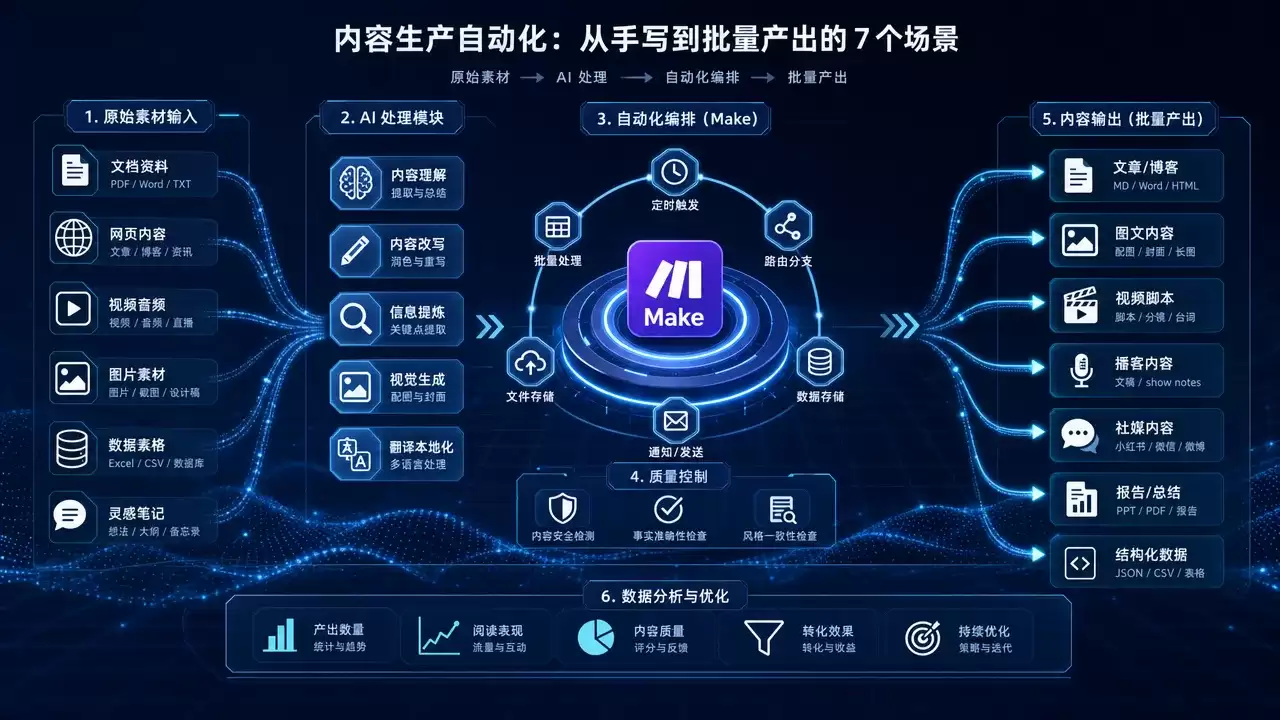
Make(原 Integromat)在低代码自动化领域,就像瑞士军刀——不用写代码,靠拖拽连线,就能把几十个应用串成全自动流水线。过去一年,通过 Make 搭建了 28 套自动化场景,覆盖内容生产、社交运营、数据采集、知识管理、办公效率和工作流方法论六大方向。这篇指南把这 28 个真实场景按类组织,每个场景都有完整教程链接,从零搭建到批量产出,形成一套可复用的自动化体系。
要点速览
- Make 是可视化自动化平台,画布式编排比 Zapier 更适合复杂多步骤工作流
- 28 个实战场景按六大类组织:内容生产、社交运营、数据采集、知识管理、办公效率、方法论
- 每个场景都配有独立深度教程,本文是索引和串联
- 不需要编程基础,但理解 JSON 和 API 概念会让你走得更快
Make 是什么:可视化自动化平台的定位
Make 的核心是一张可视化画布。在画布上放置模块(Module),每个模块对应一个应用或操作——读取 RSS、调用 OpenAI、发送到 Notion、推送到微信。模块之间用连线表达数据流向,数据从左到右流过整条管线,每个模块处理完结果后再传给下一个。
这个定位决定了 Make 的适用边界:单步触发用 Zapier 更省事,多步骤、有分支、需要循环或错误重试的场景,Make 是更好的选择。和 n8n 相比,Make 是全托管服务,不用管服务器;n8n 则提供完全的数据控制权和自托管自由。
Make 免费计划提供每月 1000 次操作,足够跑通本指南中大多数场景的测试。
常见误区
搭建了 28 个场景后,踩过的坑可以归纳成几类:
误区一:自动化等于无人值守。 全自动不代表高质量。任何涉及对外发布的内容管线,都应该保留人工审核节点。Make 支持在管线中间插入暂停模块,等人工确认后再继续执行。
误区二:一个场景解决所有问题。 超过 30 个模块的场景几乎无法维护。按功能边界拆分成多个场景,通过 Webhook 串联,每个场景独立可调试。
误区三:忽略错误处理。 生产环境下 API 超时、格式异常、配额耗尽是常态。每个关键模块都应该配上错误处理路由——失败后是重试、跳过还是告警,需要预先设计。
误区四:不做数据备份。 Make 的数据存储不是数据库,不要把它当唯一数据源。关键数据同步到 Notion 或外部数据库,Make 只做管线中转。
误区五:忽视成本控制。 免费计划 1000 次操作看起来不少,但一个复杂场景跑一次可能消耗 20-50 次操作。上线前用 Run Once 模式估算操作量,避免月底配额用完。
你的 Make 自动化检查清单
⬜ 注册 Make.com 账号并完成新手引导
⬜ 搭建第一个 RSS 到 Notion 的采集管线
⬜ 接入至少一个 AI 模型(OpenAI / DeepSeek / Claude)
⬜ 完成一个内容生产场景的端到端测试
⬜ 设置定时调度,让场景自动运行
⬜ 为关键模块添加错误处理路由
⬜ 搭建第一个跨场景 Webhook 串联
⬜ 建立提示词库并纳入版本管理
⬜ 完成一个社交平台的内容分发自动化
⬜ 估算月度操作量并选择合适的付费计划
⬜ 为所有场景添加执行日志监控
⬜ 将采集、加工、分发三类场景串联成完整管线
Make 不是目的,效率才是。这 28 个场景不需要一次性全搭——挑一个离你日常最近的场景开始,跑通了再扩展。自动化的价值不在于炫技,在于把重复劳动的时间省下来,用在真正需要人判断的事情上。
工具会迭代,场景会变化,但「采集 → 加工 → 分发」的管线思维不会过时。把这个思维模型装进去,不管未来用 Make 还是别的工具,你都能快速搭出自己的自动化体系。




