 信息图封面:verify 实验结果 三档工作流
信息图封面:verify 实验结果 三档工作流
图:verify 实验结果 三层改造复盘 三档工作流设计
从第5期到第7期,这个系列一直在与AI生成的Task列表、Review报告以及Verify报告进行深度磨合。
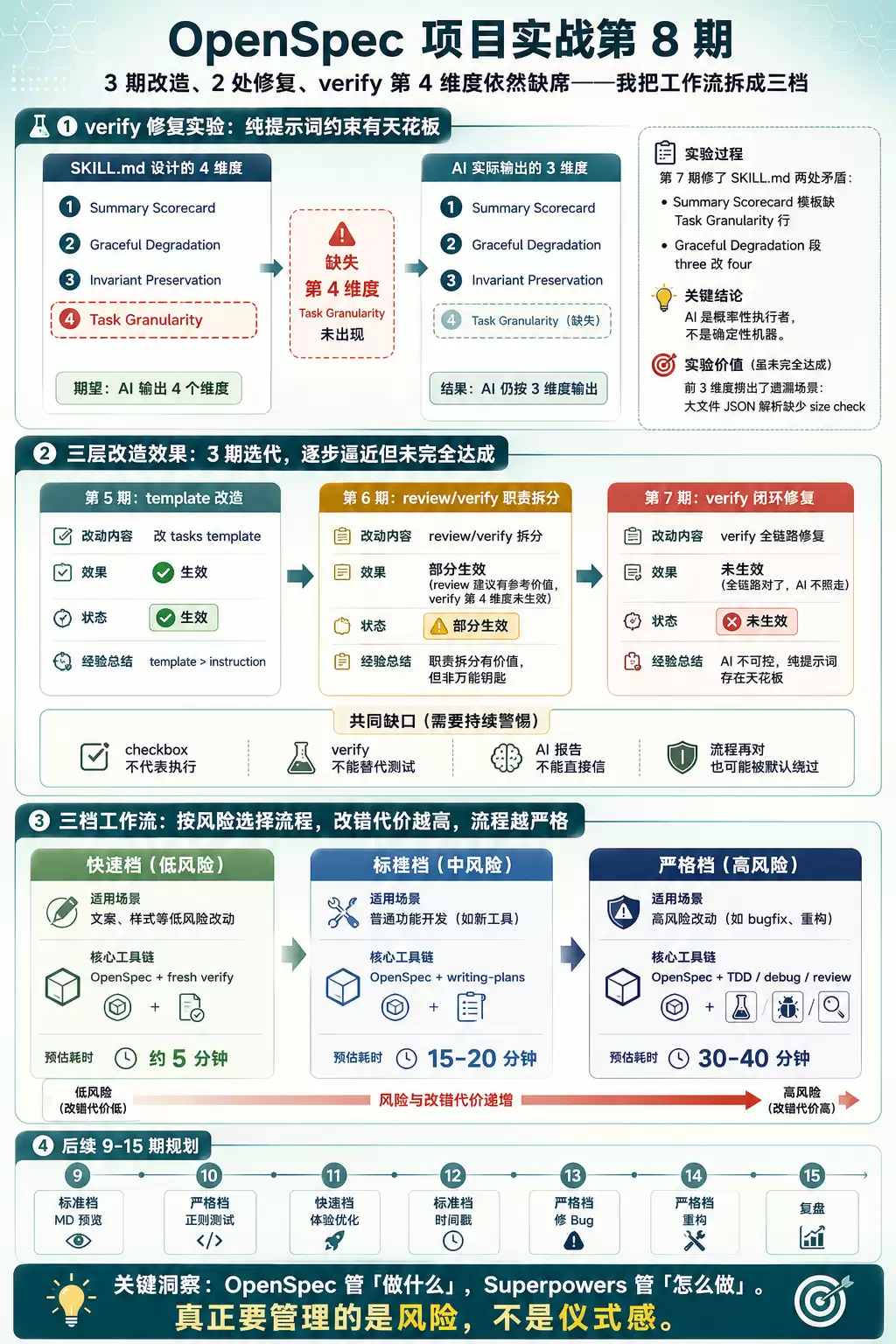
第5期优化了tasks template后,Tasks的格式终于稳定下来。第6期将Review与Verify的职责进行了拆分,使Review提供的拆分方向建议更具参考价值。第7期好不容易修复了Verify SKILL.md中两处相互矛盾的表述,原本以为这次能看到第4维度——Task Granularity出现在报告中。
结果呢?Verify报告的Summary表格依旧只有3行:Completeness、Correctness、Coherence。与修改前完全一致。
本期不开发新功能,专门复盘第7期Verify修复实验的真实结果,梳理第5-7期三层改造究竟解决了哪些问题,还存在哪些不足。更重要的是,基于这些经验教训,为后续系列设计一套可靠的工作流规则——根据风险选择流程强度,不再采取一刀切的方式。
完整流程如下:
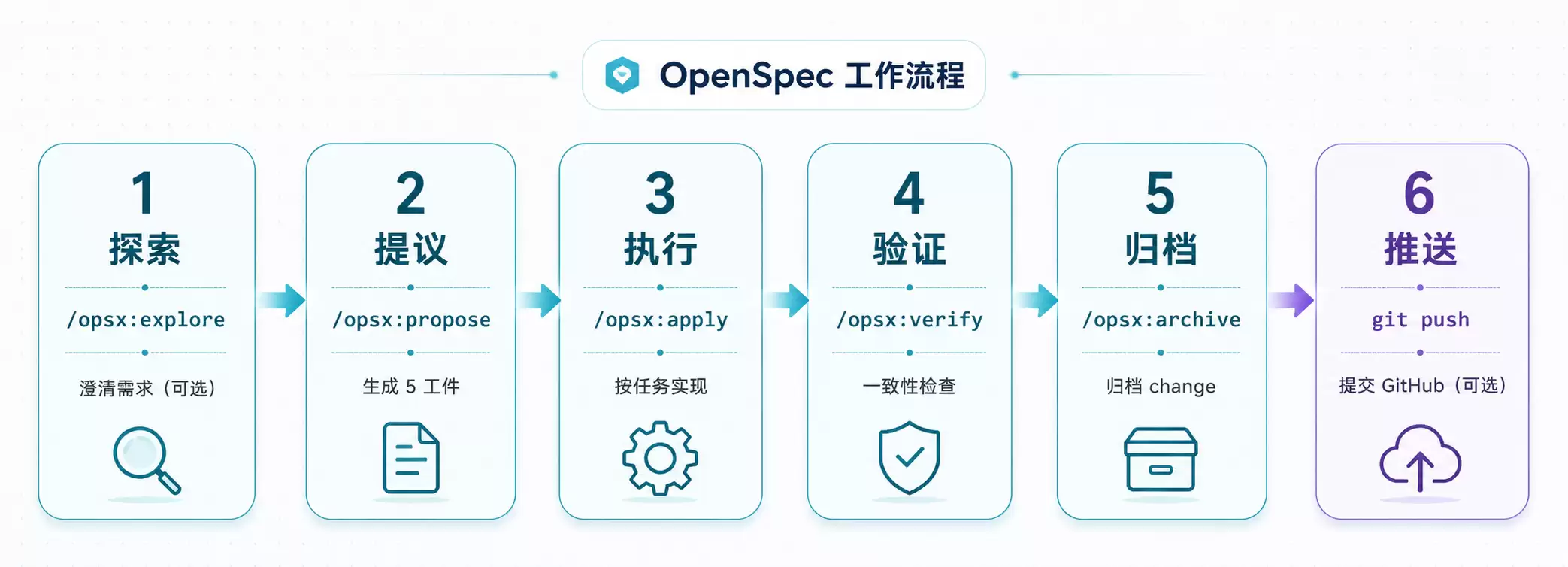 工作流总览
工作流总览
第7期verify修复实验:修改全链路后,AI依然沿旧路径运行
先交代一下第7期具体修复了什么。
第6期在Verify SKILL.md中新增了第4维度Task Granularity,但执行/opsx:verify后,报告只输出了3个维度。当时翻阅了一遍源文件,根本原因是SKILL.md内部存在矛盾——L46定义部分明确写了four dimensions,但后面两处引用依然在使用three:
- Summary Scorecard模板(L117-127):表格只有3行,缺少Task Granularity行
- Graceful Degradation段落(L159-164):最后一句写的是
verify all three dimensions
第7期修改了两处:Summary Scorecard增加了Task Granularity行(| Task Granularity | Format/TDD/Code |),Graceful Degradation中的three改为four。改动确实很小。
修改完成后,直接执行Propose → Apply → Verify流程,理论上本期Verify阶段应该能够使用修复后的配置。执行/opsx:verify后,AI输出的报告如下:
### Summary
| Dimension | Status |
|--------------|---------------------|
| Completeness | 11/11 tasks, 7/8 scenarios |
| Correctness| Requirement implemented, 1 scenario uncovered |
| Coherence| Followed/Issues|3行。Task Granularity并未出现。
定义、模板、退化逻辑全链路都已统一,但AI生成报告时依然跳过了模板,按照惯性输出。
老实说,看到这个结果时有些意外。修复前以为是只修改定义而未更新引用的问题,以为同步引用后就能生效。但实际情况是,即使全链路都已对齐,AI在生成输出时并不会严格按模板逐项填充——它有自己的惯性路径,读到模板但不一定遵循。
有一个反直觉的点值得一提:Verify报告虽然缺少第4维度,但在其他3个维度上发挥了实际价值。例如,第7期/opsx:verify的实际输出中,它发现了一个CRITICAL issue——spec里定义了处理大文件JSON解析(超过1MB需提示用户),但实现中未进行size check。还发现了一个WARNING——有效JSON点击语法校验按钮的测试用例缺失。这些都是specs写了但tasks未覆盖到的场景,Verify将它们识别了出来。
结论是:Verify并非无用,其后置检查确实有效,但纯提示词的约束存在天花板。
再看Verify SKILL.md的当前版本——L46-54确实定义了四个维度,Task Granularity下面还详细拆分了四项检查:任务格式(### 任务 N)、TDD合规(Red/Green/Refactor)、代码完整性(无TBD/TODO)、粒度评估(2-5分钟范围)。定义本身没有问题。Summary Scorecard模板也添加了Task Granularity行。Graceful Degradation也改为了four。全链路都已对齐,但AI就是不输出。
这给出了一个很现实的教训:提示词约束是一条链路,而非孤立的定义。L46写得再漂亮,如果后面模板和退化逻辑没有跟上,执行层就会沿用旧路径。但反之亦然——全链路都跟上了,也不代表AI一定会遵循。这是提示词约束与代码逻辑的本质区别:代码是确定性的,提示词是概率性的。修改代码中的if (x === 3)为if (x === 4),行为一定会变。修改提示词中的three为four,行为可能不变。
 verify 报告 3维度 vs SKILL.md 定义的4维度
verify 报告 3维度 vs SKILL.md 定义的4维度
图:SKILL.md定义了4个维度,AI实际只输出了3个,Task Granularity缺席
三层改造解决了什么,未解决什么
将第5-7期放在一起审视,每期改造的效果其实非常清晰。
第5期:template改造(生效)
前4期的tasks.md格式都不规范——使用了## 1.和 - [ ] 1.1这样的扁平列表,AI不会按照TDD五步结构拆分任务。修改instruction无效,根因是OpenSpec源码中template优先级高于instruction。旧template使用的正是## 1.格式。
修改tasks template后,替换为### 任务 N:[名称] 涉及文件列表 TDD五步结构(写失败测试 → 确认失败 → 写最小实现 → 确认通过 → 提交)。从第5期开始,tasks.md格式规范了,后续几期都稳定输出。
这条经验很直接:template比instruction更能约束输出格式。
第6期:review/verify职责拆分(部分生效)
有读者反馈:Review维度5(任务粒度审查)形同虚设——Review在tasks之前生成,根本看不到tasks.md,如何审查任务粒度?
于是从两个方面进行了修改。Review从5维度减少到4维度,删除了维度5,改为为tasks提供拆分方向建议。Verify从3维度增加到4维度,新增Task Granularity维度。
效果:Review的拆分方向建议确实具有参考价值——第6期和第7期都输出了先纯函数、再组件、最后路由的建议,与实际tasks拆分一致。Verify第4维度未生效(因内部矛盾,第7期修复矛盾后仍未生效)。
第7期:verify闭环修复(未生效)
上一节已详细阐述。全链路同步后,AI仍然按照3维度输出。
三层改造的共同短板
三层改造各有收获,但有几个问题是它们都无法解决的:
- task checkbox无法证明真正按TDD执行:tasks.md中的
[x]只记录AI声称的状态,不记录实际执行过程。AI可以标记[x]但实际跳过了某些步骤。 - verify报告无法替代fresh test/build/browser:Verify是AI自我审查。第7期Verify发现了遗漏场景,但json-formatter的export default bug是通过浏览器检查才发现的。
- AI完成报告不能直接信任:apply阶段的完成报告显示11/11 tasks complete,但json-formatter的index.tsx缺少
export default,导致页面加载直接卡死。 - 对低风险任务使用完整流程会拖慢速度:并非每个改动都需要完整的TDD review verify流程。修改按钮颜色就走全套流程,投入产出比过低。
这四个短板指向同一个问题:质量保证不能仅依赖后置检查,执行过程中的纪律同样重要。而后置检查的约束力,又受限于AI对提示词模板的遵循程度。
换个角度来说,这三个问题(checkbox不代表执行、verify不能替代测试、AI报告不能直接信任)本质上都是同一个根因:AI是概率性的执行者,而非确定性的机器。它读到了规则不等于会遵守规则,标记了完成不等于真正完成,通过了verify不等于代码没有问题。要弥补这个差距,要么在执行过程中加强纪律(让AI不得不按规则走),要么在验证环节引入独立证据(不信任AI自身的输出)。前者是Superpowers的设计思路,后者是浏览器检查和fresh test的思路。
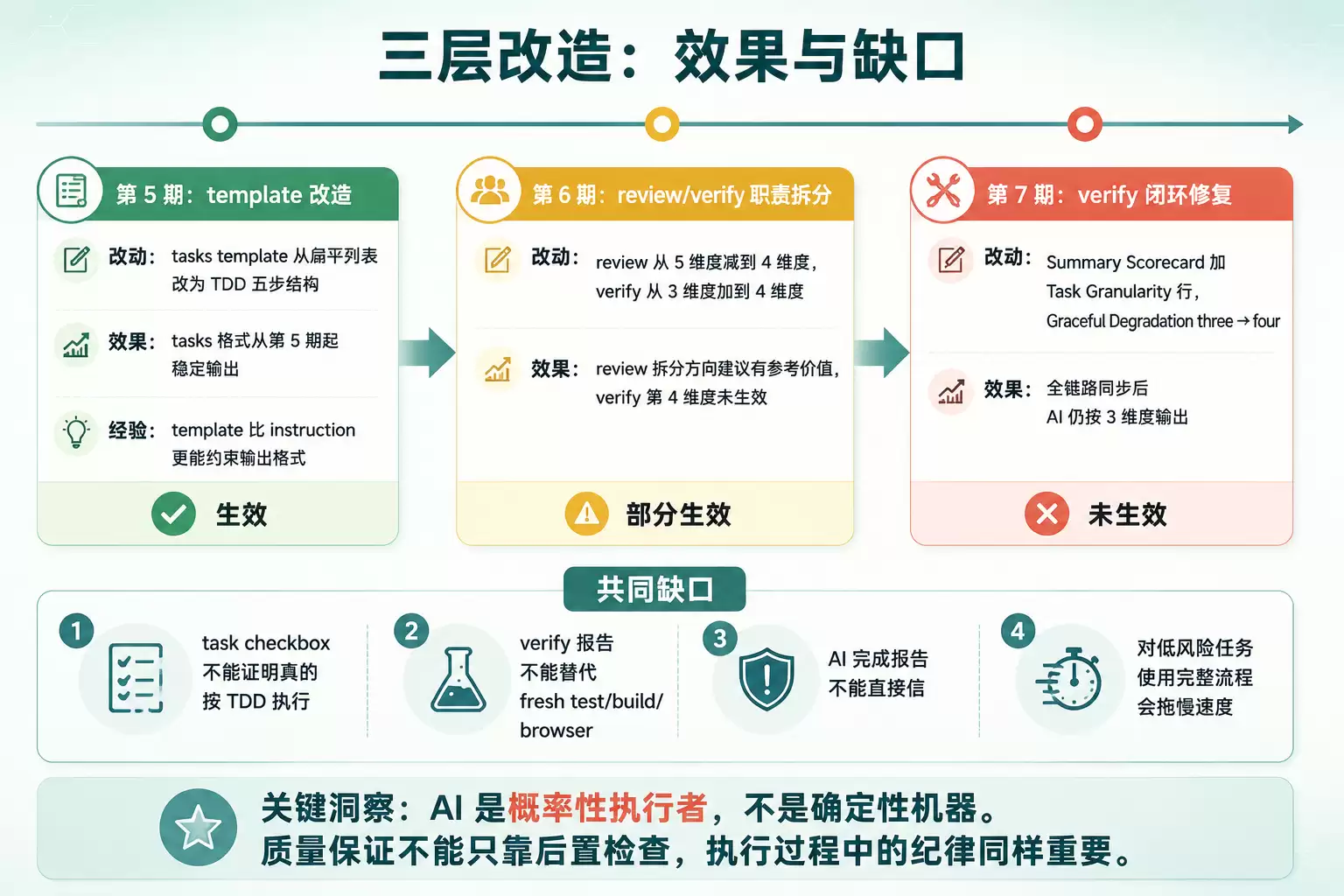 三层改造效果汇总
三层改造效果汇总
图:第5-7期改造效果 共同短板
为何引入Superpowers,但不全盘照搬
三层改造暴露的短板,恰好对应Superpowers几个核心skill要解决的问题。
writing-plans解决的是任务颗粒度不可控的问题。它将每个任务拆解为2-5分钟的步骤,每步都有明确的文件路径、代码模板和验证命令。计划颗粒度由结构化模板约束,不依赖AI自觉。这正好弥补了task checkbox无法证明执行过程的短板——不是让AI声称做了什么,而是在计划阶段就将每一步要做什么固定下来。
test-driven-development解决的是核心逻辑未经验证的问题。其铁律是先写失败测试,再写最小实现,遵循Red-Green-Refactor循环。如果未看到测试失败,就无法确认它测试了什么。这直接弥补了TDD执行纪律的短板。
verification-before-completion解决的是AI完成报告不可信的问题。其核心原则是证据优先,不允许在验证前声称完成。任何完成声明必须附有fresh verification evidence。不信任AI的成功报告。这对应了第7期json-formatter的export default bug——AI标记了11/11 complete但实际存在bug,如果有fresh browser check就不会遗漏。
subagent-driven-development解决的是高风险改动需要独立审查的问题。每个任务指派一个独立subagent执行,进行两阶段review:spec compliance review和code quality review。无需在任务间暂停等待人工确认,可连续执行。这适合核心逻辑、bugfix、公共模块重构等一处错误会影响多个工具的场景。
但并非所有任务都需要这套完整流程。
写一个按钮文案或修改颜色,不需要writing-plans拆解为2-5分钟步骤。调整CSS间距,不需要先写失败测试。工具页标题修改措辞,不需要subagent两阶段review。
说白了,Superpowers的每个skill都有其适用场景,但如果所有改动都走全套流程,速度会慢到不实用。项目实战需要速度,不能只追求流程的完备性。
因此答案并非OpenSpec与Superpowers二选一,也不是所有任务都采用Superpowers严格档。正确的做法是按风险选择流程强度。
三档工作流:快速档、标准档、严格档
基于上述分析,后续系列的工作流分为三档。每档的适用场景、工具组合、质量门槛和速度成本都各不相同。
快速档:低风险改动
适用场景:文案调整、样式微调、小范围UI交互优化。可通过浏览器和截图快速确认的改动。即使出错也不会影响其他功能。
执行流程:
OpenSpec propose/tasks/apply → /opsx:verify → npm run build → 浏览器检查主路径 → /opsx:archive质量门槛:
- fresh verification,不依赖AI的完成报告就确认完成——第7期正是AI标记了11/11但页面加载卡死
- 必须通过浏览器确认主路径——export default的bug只有浏览器能发现
- 不强制完整TDD——修改按钮颜色不需要先写失败测试
速度:与之前的OpenSpec单工具流程基本一致,多了一步浏览器确认。预估额外成本约5分钟。这里的时间是流程设计估算,并非本期实测耗时。
在shuge AI Toolbox中,快速档适合的场景:工具页标题措辞调整、textarea高度修改、按钮hover效果调整、页面间距调整、提示文案修改。这些改动的共同特征是:影响范围小(只改一个组件甚至一行CSS),验证方式直观(看一眼就知道对不对),回滚成本低(改回来即可)。
快速档的底线是不能省掉浏览器检查。即使只修改了一行CSS,也要打开页面查看实际效果。这5分钟的投入,能够拦截AI标记了完成但页面未变、改了颜色却影响了其他元素等低级问题。
标准档:普通功能开发
适用场景:实现一个独立工具。具有明确的输入和输出。包含核心纯函数或可测试逻辑。即使出错也只影响这一个工具。
执行流程:
OpenSpec propose → proposal/specs/design/review/tasks 全套工件 → Superpowers writing-plans 展开执行计划 → /opsx:apply 执行 → /opsx:verify test build 浏览器检查 → /opsx:archive质量门槛:
- OpenSpec管理规格边界——proposal、specs、design定义做什么和不做什么
- Superpowers writing-plans管理执行颗粒度——将任务拆解为2-5分钟步骤,每步有文件路径和验证命令
- 核心逻辑必须进行测试——纯函数优先编写测试
- verify必须记录真实输出——不能概括,需引用原文
速度:比快速档多一个writing-plans环节。预估额外成本约15-20分钟,换来的是任务颗粒度的可控性和执行纪律的保证。这个数字后续需要在第9、12期实战中校准。
在shuge AI Toolbox中,标准档适合的场景:实现一个新工具(Markdown预览、时间戳转换等)、为已有工具添加新功能按钮、修改工具页的交互逻辑。
严格档:高风险改动
适用场景:bug修复、公共模块重构、路由和状态管理改动、核心算法修改。一处错误会影响多个工具或整个平台。
执行流程:
OpenSpec propose → Superpowers writing-plans 展开执行计划 → TDD 或 systematic-debugging → spec compliance review → code quality review → final verification → /opsx:archive质量门槛:
- 先有失败测试或根因分析——bug修复必须包含可复现的失败测试,不能仅修改代码就声称修复完成
- 每个重要任务需经过review——spec compliance确认实现了需求,code quality确认代码质量达标
- 不允许仅凭build通过就宣称完成——第7期build通过了,但export default bug依然存在
速度:比标准档多TDD和两阶段review环节。预估额外成本约30-40分钟,换来的是高风险改动的质量保证。这个数字同样是预估,后续需要用严格档实战进行校准。对于改错代价高昂的环节,这笔投入是值得的。
在shuge AI Toolbox中,严格档适合的场景:修复影响多个工具的bug、重构工具页的公共基础组件、修改路由或状态管理的核心逻辑。
三档对比
| 档位 | 适用场景 | 工具组合 | 质量门槛 | 预估额外时间成本 |
|---|---|---|---|---|
| 快速档 | 文案、样式、低风险体验优化 | OpenSpec fresh verify | build 浏览器确认主路径 | 约5分钟 |
| 标准档 | 普通工具功能、明确输入输出 | OpenSpec Superpowers writing-plans | plan颗粒度 测试 build 浏览器检查 | 约15-20分钟 |
| 严格档 | 核心逻辑、bugfix、公共重构 | OpenSpec Superpowers TDD/debug/review | 失败测试/根因证据 review loop final verification | 约30-40分钟 |
选择标准只有一句话:改错的代价有多高?代价越高,流程越严格。
修改一个按钮颜色,代价是用户点击两下发现不对,改回来即可。走快速档。实现一个新工具,代价是工具不可用但不影响其他功能。走标准档。重构公共基础组件,代价是一个改动可能影响所有工具。走严格档。
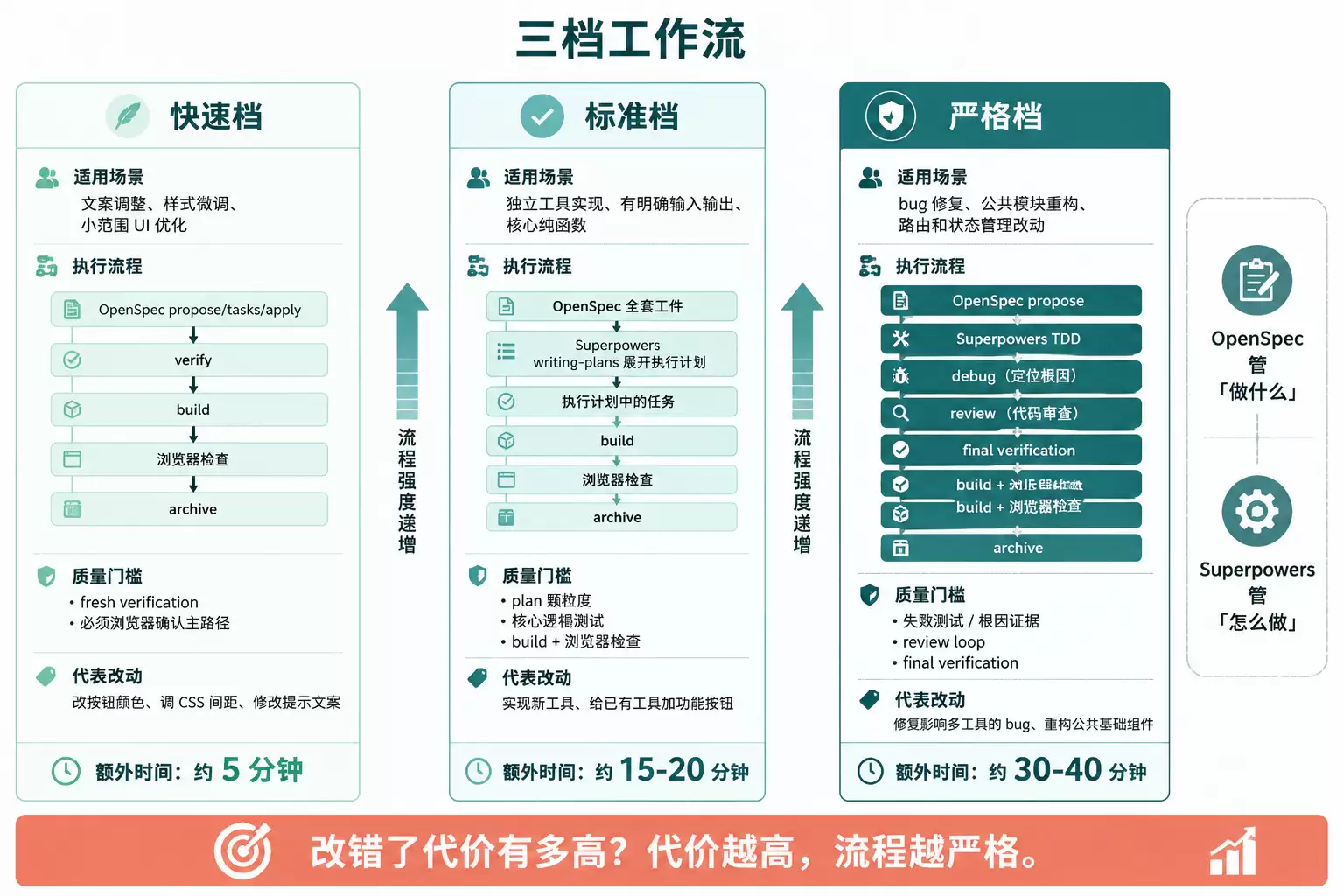 三档工作流对比
三档工作流对比
图:三档工作流的选择逻辑——风险越高,流程越严格
你在项目中是如何分级的?或者说,你认为这种按风险分级的思路在实际项目中可行吗?欢迎在评论区留言讨论。
后续系列如何应用这三档
第9-15期的档位分配已经确定下来,每期将使用对应的流程强度。
第9期:标准档,Markdown预览工具
这将是三档工作流的第一个实战验证。使用标准档实现Markdown预览工具:OpenSpec负责管理规格和工件,Superpowers writing-plans负责管理执行颗粒度。
关键验证点:writing-plans能否在不明显拖慢速度的前提下,使任务颗粒度比纯OpenSpec tasks.md更可控。如果writing-plans展开的执行计划比OpenSpec tasks更细致,并且apply阶段AI的执行更准确,那么标准档就有其价值。如果writing-plans只是增加了一层文档但执行效果相同,则需调整策略。
第10期:严格档,正则测试器
正则测试器的核心是正则表达式引擎和匹配高亮功能。这是一个具有复杂逻辑的工具,适合采用TDD驱动开发。先编写失败测试确认正则匹配行为,再编写最小实现。
关键验证点:TDD的Red-Green-Refactor循环在AI编程中是否确实能提升代码质量。正则表达式的边界条件较多(空输入、非法正则、超长匹配),TDD能够提前暴露这些边界问题。
第11期:快速档,工具页体验优化
在前两期严格档和标准档之后,插入一期快速档。纯UI/UX微调:按钮间距、交互反馈、加载状态、错误提示样式。采用快速档流程,验证低风险改动用轻量流程是否足够。
第12期:标准档,时间戳转换工具
继续使用标准档实现新工具。与第9期对比,观察标准档在不同工具上的稳定性和效率。
第13期:严格档,修复真实Bug
在第9-12期的工具开发过程中,很可能会积累一些bug。第13期专门用一个change修复一个真实bug,采用严格档:先复现、编写失败测试、定位根因、修复、verify。
关键验证点:systematic-debugging在AI编程中的实际效果。是否能够通过根因分析而非盲目修改代码来修复bug。
第14期:严格档,重构工具页公共基础
到第13期时,shuge AI Toolbox应该已有5-6个工具。每个工具页独立实现,但组件模式高度相似(textarea 操作控件 结果展示)。本期进行公共基础重构,提取共享组件。
采用严格档的原因:一处改动会影响所有工具。重构时不能破坏已有功能,每个改动都需要验证。
第15期:复盘
不开发新功能,复盘第9-14期的速度和质量数据。三档工作流在6期实战中的表现:快速档是否够快、标准档是否值得额外15分钟、严格档的review是否真正拦截了问题。
规划总览
| 期数 | 档位 | 内容 | 关键验证点 |
|---|---|---|---|
| 第9期 | 标准档 | Markdown预览工具 | writing-plans的颗粒度价值 |
| 第10期 | 严格档 | 正则测试器 | TDD在复杂逻辑中的效果 |
| 第11期 | 快速档 | 工具页体验优化 | 轻量流程对低风险改动是否够用 |
| 第12期 | 标准档 | 时间戳转换工具 | 标准档在不同工具上的稳定性 |
| 第13期 | 严格档 | 修复真实Bug | systematic-debugging的实际效果 |
| 第14期 | 严格档 | 重构工具页公共基础 | 严格档对高风险重构的保护 |
| 第15期 | 复盘 | 三档工作流速度和质量 | 数据驱动的流程评估 |
回顾:真正需要管理的是风险,而非仪式感
回看第5-7期的改造路径,其实都在回答同一个问题:如何使AI编程的产出质量可控。
第5期的答案是修改template。有效,但只管理了输出格式。第6期的答案是拆分Review和Verify的职责。有效,但后置检查存在天花板。第7期的答案是修复Verify的内部矛盾。做了,但AI不按模板执行。
三层改造的共同局限在于:它们都在后置检查上做文章。Template管理格式是后置的(format after generation),Review管理方向是后置的(review after propose),Verify管理质量是后置的(verify after apply)。后置检查有用——第7期Verify确实识别出了遗漏场景——但它无法保证执行过程本身是正确的。
三档工作流的逻辑是:将质量保证从后置检查向前移动。快速档依靠浏览器确认进行后置兜底。标准档依靠writing-plans进行计划前置。严格档依靠TDD和review进行执行过程控制。风险越高,前置越多。
OpenSpec适合管理方向和工件:proposal定义做什么,specs定义做到什么程度,design定义怎么做,archive留下变更记录。Superpowers适合管理执行纪律和证据:writing-plans管理计划颗粒度,TDD管理测试先行,verification-before-completion管理证据优先,subagent review管理独立审查。
两套工具并非二选一的关系,而是各管一段。OpenSpec管理做什么,Superpowers管理怎么做。三档工作流是根据风险选择组合强度。
说到底,真正需要管理的是风险,而非仪式感。
如果将三档工作流压缩为一条规则,那就是:修改之前先问自己,这个改动如果出了bug,需要花费多长时间定位和修复?答案是5分钟,走快速档。答案是半小时,走标准档。答案是半天甚至更久,走严格档。
这与软件工程中一直强调的风险驱动测试是同一个思路——并非所有代码都需要100%测试覆盖率,但高风险代码必须有测试。三档工作流将这个原则落实到了AI编程的工作流选择上。
预告
第9期将使用标准档实现Markdown预览工具。重点验证Superpowers writing-plans能否使执行颗粒度比纯OpenSpec tasks.md更可控,同时不明显拖慢速度。这是标准档的第一个实战样本。
声明:本文基于OpenSpec v1.3.1源码分析、实际项目操作记录和读者反馈整理。所有改造均在shuge-ai-toolbox项目中实际验证。配置和代码仅供参考,请以实际环境测试为准。




