任何 n8n 自动化流程都能快速转化为 Claude Code Skill,实现智能化升级。
听起来像是夸大其词?其实一开始我也持怀疑态度。
直到花费一整天时间,成功将一个复杂的 SEO 关键词研究流程完整迁移后,才深刻领悟:这并非简单的「转换」,而是一次「质的飞跃」——由于 Skill 原生集成了 Agent 能力,你不再需要手动配置大量 API 节点,AI 能够直接理解任务并自主执行。
n8n 与 Skill 在底层逻辑上高度一致——本质上都是对流程化任务的编排与处理。
今天将深入剖析这个 SEO 关键词调研工作流的完整设计思路,帮助你理解为何几乎所有 n8n 工作流理论上都能转化为 Skill,以及如何运用这种思维让工作效率实现倍增。
阅读完本文,你将收获:
- 一套可复用的结构化框架:掌握数据采集 → AI 分析 → 报告生成三阶段设计方法
- 一种系统化思维方式:洞悉 n8n 与 Skill 在底层架构上的统一性
- 一个即拿即用的实战工具:文末附完整提示词,助你从零构建这套系统
1. 关键词调研为何需要自动化?
先来聊聊实际痛点。
如果你也属于那种「明知可以自动化,却依然在手动重复操作」的人——
一定经历过这样的困扰:耗费数小时在多个工具间来回切换,手动复制粘贴关键词数据,再用 Excel 做聚类分析,最后勉强拼凑出一份不够专业的报告。
更令人沮丧的是,每次更换关键词,整个过程就得重新来一遍。
核心症结在哪里?
- 数据分散:关键词信息分布在多个平台,需要人工整合汇总
- 分析效率低:人脑处理海量数据的能力有限,容易遗漏关键规律
- 流程重复:每次调研都是重复劳动,缺乏可复用的机制
- 产出质量波动:结果严重依赖当天的状态和投入时间
关键词调研自动化的四大核心痛点
2. 这套工作流能解决哪些问题?
本 Skill 的设计,通过 6 个关键步骤完成一次完整的关键词深度调研:
Step 1:参数采集 → 询问关键词、目标市场、搜索深度
Step 2:DataForSEO 数据获取 → 6 路 API 并行调用,获取相关词、搜索量、竞争度、SERP 数据
Step 3:竞争者内容抓取 → 抓取排名前 5 页面的结构化数据
Step 4:AI 链式分析 → 4 轮深度分析(竞争者 → 用户意图 → 机会识别 → 内容框架)
Step 5:报告自动生成 → 输出包含 6 个部分的综合报告
Step 6:HTML 可视化展示 → 生成 Bento Grid 风格的数据仪表盘
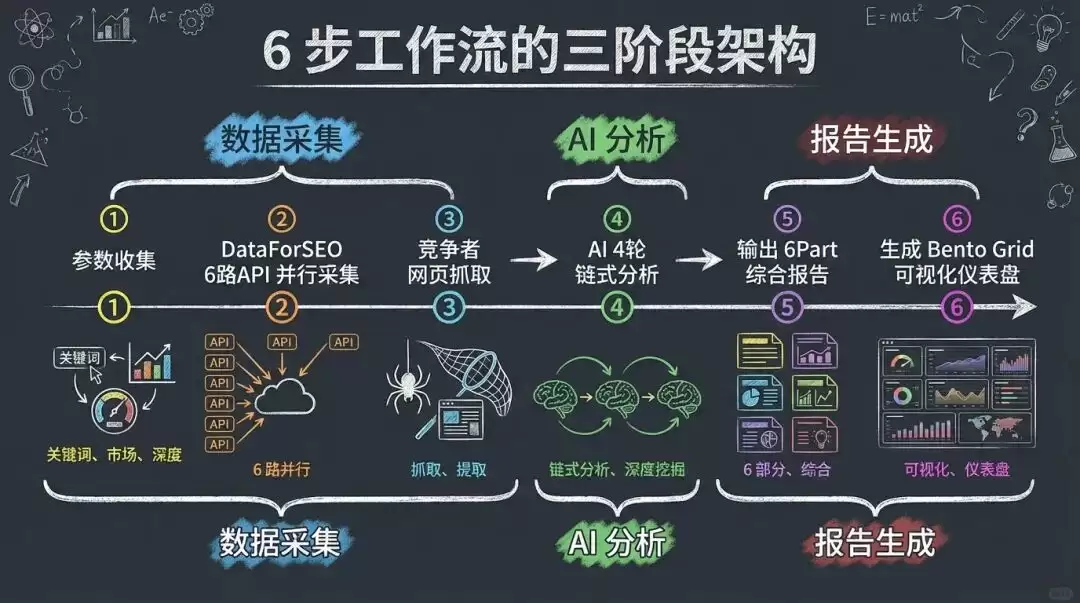
六步工作流的三阶段架构图
3. 阶段一:数据采集——让 API 替你跑腿
该工作流的第一阶段聚焦「数据采集」,涵盖 Step 1 到 Step 3。
Step 1:参数收集
工作流从一个简单问题开始:「你想调研哪个关键词?」
不要小看这个环节。一套完善的参数收集设计,直接决定了后续所有步骤的执行质量。
设计包含 4 轮提问:
- 核心关键词:例如 "bluetooth earphones"
- 目标市场区域:北美 / 欧洲 / 亚太,再细化到具体国家和语言
- 搜索深度:快速(limit=20)/ 标准(limit=50)/ 深度(limit=100)
- 品牌名称(可选):用于过滤官方资产
- runs/{keyword}-{timestamp}/
- state/:progress.json(进度状态记录)
- step01-collect-params/:config.json
- step02-dataforseo-fetch/:API 返回数据
- step03-competitor-scrape/:竞争者内容数据
- step04-ai-analysis/:AI 分析结果
- output/:最终报告文件
Step 2:DataForSEO 六路并行数据采集
这是整套工作流的「数据引擎」核心。
第一次运行这个脚本时,确实被震撼到了。
6 路 API 同时发起请求,短短几秒内就获取了手动需要 2 小时才能整理完成的数据。那一刻真正理解了「用系统打败努力」的含义——不是你不够勤奋,而是你用了错误的方式在勤奋。
一个 Shell 脚本通过 6 路 API 并行请求,在数秒内获取以下数据:
- Related Keywords:与主词语义关联的关键词
- Keyword Suggestions:基于主词的扩展推荐
- Keyword Ideas:AI 生成的关键词创意
- Autocomplete:Google 自动补全的热门搜索
- Subtopics:主题相关的子话题分解
- SERP:当前排名前 10 的搜索结果
DataForSEO 六路 API 并行采集示意图
Step 3:竞争者网页内容抓取
获取 SERP 数据后,我们掌握了排名前 10 的 URL。接下来,需要抓取这些页面的结构化内容。
本步骤借助 Jina AI 的 Reader 服务抓取网页,再通过 Node.js 脚本提取:
- Meta 信息:标题、描述等元数据
- 标题层级结构:H1、H2、H3 的层级关系
- 内容特征:字数统计、N-gram 词频分布
- 结构化元素:列表、表格、图片等页面组件
4. 阶段二:AI 分析——让大模型替你思考
数据采集完成后,进入最关键的「AI 分析」阶段。
这个阶段虽然只有一个步骤(Step 4),但内部包含了 4 个顺序执行的子分析任务:
4.1 竞争者分析
本轮核心问题:竞争对手是如何做的?
输入:竞争者网页的结构化数据
输出:
- 竞争者编码列表:C1(肯德基)、C2(麦当劳)...
- Meta 趋势:标题和描述中的高频词汇、定位策略
- 内容框架模式:重复出现的板块结构
- N-gram 分析:二元、三元词组的语义模式
- 差异化策略:每个竞争者的独特定位
4.2 用户意图分析
本轮核心问题:用户真正想获得什么?
输入:关键词数据 + 配置参数
输出:
- 主要意图:信息获取 / 导航 / 交易 / 商业调研
- 次要意图:相关问题及延伸需求
- 用户画像:搜索者的角色、痛点、背景信息
- 买家旅程阶段:认知 / 考虑 / 决策
- 问题-解决方案框架:如何定位你的内容
4.3 机会识别
输入:前两轮分析结果
输出:
- 内容空白点:竞争者未覆盖但用户需要的话题
- 长尾关键词机会:低竞争高价值的关键词
- 差异化切入点:你能做得更好的方向
4.4 内容大纲生成
输入:所有前置分析数据
输出:
- 推荐标题结构:从 H1 到 H3 的完整大纲
- 每个板块的关键要点:需要覆盖的核心信息
- 内容建议:篇幅、格式、多媒体元素建议
AI 四轮链式分析流程图
5. 阶段三:报告生成——让系统替你交付
最后阶段包含 Step 5 和 Step 6,将分析结果转化为可直接交付的成果。
Step 5:综合报告整合
将 4 份分析文档整合成一份包含 6 个部分的战略报告:
- 执行摘要:关键发现的一页纸总结
- 关键词策略规划:推荐词列表 + 优先级矩阵
- 竞争格局洞察:市场定位地图
- 用户意图深度解读:需求分析
- 内容创作指南:可执行的写作方向
- 数据附录:原始数据表格
Step 6:HTML 可视化展示
将报告转化为 Bento Grid 风格的交互式仪表盘,可直接在浏览器中查看和分享。
6. 实战效果验证
使用这套工作流对 "bluetooth earphones" 关键词进行了调研,整个流程从启动到输出报告,大约只需 5 分钟。
输出内容包括:
- 150 多个相关关键词,按搜索量和竞争度排序
- 5 个竞争者的深度分析,涵盖内容结构、关键词策略
- 用户意图画像,包括买家旅程阶段和预期内容
- 机会矩阵,标注低竞争高价值的切入点
- 内容大纲,可直接用于写作
如果手动完成这些工作,保守估计需要 4 到 6 小时。
效率提升了 50 倍。
但更关键的是:你可以将这套流程复用到任何关键词上,输出质量始终如一。
7. n8n 工作流为何能转化为 Skill?
现在回到最初的问题:为什么 n8n 工作流可以转化为 Skill?
答案隐藏在两者的底层架构中。
之前我也以为 n8n 和 Skill 是完全不同的东西——一个是可视化拖拽工具,一个是文档驱动方式。直到画出两者的结构对比图,才发现一个惊人的事实:
它们是同一种范式的两种不同表达形式。
| n8n | Skill |
|---|---|
| 节点(Node) | 步骤(Step) |
| 连接(Connection) | 数据流(File) |
| JSON Schema | workflow/*.md |
这张表揭示了一个关键真相。如果节点对应步骤,连接对应数据流,那么之前积累的所有 n8n 知识——全都能直接迁移使用。这不是「如何把 n8n 转成 Skill」,而是「它们本质上就是同一回事」。
但 Skill 拥有一个 n8n 不具备的能力:Agent 步骤。
在 n8n 中,如果你想让 AI 分析数据,需要配置 OpenAI 节点、设计 Prompt、处理响应格式。这要求一定的技术背景。
在 Skill 中,你只需在 workflow/step04-ai-analysis.md 里写清楚「你要分析什么」「输出什么格式」,Agent 就能自动完成。
这就像从「手动挡」升级到了「自动挡」。但「自动挡」只是表面变化。更深层的转变在于:你从「写精确指令」变成了「表达意图」。
- 传统编程:你告诉机器「如何做」(How)
- Agent 协作:你告诉 AI「做什么」(What)
这是人机协作范式的根本性转变——从「指令执行」迈向「意图理解」。
这意味着你在 n8n 中积累的所有工作流,都可以升级为带有 AI 加持的 Skill。你不需要重新学习一套全新系统,只需把「节点」翻译成「步骤」,把「连接」翻译成「数据流」。
你过去的积累,不是沉没成本,而是可迁移的宝贵资产。
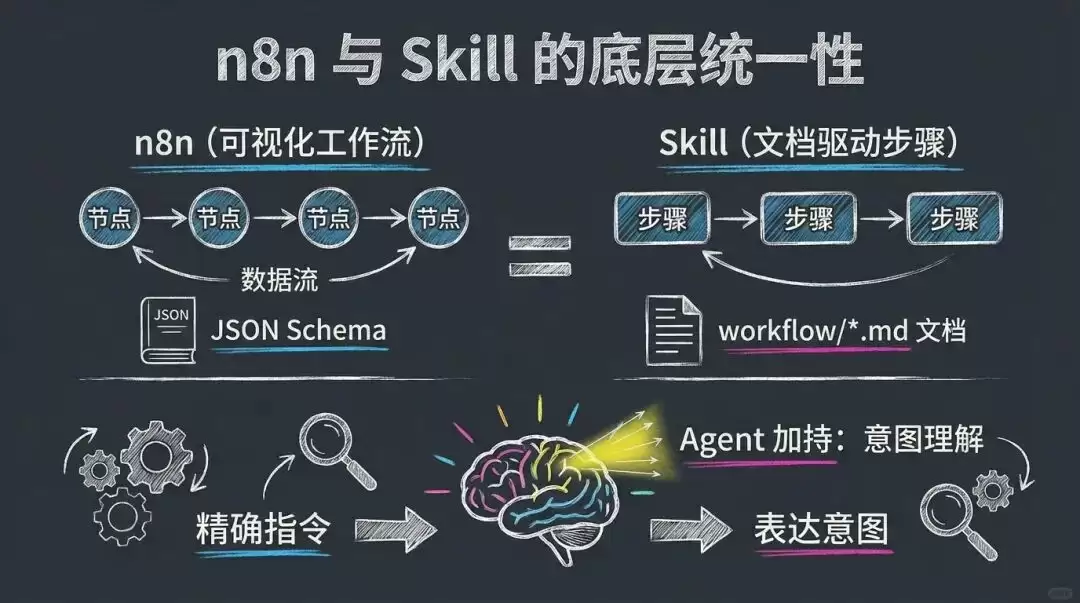
n8n 与 Skill 的底层统一性对比
8. 如何将你的 n8n 工作流转化为 Skill?
如果你有一个 n8n 工作流想要转化为 Skill,可以按照以下框架操作:
第一步:识别节点类型
将 n8n 的节点分为两类:
- 确定性节点:HTTP 请求、文件操作、数据转换 → 转化为 Bash/Node.js 脚本
- 智能节点:内容生成、数据分析、决策判断 → 转化为 Agent 步骤
第二步:设计数据流
明确数据如何从一个步骤流转到下一个步骤:
- 每个步骤的输入文件是什么?
- 每个步骤的输出文件是什么?
- 文件存储在哪个目录下?
第三步:编写 workflow/*.md
为每个步骤创建一份文档,包含:
- 执行者:脚本 / Agent
- 输入文件:依赖哪些文件
- 执行说明:具体完成什么任务
- 输出文件:生成哪些文件
- 验证检查点:如何确认步骤执行成功
第四步:编写 SKILL.md
在主文档中定义:
- 触发条件:用户提到什么关键词时触发
- 工作流概览:步骤列表及依赖关系
- 数据流图:可视化的流程说明
- 参考资料:Prompt 模板、配置文件等
9. 这套方法论可迁移到哪些应用场景?
「数据采集 → AI 分析 → 报告生成」这个三阶段架构,不仅适用于 SEO 调研。
它正是纳瓦尔所说的「代码杠杆」的具体实践——一旦将流程固化为 Skill,它就能无限次执行,边际成本趋近于零。
这不仅仅是工具转化,而是将「个人能力」升级为「可复用的资产」。
- 竞品分析:采集竞品官网、App Store 评价、社交媒体讨论 → AI 分析定位差异和用户痛点 → 生成竞品情报报告
- 市场调研:采集行业报告、新闻资讯、专利数据 → AI 分析市场趋势和机会点 → 生成调研报告
10. 总结与核心要点
今天详细分享了一个 SEO 关键词调研工作流的完整设计原理:
- 架构设计:6 步流程,分为数据采集、AI 分析、报告生成三个阶段
- 核心洞见:n8n 与 Skill 底层架构相通,都是流程化任务编排,但 Skill 原生具备 Agent 能力
- 迁移方法:识别节点类型 → 设计数据流 → 编写 workflow 文档 → 组装 SKILL.md
如果你也认同「效率不是懒,而是把时间留给真正重要的事」——那么 Skill 就是你的下一个利器。
一键复刻:复制这段提示词给 Claude Code,从零开始构建完整系统 :
「你是一位高级系统架构师,专精于 AI 驱动的自动化工作流设计。现在,请帮我从零构建一个 SEO 关键词深度调研 Skill。
系统定位: 这是一个基于 Claude Code Skill 规范的自动化工作流,通过 DataForSEO API 采集关键词数据,结合 AI 链式分析,生成策略规划 + 内容创作指南的综合报告。
核心架构(三阶段六步骤) :
阶段一:数据采集
- Step 01 - 参数收集:通过 AskUserQuestion 询问用户(主关键词、目标市场、搜索深度、品牌名称),生成 config.json,创建运行目录结构
- Step 02 - DataForSEO 采集:Bash 脚本调用 6 路 API 并行采集(Related Keywords、Keyword Suggestions、Keyword Ideas、Autocomplete、Subtopics、SERP),输出 dataforseo.json 和 serp_urls.json
- Step 03 - 竞争者抓取:Bash 脚本调用 Jina AI Reader 抓取 Top 5 竞争者页面,Node.js 脚本提取结构化数据(Meta、标题层级、N-gram),输出 competitors.json
阶段二:AI 分析
4. Step 04 - AI 链式分析:启动 4 个顺序执行的 SubAgent,每轮完成后 /compact 压缩上下文
- 4.1 竞争者分析:分析 Meta 趋势、大纲模式、差异化策略
- 4.2 用户意图分析:识别主次意图、用户画像、买家旅程阶段
- 4.3 机会识别:发现内容缺口、长尾机会、差异化切入点
- 4.4 内容大纲:生成推荐标题结构和内容建议
阶段三:报告生成
5. Step 05 - 综合报告:整合 4 份分析文档,生成 6 Part 报告(执行摘要、关键词策略、竞争格局、用户意图、内容指南、数据附录)
6. Step 06 - HTML 可视化:将报告转化为 Bento Grid 风格的交互式仪表盘
目录结构 :
- SKILL.md :主文档,定义触发条件、工作流概览、数据流图
- workflow/:步骤文档:step01-collect-params.md、step02-dataforseo-fetch.md、step03-competitor-scrape.md、step04-ai-analysis.md、step05-report-generate.md、step06-html-visualize.md
- scripts/:执行脚本:shell/fetch-dataforseo.sh、shell/fetch-jina.sh、node/extract-html.mjs
- reference/:参考资料:prompts/prompt-*.md(6 个 Prompt 模板)、presets/presets.json(市场和语言预设)、specs/(API 规范、HTML 设计规范)、templates/(HTML 模板)
- config/:配置文件:default.json(全局默认参数)
- credentials/:凭证占位:dataforseo.md、jina.md
关键约束 :
- 步骤必须顺序执行,不可跳步
- Agent 步骤每轮完成后必须 /compact
- 数据通过文件系统传递(JSON、Markdown)
- 进度持久化到 progress.json 支持断点恢复
- 确定性任务用脚本,智能任务用 Agent
请按上述规范,生成完整的 SKILL.md 和所有 workflow/*.md 文档,确保每个步骤的输入输出清晰定义,数据流完整可追溯。」




