最近,Claude Code 推出了一个很值得重点关注的新能力——Dynamic Workflows(动态工作流)。有了它,Claude Code 就能根据手头任务,动态地生成一套 Ja vaScript 工作流,调度多个子 Agent、分配上下文、选择模型、运行验证流程,最后把结果汇总回来。
简而言之,它让 Agent 不再局限于一次对话,而是能为当前任务临时搭出一套完整的执行框架。理解了这套框架,也就能真正明白 Agent Harness 是什么,以及它到底在解决什么问题。
Agent Harness 是什么
先来理解一下 Harness 这个词。
在 Claude 的语境里,Harness 可以看作是一套“让 Agent 更有组织地干活”的执行框架。它负责决定任务怎么拆、Agent 怎么调用、上下文怎么隔离、结果怎么合并,以及中断后如何恢复。
Claude Code 本身就内置了一套默认 Harness,也就是这个编程 Agent 背后的执行框架。它主要面向编码任务,负责组织 Claude Code 如何读取文件、理解项目、编辑代码、运行命令,并根据执行结果持续调整。这套默认的 Harness 已经能覆盖绝大多数日常开发场景。
不过,官方也坦言,有些任务要想取得更好的效果,过去需要在 Claude Code 之上额外构建自定义 Harness,比如深度研究、安全分析、Agent 团队协作、代码审查这些场景。有了动态工作流,Claude 现在就能现场生成这类定制化的 Harness,从而更自然地处理复杂任务。
过去,开发者需要自己手写一套流程,把多个 Claude Code 实例组织起来;现在,是 Claude Code 可以根据任务,自己写一套工作流来组织自己。
这就是动态工作流的核心能力所在。
动态工作流的工作原理
Dynamic Workflows 会先执行一个 Ja vaScript 文件。这个文件中包含一些特殊函数,用于创建和协调多个 subagent。它也支持标准 Ja vaScript 能力,比如 JSON、Math、Array,来处理结构化数据。
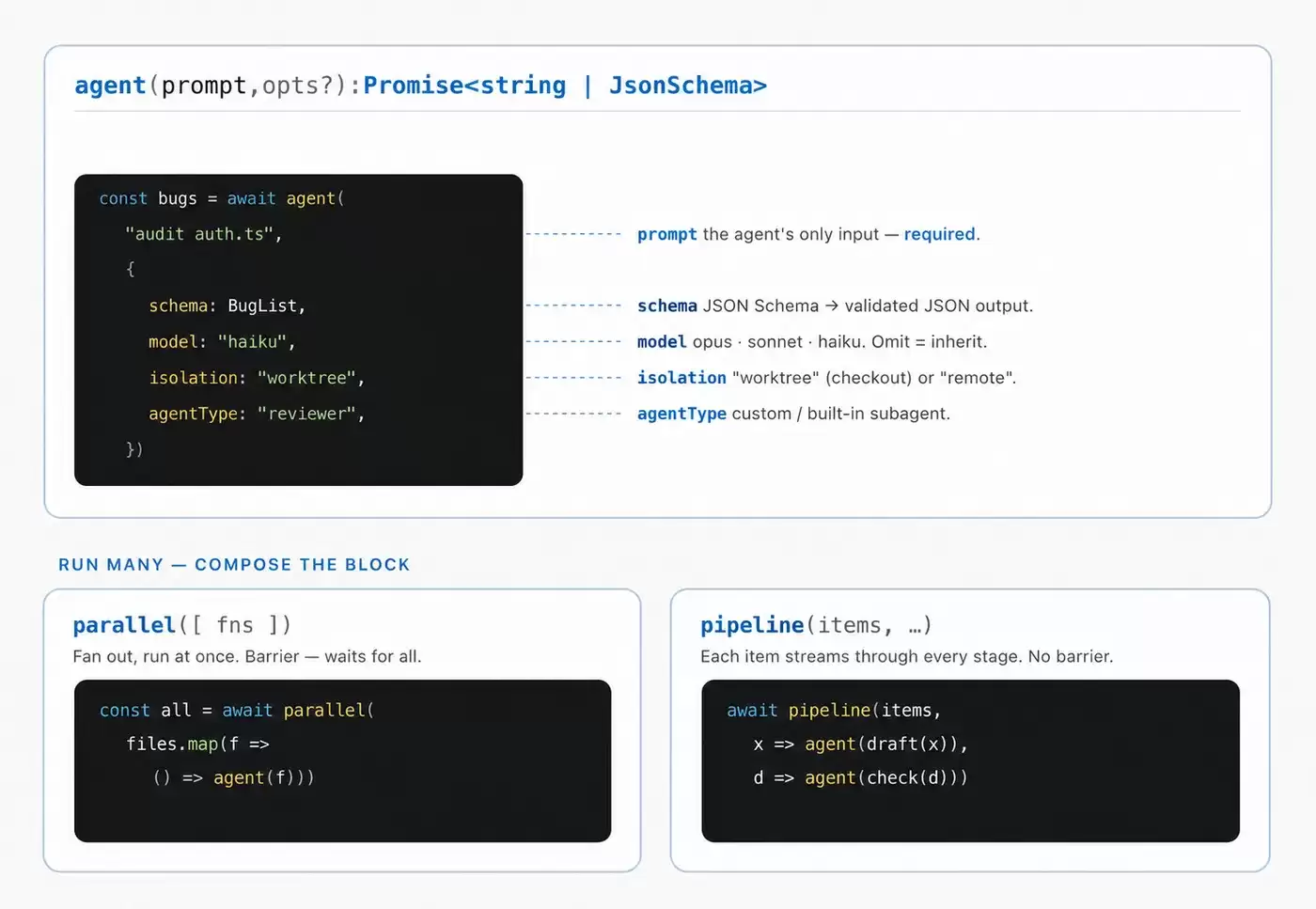
图 1:上图展示了工作流是如何通过 Ja vaScript 协调 subagent
除此之外,工作流还能决定两件事:每个子 Agent 使用哪个模型,以及是否让它在独立的 worktree 里运行。
这两个能力相当关键。模型选择直接影响任务成本和执行效果。不是每个子任务都需要动用最强模型——分类、清洗、初筛这类任务,用更轻的模型可能完全够用;但如果任务需要理解复杂代码或做深入推理,还是得把更强的模型派上场。
worktree 解决的是隔离问题。在做大规模项目重构时,不同子 Agent 可以在各自的 worktree 中进行修改,互不干扰,最后再由另一个 Agent 统一审查、合并和验证。
还有一点值得注意:如果你的工作流被意外中断,或者终端退出,等 session 恢复之后,工作流可以从中断位置继续执行,而不是一切重来。
所以,Dynamic Workflows 不只是一次性的问答式任务,它更像一个可恢复、可编排、可长期运行的执行流程。
动态工作流的重要性
前面提到,Claude Code 默认的 Harness 已经很好用,足以覆盖很多日常编码任务。但它的规划和执行主要还是发生在同一个上下文窗口里。一旦任务变长、复杂化,需要大规模并行和严格验证,这种方式就容易暴露出问题。官方总结了几个典型的失败场景:
第一个是 Agentic laziness,即 Agent 在复杂、多步骤任务中容易出现“提前收尾”的情况。任务还没完全做完,它就停止执行并声称已经完成。Claude 举过一个例子:安全审查中一共有 50 个问题,它处理了 35 个,就认为工作结束了。
第二个是 Self-preferential bias,即 Claude 会倾向于偏好自己的结果,尤其是当你让它依据某个标准来验证、评判自己输出的时候。
第三个是 Goal drift。任务执行时间越长,Claude 对原始目标的保持能力就越容易下降。特别是在上下文压缩之后,每次总结都会带来信息损失,一些边界条件、反例要求,以及“不要做什么”的限制,都可能在过程中被慢慢丢掉。
这三个问题,根源都在于“一个上下文承担了太多职责”。
如果一个 Agent 既要规划、又要执行、还要验证、还得做总结,它在长任务中很容易失真。Dynamic Workflows 的做法,是把任务拆给多个子 Agent,让它们拥有独立的上下文和更聚焦的目标。一个 Agent 负责提出方案,另一个 Agent 负责验证方案,第三个 Agent 专门反驳前两个 Agent 的结论。这样,验证过程就不再完全依赖同一个上下文里的自我判断。
这也是动态工作流对 Agent Harness 设计最有启发的地方:复杂任务的可靠性,不能只靠模型本身变强,也要靠执行结构来保证。
动态工作流 vs 静态工作流
在 Dynamic Workflows 出现之前,开发者也可以用 Claude Agent SDK,或者 claude -p 指令去协调多个 Claude Code 实例,搭建一套 Static workflow,也就是静态工作流。
静态工作流需要提前考虑各种边界情况,所以通常会写得很通用。Dynamic Workflows 的思路则灵活得多。Claude 可以根据当前任务,生成一套更贴合任务本身的 Harness。它不是提前写死一个固定流程,而是根据这次任务现场定制流程。
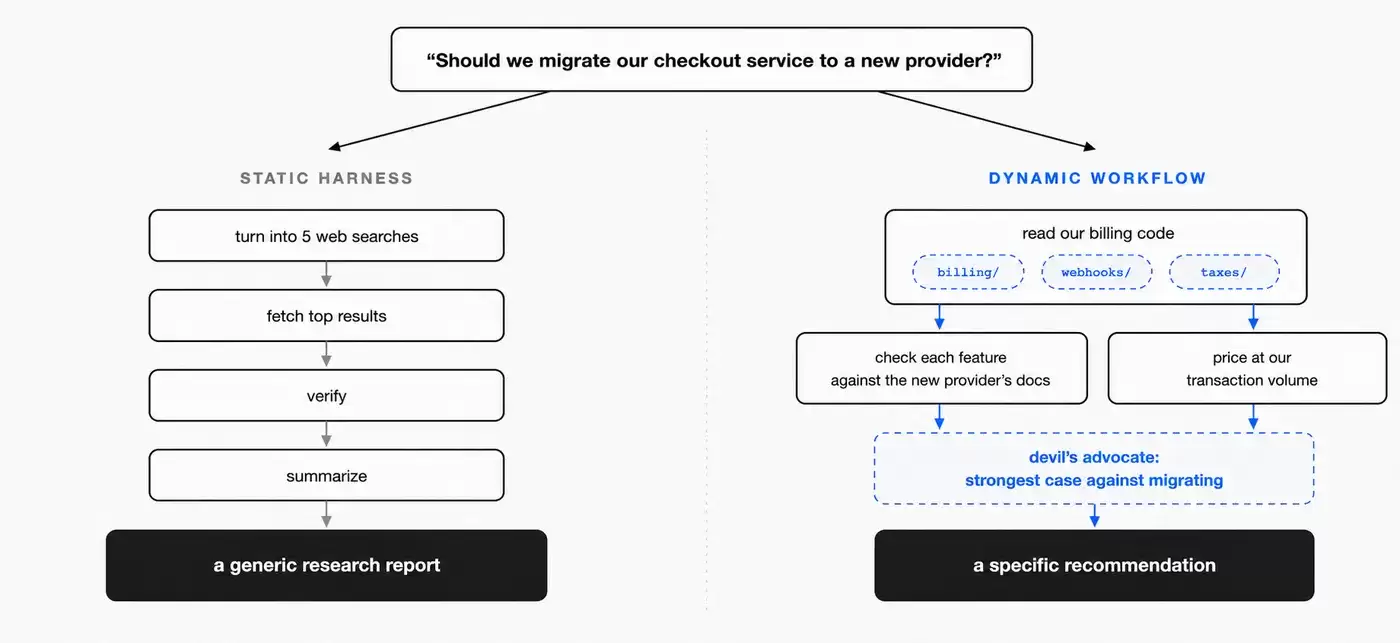
图 2:“静态工作流”和“动态工作流”的对比。
这有点像从“固定流水线”走向“任务级编排”。
不同任务需要的工作流结构并不一样。代码迁移可能会按模块、调用点、失败测试来拆分;事实核查可能会先抽取声明,再逐条查证,最后合成报告;排序任务则可能会采用两两比较、锦标赛,或者先分桶再合并。
所以,Dynamic Workflows 强调的不是某一套固定流程,而是让执行框架跟着任务变化。放到 Agent Harness 设计里,这一点很关键:复杂任务所需的 Harness,往往也应该是可调整、可定制的。
典型工作流模式
Claude 原文总结了六种常见模式,通过这些模式可以快速理解 Dynamic Workflows 到底能做什么。
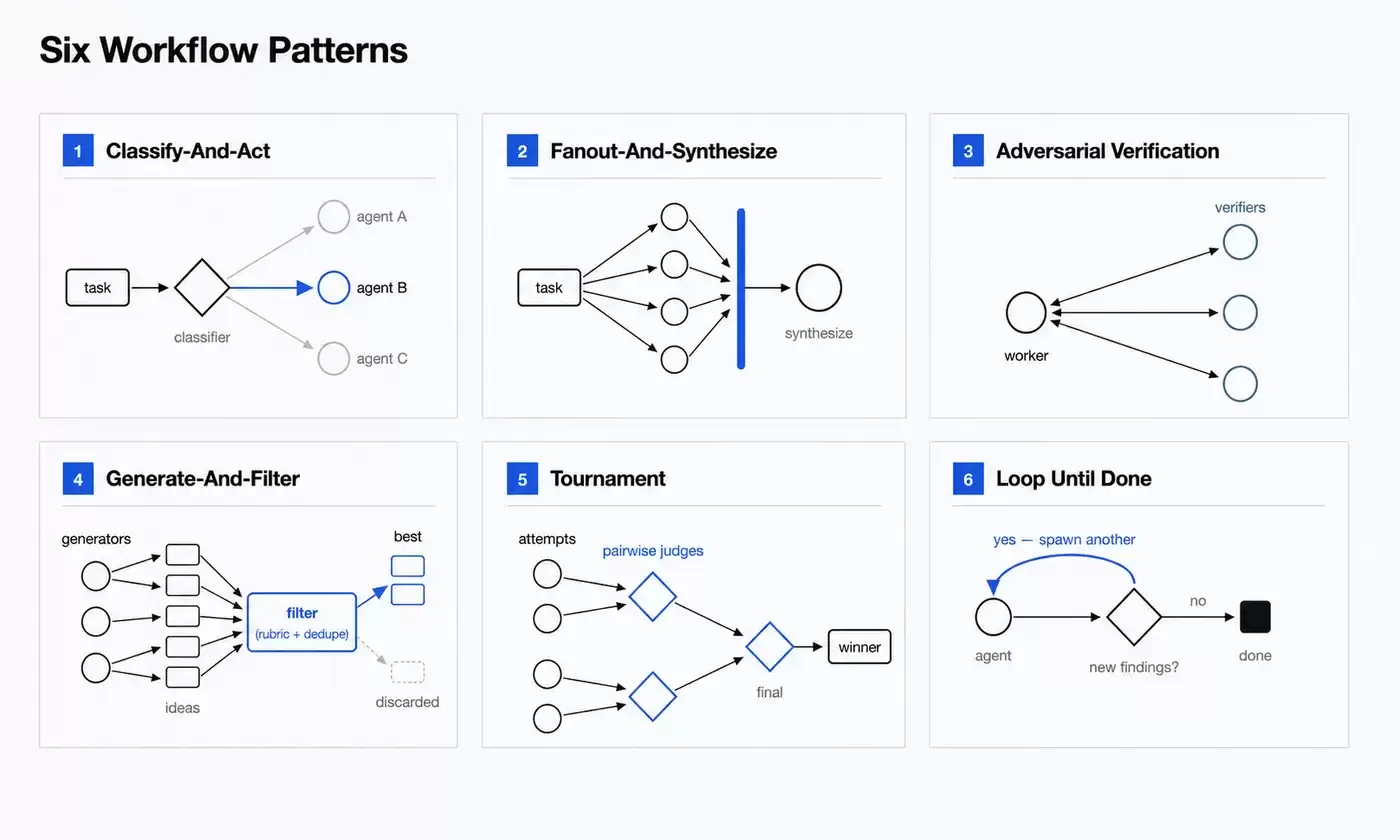
Classify-and-act:先分类,再行动
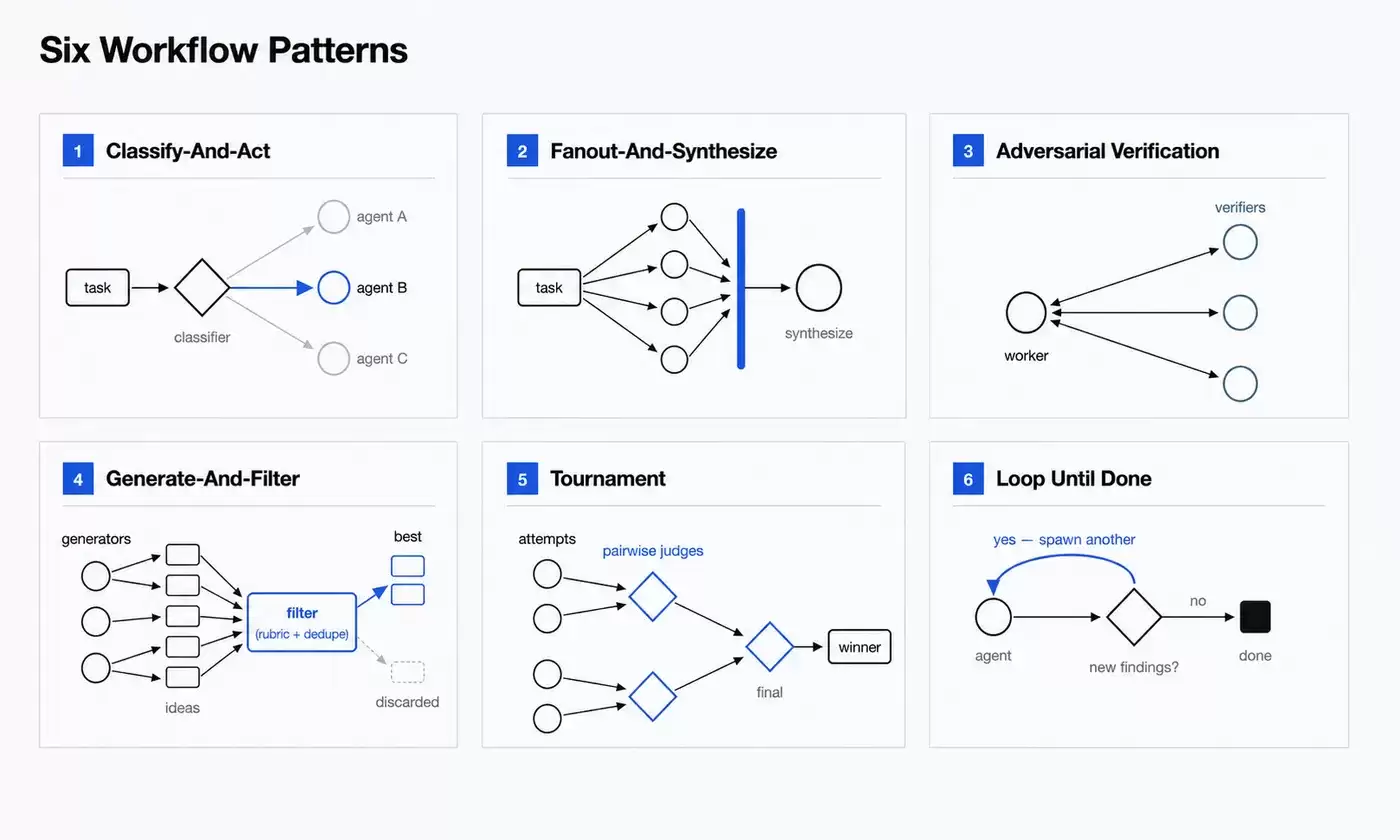
这个模式会先让一个分类 Agent 判断任务属于哪一类,再根据分类结果,把任务交给不同的 Agent,或者导入不同的处理流程。流程末尾也可以再加一个分类器,用来判断最终输出属于哪种类型。
它适合处理任务结构复杂、类型不统一的场景。比如,有一批工单,有的是 Bug,有的是产品反馈,有的是使用问题咨询,这个工作流就可以先完成分类,再把不同类型的问题交给对应的 Agent 处理。
Fanout-and-synthesize:拆开并行,最后汇总
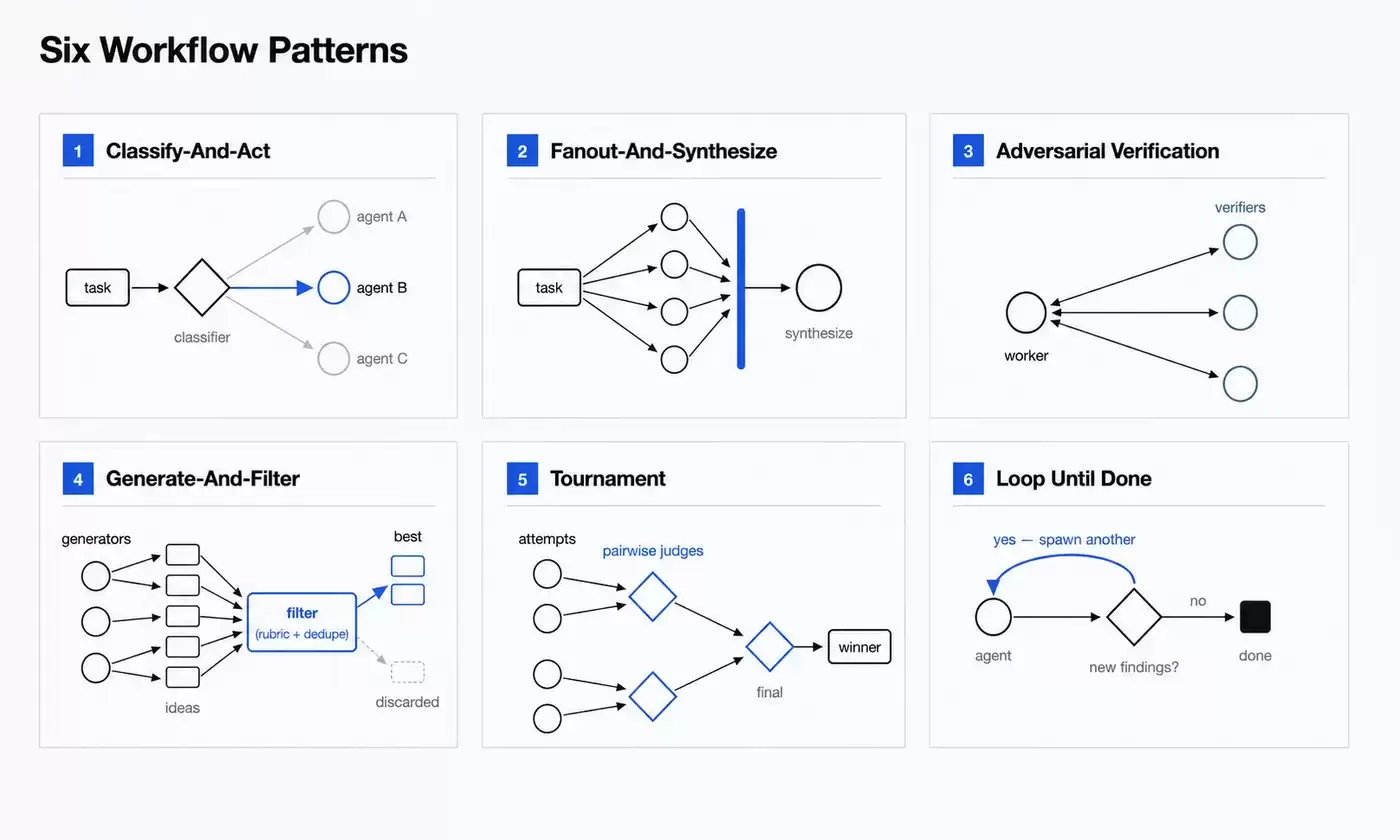
这个模式会把一个大任务拆成很多小步骤,每个小步骤交给一个 Agent 处理,最后再把所有结果合并。
官方指出,这种模式适合处理大量小步骤,或者每步都需要独立、干净上下文的任务。汇总阶段会等待所有 fan-out Agent 完成,再把结构化输出合成一个结果。
举个例子,要验证一篇文章里的 80 个技术说法,可以先把所有待核查说法抽取出来,再为每条说法启动一个子 Agent 分别查证,最后统一生成核查报告。
这里的关键不是“多开几个 Agent”,而是把大任务拆成一组可以独立处理的小任务,让每个 Agent 的上下文更干净、目标更聚焦。
Adversarial verification:对抗式验证
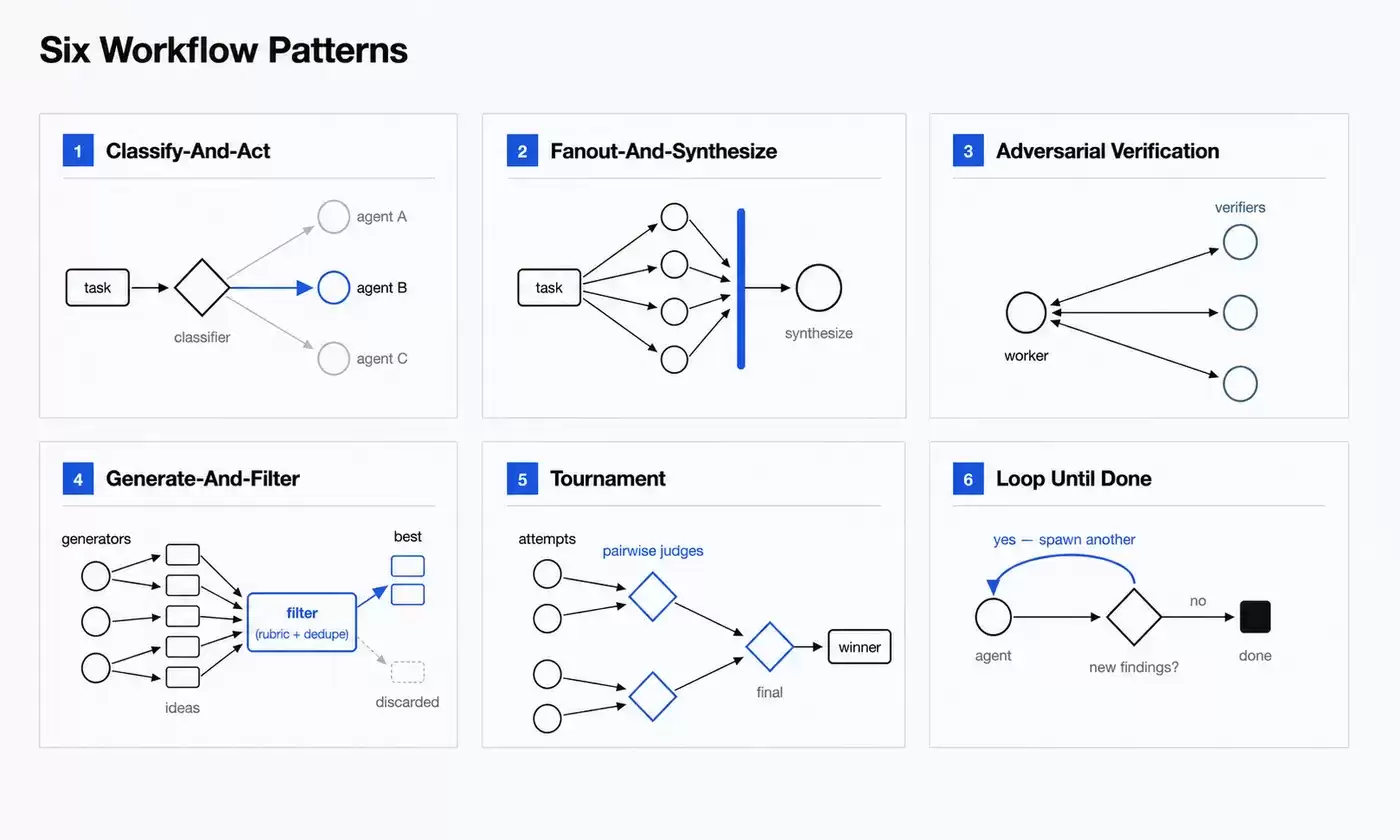
这个模式会在一个 Agent 产出结果之后,再启动另一个 Agent,按照既定标准进行验证,甚至专门从反方向去检查问题。
它非常适合代码审查、安全分析、事实核查、方案评估这类任务。比如,一个 Agent 负责修复 Bug,另一个 Agent 专门检查这次修改有没有引入新问题;一个 Agent 给出技术判断,另一个 Agent 则根据证据逐条核查、提出反驳。
看得出来,这是用对抗结构来降低自我偏见。让同一个 Agent 自我检查,容易漏掉问题;把验证者独立出来,结果通常会更稳定。
Generate-and-filter:生成,再筛选
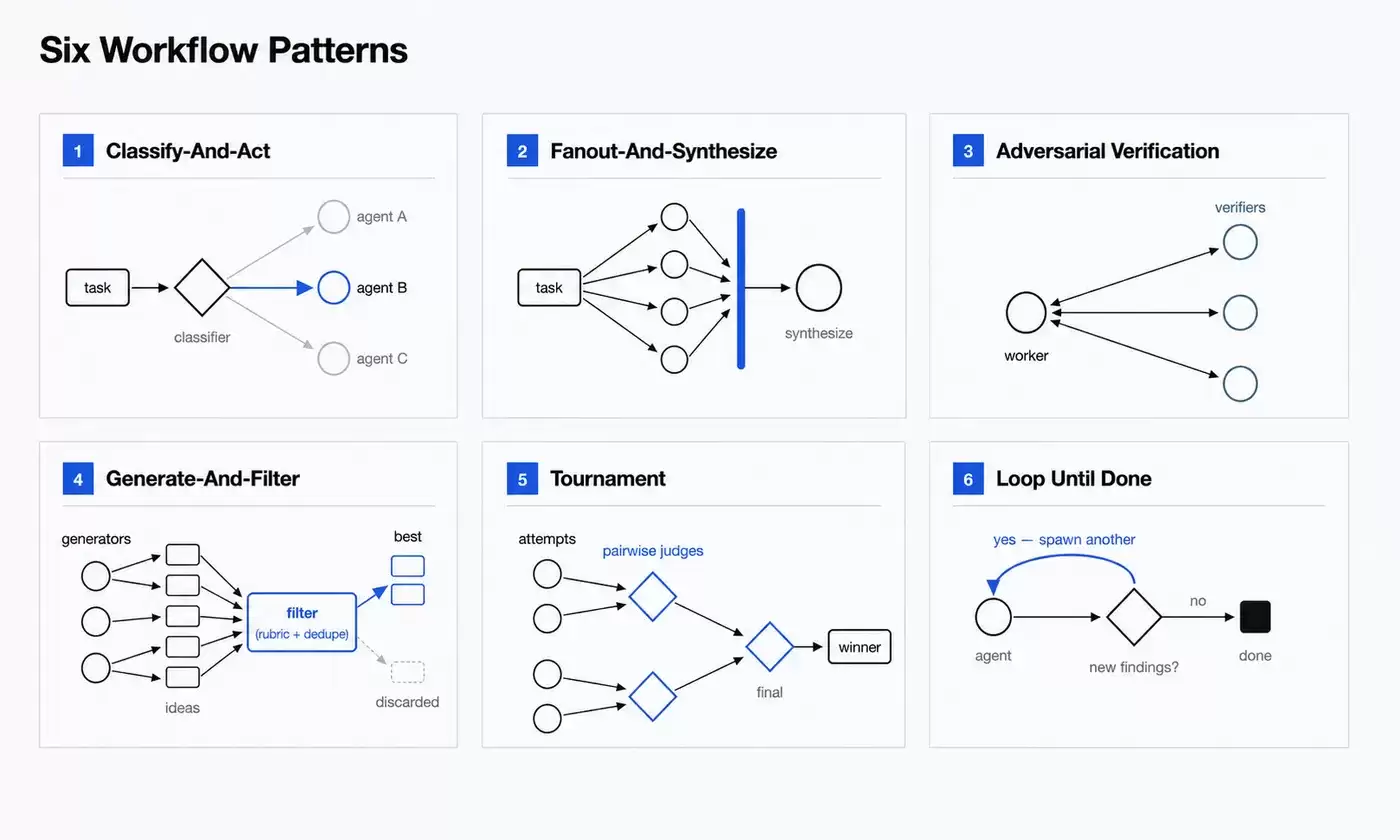
这个模式先生成一批候选结果,再根据评分标准、验证流程或去重逻辑,从中筛选出质量更高的结果。
比如起名字、写方案、列备选架构、生成测试用例,都可以先多生成一些候选项,再去掉重复、低质量或者不符合要求的结果。
Tournament:锦标赛式比较

Tournament 模式会让多个 Agent 用不同思路解决同一个任务,再通过两两比较,让评审 Agent 选出更好的结果,直到最终胜出方案出炉。
这个模式很适合主观性强、难以直接打分的问题。比如 CLI 工具命名、产品方案选择、架构路线比较。很多时候,让模型直接打分并不稳定,但让它比较 A 和 B 哪个更好,往往更容易得到可靠的判断。
Loop until done:直到完成为止
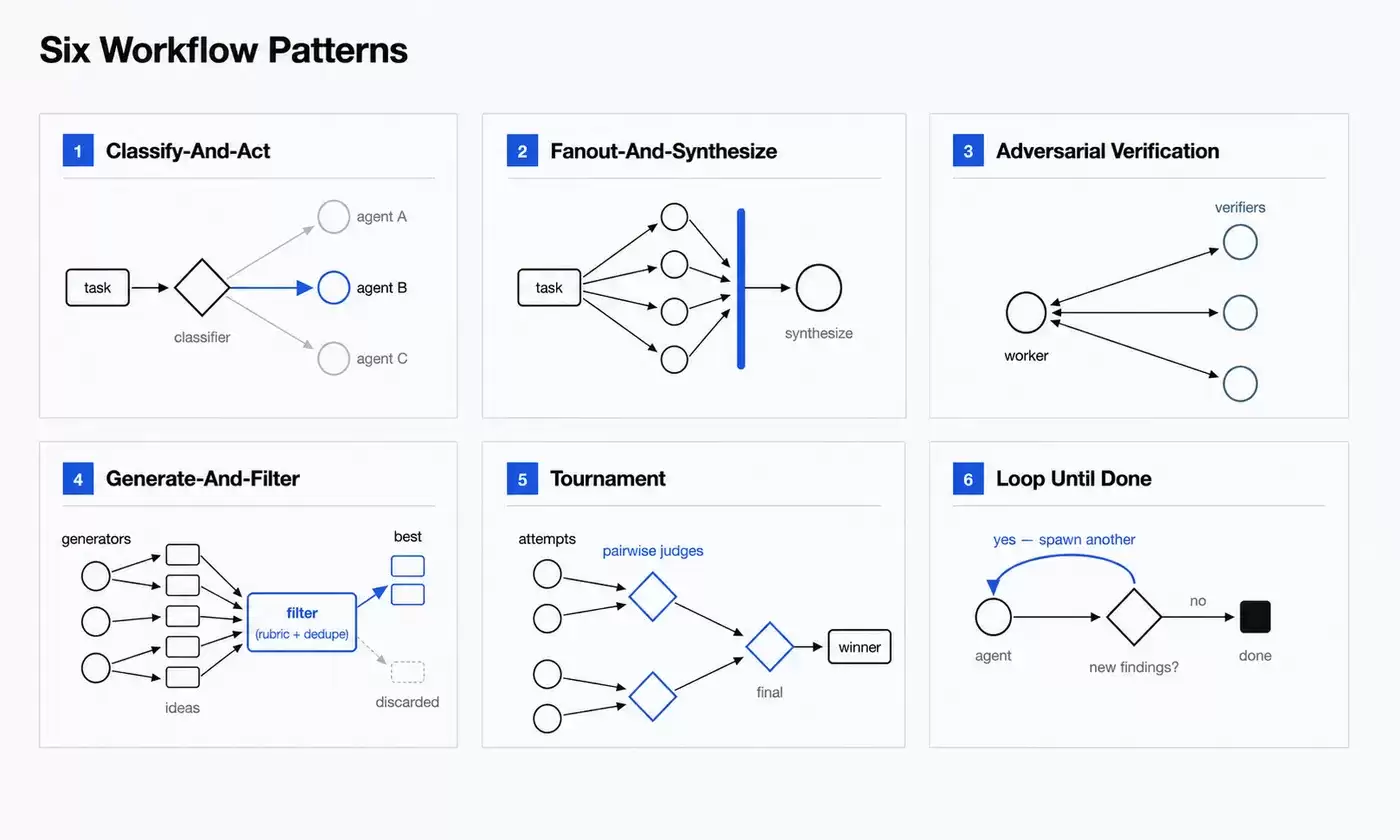
对于工作量不确定的任务,工作流可以持续启动 Agent,直到满足预设的停止条件。像是没有新的发现、日志里不再出现新的错误,或者测试已经全部通过,都可以作为停止条件。
这类模式适合调试、根因分析、持续分拣、反复验证等任务。它解决的是“提前写死执行轮次”不够可靠的问题。有些任务很难一开始就判断需要跑几轮:检查三轮可能不够,跑太多轮又会浪费资源。更合适的做法,是先把停止条件定义清楚,再让流程自己判断什么时候结束。
动态工作流的使用场景
以下是六大典型的使用场景:
迁移和重构
大规模迁移和重构,是 Dynamic Workflows 比较典型的使用场景。
举个例子,要把项目中 User 字段改名为 Account。表面上看只是改名,但在真实项目里,可能会涉及调用点、测试、模块边界、文档、类型定义、迁移脚本等很多地方。像 Bun 从 Zig 重写到 Rust 时就用了 workflows。
对于这类任务,关键在于把工作拆开:有的子任务负责处理调用点,有的负责修复失败测试,有的负责检查特定模块。每个修复任务都可以交给一个子 Agent,在独立的 worktree 里处理,最后再由另一个 Agent 做审查、合并和验证。
这也符合工程里的常识:大规模重构最怕不同修改互相干扰。worktree 隔离、并行修复、统一审查,可以让多个 Agent 更像一个临时组成的工程团队。
深度研究
Claude Code 里的 /deep-research skill 也用了 Dynamic Workflows。它会并行搜索网页、抓取来源、对说法进行对抗式验证,最后合成一份带引用的报告。
这个流程和人工研究很像:先扩大搜索范围,收集足够多的材料;再核查信息质量,排除不可靠的来源;最后把验证后的信息汇总成报告。
类似思路可以迁移到代码库研究里。比如让 Claude 研究一个项目里的鉴权模块如何工作,可以让不同 Agent 分别查看路由、中间件、数据库模型和测试文件,最后再合成一份整体说明。
深度验证
如果有一份报告,需要检查里面的事实性说法是否可靠,可以生成一个 workflow 来完成验证。
官方给出的思路是:先让一个 Agent 找出报告里的所有待核查说法,再为每条说法启动一个子 Agent 分别检查。必要时,还可以再加一个验证 Agent,专门来判断引用来源的质量是否足够高。
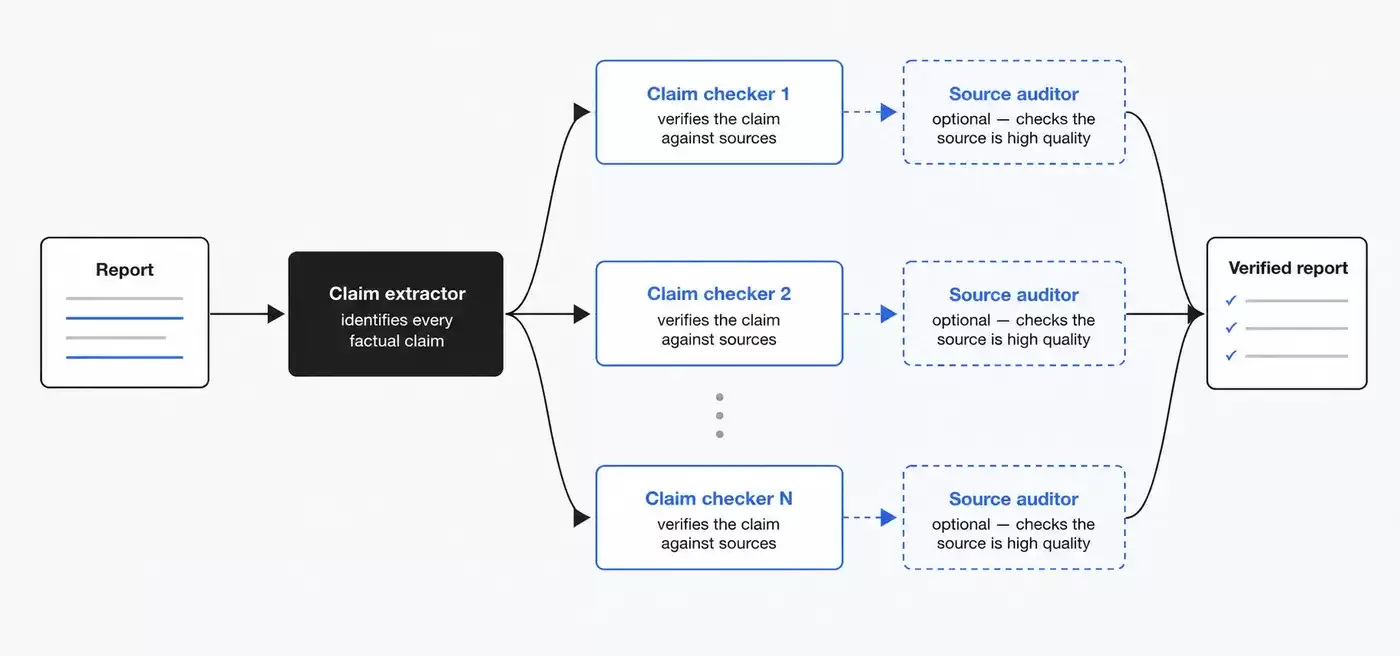
图 10:“抽取待核查说法 → 分别验证 → 再检查来源质量”的流程
这个思路对技术文章也有参考价值。如果一篇文章中有很多判断,比如某个工具支持什么能力、某个模型有什么限制、某种方案适合什么场景,单靠作者人工检查很容易漏掉细节。用 workflow 先把这些待核查说法抽出来,再逐条验证,可以有效减少文章里的事实硬伤。
大规模排序
Claude 原文还提到,很多团队都会遇到需要排序的对象,比如支持工单、Bug 列表、候选简历、需求池等。
如果把 1000 行数据直接塞进一个 prompt,让模型一次性排序,质量很容易下降,也可能超出上下文限制。更合适的做法,是把排序过程拆开:可以先让模型做两两比较,或者先按优先级分组,再分别排序和合并。
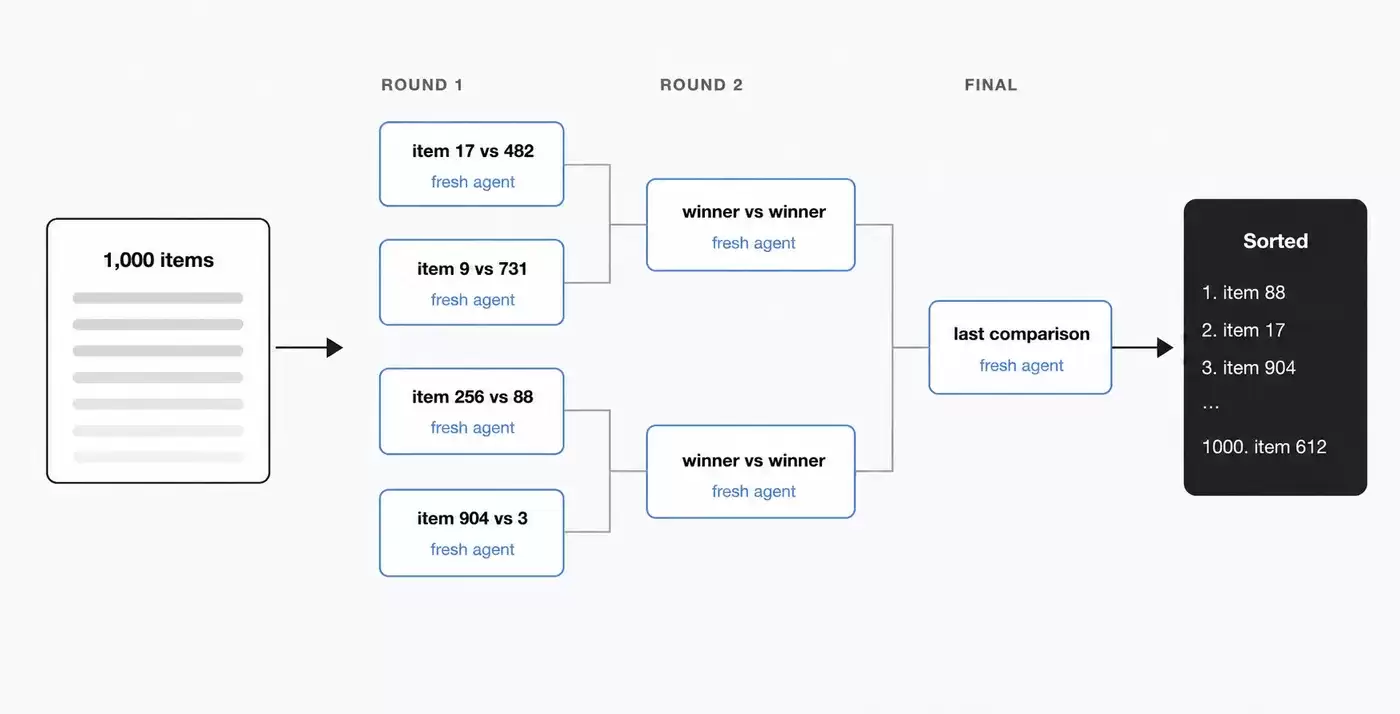
记忆和规则遵守
Claude 还提到一个很实用的做法:如果发现它总是漏掉某些规则,哪怕已经写进 CLAUDE.md 里,还是会遗忘,就可以专门创建一个 workflow,让每条规则都配一个 verifier agent 来检查。
这个流程也可以反过来用:从最近的 session 和 code review comment 里,找出反复纠正 Claude 的地方,再把这些纠正聚类、验证,最后沉淀回 CLAUDE.md。
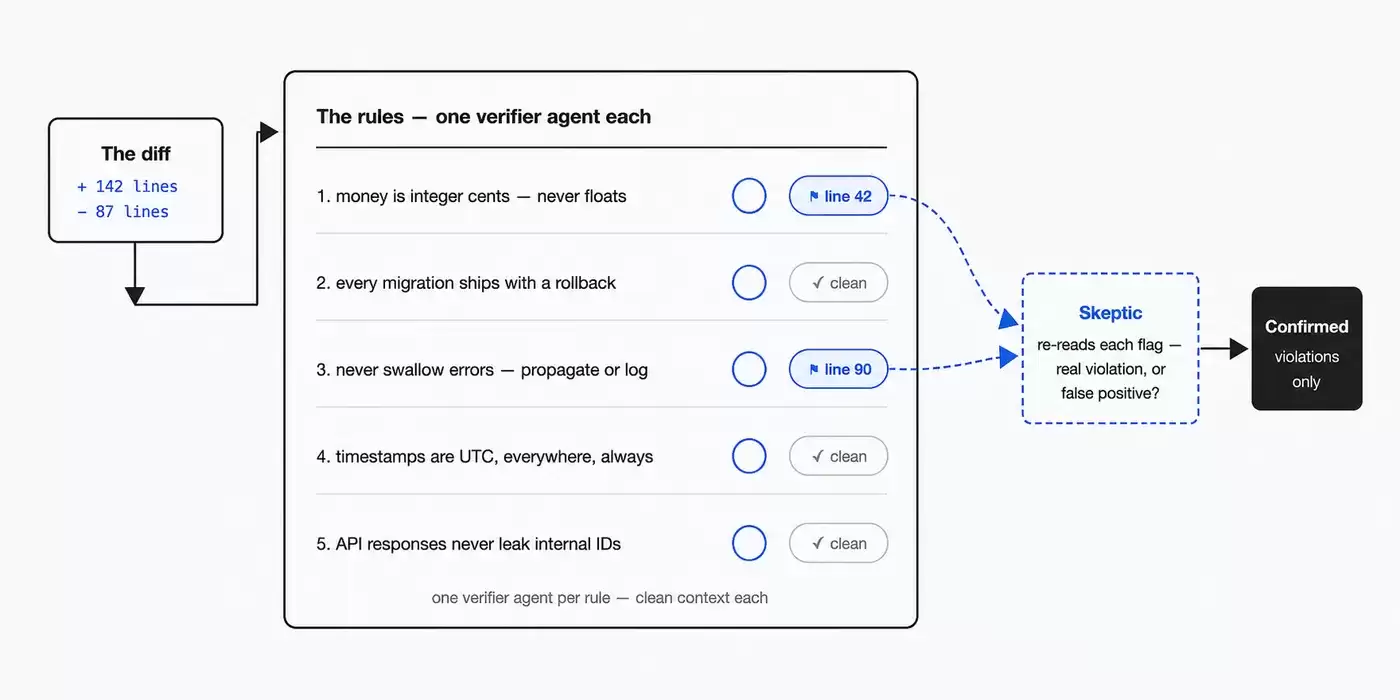
这个用法很有意思。它把“人类反复纠错”变成了一套可以沉淀的规则更新流程。Agent 完成任务之后,系统还能从人和 Agent 的互动历史中提取规则,反过来改善下一次的执行效果。
根因分析
根因分析也很适合动态工作流。
官方提到,调试时最好提出多个独立假设,再逐一验证。但如果只在一个上下文窗口里完成这件事,Claude 可能会受到自我偏见影响,过早相信某个判断。
工作流可以用更结构化的方式来降低这个问题:让不同 Agent 从不同证据出发提出假设——比如一个看日志,一个看文件,一个看数据;再让验证 Agent 和反驳 Agent 分别检查这些假设,判断哪些更站得住脚。
这不只适用于代码问题。销售额为什么下降、某条数据管道为什么失败、一次事故的真实原因是什么,都可以用类似方法拆开分析。
动态工作流的局限性
Dynamic Workflows 很强,但并不适合所有任务。
Claude 官方也提醒,这项能力还很新,而且会带来更多的 token 消耗。改一个函数、补一个测试、修一个小 Bug,普通 Claude Code 通常就够了。
更适合使用 Dynamic Workflows 的,是那些步骤多、需要并行处理、交叉验证、容易遗漏,或者单个上下文放不下的任务。
所以,工作流的价值不在于“多开几个 Agent”,而在于降低复杂任务的不确定性。
使用动态工作流的一些技巧
Claude 原文最后给出了一些使用建议。
首先,prompt 要尽量具体。可以直接让 Claude 创建 workflow,也可以使用触发词 ultracode 来确保 Claude Code 创建 workflow。但如果能提前说明任务结构、验证标准和停止条件,效果会更好。
其次,workflow 可以和 /goal、/loop 结合使用。比如分拣、研究、验证这类需要反复执行的任务,可以用 /loop 周期性运行,再用 /goal 设置明确的完成条件。
另外,也可以在 prompt 里指定 token budget,比如 “use 10k tokens”,让 workflow 在预算内执行。
最后,workflow 还可以保存和分享。官方提到,可以在 workflow 菜单里按 s 保存工作流,也可以把它们 check in 到 ~/.claude/workflows,或者通过 skill 分发。
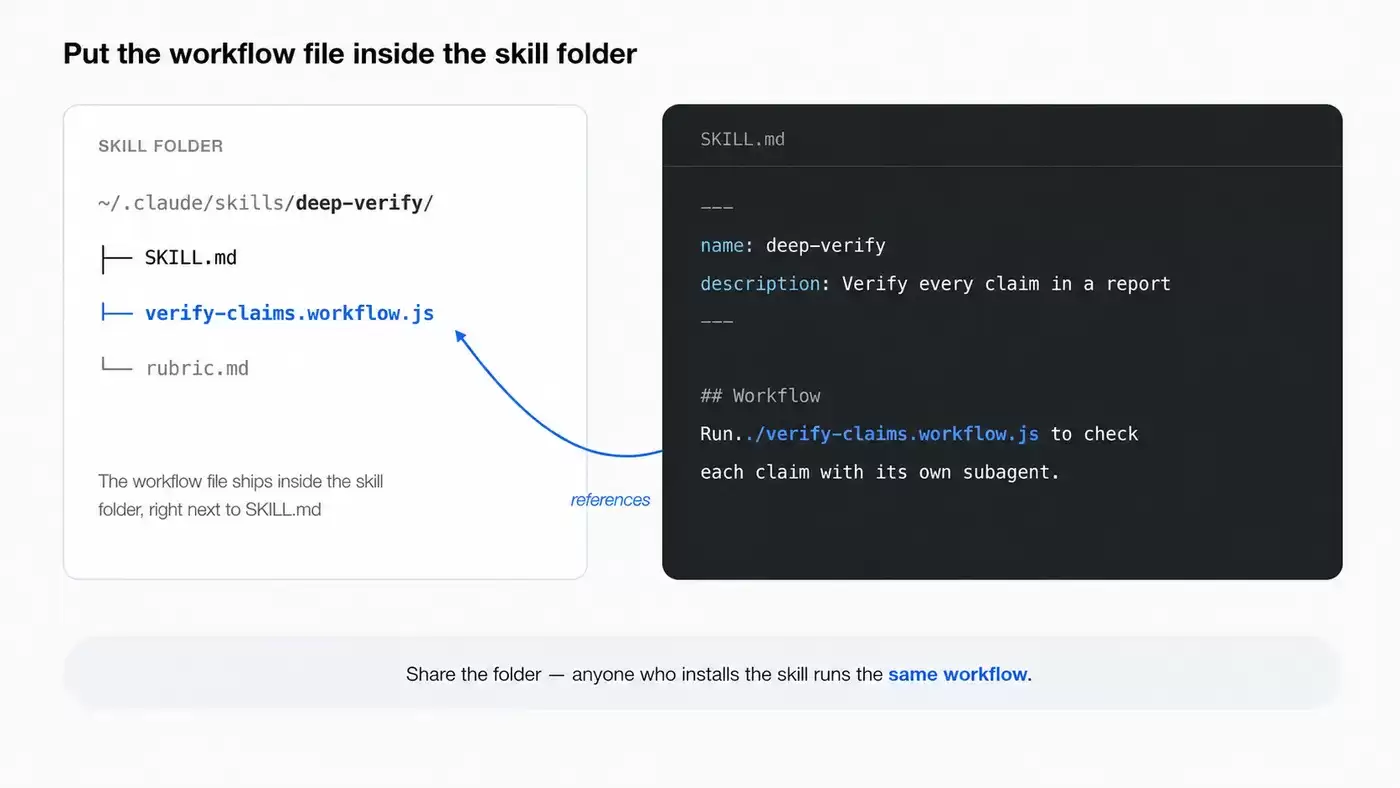
图 13:workflow 可以被保存、复用和分发
这也说明,Dynamic Workflows 不只是一次性执行脚本。如果某个流程在团队里经常使用,它可以沉淀下来,变成团队共享的 Agent 工作方式。
从动态工作流看 Agent Harness 设计
从功能层面看,Dynamic Workflows 是 Claude Code 的一个新能力:让 Claude 根据任务生成工作流,调度多个子 Agent。
但从 Agent 系统设计的角度来看,它真正强调的核心理念是:复杂任务不能只靠一个上下文一路做到底。任务需要拆分,上下文需要隔离,验证需要独立,流程也要能在中断后恢复。不同子任务还可以选择不同模型和预算,避免所有事情都挤在同一个执行路径里。
这些设计放在 Claude Code 里,就是 Dynamic Workflows;放到更大的 Agent 系统里,其实就是 Agent Harness 要解决的问题。
所以,理解 Dynamic Workflows 的价值,不只是看它能不能多开几个 Agent,而是看它如何把复杂任务组织成一套更稳定、更可靠的执行流程。这也是这篇文章里,Agent Harness 最值得被单独拿出来讨论的原因。




