一、案例说明
网页抓取时,多数网站返回的链接都是相对路径——光秃秃的,没有域名,直接拿着它去访问肯定报错。这个案例就是用火语言RPA,把页面里所有的相对链接一次性抓出来,再循环补上网站根域名,拼成标准的完整URL。说白了,就是解决“链接不能用”的痛点。适用于批量访问详情页、数据采集等场景。
二、案例逻辑
打开浏览器,进入目标公告页面(https://www.ccgp.gov.cn/cggg/zygg/ ),先把页面上所有链接的href相对路径批量提取出来。然后一条一条遍历这些短链接,拼接上根域名,生成可以直接点开的完整URL。逻辑清晰,没有弯弯绕。
三、操作细则
1、先建一个空列表,叫list1,用来存后面的完整链接。
2、打开浏览器,选一个你常用的浏览器类型(比如Chrome、Edge都行)。
3、在浏览器里输入目标网址:https://www.ccgp.gov.cn/cggg/zygg/ ,打开页面。
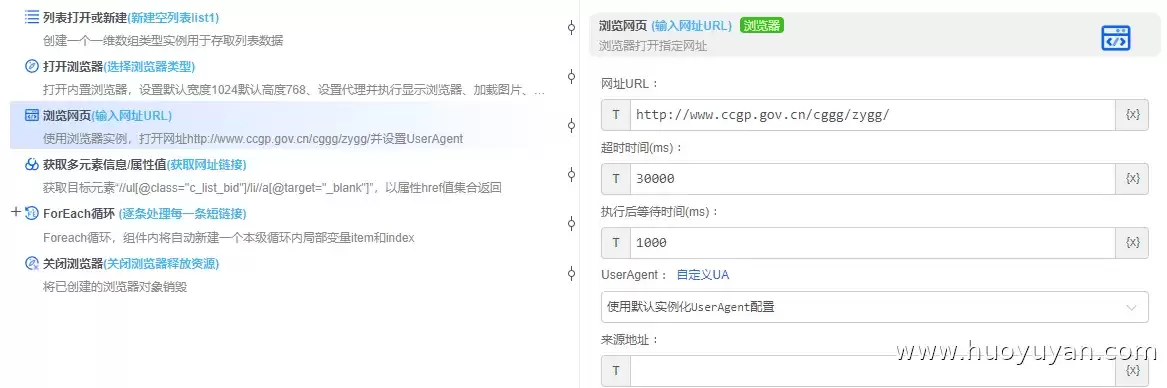
4、关键一步:抓取元素。用XPath定位到所有链接,获取它们的href属性值。可以看到,抓回来的都是相对路径(比如 ./fblbgg/……),没法直接用。这里要做的就是补全链接。
- 目标元素://ul[@class="c_list_bid"]/li//a[@target="_blank"]
- 返回结果:指定属性值
- 属性名称:href
5、用一个 ForEach循环,逐条处理每一条短链接。这一步是整个流程的核心。
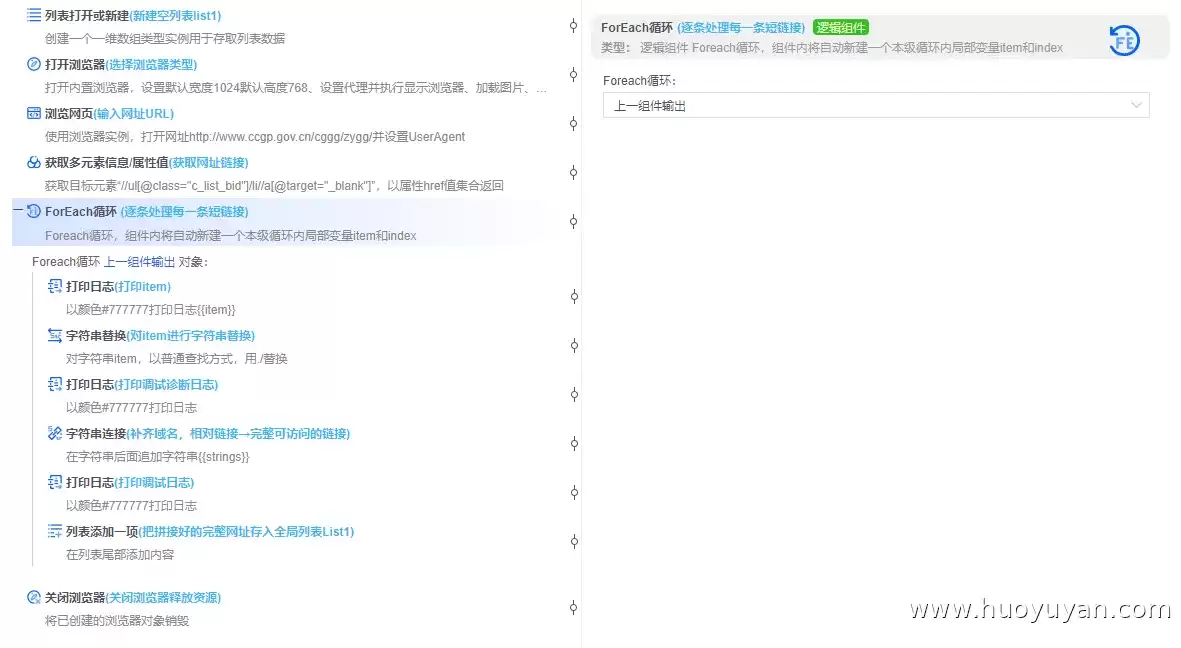
5.1 先打印日志,看看遍历出来的item是什么内容。打印结果:./fblbgg/202606/t20260605_26696649.htm。而完整URL应该是:https://www.ccgp.gov.cn/cggg/zygg/fblbgg/202606/t20260605_26696649.htm。对比一下,只需要把开头的 ./ 去掉,再拼上域名就可以了。
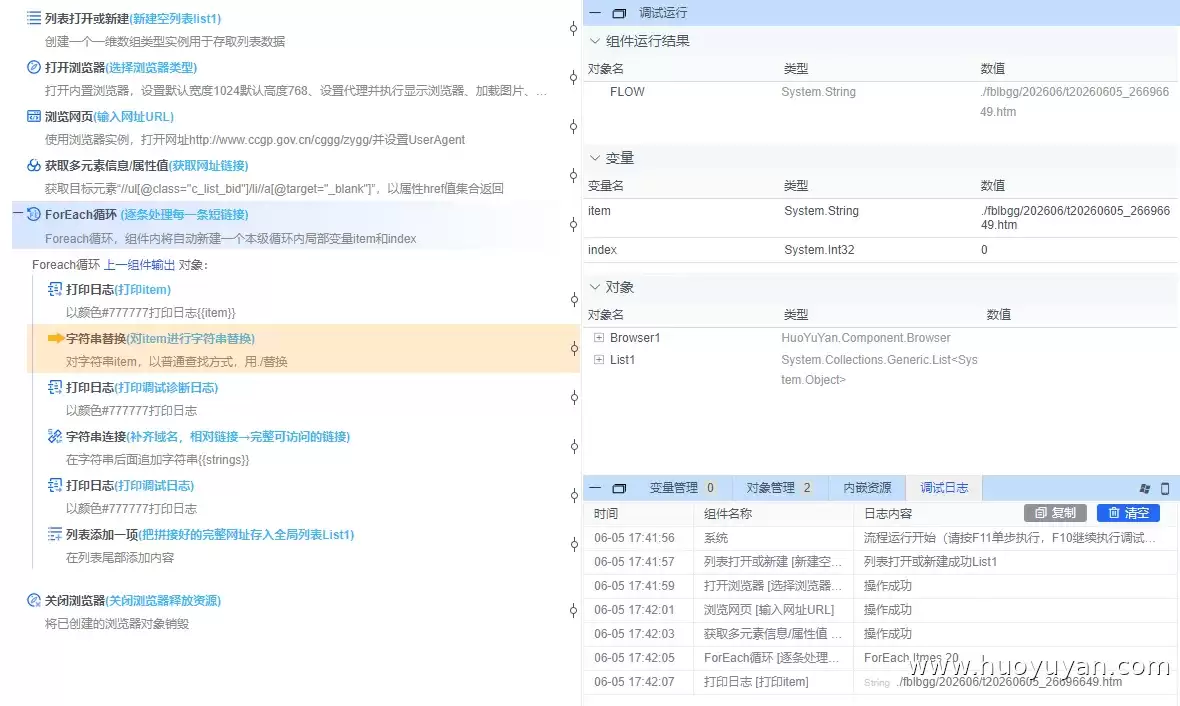
5.2 用 字符串替换 组件,把 item 里的 "./" 替换成空值,去掉这个恼人的前缀。
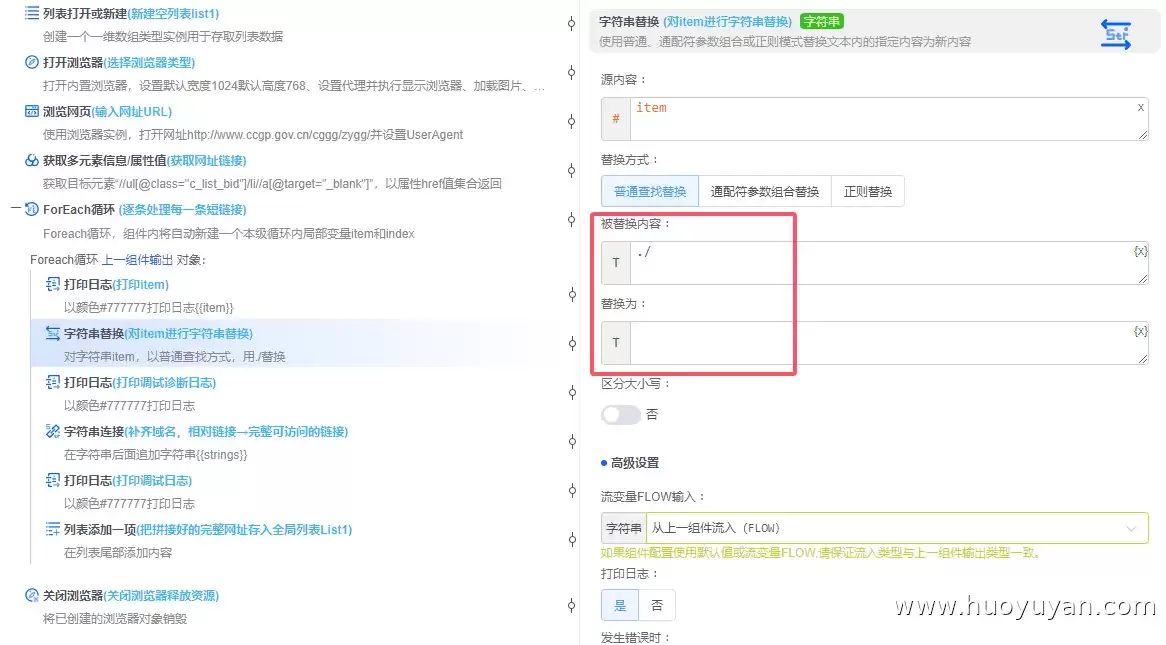
5.3 再打印日志确认:替换后的结果已经变成了 fblbgg/202606/t20260605_26696649.htm,干净多了。
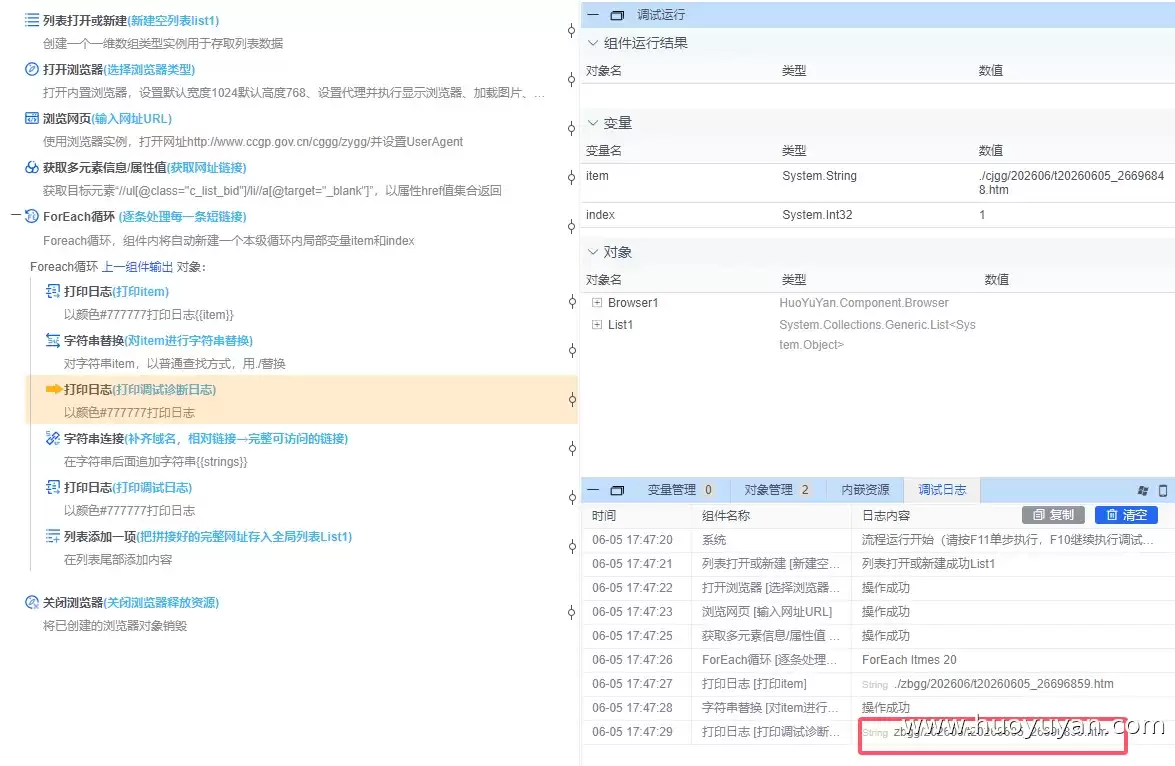
5.4 接下来用 字符串连接 组件,把根域名拼到前面。注意域名要带路径:https://www.ccgp.gov.cn/cggg/zygg/,这样就得到了完整的可访问链接。
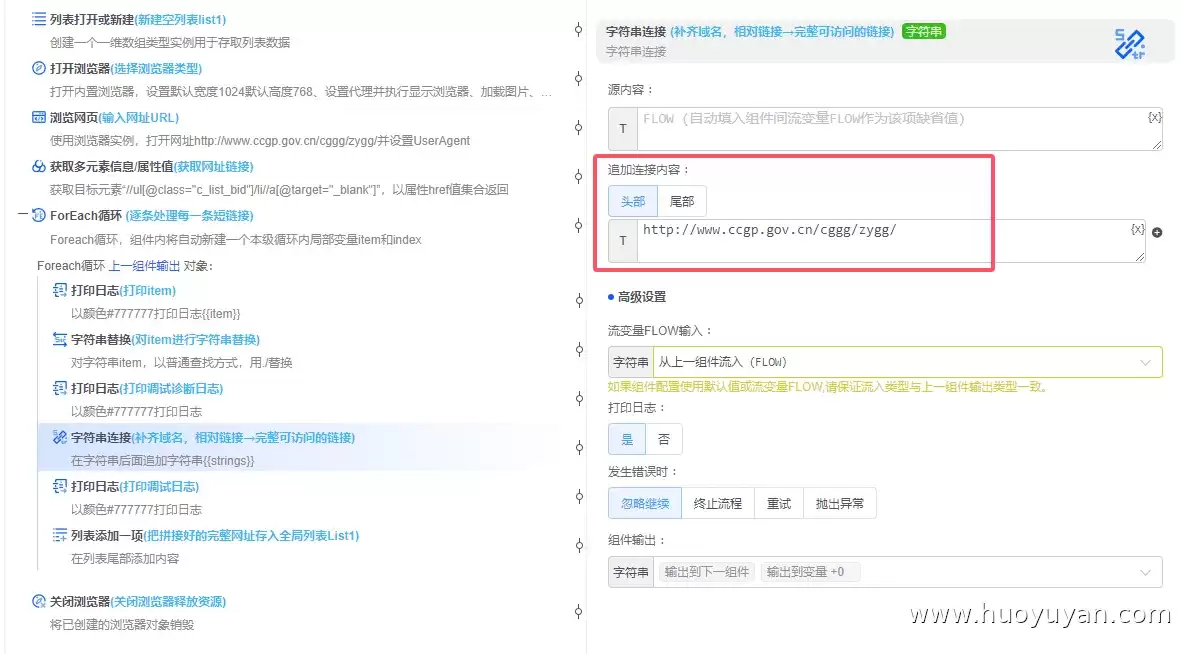
5.5 打印拼接后的结果,确认无误。


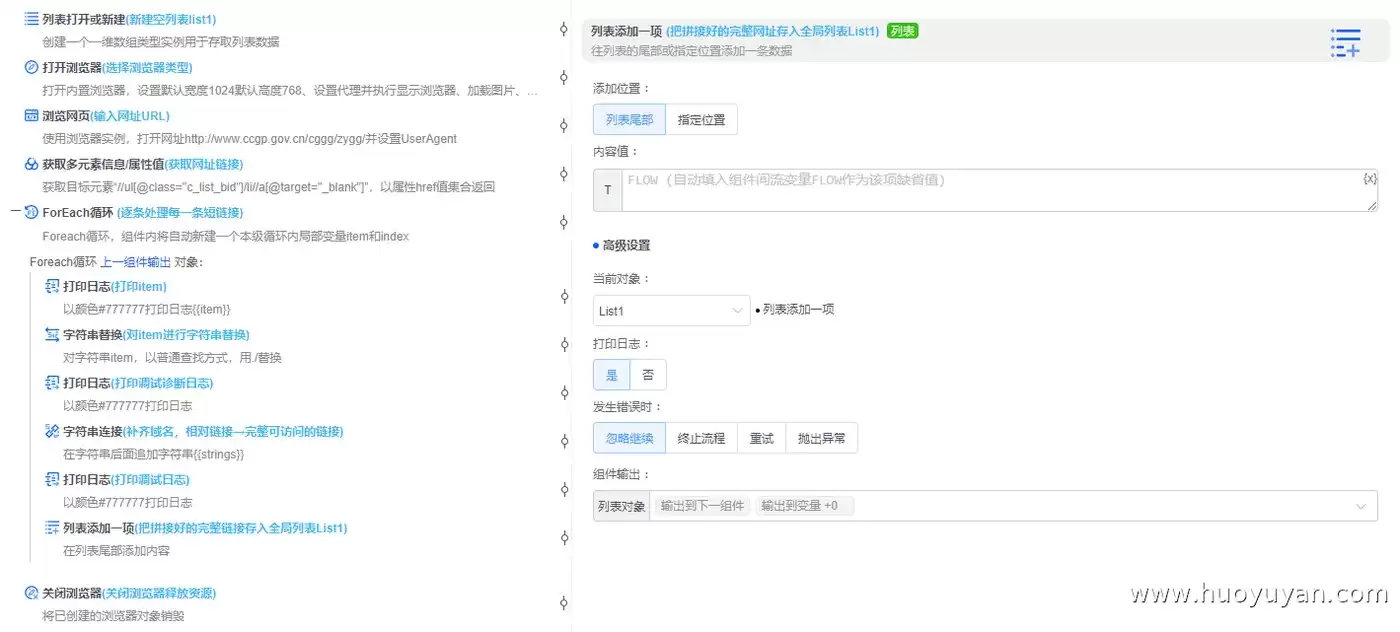
5.6 最后一步,用 列表添加一项,把拼好的完整链接存入全局列表 List1 中,方便后续使用。
6、全部处理完之后,别忘了关闭浏览器,释放资源。
四、划重点
网页抓取的 href 大多都是相对路径,不带域名,直接打开肯定报错。所以必须补上网站根域名。这里我们用了“字符串连接”组件来实现,当然你也可以直接使用“网址/图片地址获取”组件,效果一样。关键在于理解相对路径→绝对路径的转换逻辑,一通百通。




