6月9日消息,小米与TileRT联合发布了MiMo-V2.5-Pro-UltraSpeed,这一成果标志着行业迈出了标志性的一步:基于万亿参数大模型,在单台标准的8卡通用GPU节点上,首次实现了文本生成速度高达1000 tokens/s的突破。峰值表现甚至能达到1200 tokens/s,全程无需定制专用芯片,从而极大降低了极速AI推理的落地门槛。
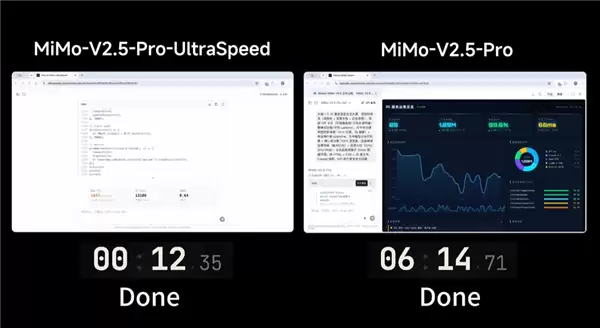
同步上线的限时API服务同样备受关注。其定价为原版MiMo-V2.5-Pro的3倍,但生成速度提升了约10倍,性价比优势十分突出。不过,受限于高速推理资源,该服务采用申请制限时开放,试用周期为北京时间6月9日至6月23日23:59。平台将优先审核有实际业务需求的企业与专业开发者,而普通用户则可通过专属网页免费体验对话功能。
具体使用规则方面:单账号每日排队上限为10次,单会话最长为30分钟,闲置5分钟将自动断开连接——这样设计旨在确保资源得到公平分配。
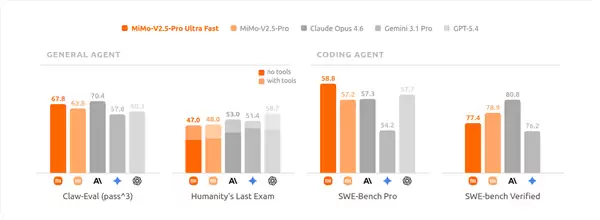
本次性能飞跃,本质上是模型与系统深度协同设计的结果,核心包含三大技术创新:
第一,FP4量化技术。针对模型MoE架构特点,仅对占绝大多数参数的专家层执行无损FP4量化,其余模块则保留原始精度。这样一来,既缩减了内存占用、缓解了带宽压力,又基本保持了模型的综合能力不变。
第二,DFlash区块并行推测解码。它摒弃了传统的串行解码模式,单次即可预测一整段文本区块。在代码、数理推理等场景下,平均单轮能确认6至7个token,大幅提升了解码效率。
第三,TileRT推理系统。该系统重构了GPU执行架构,采用持久化内核与异构流水线,消除了算子切换带来的延迟,让硬件算力得以持续满负荷运转。
极速推理能力正在重塑AI应用场景。超高速度支持模型并行推演和自主纠错,从而提升逻辑推理质量;它能够大幅缓解代码生成时的等待卡顿,释放编程智能体的生产力;同时,也让万亿参数大模型落地高频量化交易、实时反欺诈、医疗影像分析等毫秒级实时决策场景成为可能。





