先分享几个核心判断。大语言模型的能力边界其实远没有人们想象得那么绝对。许多人认为模型越强大效果越好,但实际情况是——将一个模型放入精心构建的“Agentic工作流”中,其综合表现往往比单纯升级到更先进的模型还要出色。

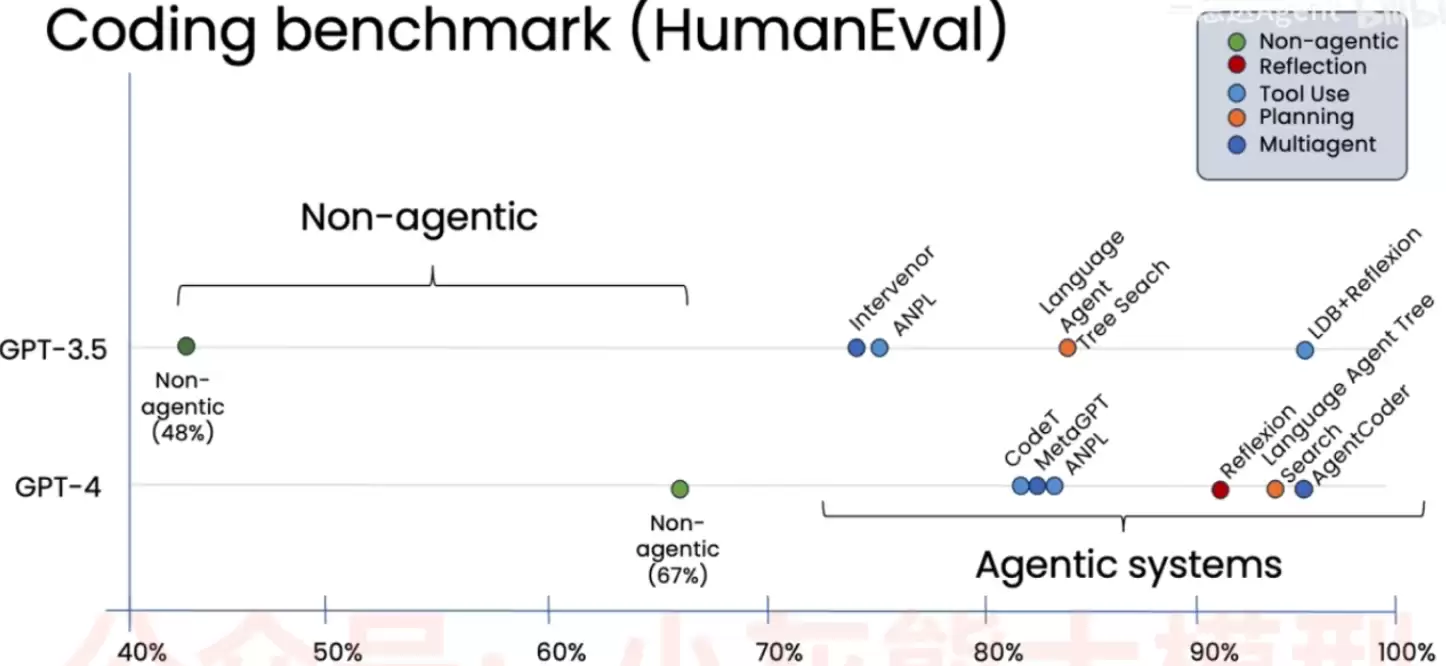
这张图非常直观。左侧绿色数据点展示的是模型在非Agentic模式下的表现:GPT-3.5的代码编写准确率仅为48%,而GPT-4虽然提升明显,也仅达到67%。请留意图表的右侧,标注为“Agentic systems”的区域。无论是GPT-3.5还是GPT-4,一旦引入反思机制、工具调用、任务规划以及多智能体协作等复杂工作流,准确率几乎呈直线飙升,直接跃升至70%到95%以上的范围。
因此结论十分清晰:一个普通模型搭配优秀的Agent系统,完全可能超越一个功能更强的“裸模型”。图中搭载了Agentic工作流的GPT-3.5,其实际表现远远超过了没有辅助机制的GPT-4。这充分说明,在处理复杂编程任务时,出色的系统工程设计与思维框架,往往比单纯依赖底层模型本身的性能更为关键。
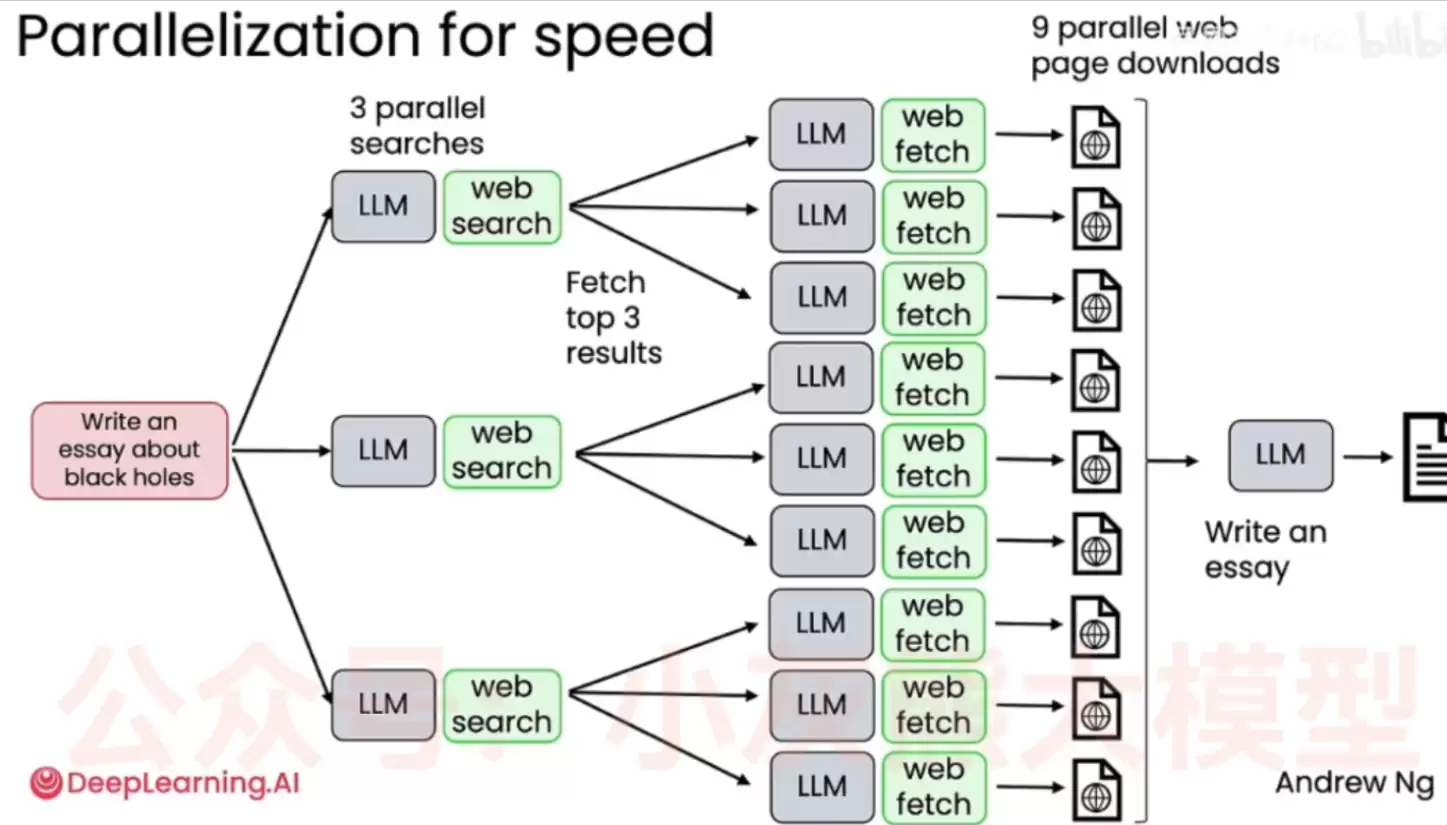
Agentic工作流还有一个极其重要的优势——并行执行能力。以“写一篇关于黑洞的文章”为例,系统接收到提示词后,并不会让模型线性地逐个搜索与处理,而是同时启动三个并行的搜索任务。每个任务完成搜索后,各自提取排名前三的网页链接,从而共生成九个并行节点同时抓取网页内容。这九个节点将信息汇总至最终的大模型节点,由它综合输出完整的文章。其核心思想可以概括为一句话:用计算资源换取时间。如果采用传统线性流程,模型需要“搜索→读取网页1→读取网页2……→读取网页9→撰写文章”,耗时自然可以估算。而引入并行架构后,原本需要几分钟的深度调研与写作,可以在几秒到十几秒内完成。

最后,简单归纳一下Agentic工作流带来的三大核心价值。
性能显著提升:它能让能力相对有限的模型,发挥出甚至超越强大模型的战斗力。
远超人工的处理速度:借助并行化技术,系统可在同一时间分发数十个子任务进行搜索、抓取与网页阅读,这种处理效率是人力无法比拟的。
高度模块化:如同玩积木一样灵活。假如今天出现一个更便宜、更快的新模型,随时可以替换底层模型,无需重写业务逻辑。需要计算就接入计算器工具,需要绘图就挂载绘图API。整个系统架构可以根据需求灵活地添加、删除或升级各类外部工具。




