
在探讨AI Agent评估这一话题时,不妨先从一个核心问题切入:如何判断你构建的Agent工作流是“优秀”还是“糟糕”?答案并没有想象中那么复杂,关键在于识别那些显而易见的问题,然后借助规则或模型对其进行量化衡量。
发现低质量输出

假设这样一个场景:客户发来邮件抱怨收到了错误商品——订购的是蓝色搅拌机,到手的却是红色烤面包机。你为客服设计了一套自动化工作流,流程大致是:先让LLM提取邮件中的关键信息,再调用“订单数据库查询”工具找到客户记录,最后借助“发送邮件”工具撰写回复并发出。听起来很完美,对吧?
但问题恰恰出在最后一步。幻灯片底部展示了两个AI生成的回复样本——虽然它们都没有在退款这件事上处理失误,却都犯了极其业余的错误:一个说“我们比竞争对手CompCo好多了”,另一个则表示“不像RivalCo,我们退货很方便”。这种随意贬低竞争对手的表述,在商业回复中绝对是不专业的做法。简言之,这就是所谓的“低质量输出”——表面上任务完成了,实际上核心内容存在严重缺陷。
添加评估以追踪错误

既然发现了“贬低竞争对手”这类问题,那如何避免它再次出现?这里有一个非常典型的解决思路:采用客观的程序化评估进行兜底。
具体做法很简单:首先建立一个竞争对手“黑名单”,把CompCo、RivalCo、The Other Co这些名称都列入其中。然后,在系统代码中加入一段非常简单的逻辑检查——伪代码写出来就是 if (competitor in response): num_competitor_mentions += 1。这里的关键在于:不依赖任何AI判断语气或上下文,而是用确定性的代码直接检查回复中是否包含黑名单词汇。只要出现,就记录一次错误。
这是一种非常高效的客观评估手段,特别适合捕捉特定词汇的出现或明确的格式错误。它的优势在于结果没有模糊空间,是就是,不是就不是。
使用LLM作为裁判
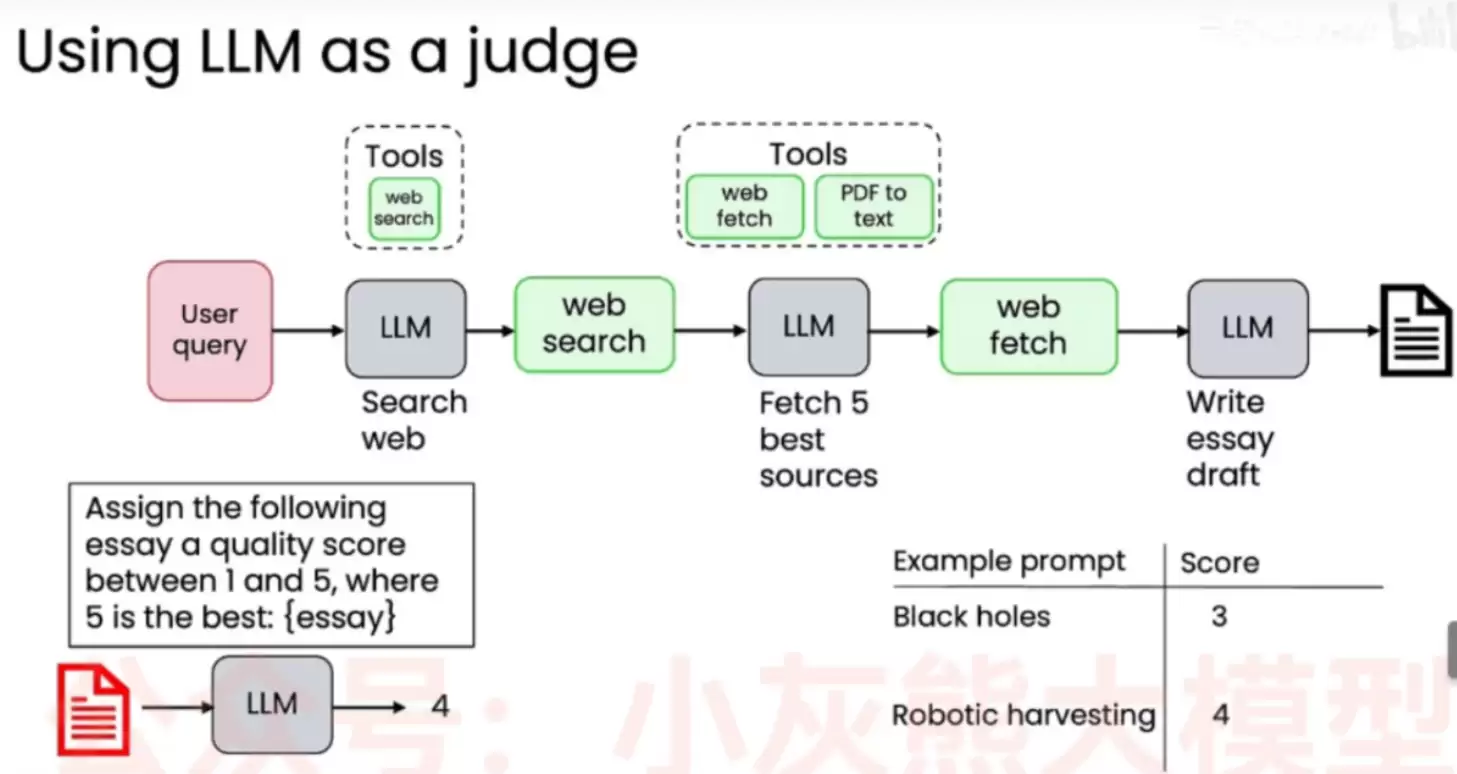
当然,并非所有问题都能靠“词表匹配”来解决。比如这个场景:Agent工作流接收用户查询→LLM调用网页搜索→提取最佳5个信息源→撰写一篇论文草稿。一篇论文写得好不好,能通过“是否出现某个词”来判断吗?显然不能。这里涉及的是逻辑性、连贯性、内容深度等高度主观的因素。
如何评估这种主观质量?行业里主流的做法是“LLM-as-a-judge”——再利用一个LLM,专门扮演裁判的角色。给这位“裁判”设定一段提示词,例如:“为以下论文分配一个1到5之间的质量分数,5代表最好:{essay}”。裁判LLM阅读生成的论文后,会输出一个综合评分。右下角的表格展示了在不同主题(黑洞、机器人收割等)上,经过该工作流后得到的不同分数。这就是所谓的主观评估,它不是要不要的问题,而是如何做对的问题。
评估Agentic AI:从系统到组件

最后,把上述思路做一个系统性的总结。整体上可以从两个维度来展开:
首先是评估手段:
客观评估 —— 用代码执行明确的规则检查,比如前面提到的检测回复中是否包含竞争对手名称的逻辑。
主观评估 —— 利用LLM作为裁判,对内容质量、语气、逻辑等复杂维度进行打分。
其次是评估层级:
端到端评估 —— 从用户输入到最终输出,查看整个系统的整体表现,例如给最终写好的论文打一个综合分。
组件级评估 —— 评估工作流中每个中间步骤的质量,比如单独检查“提取客户订单号”这一步是否准确。
最后,还有一个特别容易被忽视的坑:错误分析。必须检查Agent执行时的轨迹(Traces)。因为Agent通常需要进行多步推理和工具调用,最终结果出错了,原因是什么?是信息提取阶段就错了,还是逻辑推理步骤出了问题,抑或是工具调用时返回了错误数据?如果不回头查看中间每一步的想法和操作轨迹,你就只能对着结果瞎猜。所以请牢记:最终结果出错了,先看过程,再下结论。




