先说个题外话。不少使用Claude Code、Cursor、Codex这类AI编程工具的朋友,应该都遇到过这种困扰:明明只是想请Agent修改一个小功能,上下文却像漏了底一样,飞快地往上涨。这确实是个让人头疼的问题。
实际上,token消耗得这么快,很多时候并不是因为模型推理有多复杂。真正的“元凶”,其实是Agent那些不起眼的“小动作”。仔细观察就会发现,Agent为了搞懂代码,往往需要反复执行grep、read、扫描文件;为了运行测试,大量的日志、报错信息、diff、命令输出都会一股脑塞进上下文。这些操作本身不可或缺,但问题在于它们夹带了太多“噪音”——无关的代码片段、重复的日志、无用的输出信息。正是这些噪音,变成了消耗你token的“黑洞”。
今天,我们来聊聊三个真正能帮上忙的开源项目。它们的核心任务很纯粹:帮你为Coding Agent的“上下文”做一次深度清理。让Agent少翻没用的代码,少读冗长的日志,把宝贵的token留给最核心的判断。没错,就是下面这三个项目:
CodeGraph:先给代码库建立一张“关系网络”
先来看CodeGraph。这个项目是上周在RTK项目介绍的贴图下,由@胡琦推荐的。他表示自己近期一直在用,效果很不错。感谢这位朋友的推荐。
项目名片如下:代码语言:txt复制CodeGraph = {"地址": "github.com/colbymchenry/codegraph","标星": "43.4k","开发语言": "TypeScript","特点": ["本地代码知识图谱", "MCP 接入", "减少 Agent 代码探索成本"],}
Agent要理解一个代码库,最直接的方式就是从文件开始逐一排查:查看目录结构、搜索关键词、读取文件内容、追踪函数调用……这个过程,和我们新手接手一个项目时做的差不多。唯一区别在于,我们消耗的是脑力,而Agent每多读一点内容,消耗的都是真金白银的token。CodeGraph的思路则更聪明:与其让Agent每次都从头翻代码,不如先将代码库梳理成一张结构化的“关系网”。在这张网里,函数、类、文件、调用关系、导入依赖……所有关键信息都一目了然。Agent接到任务后,先查阅这张“关系网”,就能迅速锁定相关的代码块、调用链、受影响文件。这样一来,就无需一开始就把整个项目目录塞进上下文。简单说,CodeGraph就像一份代码库的“结构地图”。Agent拿着地图找路,自然能少走很多弯路。这个工具最适合的场景也很明确:项目规模较大、文件繁多、调用关系复杂的时候。它能显著减少Agent盲目执行grep和read的次数,让Agent更快进入核心逻辑。因此,CodeGraph主要节省的是Agent为了“定位”相关代码而消耗的上下文。
RTK:给命令输出来一次“精炼提纯”
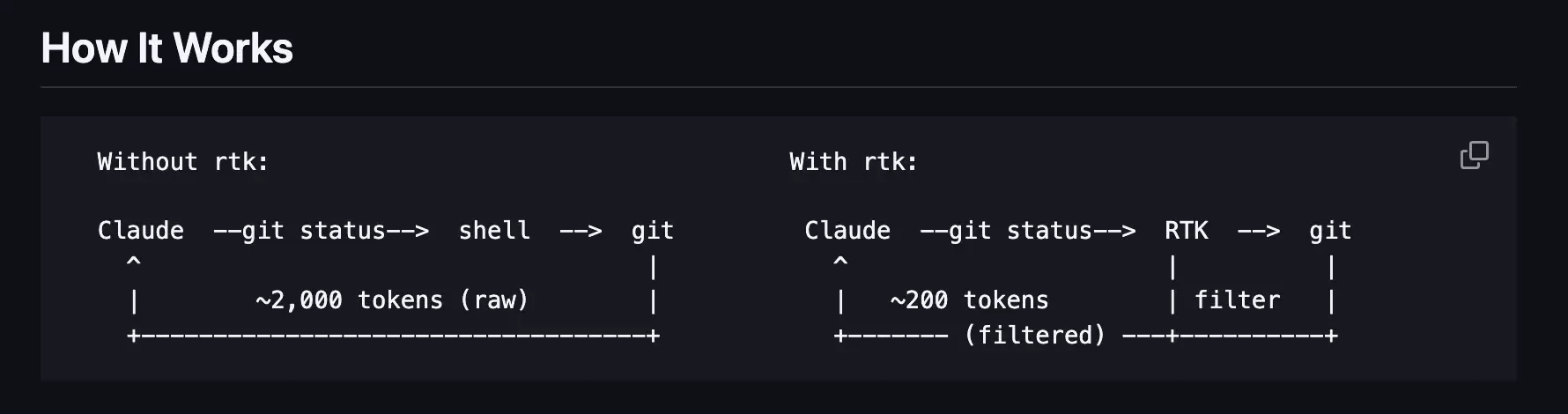
第二个要介绍的是RTK,全称Rust Token Killer。它直面的是另一类典型的token浪费:命令输出。
项目名片如下:代码语言:txt复制RTK = {"地址": "github.com/rtk-ai/rtk","标星": "59.6k","开发语言": "Rust","特点": ["命令输出压缩", "支持 100 种常用开发命令", "减少 Agent 读取日志和 diff 的 token 消耗"],}
Coding Agent在编写代码时,本质上就是一个命令执行器。git diff、npm test、cargo test、pytest、go test……这些命令的输出结果对Agent的决策至关重要,它需要依靠这些结果来判断代码是否运行正常、哪里出了错误。但问题在于,这些命令的原始输出往往又长又乱:测试日志里充斥着与当前任务无关的重复信息;构建输出中,错误消息被淹没在无关的编译进度里;diff输出里,Agent暂时不需要关注的代码细节也占据了大量篇幅。如果这些“噪音”原封不动地喂给模型,token自然不够用。RTK扮演了一个“中间人”的角色:它像一个CLI过滤器,在命令输出和Agent之间,先将输出结果压缩、过滤、整理,只把最精炼、最有价值的部分交给Agent。这样Agent看到的就不是杂乱无章的原始日志,而是一份结构清晰、重点突出的“简报”。这类工具最大的好处是,它不改变你的工作流程,也无需学习一套全新的工具。它只做一件很具体的事:让命令结果变得更短、更干净、更有用。因此,RTK主要节省的是Agent读取测试日志、报错信息、diff、命令结果时消耗的上下文。
Tokalator:为上下文装上“仪表盘”
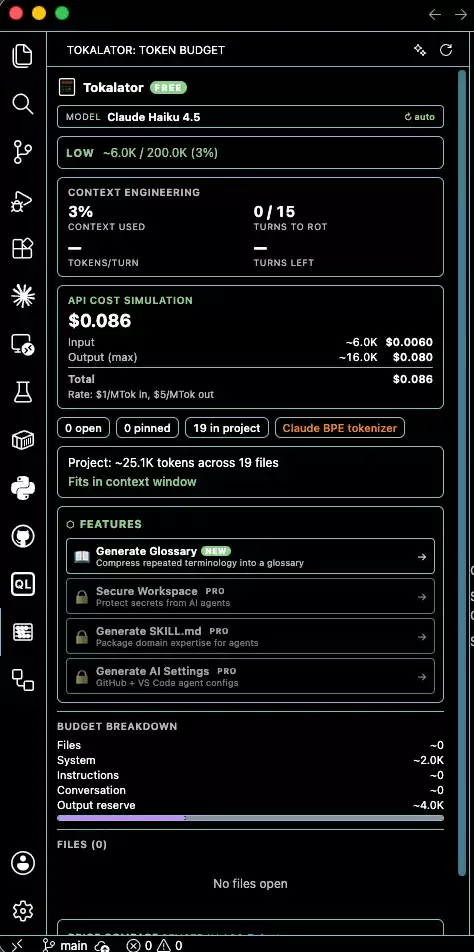
以上两个工具,一个帮Agent找准路径,一个帮Agent消化精华。Tokalator则解决另一个核心问题:你总得清楚自己的token到底花在了哪里,对吧?Tokalator定位为“面向AI Coding场景的上下文工程工具包”,包含VS Code扩展、CLI、MCP Server、用量追踪器等组件。它不会直接帮你改代码,而是帮你做一件更基础但也更重要的事:监控和分析你的上下文预算。
项目名片如下:代码语言:txt复制Tokalator = {"地址": "github.com/vfaraji89/tokalator","开发语言": "TypeScript","特点": ["实时 Token 预算监控", "MCP/CLI 接入", "看清上下文消耗来源"],}
大多数时候,我们在IDE里打开一堆文件,或者给Agent喂了一份很长的说明文档,往往很难直观感受到这些操作到底消耗了多少token。Token浪费在哪里,心里没数,优化也就无从下手。有了Tokalator,就像给上下文预算装了一个实时仪表盘。你能直观地看到:当前上下文用了多少?预算还剩多少?是哪个文件、哪段提示词快把容量撑爆了?知道了浪费点,我们才能更精准地调整文件选择、优化提示词,把有限的token都用在刀刃上。
小工具,大价值:延伸了解一下
除了以上三个精选项目,最近圈子里的动向也表明,大家都在朝这个方向发力。下面这些项目同样值得关注,不过不再逐一展开,作为延伸阅读清单供参考:
把上面的项目放在一起看,它们分别处理了不同位置的token使用问题:
本文精选了三个更具代表性的项目进行深度讲解,其余项目留给感兴趣的朋友自行探索。善用这些工具,能让我们的Agent更高效地工作,而不是更盲目地消耗资源。这才是真正的“降本增效”。




