计算机视觉顶级会议CVPR 2026刚刚落幕,理想汽车在本届会议上的表现令人瞩目——共有12篇论文被收录,研究方向覆盖世界模型、端到端规划、多模态感知、强化学习、认知模型以及语言与视觉智能等核心技术领域。
需要指出的是,CVPR与ICCV、ECCV并称为计算机视觉三大顶会。一家中国车企能够一次性入选12篇,其含金量远非普通会议论文可比,充分体现了技术积累的深度。
更值得关注的重点并非论文数量本身,而是这些研究共同揭示了一个趋势:理想汽车的智能化战略,正从产品功能层面深度向底层模型、仿真能力、安全验证和推理引擎全面下沉。这背后是持续且高强度的研发投入——截至2026年第一季度,理想汽车已连续5个季度保持约30亿元的研发投入规模,累计接近150亿元。在过去五年中,他们在CVPR、ICCV、ECCV、NeurIPS、SIGGRAPH、IROS、ICRA等顶级会议和期刊上已累计发表近百篇论文。
量变之下,质变已然显现。这12篇论文究竟聚焦哪些核心难题?逐一拆解后,可以清晰提炼出四条关键技术主线。
一、世界模型四项突破:仿真与安全基座升级
在自动驾驶领域,世界模型需要解决的根本问题是:车辆能否在采取行动之前,先理解并推演周围环境的动态变化。
这四篇关于世界模型的论文,分别从深度估计、三维重建、交通规则认知评估、安全风险预判四个维度展开,构建了一条从“还原真实场景”到“理解交通规则”,再到“预判危险后果”的完整技术链路。
道路结构如何变化?其他交通参与者可能如何运动?一条规划轨迹是否存在风险?面对复杂交通规则时如何取舍?对于面向真实道路的自动驾驶系统而言,世界模型不仅是仿真模拟的基石,更是提升安全性、处理长尾场景的关键支撑。
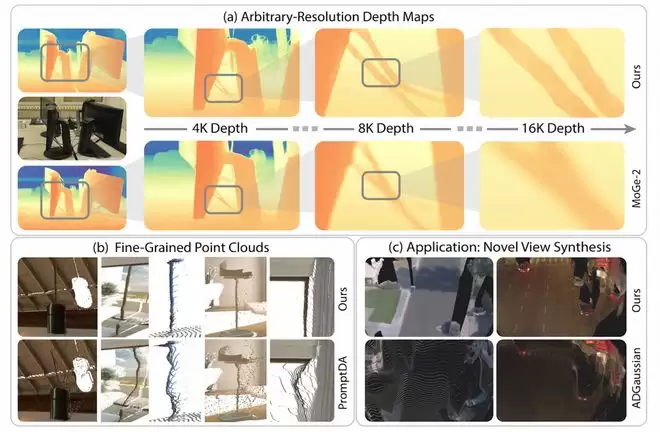
InfiniDepth:将深度估计从“像素级”推向“连续场”
在几何理解层面,InfiniDepth聚焦于最基础也最关键的问题——深度感知。传统方法通常是在固定图像网格上估算深度,结果容易受分辨率限制,细小结构及几何边界常常模糊不清。InfiniDepth创新地将深度表示为连续的神经隐式场,模型能够查询任意二维坐标下的深度值,从而支持更高分辨率、更精细的估计。对自动驾驶场景而言,这意味着可以更准确地还原道路、车辆、障碍物的三维结构,为后续的仿真和环境建模提供更可靠的几何基础。
Unposed-to-3D:从真实驾驶图像中直接“生长”出三维车辆资产
在仿真资产构建方面,Unposed-to-3D解决了一个现实痛点:高质量的三维车辆资产从何而来?现有方法依赖合成数据进行训练,与真实道路图像之间存在域差距,生成的车辆姿态不统一、尺度不准确,难以直接应用于驾驶仿真环境。Unposed-to-3D采用两阶段框架,直接从真实驾驶图像学习三维车辆重建,并引入尺度感知与外观协调模块,使生成车辆在尺寸、姿态和光照上更贴近真实场景。这意味着未来构建大规模、多样化的仿真交通环境时,可以大幅减少人工建模依赖,更高效地从真实世界中获取可用资产。
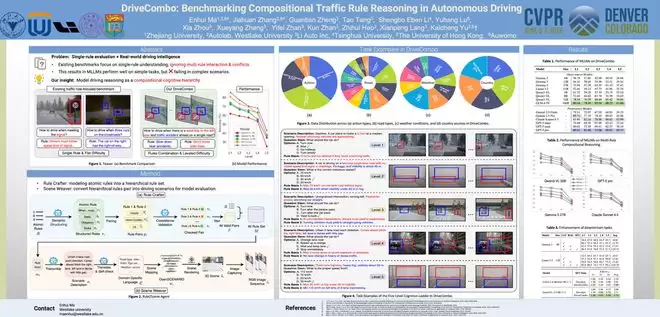
DriveCombo:为多模态大模型设计一套“交通规则考试题”
世界模型不仅要“看得准”“建得真”,还需理解交通世界中的规则。DriveCombo正是面向复杂交通规则推理而提出的评测基准。现有评测通常局限于单一规则场景,如识别交通标志或简单路权判断,但真实驾驶中更常见的是多条规则同时出现甚至相互冲突。DriveCombo构建了文本与视觉结合的组合式推理基准,并提出了五级认知阶梯,从单规则理解逐步提升至多规则整合与冲突消解。通过对14个主流多模态大模型的评估发现,任务越复杂,模型性能下降越明显,尤其是在规则冲突场景中。简言之,这并非一个驾驶模型,而是一套“考题”——用于评估模型能否理解复杂交通规则,尤其在出现多条规则冲突时如何做出正确判断。
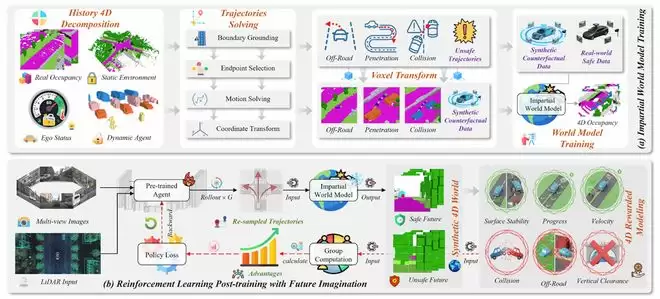
AD-R1:让世界模型学会“预判危险”
安全预判是世界模型走向闭环训练的关键一步。AD-R1聚焦于端到端驾驶强化学习中的一个核心难题:如果世界模型仅在安全专家数据上训练,容易产生“乐观偏差”——面对危险轨迹时仍倾向于预测看似安全的未来,例如忽略碰撞或道路边界风险。AD-R1提出了“公正世界模型”的概念,通过反事实合成生成碰撞、驶离道路等风险场景,使模型学会真实预测危险后果,并将其作为闭环强化学习中的内部评论器,为候选动作提供安全反馈。换句话说,模型不仅要学习“好司机怎么开”,也要理解“错误动作会导致什么后果”。这对于提升系统在长尾风险场景下的可靠性具有直接意义。
这四项研究共同构成了理想汽车在世界模型方向的系统性布局,也为智能驾驶从“看见世界”迈向“理解世界、推演世界并规避风险”提供了更坚实的技术支撑。
二、认知对齐与语言、视觉智能:让模型推理更准更快
世界模型是训练侧的关键,而在推理侧,认知对齐、语言与视觉智能同样不可或缺。要让车辆从“看见道路”进一步走向“理解道路”,模型需要的不仅仅是识别能力,还包括连续认知、语言理解、动作生成以及高效部署能力。
针对上述问题,理想汽车拿出了5篇研究:CogDriver提升驾驶决策的时序稳定性,LinkVLA打通语言理解与动作生成,FastMMoE降低多模态大模型推理成本,CoV-Align提升视觉与语言的细粒度对齐效率,Switch-KD则让大模型能力更容易迁移到轻量模型。这些研究共同构成了理想在认知模型、语言智能和视觉智能方向的技术积累。
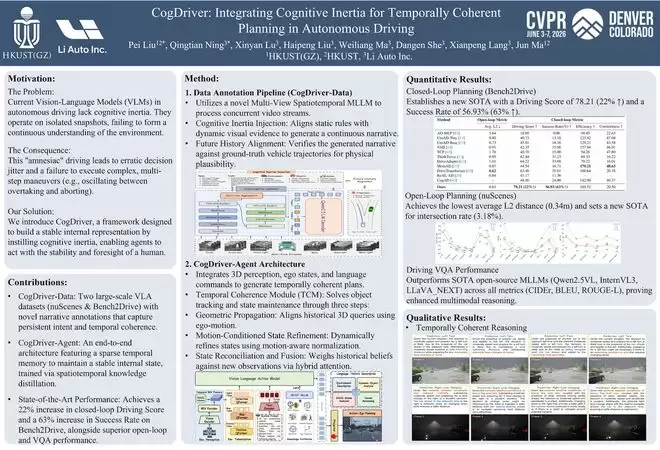
CogDriver:为驾驶模型加入“记忆”和“惯性”
CogDriver关注当前视觉语言模型在时序理解上的短板。许多模型处理驾驶场景时,更像是逐帧“看图说话”,缺乏对历史状态和持续意图的记忆,容易导致决策抖动。CogDriver引入“认知惯性”机制,通过大规模视觉-语言-动作数据集提供时序监督,并在智能体中融入稀疏时序记忆模块,使模型形成更稳定的内部状态。实验结果表明,CogDriver在Bench2Drive闭环驾驶得分上提升22%,在nuScenes上将平均轨迹误差降低21%。
LinkVLA:将语言和动作统一到同一套“密码本”中
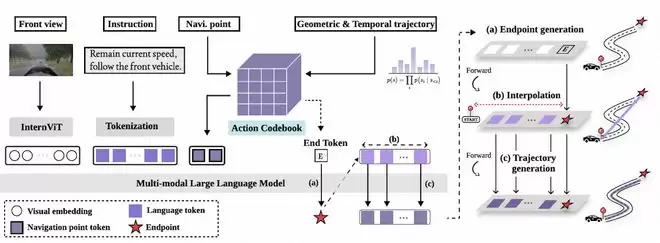
CogDriver解决的是“连续理解”问题,而LinkVLA则更进一步,面向“理解之后如何行动”。视觉语言动作模型被认为是端到端驾驶的重要方向,但现有方法常存在语言指令与动作输出对齐不佳、逐步生成动作序列导致推理效率低的问题。LinkVLA将语言和动作统一到共享离散码本中,从结构上强化跨模态一致性;同时引入动作理解辅助任务,使模型既能从语言到动作,也能从轨迹反推语义描述。它还采用由粗到细的两步生成方式替代传统逐步解码,在提升指令遵循和驾驶表现的同时,节省了86%的推理时间。系统延迟更低,也更加智能。
FastMMoE:让多模态大模型“减负”跑得更快
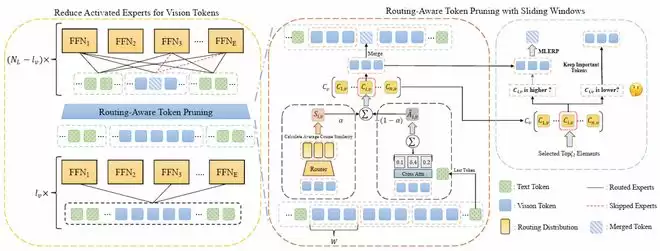
模型变得更聪明后,另一个现实问题是能否跑得更快、更轻。FastMMoE面向基于MoE架构的多模态大模型,提出免训练加速框架,从路由行为入手:一方面减少视觉Token不必要的专家激活,另一方面根据路由概率分布识别并裁剪冗余视觉Token。相比单纯从注意力权重判断哪些Token可以删除,FastMMoE更贴合MoE模型自身的计算机制。实验显示,在DeepSeek-VL2、InternVL3.5等模型上,FastMMoE最高可减少55%的FLOPs,同时保留约95.5%的原始性能。这对于车端、座舱等对延迟和算力敏感的场景非常有价值。
CoV-Align:让模型真正“看懂”图像和文字的对齐
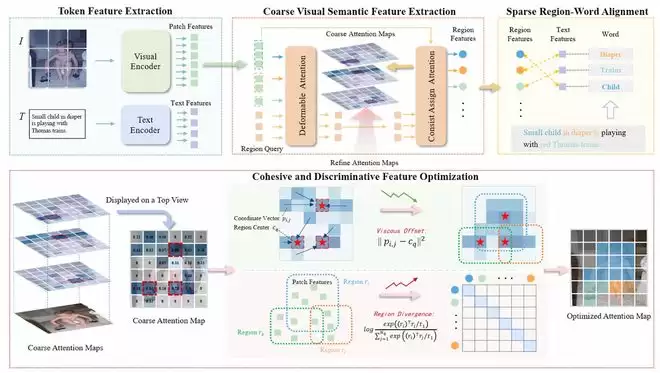
在多模态理解中,语言与视觉之间能否精准对齐,决定了模型是否真的“看懂了”。CoV-Align聚焦于图像区域与文字描述之间的细粒度对齐。传统方法往往依赖文本引导去聚合图像区域,容易产生冗余的patch-word匹配,计算成本也较高。CoV-Align提出“内聚视觉语义优先”的思路:先在不依赖文本的情况下,将语义一致的视觉区域聚合起来,再进行跨模态对齐。这样既减少了噪声,也提升了效率。在Flickr30K和MS-COCO等图文评测基准上,CoV-Align达到领先表现,并带来3至5倍的计算加速。
Switch-KD:将大模型能力“浓缩”进小模型
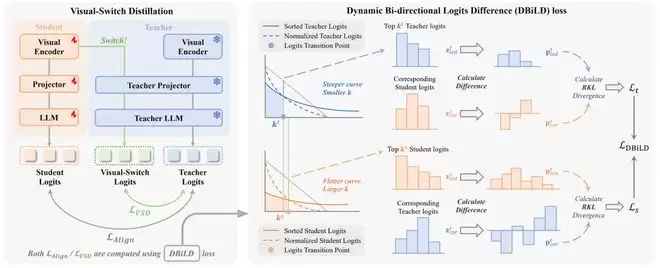
视觉语言模型能力强大,但参数规模大、部署成本高。传统知识蒸馏常将视觉和语言分开监督,容易造成跨模态知识传递不充分。Switch-KD提出视觉切换蒸馏框架,将视觉-语言知识统一到共享的文本概率空间中,让小模型更有效地学习大模型的多模态理解能力。论文显示,0.5B的TinyLLaVA在3B教师模型指导下,在10个多模态基准上平均提升3.6分,且无需改变模型结构。对于需要在有限算力下运行的车端边缘计算和智能座舱场景,这种轻量化能力同样至关重要。
三、端到端规划升级:从“看懂场景”到“形成目标”
相比将感知、预测、规划拆分为多个独立模块,端到端方法希望模型能直接从传感器输入中理解道路环境,并生成可执行的驾驶轨迹。然而,现实驾驶场景并非简单的图像识别问题:车辆需要理解三维空间关系、交通参与者行为、道路结构变化,以及自身下一步应达到的短期目标。
理想汽车提出的SGDrive,正是围绕这一问题展开。
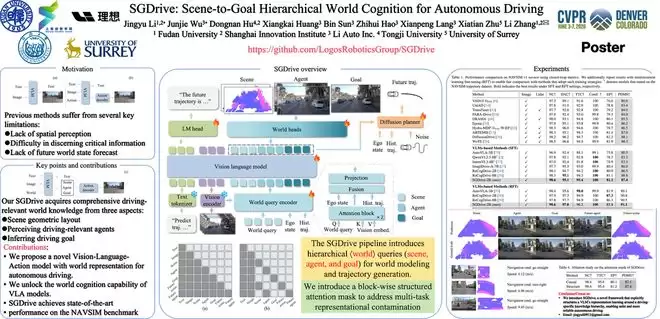
SGDrive将驾驶理解拆分为更接近人类驾驶认知的层级结构:先理解整体场景,再关注关键交通参与者及其行为,最后形成短期目标并执行动作——即Scene-Agent-Goal(场景—交通参与者—目标)的层级认知框架。它并非简单地让模型“看图后直接输出轨迹”,而是补上了驾驶任务所需的中间认知过程。
人类驾驶员在复杂路口或拥堵道路中,不会仅凭单帧画面做判断,而是先把握道路整体格局,再判断哪些车辆、行人或障碍物会影响自身行驶,最后形成一个可执行的短期目标。SGDrive将这种过程结构化地注入模型,使通用视觉语言模型能够围绕驾驶知识进行表示学习,更好地服务于轨迹规划。在NA VSIM基准上,SGDrive取得了纯视觉方法中的领先表现。
四、多模态感知与强化学习:提升环境预判与规划优化
端到端规划中,模型需要从复杂道路环境中形成合理驾驶目标。而要让目标真正可靠,前提是系统既能提前预判环境变化,也能在试错和反馈中优化规划策略。
SparseWorld-TC和PlannerRFT分别从多模态感知和强化学习两个方向切入。前者关注车辆如何更准确地理解未来场景,后者关注规划器如何在闭环训练中生成更优轨迹。
SparseWorld-TC:提前“看见”未来几秒的三维场景
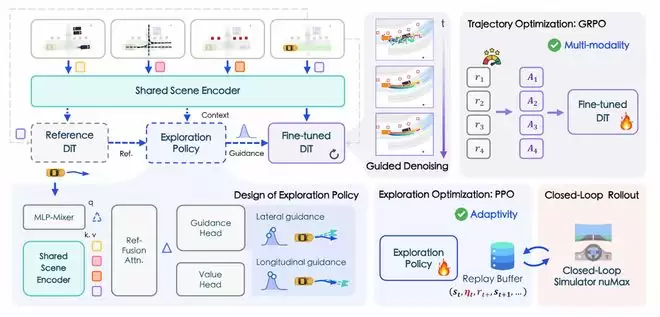
SparseWorld-TC解决的是未来三维场景预测问题。对车辆而言,仅仅识别当前时刻的道路、车辆和障碍物还不够,更关键的是判断接下来几秒钟内环境会如何演化。传统方法依赖鸟瞰图投影或离散化占据token,虽然便于建模,但也带来了信息压缩和表达能力限制。SparseWorld-TC采用稀疏占据表示,直接从原始图像特征出发,端到端预测未来多帧三维场景的占据情况,绕开了BEV投影和离散token表示的双重瓶颈。真实道路上的风险往往不是静态出现的,而是在车辆、行人、道路结构和自身轨迹共同变化中逐步形成的。SparseWorld-TC通过轨迹条件化的方式,让车辆提前预测未来几秒周围三维空间的变化,为后续规划提供更可靠的环境预判。

PlannerRFT:在仿真反馈中“学会”生成更优轨迹
如果说SparseWorld-TC让系统更好地“预判世界”,PlannerRFT则关注如何让规划器在反馈中变得更强。扩散模型被用于生成更接近人类驾驶习惯的轨迹,但在强化微调过程中,如何生成多样化、场景自适应的轨迹,仍然是一个难点。PlannerRFT提出了面向扩散规划器的样本高效强化微调框架,通过双分支优化同时调整轨迹分布,并自适应引导去噪过程,在不改变原始推理流程的前提下,使规划器更有效地探索高价值轨迹。更重要的是,PlannerRFT同步开发了nuMax仿真器,用于支撑大规模并行学习。论文显示,nuMax的轨迹推演速度相比原生nuPlan提升10倍,为强化学习训练提供了更高效的闭环环境。
结语:全方位布局自动驾驶
从这12篇论文中可以清晰地看到,理想汽车的技术布局并非停留在单点能力突破,而是在围绕智能驾驶构建一整套更完整的能力链条:世界模型负责还原、推演与评估真实道路环境;认知对齐与语言、视觉智能提升理解和推理效率;端到端规划让模型形成驾驶目标;多模态感知与强化学习进一步强化环境预判和闭环优化能力。
这些研究共同指向同一个方向:让车辆不仅能看见世界,更能理解世界、推演未来,并在复杂场景中做出更可靠的行动选择。