花分类这个任务,可以说是很多同学踏入图像识别领域的第一个实战项目。经典归经典,但想把效果跑好,不少细节还是得留个心。这里就拿 AlexNet 和它最经典的花卉数据集来说道说道,希望对实践中的你有帮助。
使用的数据集
花分类数据集:
百度云链接下载: https://pan.baidu.com/s/1QLCTA4sXnQAw_yvxPj9szg
提取码:58p0
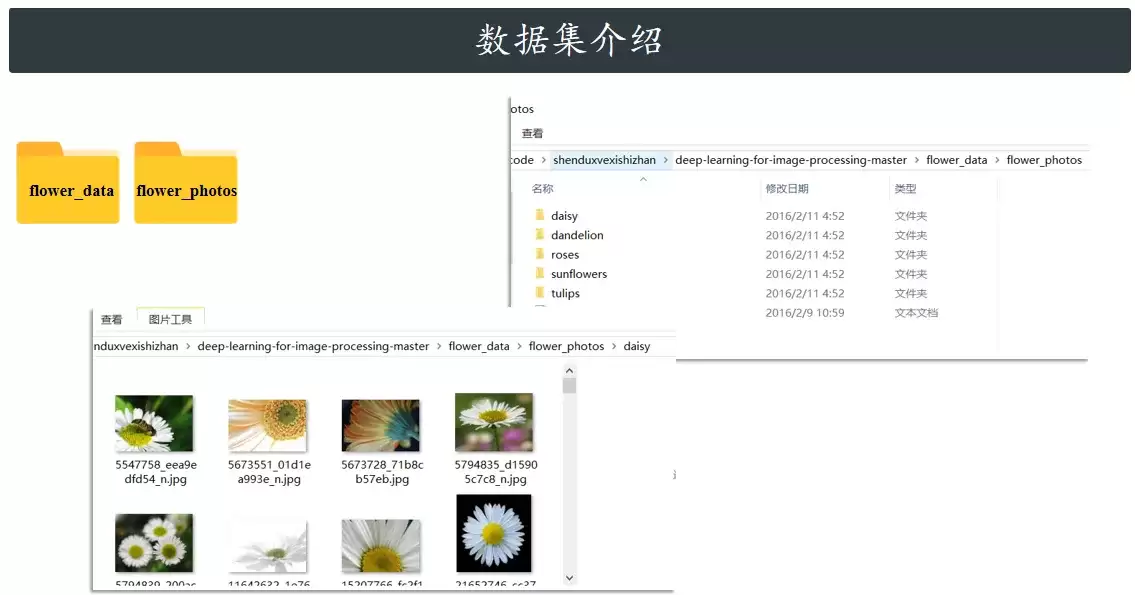
下载好之后,解压到flower_data文件夹下。来看看原始数据长什么样:
分类类别:共包含 5 类花卉,对应 5 个文件夹: daisy(雏菊) dandelion(蒲公英) roses(玫瑰) sunflowers(向日葵) tulips(郁金香)
跑过一些图像项目(比如YOLO这类)的朋友应该都有印象,数据集的组织方式是有“规矩”的。一般情况都分成两个主要文件夹:一个叫 train,另一个叫 val。每个文件夹下面,再按类别名称创建子文件夹。常见的做法是按照8:2的比例来划分训练集和验证集。这种数据整理的活儿,虽然可以用AI写脚本自动化处理,但千万别偷懒不做检查,确保每个文件夹里的东西都没放错位置。

举个例子,训练集的路径可能是:D:vscodeshenduxvexishizhanCNNflower_datatrain,验证集的路径则是:D:vscodeshenduxvexishizhanCNNflower_data val。
AlexNet
AlexNet 创新点
别看现在各种网络结构层出不穷,当年 AlexNet 的横空出世,可是在深度学习史上画下了浓墨重彩的一笔。它的创新点,总结下来有这么几个里程碑式的突破:
(1) 它首次成功搭建并训练了一个8层的深度网络(5个卷积层 + 3个全连接层),这在当时比之前的网络深了不少,让大家看到了“深”的潜力。
(2) 它对激活函数进行了革命性的替换,在深层网络中大规模地、成功地使用了 ReLU 函数。相比传统的 Sigmoid 或 Tanh 函数,ReLU 在缓解梯度消失问题上效果显著。
(3) 它还引入了一系列现在看起来稀松平常,但当时非常前卫的技术:利用 GPU 加速训练、采用 Dropout 正则化防止过拟合、通过数据增强 (Data Augmentation) 来扩充样本、使用局部响应归一化(LRN)和重叠池化(Overlapping Pooling)来提升模型的泛化能力。
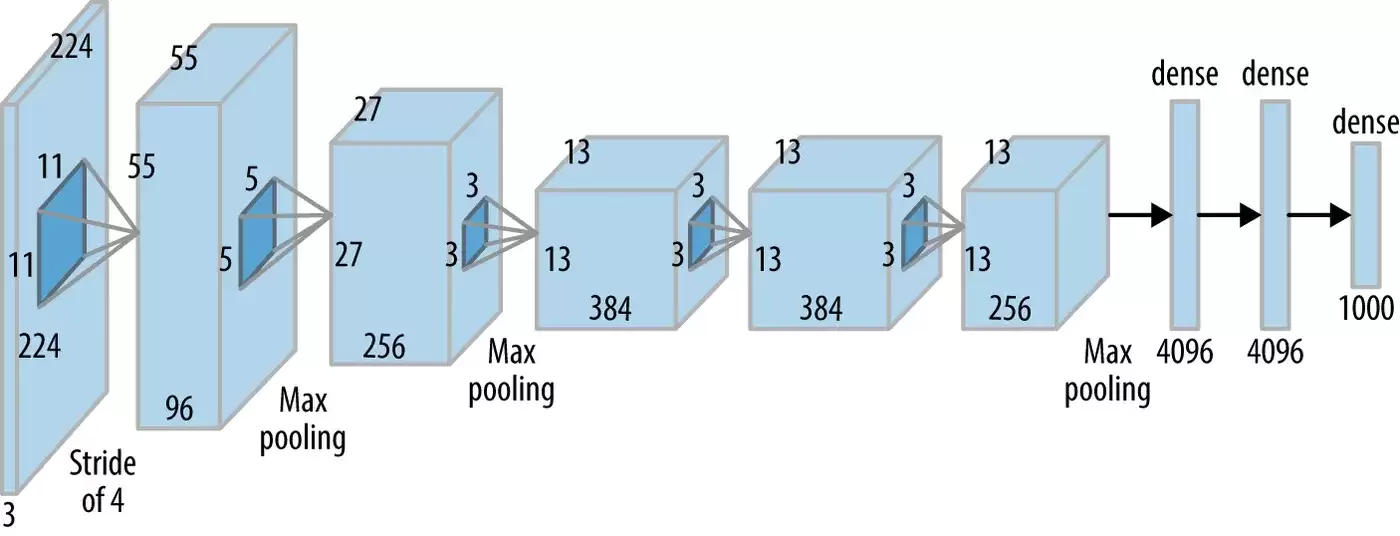
网络结构
光说理论可能有点虚,直接上结构图最实在。这张表把 AlexNet 的核心脉络梳理得清清楚楚:
| 层类型 | 具体参数 | 输入尺寸 | 输出尺寸 | 作用 |
| 卷积层 1 | Conv2d (3→48, 11×11, 步长 4, 填充 2) | [3,224,224] | [48,55,55] | 提取基础纹理特征 |
| 池化层 1 | MaxPool2d (3×3, 步长 2) | [48,55,55] | [48,27,27] | 降维 + 增强鲁棒性 |
| 卷积层 2 | Conv2d (48→128, 5×5, 填充 2) | [48,27,27] | [128,27,27] | 提取更复杂特征 |
| 池化层 2 | MaxPool2d (3×3, 步长 2) | [128,27,27] | [128,13,13] | 继续降维 |
| 卷积层 3 | Conv2d (128→192, 3×3, 填充 1) | [128,13,13] | [192,13,13] | 特征细化 |
| 卷积层 4 | Conv2d (192→192, 3×3, 填充 1) | [192,13,13] | [192,13,13] | 特征细化 |
| 卷积层 5 | Conv2d (192→128, 3×3, 填充 1) | [192,13,13] | [128,13,13] | 特征压缩 |
| 池化层 3 | MaxPool2d (3×3, 步长 2) | [128,13,13] | [128,6,6] | 最终降维 |
| 全连接层 1 | Linear(128×6×6 → 2048) | 4608 | 2048 | 特征映射到高维空间 |
| 全连接层 2 | Linear(2048 → 2048) | 2048 | 2048 | 特征变换 |
| 全连接层 3 | Linear(2048 → num_classes) | 2048 | num_classes | 最终分类 |
model.py
理论落地,终究是要看代码的。下面这段就是 AlexNet 的核心模型定义,结构清晰,注释也很完整:
import torch.nn as nn
import torch
class AlexNet(nn.Module):
def __init__(self, num_classes=1000, init_weights=False):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2), # input[3, 224, 224] output[48, 55, 55]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[48, 27, 27]
nn.Conv2d(48, 128, kernel_size=5, padding=2), # output[128, 27, 27]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 13, 13]
nn.Conv2d(128, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 128, kernel_size=3, padding=1), # output[128, 13, 13]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 6, 6]
)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(128 * 6 * 6, 2048),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(2048, 2048),
nn.ReLU(inplace=True),
nn.Linear(2048, num_classes),
)
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
# 测试模型前向传播
if __name__ == "__main__":
# 创建模型实例
model = AlexNet(num_classes=1000, init_weights=True)
# 生成随机输入(batch_size=4, 3通道, 224×224)
input_tensor = torch.randn(4, 3, 224, 224)
# 前向传播
output = model(input_tensor)
# 打印输出形状
print(f"输入形状: {input_tensor.shape}")
print(f"输出形状: {output.shape}") # 应输出 [4, 1000]
# 打印模型参数量
total_params = sum(p.numel() for p in model.parameters())
trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"总参数量: {total_params/1e6:.2f}M")
print(f"可训练参数量: {trainable_params/1e6:.2f}M")
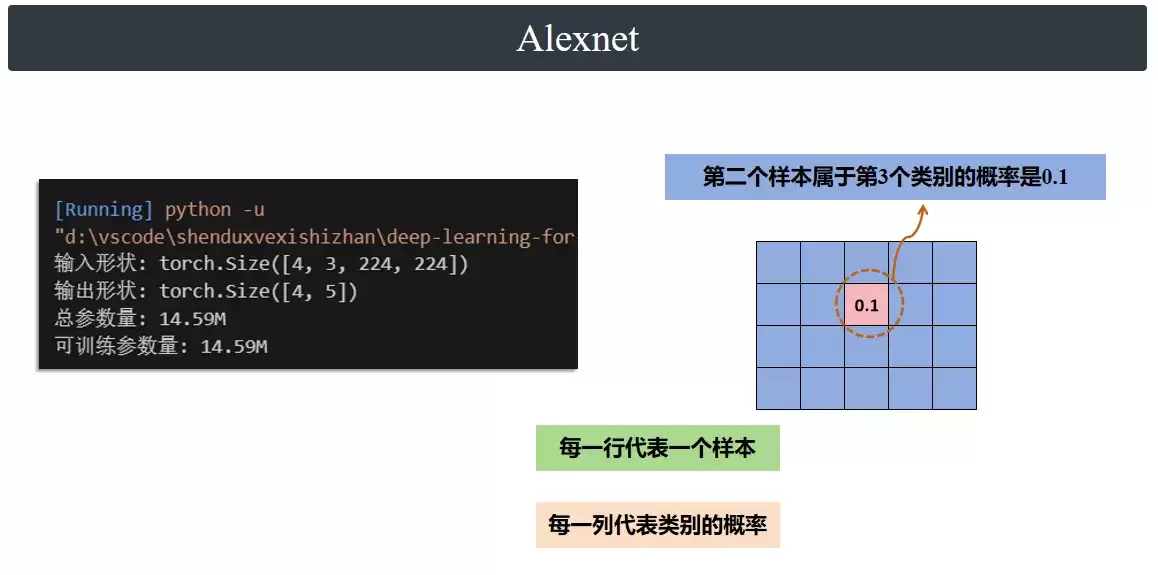
对于这个模型,输入是 [B, 3, 224, 224],代表 B 张图片;输出是 [B, 5],代表 B 个样本中每个类别的预测概率。在实际项目中,这部分既是基础,也是核心。说它基础,是因为所有神经网络的本质都是为了提取特征,很多时候我们其实不需要过深追究每一个数学推导,只要清楚网络输入和输出是什么、能干什么事就行。但最核心的是,特征提取这部分的质量好坏,会直接决定了整个训练效果的天花板。
图解处理和图像增强
数据处理这部分有一个很重要的原则:在验证的时候是不需要做数据增强的,只需要保证尺寸统一和归一化即可。具体到代码中,数据预处理通常会像下面这样分别定义:
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)), # cannot 224, must (224, 224)
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
train.py
训练脚本是整个流程的发动机。下面是完整的训练代码,从数据加载、模型初始化到训练循环都有清晰的实现逻辑:
import os
import sys
import json
import torch
import torch.nn as nn
from torchvision import transforms, datasets, utils
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
from tqdm import tqdm
from model import AlexNet
def main():
device = torch.device("cuda:0" if torch.cuda.is_a vailable() else "cpu")
print("using {} device.".format(device))
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)), # cannot 224, must (224, 224)
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
data_root = os.path.abspath(os.path.join(os.getcwd(), "../..")) # get data root path
image_path = os.path.join(data_root, "data_set", "flower_data") # flower data set path
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),
transform=data_transform["train"])
train_num = len(train_dataset)
# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
# write dict into json file
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
batch_size = 32
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=nw)
validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),
transform=data_transform["val"])
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=4, shuffle=False,
num_workers=nw)
print("using {} images for training, {} images for validation.".format(train_num,
val_num))
# test_data_iter = iter(validate_loader)
# test_image, test_label = test_data_iter.next()
#
# def imshow(img):
# img = img / 2 + 0.5 # unnormalize
# npimg = img.numpy()
# plt.imshow(np.transpose(npimg, (1, 2, 0)))
# plt.show()
#
# print(' '.join('%5s' % cla_dict[test_label[j].item()] for j in range(4)))
# imshow(utils.make_grid(test_image))
net = AlexNet(num_classes=5, init_weights=True)
net.to(device)
loss_function = nn.CrossEntropyLoss()
# pata = list(net.parameters())
optimizer = optim.Adam(net.parameters(), lr=0.0002)
epochs = 10
sa ve_path = './AlexNet.pth'
best_acc = 0.0
train_steps = len(train_loader)
for epoch in range(epochs):
# train
net.train()
running_loss = 0.0
train_bar = tqdm(train_loader, file=sys.stdout)
for step, data in enumerate(train_bar):
images, labels = data
optimizer.zero_grad()
outputs = net(images.to(device))
loss = loss_function(outputs, labels.to(device))
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,
epochs,
loss)
# validate
net.eval()
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
val_bar = tqdm(validate_loader, file=sys.stdout)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_accurate = acc / val_num
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, val_accurate))
if val_accurate > best_acc:
best_acc = val_accurate
torch.sa ve(net.state_dict(), sa ve_path)
print('Finished Training')
if __name__ == '__main__':
main()
训练结果
训练50代之后,效果还是比较可观的。从结果来看,验证集的准确度大致可以稳定在0.8左右,对于从零开始训练来说,这个成绩已经足够说明问题了。

预训练模型完成训练
如果从零开始训练效果已经不错,那用预训练模型来做迁移学习,效果往往会更上一层楼。具体操作起来,其实就是三个核心步骤:
加载预训练权重:直接导入在 ImageNet 上训练好的 AlexNet 权重,相当于模型已经具备了丰富的视觉经验。
修改分类器:因为我们的任务是 5 类花卉分类,需要把 AlexNet 原本的 1000 类输出层给替换掉,改成匹配我们的 num_classes=5。
设置学习率/冻结层:通常对预训练模型使用更小的学习率进行微调,或者干脆冻结特征提取层(features)的参数,只训练分类器(classifier)的参数。这么做的好处是很明显的——能极大提升训练速度,同时模型收敛得也更好。
import os
import sys
import json
import torch
import torch.nn as nn
from torchvision import transforms, datasets, models # 导入 models
import torch.optim as optim
from tqdm import tqdm
from model import AlexNet # 假设这是你自定义的 AlexNet 类
def main():
device = torch.device("cuda:0" if torch.cuda.is_a vailable() else "cpu")
print("using {} device.".format(device))
# ... (数据加载和处理部分保持不变) ...
# ------------------ 【修改开始】模型加载与设置 ------------------
# 1. 实例化 AlexNet 模型
# 如果使用你自定义的 AlexNet 类,这里加载预训练权重(需要文件支持)
net = AlexNet(num_classes=1000, init_weights=False) # 实例化1000类模型
# 假设你的预训练权重是 'alexnet_imagenet.pth'
# weights_path = "./alexnet_imagenet.pth"
# assert os.path.exists(weights_path), f"Pretrained weights file: '{weights_path}' not found."
# net.load_state_dict(torch.load(weights_path), strict=False) # strict=False 如果你的类和权重不完全匹配
# 或者:使用官方预训练模型(更简单)
net = models.alexnet(weights=models.AlexNet_Weights.IMAGENET1K_V1)
# 2. 替换分类器 (迁移学习的关键)
in_features = net.classifier[6].in_features # 官方 AlexNet 的最后一个 Linear 层是第 6 个模块 (索引从 0 开始)
# 替换为 5 个类别的输出
net.classifier[6] = nn.Linear(in_features, 5)
net.to(device)
loss_function = nn.CrossEntropyLoss()
# 3. 设置微调学习率(通常更小)
# 只训练分类器参数,使用更高的学习率:
# optimizer = optim.Adam(net.classifier.parameters(), lr=0.001)
# 或者,微调所有参数,使用更小的学习率:
optimizer = optim.Adam(net.parameters(), lr=0.00005) # 降低学习率进行微调
# ------------------ 【修改结束】模型加载与设置 ------------------
epochs = 50
sa ve_path = './AlexNet.pth'
best_acc = 0.0
train_steps = len(train_loader)
for epoch in range(epochs):
# train
net.train()
running_loss = 0.0
train_bar = tqdm(train_loader, file=sys.stdout)
for step, data in enumerate(train_bar):
images, labels = data
optimizer.zero_grad()
outputs = net(images.to(device))
loss = loss_function(outputs, labels.to(device))
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,
epochs,
loss)
# validate
net.eval()
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
val_bar = tqdm(validate_loader, file=sys.stdout)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_accurate = acc / val_num
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, val_accurate))
if val_accurate > best_acc:
best_acc = val_accurate
torch.sa ve(net.state_dict(), sa ve_path)
print('Finished Training')
if __name__ == '__main__':
main()

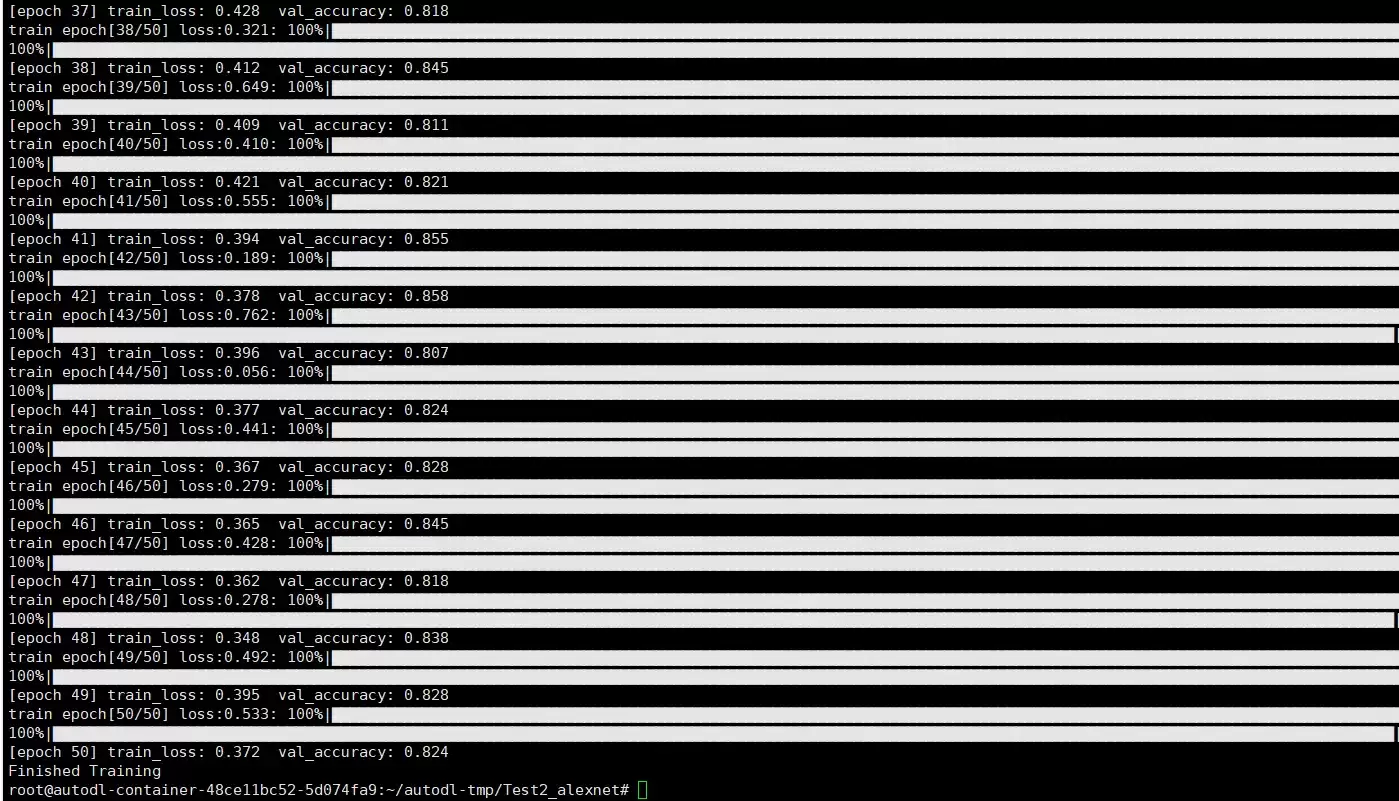
训练效果
如果亲自跑一下代码就能直观感受到,使用预训练模型的方式,训练速度更快,而且效果往往更稳定。