Mem0 源码深度解析(一):记忆添加机制全流程拆解
在AI应用中,如何让系统长久记住用户说过的话、偏好和习惯,一直是个棘手难题。Mem0(发音为“mem-zero”)正是为解决这一痛点而生。作为一款开源项目,它为AI应用构建了专属的长期记忆层,赋能AI助手记忆用户偏好、适应个性化需求,并实现持续学习。无论是客户支持机器人、智能助手还是自主系统,Mem0都能有效发挥作用。
在深入源码之前,有几个核心疑问值得思考:
- Mem0 如何从对话中精准抽取有价值的信息?
- 它依据什么来判断:何时添加新记忆、更新旧记忆,或删除已过时的内容?
- 向量存储与图存储各自扮演什么角色,它们又是如何协同工作的?
让我们带着这些问题,一步步拆解其实现原理。
一、整体架构概览
从抽象层面看,Mem0 添加记忆的完整流程大致如下:
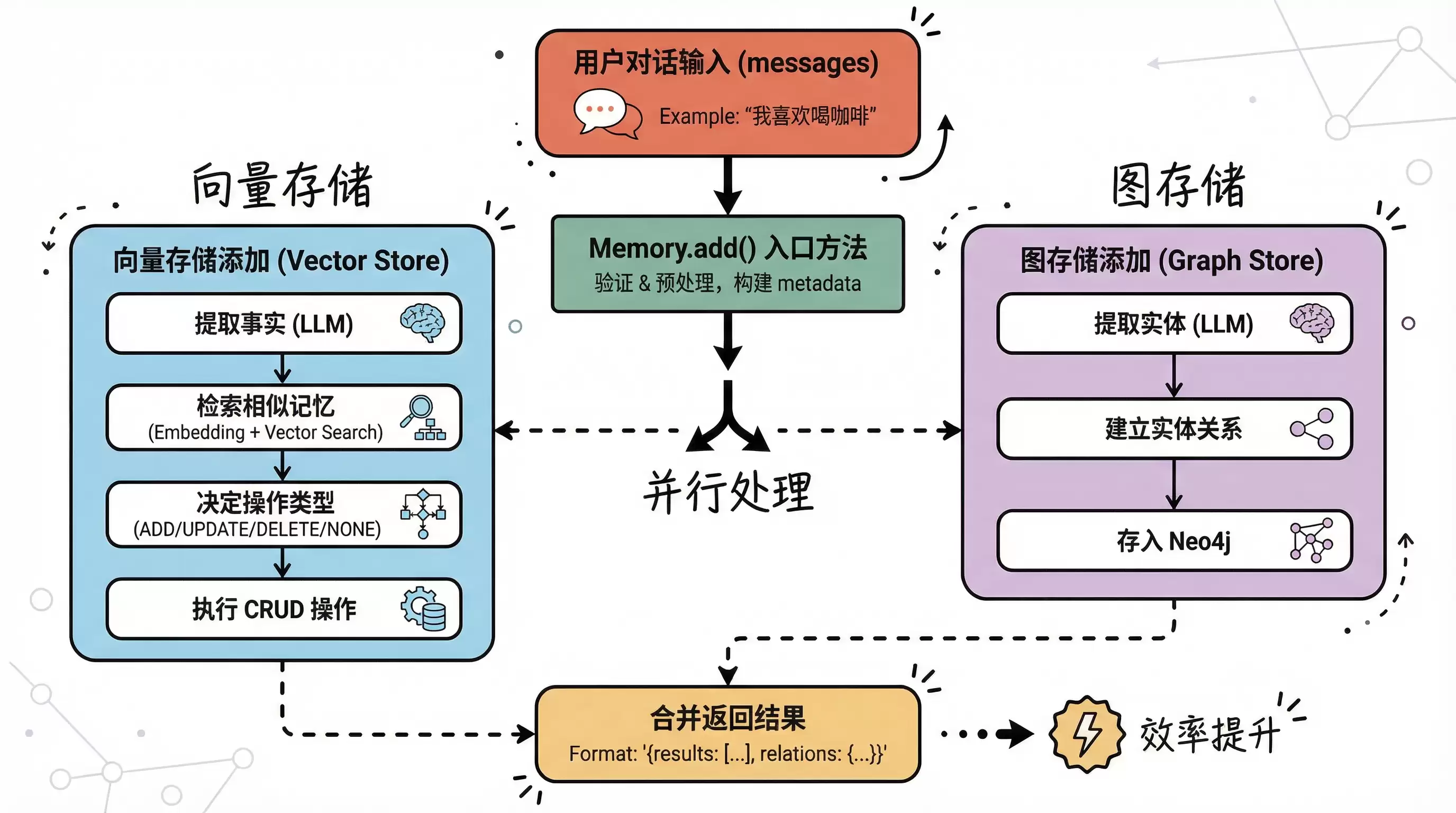
其核心逻辑集中在 mem0/memory/main.py 文件中,主要涉及三个关键方法:
Memory.add():作为入口方法,负责接收外部输入并调度后续任务_add_to_vector_store():负责向量存储的写入操作_add_to_graph():负责图存储的写入操作
可以说,理解了这三个方法的设计思路,就掌握了记忆添加的大部分秘密。
二、入口方法:Memory.add()
我们从入口方法开始分析(位于 mem0/memory/main.py:281):
def add(self,messages,*,user_id: Optional[str] = None,agent_id: Optional[str] = None,run_id: Optional[str] = None,metadata: Optional[Dict[str, Any]] = None,infer: bool = True,memory_type: Optional[str] = None,prompt: Optional[str] = None,):参数详细说明
messages:输入的对话内容,格式灵活多样。可以是纯字符串(例如
"我喜欢喝咖啡"),也可以是单条消息字典(如{"role": "user", "content": "我喜欢喝咖啡"}),或是包含多轮对话的消息列表。user_id/agent_id/run_id:作为会话标识符,用于隔离不同用户或不同会话的记忆数据,防止信息交叉污染。
infer:是否开启大模型(LLM)推理功能,默认
True。开启后,系统会借助大模型提取关键事实、智能管理记忆;若设为False,则仅将原始消息原封不动存入,不做额外处理。memory_type:记忆类型标签,例如
"procedural_memory"用于专门存储程序性记忆。
核心执行流程
add() 方法的执行逻辑可以简化为以下步骤:
# 1. 构建元数据和过滤条件processed_metadata, effective_filters = _build_filters_and_metadata(user_id=user_id, agent_id=agent_id, run_id=run_id, input_metadata=metadata)
# 2. 处理特殊记忆类型(如程序性记忆)
if agent_id is not None and memory_type == MemoryType.PROCEDURAL.value:
return self._create_procedural_memory(messages, metadata=processed_metadata)
# 3. 并行执行向量存储与图存储的添加操作
with concurrent.futures.ThreadPoolExecutor() as executor:
future1 = executor.submit(self._add_to_vector_store, messages, processed_metadata, effective_filters, infer)
future2 = executor.submit(self._add_to_graph, messages, effective_filters)
concurrent.futures.wait([future1, future2])
vector_store_result = future1.result()
graph_result = future2.result()
# 4. 返回最终结果
return {"results": vector_store_result, "relations": graph_result}这里有一个关键设计:向量存储与图存储的添加操作是并行执行的。两者相互独立、互不干扰,通过 ThreadPoolExecutor 同步提交,显著提升了系统效率。
三、向量存储添加:_add_to_vector_store()
此环节是整套流程中最核心的部分,代码位于 mem0/memory/main.py:386。
两种工作模式
模式一:infer=False(直接存储模式)
此模式不经过大模型处理,直接将原始消息存入向量数据库:
if not infer:
for message_dict in messages:
# 跳过系统消息
if message_dict["role"] == "system":
continue
# 生成向量嵌入
msg_embeddings = self.embedding_model.embed(msg_content, "add")
# 直接创建记忆条目
mem_id = self._create_memory(msg_content, msg_embeddings, per_msg_meta)
returned_memories.append({"id": mem_id, "memory": msg_content, "event": "ADD"})
return returned_memories这种方式简单直接,适合需要保留对话原始完整性的应用场景。
模式二:infer=True(智能推理模式)
这是系统的默认模式,处理流程更为复杂:
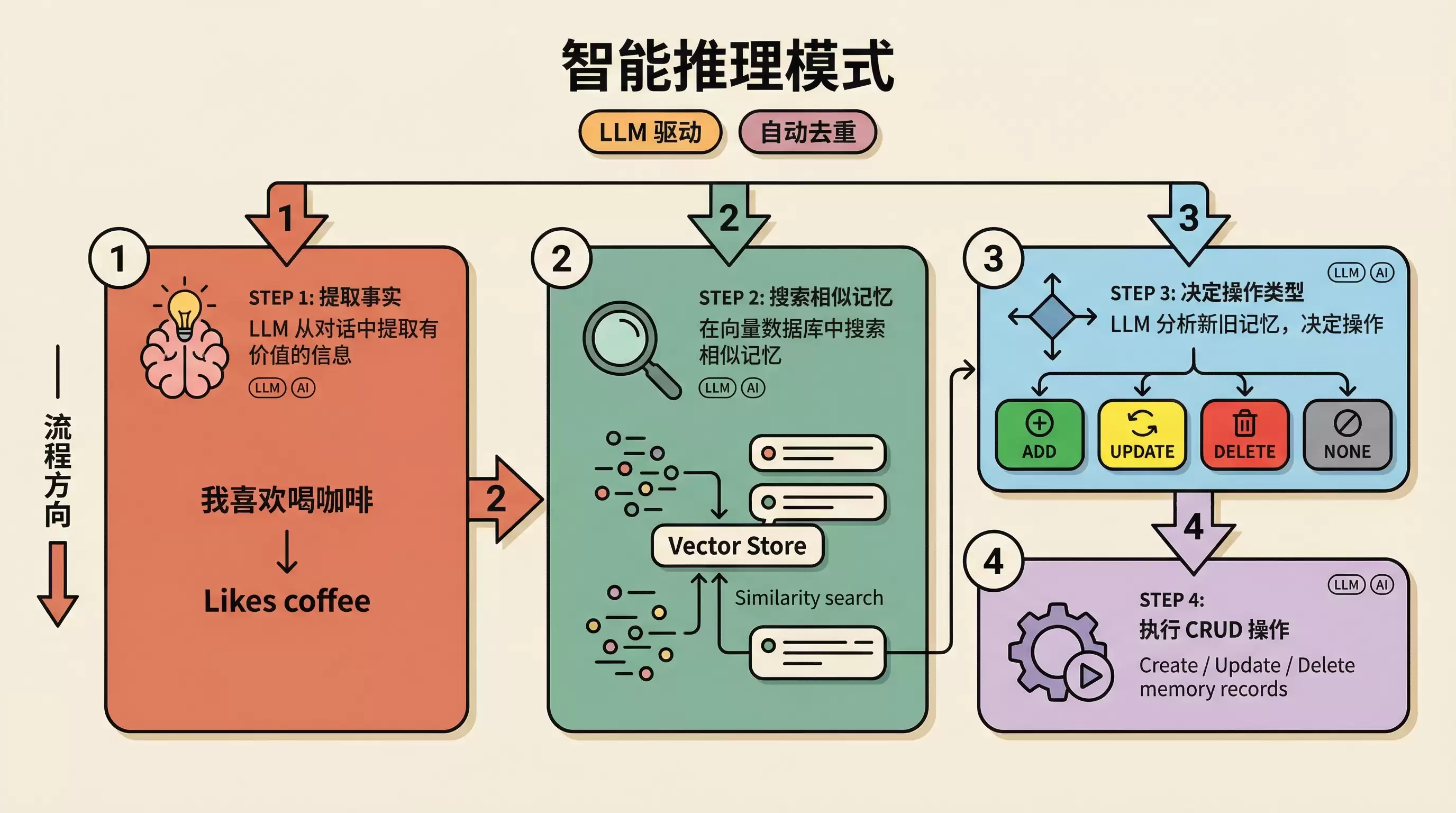
下面我们来逐步拆解其中的每个步骤。
步骤1:事实抽取
首先,系统让大模型从对话中提取出值得保留的关键事实。它会根据消息角色是用户还是助手,选择不同的提取提示词:
# 选择适用的提示词(用户记忆 vs 助手记忆)
is_agent_memory = self._should_use_agent_memory_extraction(messages, metadata)
system_prompt, user_prompt = get_fact_retrieval_messages(parsed_messages, is_agent_memory)
# 调用大模型
response = self.llm.generate_response(messages=[{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}],
response_format={"type": "json_object"})
# 解析 JSON 格式的结果
new_retrieved_facts = json.loads(response)["facts"]以下是提示词的一个示例(摘自 mem0/configs/prompts.py:14):
FACT_RETRIEVAL_PROMPT = """You are a Personal Information Organizer...
Types of Information to Remember:
1. Store Personal Preferences
2. Maintain Important Personal Details
3. Track Plans and Intentions
...
Input: Hi, my name is John. I am a software engineer.
Output: {"facts": ["Name is John", "Is a Software engineer"]}
"""可见,提示词定义了一套详细的分类指南,大模型据此提取出结构化、条理清晰的“事实”。
步骤2:相似记忆检索
对于每一条新提取的事实,系统会在向量数据库中搜索可能存在的相关记忆:
for new_mem in new_retrieved_facts:
# 生成向量嵌入
messages_embeddings = self.embedding_model.embed(new_mem, "add")
# 在向量库中检索相似记忆(基于向量相似度)
existing_memories = self.vector_store.search(query=new_mem, vectors=messages_embeddings, limit=5, filters=search_filters)
for mem in existing_memories:
retrieved_old_memory.append({"id": mem.id, "text": mem.payload.get("data", "")})系统默认取前5条最相似的记忆,作为后续操作决策的参考依据。
步骤3:操作类型决策
在同时获得新旧记忆后,系统会再次调用大模型来做出决策——针对每条新事实,应该执行什么操作?

# 构建操作决策提示词
function_calling_prompt = get_update_memory_messages(retrieved_old_memory, new_retrieved_facts)
# 大模型返回操作指令
response = self.llm.generate_response(messages=[{"role": "user", "content": function_calling_prompt}],
response_format={"type": "json_object"})
new_memories_with_actions = json.loads(response)决策提示词(摘自 mem0/configs/prompts.py:175)定义了四种操作类型:
DEFAULT_UPDATE_MEMORY_PROMPT = """You are a smart memory manager...
Compare newly retrieved facts with the existing memory. For each new fact, decide whether to:
- ADD: Add it to the memory as a new element
- UPDATE: Update an existing memory element
- DELETE: Delete an existing memory element
- NONE: Make no change"""以下是一个大模型决策的示例输出:
{
"memory": [
{"id": "0", "text": "Likes cheese and chicken pizza", "event": "UPDATE"},
{"id": "1", "text": "Name is John", "event": "NONE"},
{"id": "2", "text": "Dislikes cats", "event": "ADD"}
]
}在这个例子中,第一条原有记忆“喜欢芝士披萨”需要更新为“喜欢芝士和鸡肉披萨”;第二条“名字叫 John”已存在,无需变动;第三条“讨厌猫”则为全新信息,需新增存储。
步骤4:执行操作
决策结果生成后,系统会根据不同的 event 类型执行对应的CRUD操作:
for resp in new_memories_with_actions.get("memory", []):
action_text = resp.get("text")
event_type = resp.get("event")
if event_type == "ADD":
memory_id = self._create_memory(action_text, existing_embeddings, metadata)
elif event_type == "UPDATE":
self._update_memory(memory_id=temp_uuid_mapping[resp.get("id")],
data=action_text, existing_embeddings=existing_embeddings, metadata=metadata)
elif event_type == "DELETE":
self._delete_memory(memory_id=temp_uuid_mapping[resp.get("id")])
elif event_type == "NONE":
pass记忆创建的具体实现
以 _create_memory() 方法(位于 mem0/memory/main.py:1075)为例,它主要完成以下任务:生成唯一ID、构建元数据(包括原始数据、MD5哈希值和创建时间)、将向量嵌入和元数据写入向量数据库,并同时在SQLite中记录操作历史。
def _create_memory(self, data, existing_embeddings, metadata=None):
memory_id = str(uuid.uuid4())
metadata["data"] = data
metadata["hash"] = hashlib.md5(data.encode()).hexdigest()
metadata["created_at"] = datetime.now(pytz.timezone("US/Pacific")).isoformat()
self.vector_store.insert(vectors=[embeddings], ids=[memory_id], payloads=[metadata])
self.db.add_history(memory_id, None, data, "ADD", ...)
return memory_id四、图存储添加:_add_to_graph()
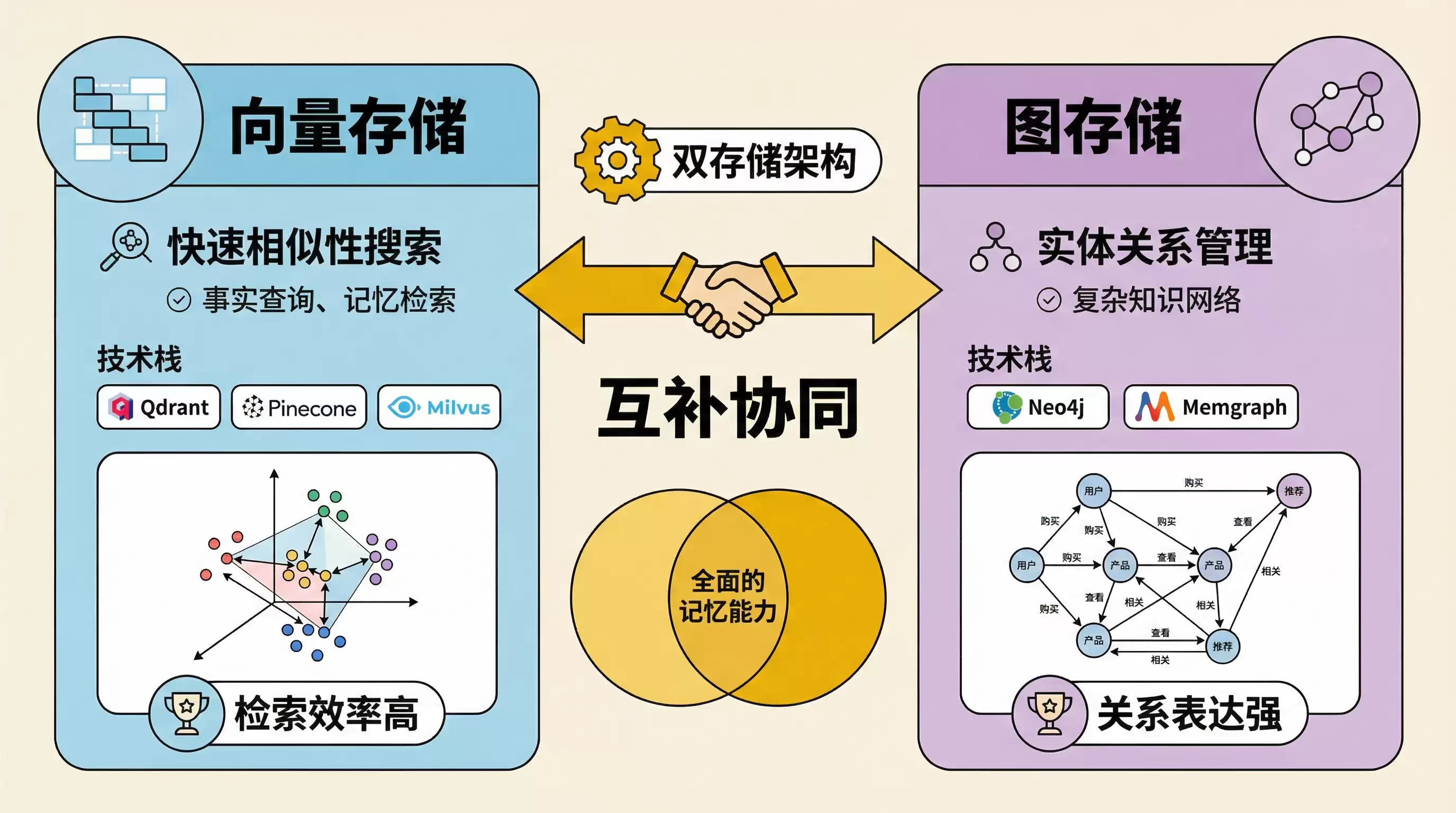
向量存储主要处理事实检索,而图存储则负责管理实体及其之间的关系,更适合构建复杂的知识网络。
入口方法
该方法位于 mem0/memory/main.py:599:
def _add_to_graph(self, messages, filters):
if self.enable_graph:
data = "n".join([msg["content"] for msg in messages if msg["role"] != "system"])
added_entities = self.graph.add(data, filters)
return added_entities图存储的核心逻辑
图存储模块本身位于 mem0/memory/graph_memory.py:76,其核心步骤包括:
def add(self, data, filters):
# 1. 从数据中提取实体
entity_type_map = self._retrieve_nodes_from_data(data, filters)
# 2. 建立实体间的关系
to_be_added = self._establish_nodes_relations_from_data(data, filters, entity_type_map)
# 3. 在图数据库中搜索相似节点
search_output = self._search_graph_db(node_list=list(entity_type_map.keys()), filters=filters)
# 4. 识别需要删除的实体(如发现矛盾关系)
to_be_deleted = self._get_delete_entities_from_search_output(search_output, data, filters)
# 5. 执行删除和添加操作
deleted_entities = self._delete_entities(to_be_deleted, filters)
added_entities = self._add_entities(to_be_added, filters, entity_type_map)
return {"deleted_entities": deleted_entities, "added_entities": added_entities}系统首先借助大模型从数据中抽取实体及其类型,然后建立实体之间的关联。接着,对比图数据库中已有的节点,决定哪些实体需要新增、哪些需要删除(例如检测到矛盾关系时),最后执行实际的增删操作。
举个例子,如果用户说“张三喜欢喝星巴克的拿铁”,提取结果大致为:
- 实体:
{ "张三": "person", "拿铁": "drink", "星巴克": "brand" } - 关系:
[ {"source": "张三", "relationship": "likes", "destination": "拿铁"}, {"source": "拿铁", "relationship": "brand", "destination": "星巴克"} ]
最终存入Neo4j等图数据库的三元组类似:
(张三:Person) -[:LIKES]-> (拿铁:Drink) -[:BRAND]-> (星巴克:Brand)五、关键组件介绍
LLM 工厂模式
Mem0 支持多种大模型,并通过工厂模式实现灵活切换:
# mem0/utils/factory.py
class LlmFactory:
provider_to_class = {
"openai": ("mem0.llms.openai.OpenAILLM", OpenAIConfig),
"anthropic": ("mem0.llms.anthropic.AnthropicLLM", AnthropicConfig),
"azure_openai": ("mem0.llms.azure_openai.AzureOpenAILLM", AzureOpenAIConfig),
"gemini": ("mem0.llms.gemini.GeminiLLM", BaseLlmConfig),
...
}类似地,Embedding模型和向量存储也各有相应的工厂类,覆盖了主流的商业及开源方案,例如:OpenAI、HuggingFace、Qdrant、Chroma、Pinecone、Milvus、Weaviate等。
六、完整流程示例
理论阐述过后,让我们通过一个完整示例来串联全流程:
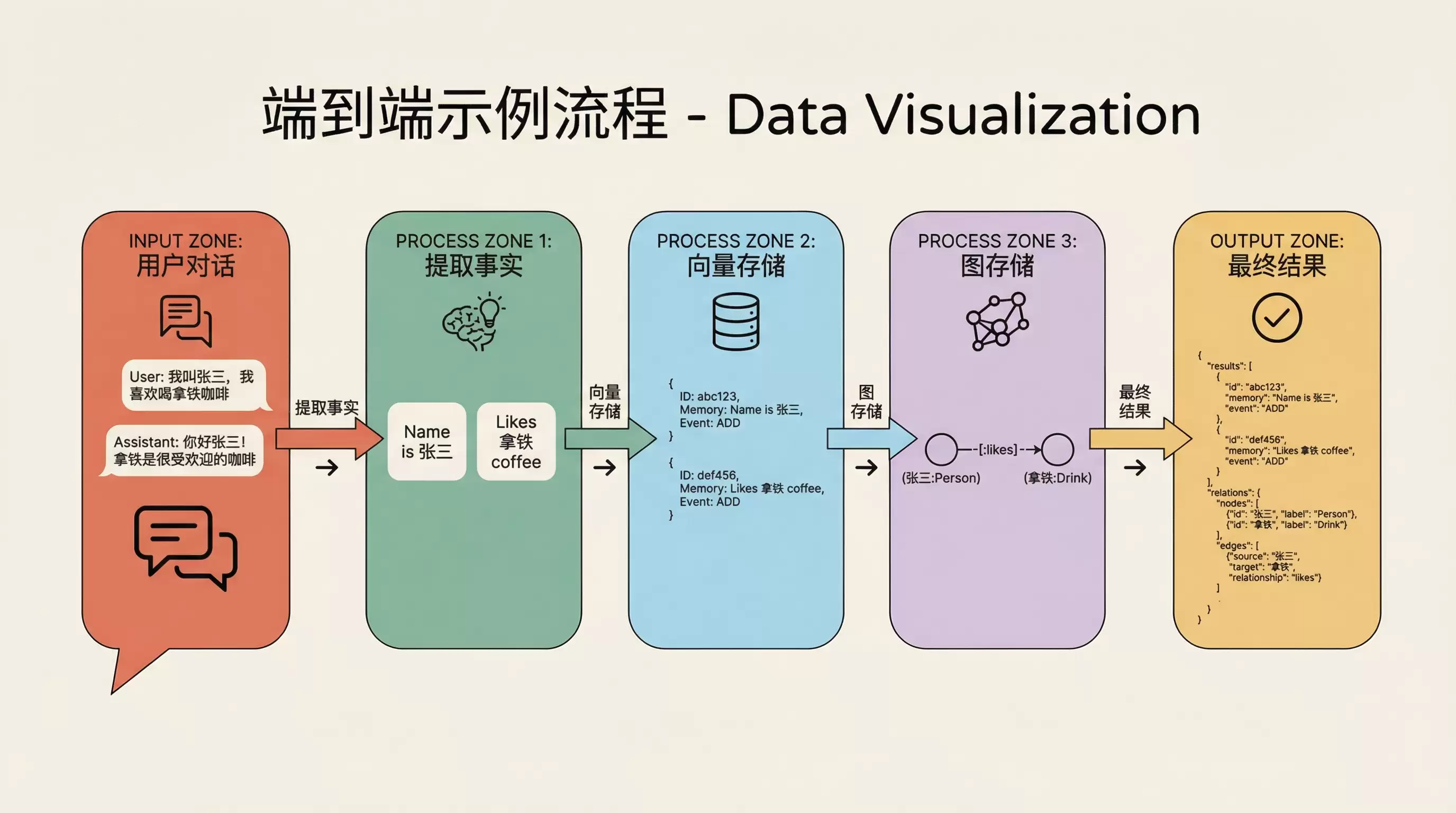
from mem0 import Memory
memory = Memory()
messages = [
{"role": "user", "content": "我叫张三,我喜欢喝拿铁咖啡"},
{"role": "assistant", "content": "你好张三!拿铁是很受欢迎的咖啡"}
]
result = memory.add(messages, user_id="zhangsan")返回的结果如下:
{
"results": [
{"id": "abc123", "memory": "Name is 张三", "event": "ADD"},
{"id": "def456", "memory": "Likes 拿铁 coffee", "event": "ADD"}
],
"relations": {
"deleted_entities": [],
"added_entities": [
{"source": "张三", "relationship": "likes", "target": "拿铁"}
]
}
}整个流程拆解如下:大模型提取出两条事实→在向量数据库中搜索(假设为新用户,未找到相似记忆)→大模型决定全部执行 ADD→在向量库中创建两条记忆记录→图存储提取实体 {“张三”: “person”, “拿铁”: “drink”} 并建立它们之间的关系。
七、设计亮点
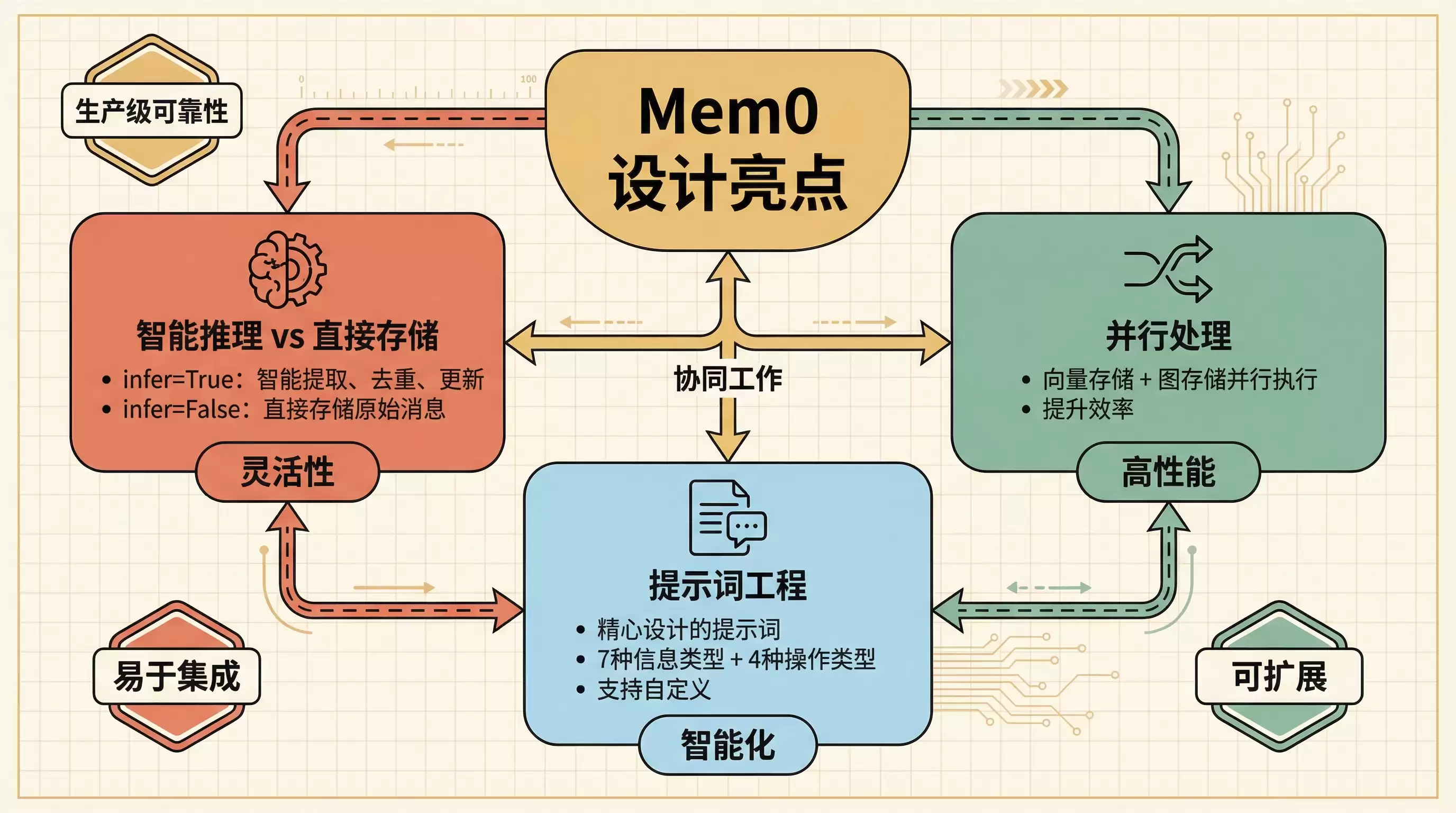
智能推理与直接存储的灵活切换。两种模式对应不同应用场景:生产环境推荐使用 infer=True,可以实现智能提取、去重与更新;若业务需求是保留完整的原始对话记录,则 infer=False 是更直接高效的选择。
双存储架构设计。向量存储擅长快速相似性搜索,而图存储则擅长管理实体间的网络关系——两者优势互补,缺一不可。
并行处理机制。向量存储与图存储的写入操作互不影响,通过 ThreadPoolExecutor 实现并行提交,从架构上避免了串行等待带来的性能瓶颈。
提示词工程。这是 Mem0 能够 “聪明” 管理记忆的核心所在。事实提取提示词定义了7种信息类型,记忆更新提示词定义了4种操作类型,并且系统支持用户自定义提示词。可以说,提示词的质量直接决定了记忆管理效果的优劣。
八、总结
回顾整个流程,Mem0 的添加记忆机制绝不仅仅是简单的“存进去”,而是一套完整的智能决策链路:
- 先让大模型从对话中精准抽取有价值的事实
- 再到向量数据库中检索已存在的相似记忆
- 然后由大模型决策新事实应执行新增、更新、删除或不处理
- 最后将结果同时写入向量存储和图存储
其核心设计理念非常清晰:以大模型管理记忆生命周期,向量存储负责事实级检索,图存储负责实体关系建模,而并行处理则确保了系统的高效运行。
当然,这一切智能化操作的起点,都源自精心设计的提示词。下一篇,我们将专门深入拆解 Mem0 的提示词工程,探究这些提示词的设计精髓,以及它们对记忆管理智能化程度的影响。
- 下一篇预告:提示词工程的深度解析
相关代码文件参考:
mem0/memory/main.py:核心 Memory 类mem0/memory/graph_memory.py:图存储实现mem0/configs/prompts.py:提示词定义mem0/utils/factory.py:各类工厂模式实现




