每次提到数据建模,不少从业者的第一反应往往是——这应该是算法工程师、数据分析师或数仓开发才需要掌握的工作。
事实上,情况并非如此。
只要你的日常工作与数据有所关联,无论是运营、产品、业务分析,还是搭建报表体系,数据建模都难以绕过。它直接决定了你手上的数据是否清晰可读、使用起来是否顺畅、运行起来是否稳定,更会进一步影响后续的分析效率与决策质量。
因此,本文不打算堆砌大量概念,而是基于实际工作场景,将数据建模从零到一的完整流程逐层拆解并讲透。阅读完这篇文章后,你不仅能够建立系统认知,还能将这些方法真正应用到自己的项目实践中。
一、明确业务目标
数据建模的第一步,并非绘制表结构,也非急于拉取数据,而是先把业务问题界定清楚。许多建模工作之所以越做越混乱,根源往往不在于技术能力不足,而是一开始就没有回答好一个问题——这次建模究竟要解决什么问题。
从根源来看,如果目标不清晰,后续大概率会遇到以下问题:
- 指标口径频繁变更
- 维度不断增加,模型越来越冗余
- 数据量看似庞大,但真正支持决策的内容却很少
- 不同团队各自为政,最终口径难以对齐
因此,在启动建模之前,建议先对齐以下几个关键点:
- 服务对象是谁:是管理层、运营团队、销售人员还是分析团队
- 要解决什么问题:是经营分析、用户增长、商品分析还是风险监控
- 核心指标有哪些:例如收入、转化率、留存率、复购率
- 分析颗粒度是什么:是按天、按人、按订单还是按门店
- 建模结果最终用在哪里:是报表、看板、标签体系还是算法输入
这一步虽然看似偏向业务,但实际上决定了后续模型的方向。目标越具体,模型越容易收敛。目标越模糊,后期返工的可能性也就越高。
二、盘点数据来源
业务目标确定后,下一步就是审视手头究竟有哪些数据。许多项目推进不下去,并非因为不会建模,而是在数据源盘点时才发现数据分散在多个系统中,结构也不一致。
常见的数据来源通常包括以下几类:
- 业务系统数据:如订单、用户、商品、库存
- 埋点行为数据:如浏览、点击、停留、转化
- 第三方数据:如广告投放、渠道回传、外部画像
- 手工台账数据:如运营登记表、活动配置表
- 历史数仓或报表数据:用于校验和补充
真正的难点不在于数据量少,而在于来源过多。用户信息在CRM中,订单在交易系统里,活动数据在Excel表格里,广告消耗在第三方平台。面对这种情况,如果仍然依赖人工导表、拼接和修改字段,不仅效率低下,还极易出现错误。
盘点数据来源时,重点并非仅仅列出一个清单,而是需要进一步追问几个问题:每张表的业务含义是什么?字段口径是否一致?数据更新时间和刷新频率如何?这一步做扎实了,后续模型才能拥有稳定的数据基础。
三、定义指标与口径
许多人将建模简单理解为设计表结构,但实际上,真正让模型具备价值的,是统一指标口径。缺乏口径的统一,再精美的模型也仅仅是一个数据堆放区。
以“新增用户”为例,这个看似简单的指标,不同团队可能就有不同的定义。有的按照注册时间计算,有的按照首次下单计算,有的剔除测试账号,有的则保留全量账号。如果这些口径未能提前统一,后续所有分析都可能出现偏差。
在定义指标时,建议至少明确以下几个层面:
- 指标名称
- 业务定义
- 计算逻辑
- 统计周期
- 适用范围
- 异常处理规则
这里需要特别注意两个问题。
第一,核心指标要少而精。不要一开始就列出几十个指标,结果每个都想分析,最终导致模型臃肿混乱。应该先抓住最核心的经营指标和分析指标,确保它们稳定且可复用。
第二,维度设计要贴近业务实际。常见的维度包括时间、地区、渠道、用户类型、商品品类、门店、活动等。维度并非越多越好,而要围绕分析场景来确定,能够支撑业务拆解就足够。
一个实用的建议是,将指标和维度整理成统一的文档,提前让业务、分析和技术三方对齐。许多后期的争议,实际上都能在这个阶段提前化解。
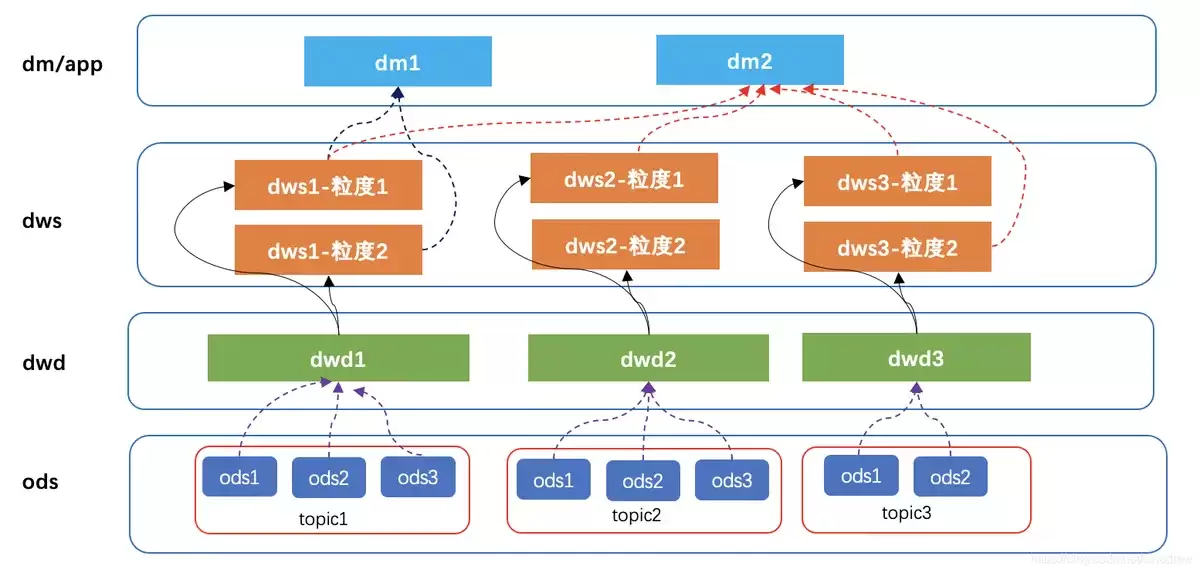
四、设计模型结构
数据来源和指标口径确认后,便进入了真正的建模设计阶段。简单来说,就是要决定数据如何分层、如何组织、表之间如何关联,才能既易于理解,又便于分析。
在实际工作中,模型设计通常会围绕几个核心问题展开:
- 事实表应存放哪些数据
- 维度表应包含哪些属性
- 主键和关联键如何设计
- 模型粒度如何控制
- 是否需要构建汇总层或宽表层
如果设计的是分析型模型,一种常见的思路是以业务过程为中心来构建事实表,例如订单事实表、支付事实表、访问行为事实表,再配合用户、商品、渠道、时间等维度表进行关联。这样做的优势在于结构清晰,扩展性也较强。
设计模型结构时,颗粒度必须特别留意。颗粒度过细,计算成本高,使用门槛也相应提高。颗粒度过粗,许多分析场景又无法满足。一个简单的原则是,以最常用、最稳定的业务行为作为事实粒度,再通过汇总层满足高频分析需求。
这里可以重点检查以下几个方面:
- 一张表是否只表达了一个清晰的主题
- 是否存在重复存储和口径冲突
- 关联关系是否稳定
- 后续新增需求时是否容易扩展
- 查询性能是否在可接受范围内
好的模型,不一定复杂,但一定要让人看得懂、用得顺、维护得住。
五、数据加工与校验
模型结构设计完成,并不代表工作就此结束。接下来,需要将原始数据真正加工到模型中,并进行系统性的校验。许多项目的隐患并非出现在模型设计环节,而是出在加工和验证阶段未能做细。
数据加工通常包括以下步骤:
- 字段清洗与标准化
- 类型转换和格式统一
- 主键去重
- 缺失值处理
- 多表关联
- 指标派生计算
- 分层落表与调度更新
这一步最容易遇到两种情况。第一是逻辑编写速度很快,但没有人复核,结果上线后发现指标计算有误。第二是只关心结果是否产出,而不关注数据是否可信,最终导致业务部门对整个模型失去信任。
因此,在校验时,建议务必进行分层检查:源表和目标表的数据量是否匹配?主键是否唯一?核心字段是否存在异常空值?如果条件允许,可以将校验规则固化为标准流程,而不是每次都依赖人工抽查。尤其是核心经营指标,一定要建立常态化的数据质量检查机制。只有数据可信,模型才能真正具备生命力。
六、落地应用与持续迭代
很多人将建模视为一次性项目,表结构建完、报表输出后,便认为工作结束了。实际上,真正有价值的数据模型,一定是能够持续服务于业务,并且随着业务变化而不断迭代的。
落地应用通常会进入以下场景:
- 经营分析看板
- 用户分层与标签体系
- 精细化运营分析
- 财务和销售对账
- 管理层周报月报
- 算法或预测模型的数据输入
到了这个阶段,问题往往不再是模型能否建出来,而是能否稳定运行、能否快速适应变化。业务突然新增一个渠道,订单系统字段发生变更,活动维度需要重构,或者多个系统之间需要实现实时同步——如果底层链路不够稳定,模型再优秀也会被拖累。
这也是为什么许多团队在模型投入使用后,会进一步将数据集成、开发调度、质量预警和任务运维串联起来。在一个典型场景中,运营人员早上需要查看前一日活动转化情况,交易系统、用户行为日志和渠道投放数据都需要按时汇总到模型层。如果此时依赖脚本东拼西凑,排查问题会非常困难。一旦某个环节出现延迟,整张看板都可能失真。
因此,第六步的重点不仅在于上线,更在于迭代。建议将以下几件事列为常规工作:
- 定期收集业务反馈
- 追踪模型的使用频率和使用效果
- 评估新增需求是否会影响原有口径
- 清理长期无人使用的字段和表
- 维护版本记录和变更说明
能够落地、能够复用、能够持续迭代的模型,才算真正建成。
总结
将数据建模从零到一拆解来看,核心无非是这六步。这套流程看似并不复杂,但每一步都至关重要,少做一步,后续都可能需要返工。
这套方法最大的价值在于,它并非只适用于大厂和专业团队——许多中小团队在做报表、做分析、做经营看板时,同样可以直接套用。
数据建模的重要性也正在于此。它并非为了让数据看起来更花哨,而是为了让数据真正服务于业务,让分析结果更加一致,让决策依据更加可靠。




