近日,摩尔线程宣布正式发布并开源了名为 MusaCoder 的代码大模型,这一动作迅速引发 GPU 底层编程领域的广泛关注。
据官方介绍,MusaCoder 是行业首个基于国产 GPU 算力底座完成全链路训练与验证的开源代码大模型。其完整的后训练流程全部在基于 MTT S5000 构建的夸娥智算集群上完成。仅凭这一亮点,就值得深入探讨。
MusaCoder 提供 9B 和 27B 两个版本,专为 GPU 底层算子生成任务而设计。它的核心能力在于:能够从 PyTorch 标准算子自动生成高性能的 CUDA 或 MUSA 原生 Kernel 代码。这意味着开发者无需再手动编写底层 GPU 算子代码——这一过程门槛高、耗时久,如今可直接交由 MusaCoder 高效完成。
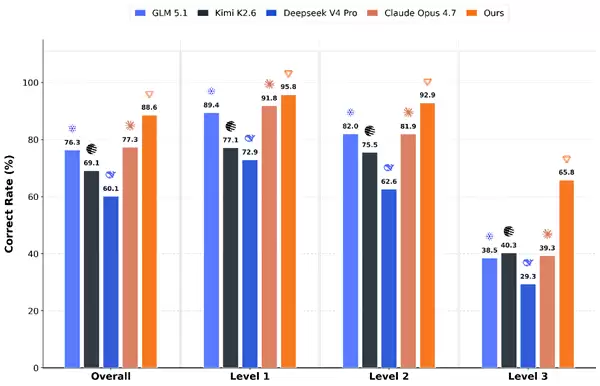
在性能表现上,MusaCoder-27B-RL 在 KernelBench 评测中取得了 Overall Pass@8 93.2%、Avg@8 88.60% 的成绩,成功超越了 Claude Opus 4.7、DeepSeek-V4 Pro、GLM-5.1、Kimi K2.6 等主流 SOTA 代码模型。在当前行业中,这一水平无疑处于领先梯队。
更值得关注的是,MusaCoder 的 SFT(监督微调)、RFT(拒绝采样微调)、RL(强化学习)、异步 rollout、在线编译执行验证以及 reward 计算等全栈训练与验证流程,均依托于 MTT S5000 构建的夸娥智算集群完成。这意味着国产 GPU 不仅能够支撑大模型推理和常规微调,还可稳定承载代码大模型全周期后训练的算力需求。
尤其在 GPU Kernel 生成这类任务中,训练系统需要频繁进行代码生成、编译、执行、验证和反馈计算,这对硬件、编译栈、运行时、调度系统以及评测基础设施都提出了极高要求。MusaCoder 能够成功跑通并开源,本身就是一次强有力的技术验证。
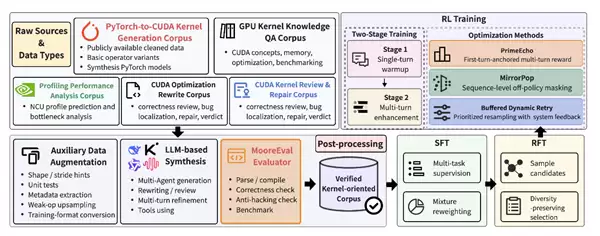 MusaCoder 训练总流程
MusaCoder 训练总流程





