI 比较适合从小数据开始尝试:一条曲线、一份 CSV、一个预测窗口,先看预测曲线是否符合业务直觉;再加入协变量,观察结果是否变得更稳定;最后将 REST API 或 Python SDK 接入现有看板、告警或巡检流程中。
它并非替代数据清洗,也非替代现场判断。更合理的用法,是将过去只能人工盯图的时序数据,推进到“能预测、能发现偏离、能把结果沉淀在系统中”的状态。




