做机器学习,十有八九会碰到这么个情况:手头的数据,有的变量动辄几百上千(比如房价),有的却小得可怜(比如犯罪率)。这种“量纲不统一”的问题,直接扔给算法去跑,结果基本是乱成一锅粥。那怎么办?标准操作就是先做一步“数据缩放”——也叫Feature Scaling。这里面最常用的两招,就是标准化和归一化。
咱们就拿学生成绩来说吧。假设有学生考了三门课,满分分别是150分、100分和30分。这三个分数如果不处理,直接拿来分析,满分30分的科目天然就会被“淹没”掉。那怎么解决?关键在于把不同尺度的数据拉到同一个“台面”上比较。
数据的标准化(Standardization)
标准化走的是“统计路线”。它不去管数据原来的范围,而是用均值和方差来做文章。核心逻辑是:把原始数据变成均值为0、标准差为1的正态分布。不管你原来数值多大,一标准化之后,分布形态不变,但数值的“尺度”就统一了。公式如下:
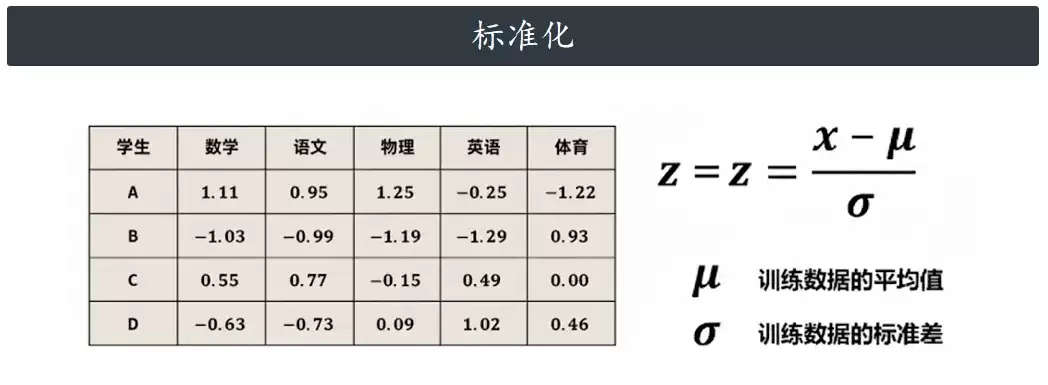
简单来说,就是拿每个数减去平均值,再除以标准差。这样一来,你就不需要再去纠结“这个变量是100分还是30分”——标准化之后,大家度量衡一致了。
归一化(规范化)(Normalization)
归一化和标准化虽然听着像,但走的路径完全不同。归一化走的是“极值路线”。它用的是最小值和最大值。其计算公式很简单:等于原始数据减去最小值,再除以最大值减去最小值。计算结果会把所有数据强行压缩到[0, 1]或者某些情况下是[-1, 1]之间。
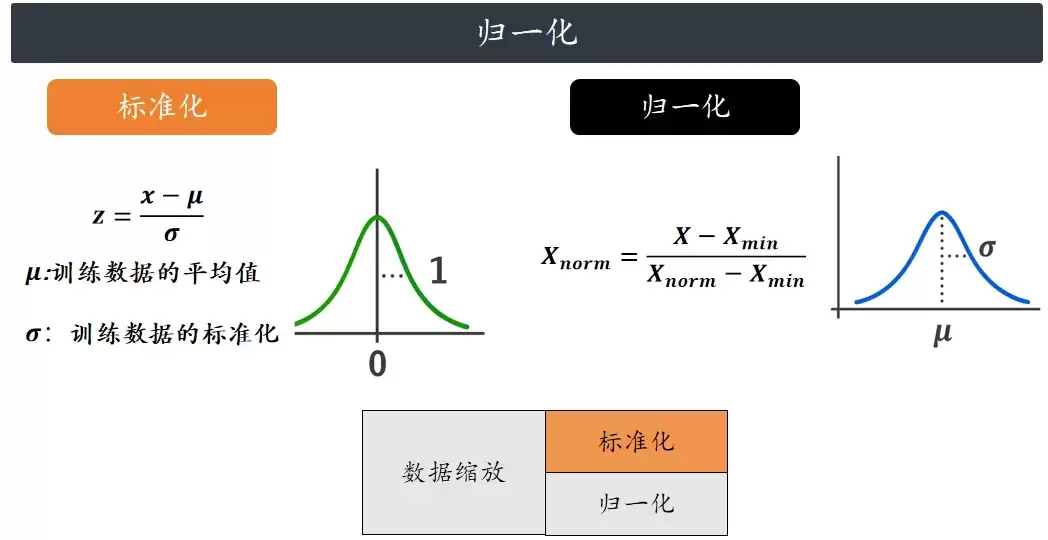
归一化不像标准化那样固定了均值和标准差,它只是单纯地“按比例缩放”。但这里有个大坑:它对异常值极其敏感。举个例子,如果数据里大部分都是1到10的数值,但某个点突然蹦出来个1000,归一化之后,其他所有值都会被瞬间压缩到0.01以内,这种结果基本等于白做了。
所以需要好好区别一下这两个东西:
| 特性 | 归一化 (Normalization) | 标准化 (Standardization) |
|---|---|---|
| 计算过程 | 使用最小值和最大值来缩放 | 使用平均值和标准差来缩放 |
| 数据分布 | 不改变原始数据的分布;平均值、标准差不固定 | 将数据分布在:平均值为 0,标准差为 1 |
| 结果范围 | 数据介于 [0, 1] 和 [-1, 1] 之间 | 数据不受特定范围的限制,但大致在 [-3, 3] 之间 |
| 其他名字 | 也称为最小最大缩放,Min-Max Scaling | 这个过程称为 Z-分数标准化,Zero-Score |
| 异常值影响 | 对异常值非常敏感 | 相对不敏感 |
实际应用中的“潜规则”
这里必须强调一个在实际业务中常被新手踩的坑。在做模型之前,我们通常会把数据集分成训练集和测试集。那么问题来了:你是先标准化再拆分,还是先拆分再标准化?
行业里的标准做法是:先拆分(分出训练集和测试集),仅对训练数据集进行“拟合”(也就是算出均值和标准差,或者最小最大值),然后用训练集这些算好的参数去缩放测试集。原因很简单:测试集是用来模拟“未来未知数据”的,在模型训练阶段,测试集不能向训练集“泄露”任何信息。如果直接用全数据去缩放,那叫“数据泄露”,模型测试结果会虚高,没有实际参考意义。
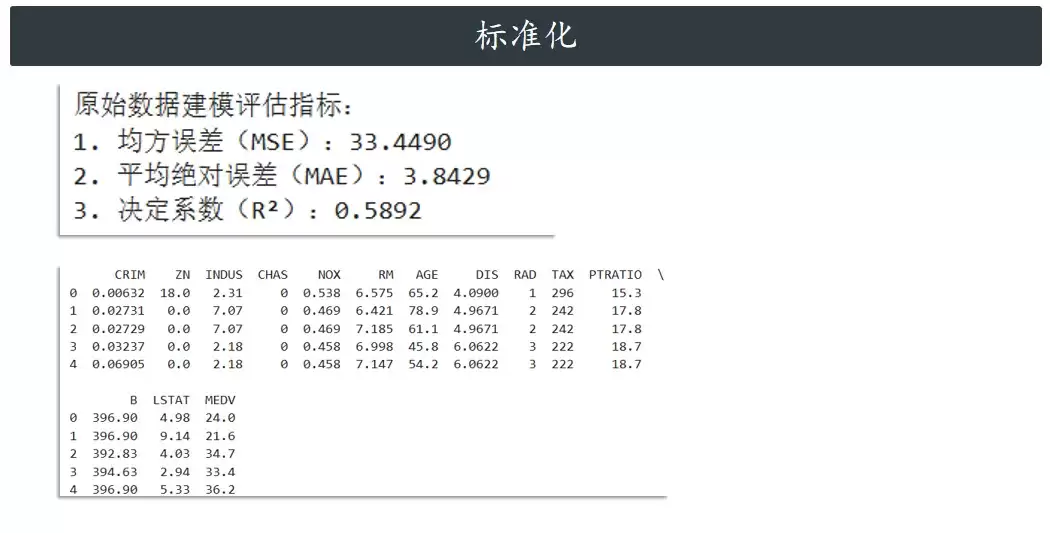
下面用波士顿房价数据集做个演示,直观看看效果。这个数据集很有名,虽然只有506个样本,但包含了14个完整的属性,用来演示标准流程刚刚好。
| 缩写代码 | 原始描述 | 中文简要描述 |
|---|---|---|
| CRIM | 城镇人均犯罪率 | 城镇人均犯罪率 |
| ZN | 占地面积超过25,000平方英尺的住宅用地比例。 | 住宅用地所占比例 |
| INDUS | 每个城镇非零售业务的比例。 | 城镇中非商业用地占比 |
| CHAS | Charles River虚拟变量 | 靠近河道为 1,否则 0 |
| NOX | 一氧化氮浓度 | 环保指标 |
| RM | 每间住宅的平均房间数 | 房间数 |
| AGE | 1940年以前建造的自住单位比例 | 房龄比例 |
| DIS | 波士顿的五个就业中心加权距离 | 就业距离 |
| RAD | 径向高速公路的可达性指数 | 交通便利指数 |
| TAX | 每10,000美元的全额物业税率 | 税率 |
| PTRATIO | 城镇的学生与教师比例 | 师生比 |
| B | 1000(Bk - 0.63)^2 | 黑人比例相关指标 |
| LSTAT | 人口状况下降 % | 低收入阶层比例 |
| MEDV | 自有住房中位数报价(单位:千美元) | 目标变量(房价) |
先用原始数据跑一遍线性回归,看看效果:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
# 1. 加载数据
Boston = pd.read_csv('house_data.csv')
X = Boston.drop('MEDV', axis=1)
y = Boston['MEDV']
# 2. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=0
)
# 3. 原始数据训练模型
model = LinearRegression()
model.fit(X_train, y_train)
# 4. 预测并计算指标
y_pred = model.predict(X_test)
# 5. 输出3个核心指标
mse = mean_squared_error(y_test, y_pred)
mae = mean_absolute_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print("原始数据建模评估指标:")
print(f"1. 均方误差(MSE):{mse:.4f}")
print(f"2. 平均绝对误差(MAE):{mae:.4f}")
print(f"3. 决定系数(R²):{r2:.4f}")
再用标准化数据跑一遍:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
# 1. 加载数据
Boston = pd.read_csv('house_data.csv')
X = Boston.drop('MEDV', axis=1)
y = Boston['MEDV']
# 2. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=0
)
# 3. 数据标准化
scaler = StandardScaler()
X_train_std = scaler.fit_transform(X_train)
X_test_std = scaler.transform(X_test)
# 查看标准化后的数据特点
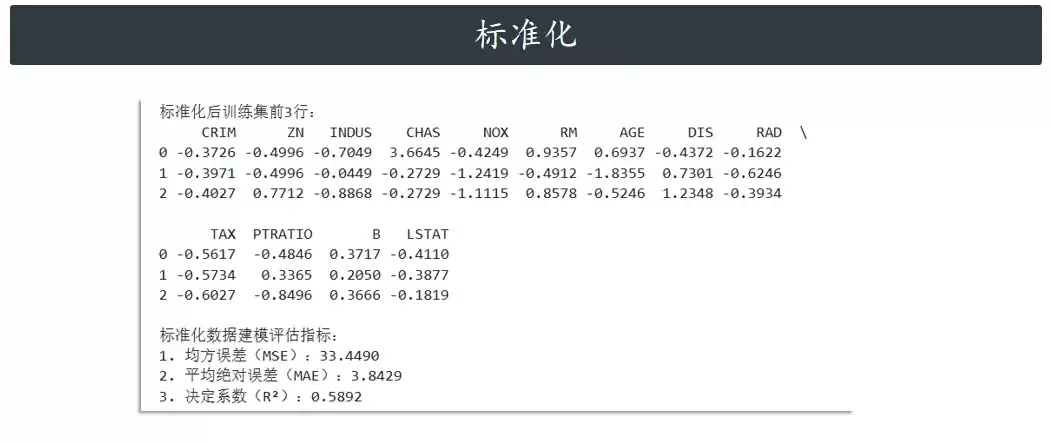
print("标准化后训练集前3行:")
print(pd.DataFrame(X_train_std, columns=X.columns).head(3).round(4))
# 4. 用标准化数据训练模型
model_std = LinearRegression()
model_std.fit(X_train_std, y_train)
# 5. 预测并计算指标
y_pred_std = model_std.predict(X_test_std)
# 6. 输出指标
mse_std = mean_squared_error(y_test, y_pred_std)
mae_std = mean_absolute_error(y_test, y_pred_std)
r2_std = r2_score(y_test, y_pred_std)
print("n标准化数据建模评估指标:")
print(f"1. 均方误差(MSE):{mse_std:.4f}")
print(f"2. 平均绝对误差(MAE):{mae_std:.4f}")
print(f"3. 决定系数(R²):{r2_std:.4f}")
最后用归一化数据跑一遍:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
# 1. 加载数据
Boston = pd.read_csv('house_data.csv')
X = Boston.drop('MEDV', axis=1)
y = Boston['MEDV']
# 2. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=0
)
# 3. 数据归一化
scaler = MinMaxScaler()
X_train_norm = scaler.fit_transform(X_train)
X_test_norm = scaler.transform(X_test)
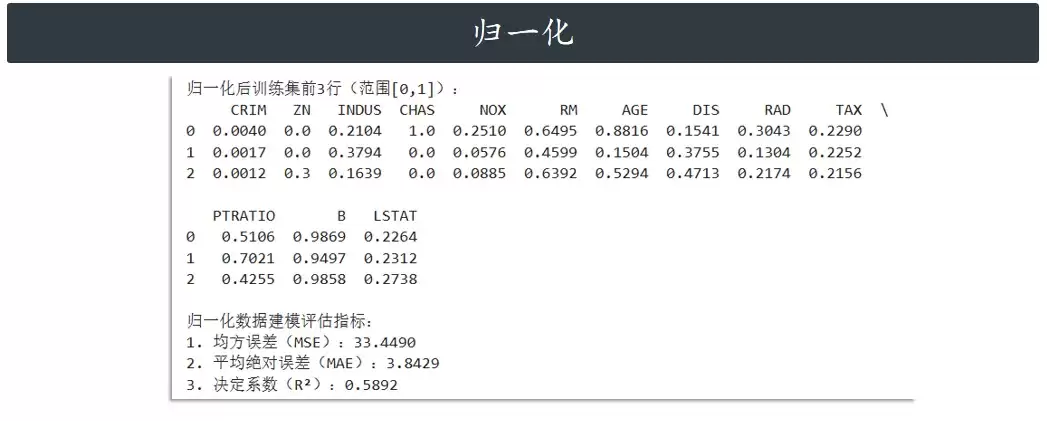
print("归一化后训练集前3行(范围[0,1]):")
print(pd.DataFrame(X_train_norm, columns=X.columns).head(3).round(4))
# 4. 用归一化数据训练模型
model_norm = LinearRegression()
model_norm.fit(X_train_norm, y_train)
# 5. 预测并计算指标
y_pred_norm = model_norm.predict(X_test_norm)
# 6. 输出指标
mse_norm = mean_squared_error(y_test, y_pred_norm)
mae_norm = mean_absolute_error(y_test, y_pred_norm)
r2_norm = r2_score(y_test, y_pred_norm)
print("n归一化数据建模评估指标:")
print(f"1. 均方误差(MSE):{mse_norm:.4f}")
print(f"2. 平均绝对误差(MAE):{mae_norm:.4f}")
print(f"3. 决定系数(R²):{r2_norm:.4f}")
深度学习的“降维打击”:层归一化(LN)和批量归一化(BN)
进入到深度学习领域,数据缩放的玩法又升级了。因为网络一大,层数一深,最常见的三个问题就是:梯度消失、过拟合、训练速度慢。归一化在这里除了解决尺度问题,更核心的任务是稳定每一层的输入分布,从而让梯度传递更顺畅。当然这得选对工具:层归一化(LN)是Transformer家的标配,批量归一化(BN)则是图像领域的常客。
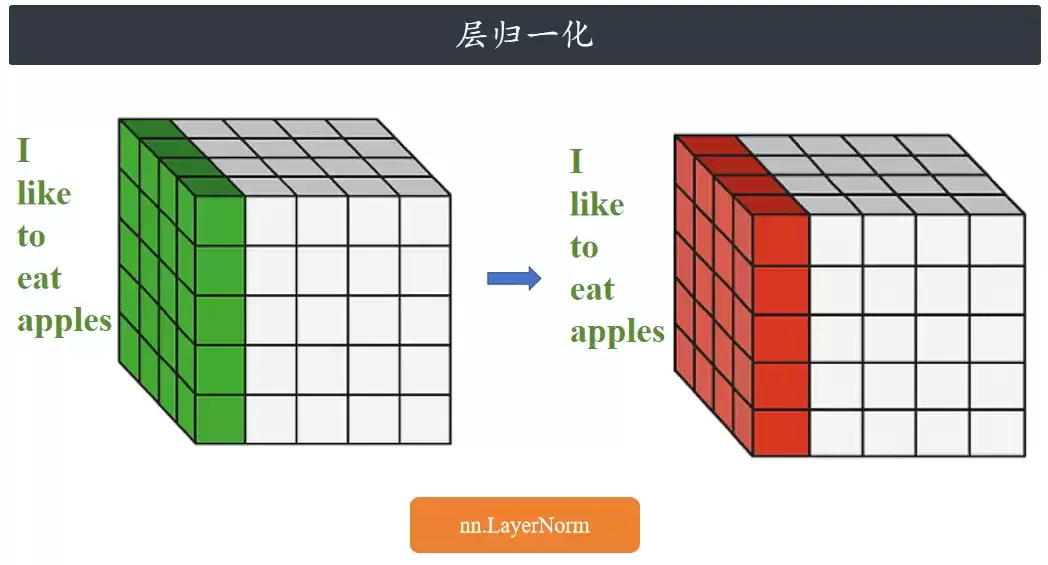
先说层归一化(LN)怎么干活。
假设你正在撸一个处理自然语言的Transformer模型。你准备了4句话,每句话有5个单词,每个单词用一个5维的“词向量”来表示。数据形状就是(批次大小=4,句子长度=5,词向量维度=5)。
层归一化的逻辑很简单:它不关心别的样本长什么样,只管针对当前这句话里每一个单词,单独调整它的5个数字。具体分四步走:
第一步,算均值。比如第一个单词的词向量是[1.2, 0.8, 1.5, 0.9, 1.1],把这五个数加起来得5.5,除以5,算出均值1.1。
第二步,算方差(波动大小)。拿每个数减去均值,得到差值,再平方,最后求和除以5,算出方差0.06。方差越大说明这几个数字之间差别越大。
第三步,做归一化。拿每个原始值减去均值,再除以方差的平方根(再加一个极小数值防止除零报错)。这样处理后,每个词向量的数值都会变成围绕0波动的正态分布。
第四步,学习式“微调”。模型为了保留自己独特的特征,会塞进来两个可学习参数:γ(初始值1,负责缩放)和β(初始值0,负责整体偏移)。最后输出是(归一化后的值×γ)+ β。这样一来,既做了标准化,又保留了每句话的“个性”。
理解“层”这个字是关键:在这里,它指的不是数据里的一整句话,而是模型里的功能模块(比如注意力层、前馈计算层)。层归一化是插在这些模块之间的“稳定器”——让每一层接收到的输入分布都规规矩矩,梯度消失、训练慢的问题自然就缓解了。

代码也极度简单:
import torch import torch.nn as nn ln = nn.LayerNorm(normalized_shape=5) # 参数是最后一个维度大小 x = torch.randn(5, 5, 5) # 模拟输入 output = ln(x)

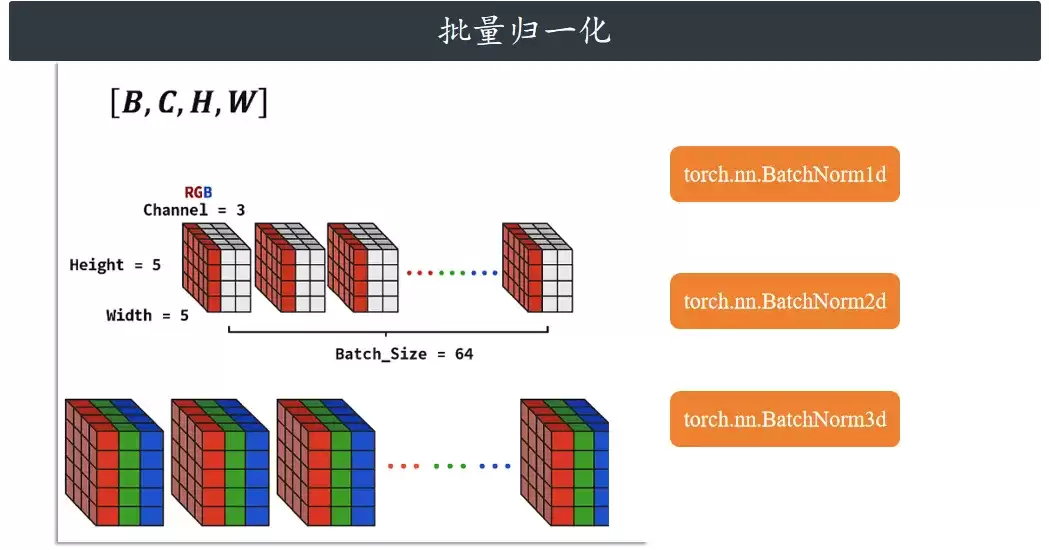
再来看批量归一化(BN)。
批次归一化和层归一化的公式几乎是同一个,但“算的方向”完全不同。层归一化是“对着一个样本的一个特征维度去算”,而批量归一化是跨样本、对着同一个通道去算。
举个例子:现在模型吃的是图片。假设批次大小是64,每张图是RGB三通道,分辨率是5×5。此时数据形状是(64, 3, 5, 5)。
批量归一化的操作逻辑是:只抓取所有64张图里红色通道的像素(64×5×5=1600个像素),计算这1600个点的均值和方差,然后对这1600个点做归一化。绿色通道和蓝色通道也如法炮制,但各自算各自的参数。这决定了BN对批次大小很敏感——如果batch size很小(比如只有2),统计出来的均值和方差就会有较大偏差。

代码也很简洁:
import torch import torch.nn as nn bn = nn.BatchNorm2d(num_features=3) # 参数是通道数 x = torch.randn(64, 3, 5, 5) output = bn(x)

到这里,两个“归一化巨头”的差异就很清晰了:
| 类型 | PyTorch API | 归一化维度 | 适用场景 |
|---|---|---|---|
| 批量归一化 | BatchNorm2d(图像) | 批次内的同一通道(跨样本) | 图像、CNN 网络 |
| 层归一化 | LayerNorm | 单个样本的所有特征(不跨样本) | 文本、Transformer、RNN |