在大模型开发与应用中,推理环节往往被视为“临门一脚”——模型训练得再出色,上线后能否真正发挥作用,全看推理效果。无论是智能客服解答用户提问,还是内容创作工具自动生成文案,亦或是智能助手完成各类任务,都离不开高效、精准的推理过程。ms-swift 框架作为大模型开发的重要工具,在推理方面提供了极为灵活且强大的能力。本文将深入探讨 ms-swift 框架下的大模型推理实践,从基础环境搭建,到命令行与代码层面的具体操作,逐步展示如何利用该框架实现高效推理。
2. 推理概述
推理,简单来说,就是使用训练好的模型处理新输入的数据,让模型输出预测结果或生成内容。在大模型场景下,推理可涵盖文本生成、问答、分类、情感分析等多种任务。模型的“智能”正是在推理环节转化为实际价值——它依据训练阶段习得的模式与知识,对新数据进行分析并给出合理回应。
ms-swift 框架的推理设计充分考虑了不同开发者的需求:如果你只想快速上手体验,可以使用命令行一键运行;如果你需要深度定制与精细控制,也可以通过 Python API 获得全部掌控权。无论是新手还是资深开发者,都能找到适合自己的使用方式。
3. 环境准备
在本地部署大模型之前,硬件与软件环境是必须首先跨越的门槛。如果已有合适的服务器并装好依赖,可直接跳过此部分。
3.1 服务器
硬件配置决定了模型能否运行以及运行速度。根据模型规模和计算需求选择服务器配置,例如使用 NVIDIA GeForce RTX 4090D GPU(24GB 显存)即可应对多数 7B 级别模型。软件方面,推荐 Ubuntu 22.04 系统、Python 3.10 版本,并安装 PyTorch 2.1.2 与 CUDA 11.8,这是一套成熟稳定的 AI 开发组合。
3.2 安装依赖
接下来需要安装必要的软件包。执行以下命令完成安装:
# 克隆 ms-swift 仓库
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e .
# 安装 vllm,用于模型转换和推理
pip install vllm
# 安装 modelscope,提供模型下载和管理功能
pip install modelscope3.3 模型准备
模型下载可以借助 modelscope 库的 snapshot_download 函数。在 /root/autodl-tmp 目录下创建一个 Jupyter Notebook 文件(例如 model_download.ipynb),写入以下代码:
from modelscope import snapshot_download
# 定义模型名称与下载路径
model_name = 'Qwen/Qwen2.5-7B-Instruct'
cache_dir = '/root/autodl-tmp'
# 使用 snapshot_download 下载模型
model_dir = snapshot_download(model_name, cache_dir=cache_dir, revision='master')
print(f"Model downloaded and stored in: {model_dir}")执行后,函数会自动处理下载与解压,模型将保存在指定路径下。至此,本地部署的基础工作全部完成,可以进入后续的微调与推理环节。
当然,也可以直接通过命令行下载:
# 安装 git-lfs
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
sudo apt-get install git-lfs
# 下载模型
git clone https://www.modelscope.cn/Qwen/Qwen2.5-7B-Instruct.git4. 文本模型推理
4.1 命令行推理
CUDA_VISIBLE_DEVICES=0 swift infer --model /root/autodl-tmp/Qwen/Qwen2.5-7B-Instruct --stream true --infer_backend pt --max_new_tokens 2048推理效果如下:

GPU 资源消耗(nvidia-smi 输出):
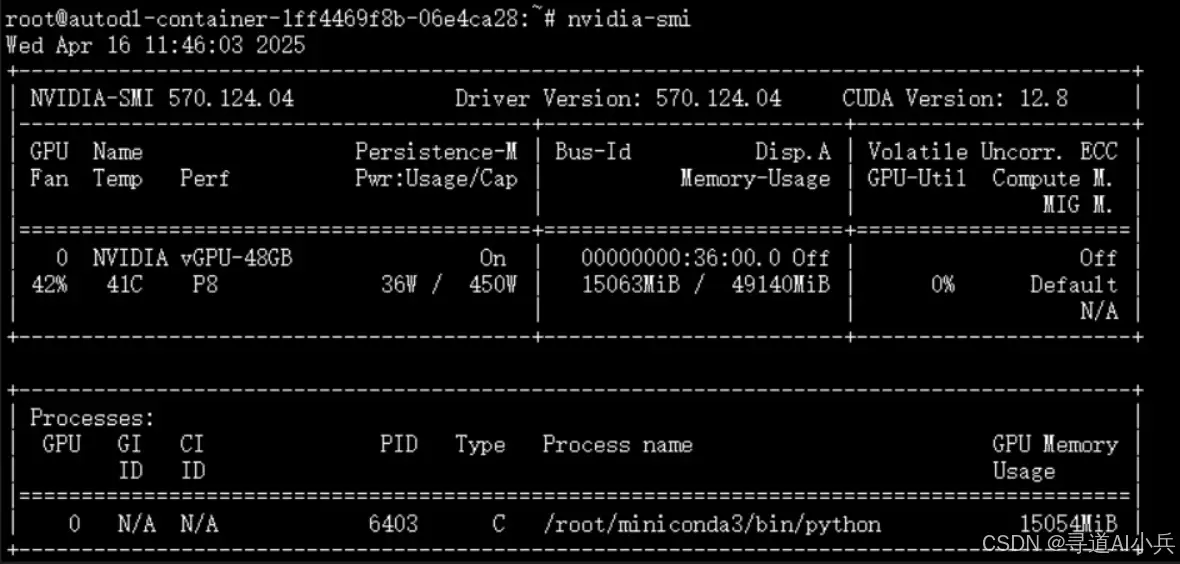
4.2 Python 推理
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
from swift.llm import PtEngine, RequestConfig, InferRequest
model = '/root/autodl-tmp/Qwen/Qwen2.5-7B-Instruct'
# 加载推理引擎
engine = PtEngine(model, max_batch_size=2)
request_config = RequestConfig(max_tokens=512, temperature=0)
# 使用 2 个 infer_request 展示 batch 推理
infer_requests = [
InferRequest(messages=[{'role': 'user', 'content': 'who are you?'}]),
InferRequest(messages=[
{'role': 'user', 'content': '浙江的省会在哪?'},
{'role': 'assistant', 'content': '浙江省的省会是杭州。'},
{'role': 'user', 'content': '这里有什么好玩的地方'},
]),
]
resp_list = engine.infer(infer_requests, request_config)
query0 = infer_requests[0].messages[0]['content']
print(f'response0: {resp_list[0].choices[0].message.content}')
print(f'response1: {resp_list[1].choices[0].message.content}')代码执行后打印输出如下:
response0: I am Qwen, a large language model created by Alibaba Cloud. I am here to assist with a wide variety of tasks and provide information on numerous topics. How can I help you today?
response1: 杭州有很多好玩的地方,以下是一些推荐:
1. **西湖**:被誉为“人间天堂”,是杭州最著名的景点之一,四季景色各异,有苏堤春晓、断桥残雪等著名景点。
2. **宋城**:以宋代文化为背景,结合现代科技手段,展现宋代风情和历史文化的主题公园。
3. **灵隐寺**:位于杭州西郊,是中国著名的佛教寺庙之一,环境幽静,适合静心游览。
4. **西溪国家湿地公园**:是中国第一个国家湿地公园,自然风光优美,可以体验到江南水乡的独特魅力。
5. **杭州乐园**:适合家庭游玩,有各种游乐设施和表演。
6. **雷峰塔**:与白娘子的故事紧密相连,不仅有美丽的传说,还有精美的建筑和周边的风景。
7. **中国茶叶博物馆**:了解中国茶文化的好地方,可以参观茶园,品尝各种名茶。
8. **杭州植物园**:拥有丰富的植物资源,是休闲散步的好去处。5. 多模态模型推理
5.1 命令行推理
CUDA_VISIBLE_DEVICES=0 MAX_PIXELS=1003520 VIDEO_MAX_PIXELS=50176 FPS_MAX_FRAMES=12 swift infer --model /root/autodl-tmp/Qwen/Qwen2.5-VL-3B-Instruct --stream true --infer_backend pt --max_new_tokens 2048推理效果如下:
<<< 这两张图有什么区别
Input an image path or URL <<< /root/autodl-tmp/images/cat.png
Input an image path or URL <<< /root/autodl-tmp/images/animal.png
这两张图片的区别在于它们的动物种类和场景。
1. **第一张图片**:
- 动物:一只小猫。
- 场景:背景是模糊的,可能是室内环境,但具体细节不清晰。
2. **第二张图片**:
- 动物:四只羊。
- 场景:背景是一个绿色的草地,有山丘和蓝天白云,显得非常自然和田园风光。
总结来说,第一张图片展示了一只小猫,而第二张图片展示了四只羊在一个自然的环境中。
-------------------------------------------------- 输入 Input an image path or URL <<< 提示输入图片地址。这里的 inputs_embeds 中,再结合文本进行推理。
模型推理消耗 GPU 资源(nvidia-smi 输出):
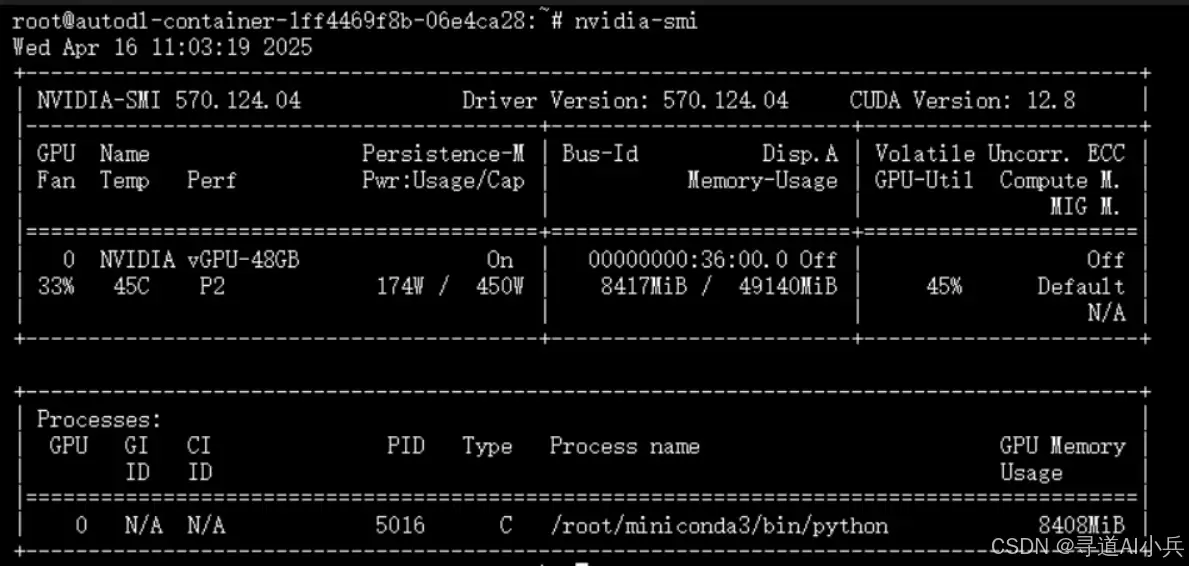
5.2 Python 推理
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
os.environ['MAX_PIXELS'] = '1003520'
os.environ['VIDEO_MAX_PIXELS'] = '50176'
os.environ['FPS_MAX_FRAMES'] = '12'
from swift.llm import PtEngine, RequestConfig, InferRequest
model = '/root/autodl-tmp/Qwen/Qwen2.5-VL-3B-Instruct'
# 加载推理引擎
engine = PtEngine(model, max_batch_size=2)
request_config = RequestConfig(max_tokens=512, temperature=0)
# 使用 3 个 infer_request 展示 batch 推理(纯文本、图像、视频)
infer_requests = [
InferRequest(messages=[{'role': 'user', 'content': 'who are you?'}]),
InferRequest(messages=[{'role': 'user', 'content': '两张图的区别是什么?'}],
images=['/root/autodl-tmp/images/cat.png', '/root/autodl-tmp/images/animal.png']),
InferRequest(messages=[{'role': 'user', 'content': ' 代码执行后打印输出如下:
response0: I am a large language model created by Alibaba Cloud. I am called Qwen.
response1: 这两张图片展示了完全不同的主题和风格。以下是它们之间的主要区别:
1. **主题**: - 第一张图片展示了一只可爱的猫咪,具有卡通风格的绘画。 - 第二张图片展示了一群卡通风格的绵羊,背景是一个绿色的草地和山丘。
2. **风格**: - 第一张图片采用了卡通风格,色彩鲜艳,细节丰富,尤其是猫咪的眼睛和表情非常生动。 - 第二张图片同样采用了卡通风格,但更偏向于简洁和可爱,颜色柔和,整体画面更加和谐。
3. **内容**: - 第一张图片中的猫咪是主角,占据了画面的主要部分,显得非常突出。 - 第二张图片中的绵羊是一组角色,每只绵羊都有独特的特征,但都保持了统一的卡通风格。
总结来说,第一张图片专注于一只可爱的猫咪,而第二张图片则是一组卡通风格的绵羊,背景和主题完全不同。
response2: A baby wearing glasses is sitting on a bed and reading a book. The baby is holding the book with both hands and is looking down at it. The baby is wearing a light blue shirt and pink pants. The baby is sitting on a white blanket. The baby is looking at the book and appears to be enjoying it. The baby is not moving much, just slightly shifting its head and body as it reads.6. 结语
通过本文的系统梳理,相信你对 ms-swift 框架的大模型推理实践已经有了较为全面的了解。从环境搭建到命令行调用,再到 Python 层次的高度灵活控制,每一步都彰显了该框架的实用性与设计巧思。无论你是刚接触大模型的初学者,还是需要深度集成的开发者,ms-swift 都提供了足够灵活且强大的工具,帮助你将大模型的智能能力快速接入实际应用。
希望本文能助你在 ms-swift 的推理之路上少走弯路。后续还可探索更多高级功能与优化技巧,进一步提升模型性能与用户体验。





