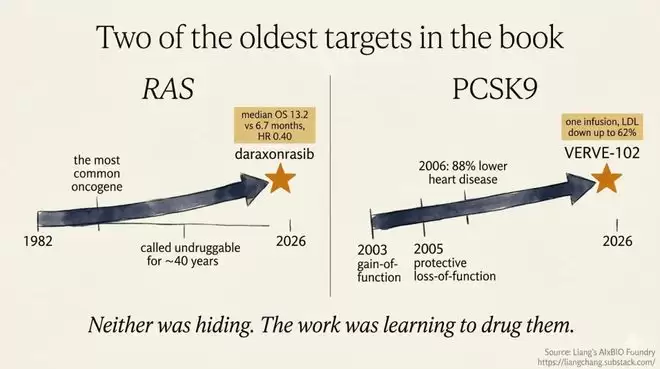
过去两周,生物制药圈最为热门的话题,莫过于2026年ASCO年会上那款胰腺癌口服新药daraxonrasib公布的临床数据:晚期患者死亡风险直降60%,中位总生存期达到13.2个月,相比以往整整翻了一倍。
与此同时,礼来的VERVE-102项目也传出重磅消息——仅需单次输注,就能在人体肝脏DNA上实施精准“编辑”,使PCSK9蛋白水平降低高达88%,LDL水平降幅达62%,且这一疗效能够持续超过一年。
作为生物技术领域的风险投资人与癌症生物学家,Liang Chang对这些突破性进展自然感到兴奋。他拥有哈佛大学癌症生物学博士学位,同时也是一位AI重度用户——在过去的两个月里,仅Token消耗就超过了1.4万美元。
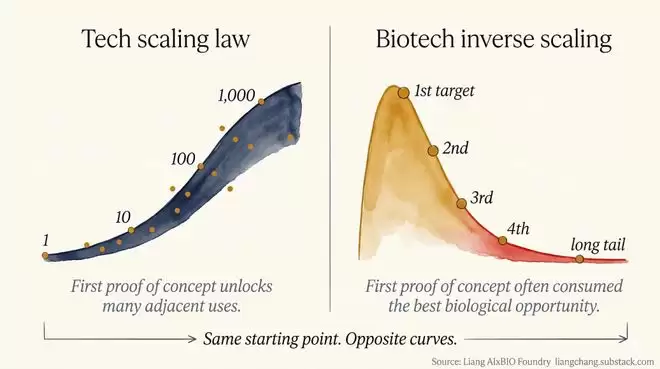
科技圈内有一个著名的“缩放定律”:随着算力和数据投入的持续增加,模型能力会呈现指数级增长,越变越强。
然而,Liang Chang在制药领域提出了一个截然相反的判断:短期内,AI可能更多是让研发管线变得异常拥挤,而非直接拉高新药获批的成功率。他称之为生物学与新药研发领域的“反缩放定律”——第一个成功往往吞噬了该领域最易得、最具价值的靶点,而后续靶点只会越来越难以攻克,不存在复利效应,只有衰减趋势。
(来源:Liang's AIxBIO foundry)
科技行业的缩放定律,为什么不能直接套用到生物学领域
如果仅从表面看,daraxonrasib和VERVE-102这两个项目的确容易让人产生乐观预期:既然RAS和PCSK9这样的重大靶点都已经取得突破,那么在AI的加持下,未来的新药研发岂不是能取得更大进展?未来5到10年内,是否会有多个类似成果不断涌现?
Liang Chang的回答相当谨慎。他认为,这两个项目的数据当然令人振奋,但不能简单推导出“AI会让新药研发像软件行业那样实现规模化”。原因非常直接:RAS和PCSK9并非AI刚刚发现的新靶点——它们恰恰是生物医药领域最古老、证据最明确、被反复研究得最为透彻的一批靶点。
(来源:Liang's AIxBIO foundry)
科技行业的增长逻辑,通常建立在可复制性的基础之上。当一个产品模型被验证后,可以迅速扩展到更多用户、覆盖更多场景、推广到更多国家。用户越多,积累的数据就越多;数据越多,模型就越聪明;模型越好,又会吸引来更多用户。这个良性循环能够实现复利式的增长。
但新药研发的逻辑完全不同。在生物学领域,第一个被成功验证的靶点,往往不是随机挑选出来的。它之所以能够最先被验证,是因为它本身就拥有最强的人类遗传学证据、最清晰的疾病关联、最明确的商业价值,以及最值得长期投入的科学理由。
这就是所谓的“反缩放定律”:在生物学领域,第一场胜利并不预示着后续也能取得胜利。相反,它可能意味着最明显、信号最强、最值得攻克的机会已经被消耗殆尽了。第二个靶点会更难,后续则越来越难。
这种规律与互联网行业的直觉完全相反。在互联网行业,一个成功的产品可以复制到相邻场景,但在新药研发领域,一个成功的靶点并不意味着邻近的靶点也同样有效。疾病的分子机制、组织环境、患者个体差异、毒性窗口、给药路径、代谢特征……每一项因素都可能让看似相近的问题,变成完全不同的难题。
因此,如果AI制药沿用科技行业的规模化想象,就很容易高估自身能力。模型可以迁移,但生物学不一定能迁移;工程经验可以复用,但人体内的因果机制却难以简单复制。
真正稀缺的不是模型,而是可靠的生物学靶点
Liang Chang在文章中提出了一个关键判断:优质靶点极其稀缺。
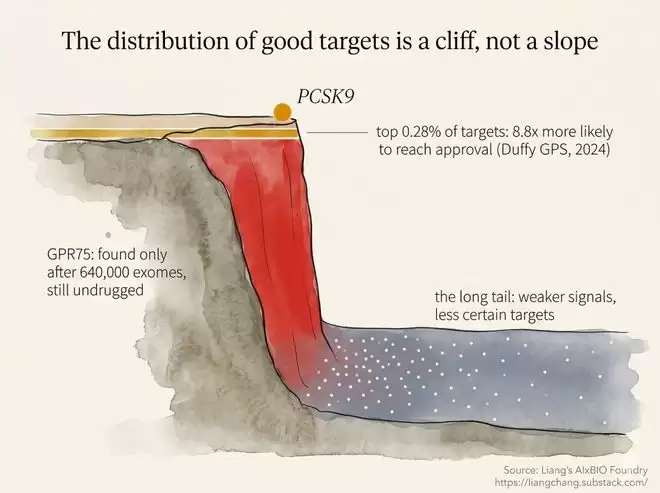
人类大约有2万个蛋白编码基因,其中或许有3000到6000个在传统意义上具备一定成药潜力,而真正拥有获批上市对应药物的靶点,仅仅只有700个左右。每一次阶段的跨越,都伴随着数量级的急剧缩减。
更为重要的是,这些留存下来的靶点并非随机样本,而是生物学证据最强、最容易被理解、最便于验证的一批。2024年,一项关于遗传优先级的实证研究发现,排名前0.28%的顶级靶点,从Ⅰ期临床试验一路闯关最终成功获批的概率,要比普通靶点高出近9倍。
(来源:Liang's AIxBIO foundry)
PCSK9就是一个典型案例。它之所以重要,并非因为AI模型从文献中推理出了它,而是人类遗传学给出了极为清晰的说明:一些人生来就携带PCSK9功能缺失变异,这类人群的LDL水平更低,冠心病风险也显著下降。
AI抬高了研发下限,却尚未突破成功率上限
实际上,Liang Chang明确承认AI在药物研发中具有巨大价值。
从一个靶点到一款药物,中间有大量工程环节需要处理:寻找苗头化合物、优化分子结构、预测蛋白结构、设计抗体或小分子、改善成药性、评估药物代谢动力学、设计实验、优化生产工艺、筛选适应症、设计临床试验、提高运营效率。在这些环节中,AI都有可能显著提升效率。
AlphaFold对蛋白结构预测的巨大推动,就是一个典型例子。如今,大量公司正尝试利用AI预测抗体结合、优化成药性特征、生成全新分子结构、提升筛选效率。
但需要警惕的是:药物研发中有一个层面绝非工程学所能解决,那就是为正确的疾病选择正确的靶点。新药研发真正的考验,往往是针对患者开展的Ⅱ期临床概念验证试验。到了这个阶段,药物必须面对真实患者、真实疾病和真实的人体复杂性。

(来源:Liang's AIxBIO foundry)
而这一阶段的数据,多年来几乎毫无起色:一款药物从步入临床试验到最终获批上市的成功率,在2014年大约是10%,而到了2020年这一数字甚至下降到了接近8%。在此期间,基因组学、CRISPR、机器学习等工具快速发展,却始终未能有效提升这一阶段的胜率。
归根结底,AI抬高了工程执行的下限,但它尚未突破生物学规律的上限。
当AI成为标配,热门靶点将变得更加拥挤
文章中最值得关注的一部分内容,是关于“拥挤”这一现象的深刻判断。
如果AI让药物研发的工程层面变得更便宜、更迅速,但并没有同步扩大经过验证的靶点池,那么资本和创业团队会往哪里去?答案很可能是:更加集中地涌向那些已验证的靶点。
原因并不复杂。AI平台本身已经带有一定的技术风险。如果一个团队同时押注一个完全未经验证的新靶点,风险就会叠加。为了让融资故事更容易被理解,让早期结果更容易被市场接受,理性的选择往往是将新技术应用在老靶点之上。靶点越成熟,投资人越容易理解;现有数据越多,AI越容易训练;临床路径越清晰,项目越容易推进。
于是,AI反而可能将整个行业推向同一个方向。就PCSK9这一个靶点而言,目前已有至少15款抗体、10款siRNA、4款ASO,以及5款口服小分子/环肽药物获得批准或已步入临床阶段;而针对CD19靶点,更是有超过300个不同的临床项目在研:包括自体CAR-T、异体CAR-T、CAR-NK、单抗、T细胞衔接器等等。

(来源:Liang's AIxBIO foundry)
当AI成为一种唾手可得的工具,而可用靶点却依然屈指可数时,短期内的必然结果,就是引发一场针对同一批已验证靶点的惨烈价格战。
如何寻找到同类首创的全新靶点?
如果AI不能凭空创造出真正的新靶点,那么first-in-class的靶点究竟从何而来?
Liang Chang的答案非常明确:最重要的来源是人类遗传学,但人类遗传学并不是坐在电脑前进行纯推理就能获得的。
你不能依靠一个最先进的AI模型,在现有知识库上更努力地推理,就找到下一个PCSK9;也不能单靠所谓的虚拟细胞扰动,在模拟环境中推导出一个足够可靠的新靶点。你必须深入真实的患者群体,进行大规模基因测序,然后开展漫长的湿实验,弄清楚这个遗传信号究竟意味着什么。
(来源:Liang's AIxBIO foundry)
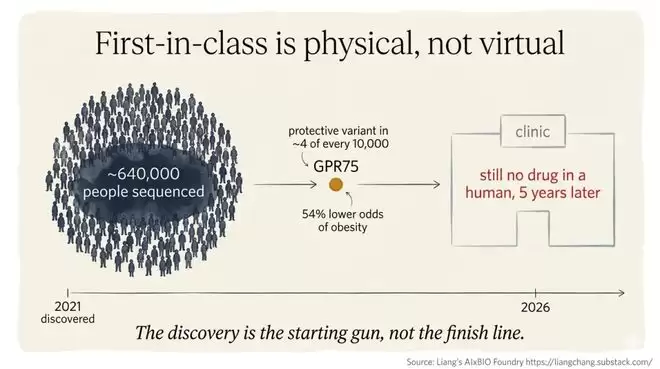
再生元制药的GPR75就是一个典型案例。为了找到GPR75这个靶点——其保护性突变与更轻的体重相关,能将肥胖概率降低54%——他们测序了大约64万个人类外显子组。结果发现,这种保护性突变在每万名受试者中仅出现约4例。如此微弱的信号,只有在如此庞大的数据规模下才有可能被捕捉到。
GPR75是2024年被提出的一个重要肥胖相关靶点。但五年后,即使已有3个平行项目在推进,仍然还没有基于GPR75的药物进入人体临床阶段。
治疗代谢相关脂肪性肝炎的靶点HSD17B13同样如此,它也来源于人类遗传学发现,目前尚无获批药物,但已经有5个临床阶段项目以及更多临床前项目在推进。
因此,发现靶点绝非终点线,它仅仅是打响了又一个长达十年的物理世界艰苦鏖战的发令枪。
这也是AI无法逾越和走捷径的鸿沟,因为绝大多数同类首创靶点,根本还未曾存在于任何AI的训练数据之中。它们依然深藏在真实的临床队列里、在实验室的试管检测中,以及无数科学家在现实物理世界里,用岁月和心血筑就的坚守之中。
归根结底,核心论点是:在科技领域,概念验证往往意味着大功告成;但在生物学领域,概念验证往往只是意味着九死一生。
我们需要保持足够的谦逊,继续扎扎实实地去测序、去寻找,并在任何人能够证明其可行性之前,依然选择去押注那些看似不露锋芒、胜算未卜的冷门尝试。
1.https://liangchang.substack.com/p/the-anti-scaling-law-in-biology-and




