 Ollama v0.30.2 版本更新概览图
Ollama v0.30.2 版本更新概览图
 Ollama 新版本核心功能模块示意
Ollama 新版本核心功能模块示意
 Ollama v0.30.2 技术架构升级要点
Ollama v0.30.2 技术架构升级要点
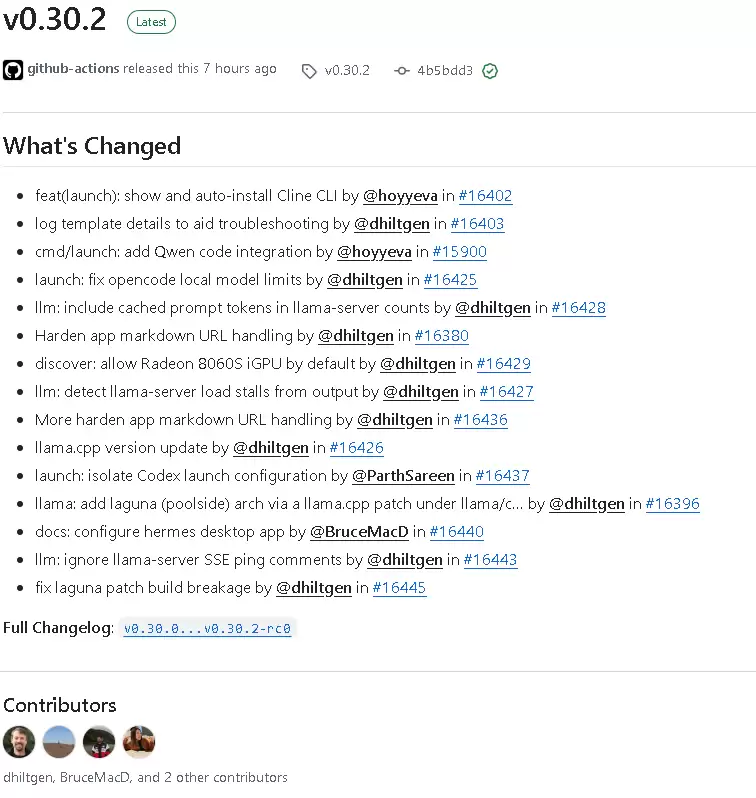
2026年6月3日,Ollama v0.30.2 正式发布。本次迭代涉及15次代码提交与38个文件变更,覆盖安全防护、模型内核升级及第三方生态集成等多个领域。先给出几个关键结论:安全层面修复了多项高危漏洞;模型内核层面已原生支持 Laguna 这类新架构;第三方生态方面实现了 Cline 与 Qwen Code 的一键安装,同时对 Codex 进行了彻底的配置隔离。简而言之,既有面向普通用户的易用性提升,也有面向开发者与运维人员的底层优化,同时还顺手解决了若干历史遗留的线上隐患。
本文将从第三方集成优化、Web 安全加固、llama-server 服务调优、llama.cpp 内核与 Laguna 适配、Codex 全链路配置隔离、硬件兼容与 Opencode 修复、日志与模板解析优化七个维度,基于官方提交的源码,完整解读本次更新的全部细节。
第三方 Launch 集成体系迭代
Ollama 的 ollama launch 生态是连接各类 AI 客户端与代码助手的核心能力。v0.30.2 重点针对 Cline 和 Qwen 两款工具完成了原生集成改造,同时完善了集成注册、自动安装校验逻辑,并重构了命令行启动执行流程。这是本次易用性更新中最值得关注的部分。
Cline CLI:自动检测与静默安装落地
版本在 cmd/launch/cline.go 中完整新增了 Cline 的生命周期管理代码,重构了原有的运行逻辑。简单来说,现在能够实现未安装时的自动检测、依赖校验以及交互式一键安装的全链路闭环。
以往的做法是直接调用系统中的 cline 命令,环境校验几乎为零。新版 Run 函数会优先调用 ensureClineInstalled 方法进行前置环境校验:第一步通过 exec.LookPath 在系统 PATH 中搜索 cline 二进制程序,找到则直接返回路径并启动;如果未找到,则继续检查系统是否安装了 npm——若连 npm 都不存在,直接抛出标准化报错,并附上 Node.js 官网下载地址。npm 环境就绪后,程序会弹出交互式确认提示,用户在确认安装后自动执行 npm install -g cline@latest 全局安装指令,安装完成后还会二次校验 PATH 环境,避免出现 npm 安装成功但系统环境变量未刷新、找不到二进制文件的问题。安装成功后,控制台会输出绿色成功提示。
配套在同目录新增了 cline_test.go 单元测试文件,覆盖环境变量模拟、npm 执行参数校验、安装确认交互、路径识别等全场景用例,确保跨系统环境下安装逻辑的稳定性。同时,在集成注册配置中,将 cline 加入了全局集成列表,并调整了集成可见性配置与自动安装标记,帮助文档的 Supported integrations 清单里也新增了 cline 条目。现在执行 ollama launch 查看帮助时,能够正常看到 cline 选项。
Qwen Code:集成接入与安装提示配置
本次更新在 launch 集成注册表内新增了 Qwen 集成项,补充了 Qwen 专属的安装指引链接配置。在集成单元测试用例中也补充了 qwen 的自动安装标记,将 Qwen 标记为支持一键自动安装的集成程序。后续用户执行 ollama launch qwen 时,会复用 Ollama 统一的第三方工具安装校验框架,配套的命令行帮助文档也追加了 qwen 条目。Qwen Code 与 Ollama Launch 的链路正式打通。
全局集成清单维护与文档同步
修改了 integrations_test.go 集成清单校验用例,在预期集成数组内补充了 cline,同步调整了隐藏集成校验规则。区分了自动安装与手动安装集成:claude、claude-desktop、codex 标记为非自动安装;cline、qwen、hermes、pi、openclaw 归入自动安装白名单。同步更新了 launch.go 的命令行帮助文案,在 Supported integrations 列表里新增了 cline 和 qwen 两行说明,优化了终端指令提示信息。
Web 工具与 Markdown 渲染全链路安全加固
v0.30.2 在应用层安全防护上投入了大量代码。新增了独立 URL 访问管控模块,改造了前端 Markdown 渲染组件,限制了 WebFetch 和 WebSearch 工具对非法 URL 的调用——从 Go 后端和 React 前端双向封堵任意 URL 跳转、恶意图片加载等安全风险。这是本次版本安全层面的核心改动,新增了 url_policy.go 和 url_policy_test.go 两份全新源码文件。
新增独立 URL 访问权限管控引擎
在 app/tools/ 目录下新建了 url_policy.go 及配套测试文件 url_policy_test.go,基于 Context 上下文实现了用户 URL 白名单机制。这套权限逻辑仅在 Windows 和 macOS 系统上生效。
具体来说:在上下文注入方面,通过 WithAllowedDirectURLs 函数接收用户原始提问文本,使用正则 https?://[^s<>"'] 批量提取文本内的全部链接,再经过cleanDirectURL` 清洗首尾标点和空格,存入上下文 map 白名单。Ollama 在会话初始化阶段,通过 userMessageText 遍历全量用户历史消息,拼接所有用户输入文本后注入 URL 白名单上下文,所有工具调用统一复用这个白名单。
URL 校验规则方面,allowedDirectURL 作为统一校验入口,只允许与用户输入原文完全一致、没有任何字符修改的链接——参数但凡被篡改、末尾追加符号、路径微调,全部拦截。清洗规则会剔除链接末尾的逗号、句号、括号、问号等冗余符号,非 http/https 协议的链接直接放行失败。配套测试用例分别校验了三种场景:用户原文链接放行、修改参数链接拦截、反引号包裹的 Markdown 链接正常提取放行,确保白名单提取和校验逻辑没有绕过漏洞。
WebFetch 与 WebSearch 接入 URL 白名单校验
WebFetch 的改造在 web_fetch.go 中实现:工具入参获取目标 URL 后,优先调用 allowedDirectURL 进行权限校验,不在用户白名单内的链接直接返回报错“web fetch is only allowed for URLs provided by the user”。网页抓取完成后,自动将页面内所有外链通过 addAllowedDirectURL 追加至当前会话白名单,后续工具就能正常访问页面内的合法跳转链接了。
WebSearch 的改造在 web_search.go 中完成:搜索接口返回结果后,遍历全部搜索结果 URL 并添加至会话白名单。搜索产出的链接后续可以被浏览器、网页抓取工具正常调用,实现了搜索链路链接白名单的自动扩容。
Browser 浏览器工具链路安全改造
修改了 browser.go 浏览器打开逻辑,页面跳转执行前增加白名单判断,非用户原始输入的 URL 直接抛出“direct URL open is only allowed for URLs provided by the user”异常。配套在 browser_test.go 新增了两条测试用例:一条校验恶意随机域名链接被拦截,一条校验精准匹配用户原文链接正常放行,覆盖了非法直链攻击场景。
前端 StreamingMarkdown 组件渲染安全升级
修改了前端 TSX 源码 StreamingMarkdownContent.tsx,并补充了 StreamingMarkdownContent.test.tsx 测试用例,从渲染层面阻断恶意 HTML 注入和隐蔽图片溯源攻击。具体做了两件事:第一,禁用原始 HTML 解析——剔除了 rehype raw 插件,只保留 katex 公式渲染插件,Markdown 内的 iframe、script 等原生 HTML 标签不再被浏览器解析执行;第二,屏蔽外链图片加载——重写 img 标签渲染组件,所有 Markdown 图片  格式内容只展示 alt 替代文本,丢弃 src 图片地址,杜绝通过像素图片携带隐私数据外传或隐蔽 CSP 穿透攻击。单元测试分别校验了 HTML 标签不被渲染、恶意域名图片链接被截断这两个场景,确保流式 Markdown 渲染全场景安全。
会话上下文自动注入白名单
改造了 app/ui/ui.go 会话接口逻辑,新增 userMessageText 函数遍历单轮会话中所有 user 角色的消息,拼接全部用户输入内容,在聊天接口初始化时自动调用 tools.WithAllowedDirectURLs 将用户消息注入请求上下文。全链路工具自动继承 URL 白名单配置,用户无需额外设置任何开关。
llama-server 深度优化
本版本针对 Ollama 内置的 llama-server 进程进行了运行稳定性改造,覆盖了模型加载卡死识别、SSE 协议冗余注释过滤、缓存 Token 计入 Prompt Token 统计、健康状态多格式解析。修改了 llm/llama_server.go 主体业务代码,并扩充了对应测试用例。
模型加载卡死自动检测与超时动态延期
引入 atomic 原子变量实现加载活动打点,新增 loadActivity 和 loadTracking 两个原子标记。进程启动时执行 startLoadTracking 开启加载监控,llama-server 运行输出日志时,memoryParsingWriter 捕获控制台输出并调用 noteLoadActivity 刷新最后活跃时间戳。lastLoadActivity 对外提供查询接口。
WaitUntilRunning 等待逻辑做了重构:加载超时时间不再从启动时间固定计算,而是每次检测到进程控制台有新输出或健康接口返回 loading 状态时,自动刷新超时截止时间。这样能够避免大模型量化加载耗时过长时被误判为卡死。如果超过连续无日志输出的超时阈值,才判定加载卡死并返回超时错误。配套新增了单元测试,验证了持续日志输出可动态顺延超时、无输出超时正常报错这两种场景。
SSE 流式输出过滤注释行
Completion 和 Chat 两大流式接口解析 SSE 数据时,新增了逻辑:行数据以单个冒号开头则直接跳过解析,忽略 llama-server 原生的 SSE ping 注释报文,避免心跳注释干扰 JSON 数据解析。配套在 SSE 解析测试用例内增加了多组 : 空注释行样例,验证过滤逻辑生效。
Prompt Token 统计纳入缓存 Token
新增了 llamaServerTimings 结构体,拆分出 CacheN(缓存 Token 数)和 PromptN(新输入 Token)两个字段。promptEvalCount 方法会自动求和处理缓存 Token 和新输入 Token;Completion 和 Chat 返回结果时,PromptEvalCount 不再单一读取 prompt_n,改用求和后的数值,精准统计单次请求实际消耗的输入 Token 总量。补充了两条专项单元测试,分别构造了 cache_n=12、prompt_n=5 的返回数据,校验最终统计数值等于 17,修正了历史版本缓存 Token 不计入统计的 BUG。
健康检查接口兼容错误嵌套格式
适配了 llama-server 的两种健康返回格式:传统的 {"status":"loading model"} 平铺格式,以及新标准的 {"error":{"message":"Loading model"}} 嵌套错误体格式。两种格式均被识别为模型加载中状态。同时补充了 no slot a vailable 无空闲插槽状态识别,完善了异常分类。健康解析单元测试也新增了嵌套错误体的测试用例。
llama.cpp 版本升级与 Laguna 全新架构原生适配
版本将内置 llama.cpp 依赖版本从 b9452 升级至 b9479,通过补丁形式在 Ollama 内部兼容 Laguna 专属模型架构,新增了一整套 Laguna 模型加载和计算图构建源码。这是本次底层模型引擎的最大更新。
版本号全局替换
修改了项目版本配置文件 LLAMA_CPP_VERSION,将原有 b9452 修改为 b9479,全项目编译时自动拉取对应 commit 的 llama.cpp 源码,同步适配新版底层算子逻辑。
基于 Patch 补丁的 Laguna 架构兼容
在 llama/compat/ 目录新增了完整的 Laguna 适配体系:
新增 models/laguna.cpp(232 行源码),实现了 llama_model_laguna 结构体,重写了超参加载、张量权重加载、计算图构建三大核心函数。适配了 Laguna 的混合稠密层 + MoE 专家层架构——模型浅层为标准 FFN 稠密前馈网络,深层切换为 MoE 混合架构,同时支持共享专家参数、SWA 滑动窗口注意力、YARN 动态 RoPE 缩放、Q/K 分头归一化、Attention 输出门控等独有算子。
新增 llama-cpp-laguna.patch(100 行补丁文件),通过 git 补丁修改原生 llama-arch、llama-model、vocab 相关源码,在 llama.cpp 内核注册了 LLM_ARCH_LAGUNA 架构枚举、专属张量标识 LLM_TENSOR_ATTN_GATE_LAGUNA、独立分词预处理规则 LLAMA_VOCAB_PRE_TYPE_LAGUNA,注册了 EoS 结束符 ,适配 Poolside Laguna 模型。
改造了 compat.cmake 和 server/CMakeLists.txt 编译脚本:配置了补丁自动编译逻辑,cmake 编译阶段自动检测补丁是否已打入,未应用则自动执行 git apply,补丁冲突会抛出编译提示。将 compat 目录下所有模型源码编译链接至 llama 静态库,保证 Ollama 编译时内置 Laguna 解析能力。
补丁编译异常修复
首次提交 Laguna 补丁后出现了构建断裂,后续提交修复了补丁编译 BUG,完善了 cmake 补丁异常捕获逻辑,规避了 llama.cpp 版本变动导致补丁无法应用的问题。
Codex 集成全链路配置隔离重构
v0.30.2 大规模重构了 cmd/launch/codex.go、codex_app.go 及配套测试代码。核心目标是隔离 Codex CLI 与 Codex 桌面 App 的配置文件、模型目录和配置参数,避免两种启动方式互相篡改 ~/.codex 下的 config.toml 全局配置,拆分出独立的 profile 配置文件。
Codex CLI 配置改造
配置文件方面:不再写入根目录 config.toml,单独生成 ollama-launch.config.toml 专属配置文件,新增 codexNamedProfileConfigPathForConfig 系列路径函数,区分全局配置、CLI 配置、App 配置三个文件路径。
启动参数方面:新增 codexValidateExtraArgs 参数拦截逻辑,用户自定义传入 --profile/-p/--model/-m/-c 等配置参数直接报错。ollama launch 全权接管 profile、模型、服务商配置,避免外部参数覆盖 Ollama 托管配置。
配置清理方面:实现了 Restore 接口,执行还原时自动删除 CLI 专属 profile 配置文件、未被引用的模型 catalog 目录,新增 SkipRestoreInstallCheckSkipper 接口标记,还原清理流程跳过二进制程序存在校验。
最低版本提升:Codex 最低支持版本从 v0.81.0 上调至 v0.134.0,版本校验逻辑同步修改了升级提示文案。
配置生成逻辑重构:拆分 writeCodexConfig 为 writeCodexProfileConfig,配置内容只写入独立 profile 文件,根 config.toml 不再被 Ollama 修改。
Codex App 桌面端配套隔离改造
独立 App 专属配置与模型目录:新增 App 专用 profile 路径、专用 model.json 模型清单文件,App 启动生成自己的配置和 catalog,与 CLI 目录物理隔离。
Catalog 模型去重优化:新增 codexAppCatalogModelKey 函数自动剔除 :latest 标签,生成模型清单时去重同名模型;构建 catalog 时同时携带模型上下文窗口等元数据。
Restore 还原逻辑完善:还原操作自动删除 App 专属 profile 配置、未使用的模型 catalog,增加旧版配置状态升级逻辑,区分根目录被托管/未托管场景,备份逻辑细化到子目录分类。
启动参数扩展:codexAppLaunchOrRestart 新增启动参数入参,支持自定义指令拉起 Codex 客户端。Windows 平台重启逻辑做了优化,区分应用 ID 拉起与程序路径兜底拉起两种方式。
配套单元测试扩容
codex_test.go 和 codex_app_test.go 新增了数十条测试用例,重点验证了:CLI 启动不污染 App 全局配置、App 配置独立存储、多模型生成独立 catalog、参数冲突拦截、Restore 正常清理配置。其中专项用例验证了:先后启动 Codex App 和 Codex CLI 后,.codex 目录生成两份独立 profile、两份独立 model.json,模型清单互不干扰。
硬件适配与 Opencode 本地模型限制问题修复
Radeon 8060S 核显默认加入了硬件白名单:修改了硬件自动发现逻辑,Ollama 启动硬件检索时默认识别并兼容 Radeon 8060S iGPU,用户无需手动配置环境变量即可使用该核显加速模型推理。
Opencode 本地模型数量限制 BUG 修复:修复了 launch 链路中 Opencode 本地模型加载上限异常问题,解除不合理的模型数量约束,本地批量导入 Opencode 系列模型时不再触发超限拦截。
模型模板日志落地、调度与能力解析优化
新增模板选型全维度日志输出
在 server/images.go 重构了模型能力解析逻辑,拆分出 Go 模板、GGUF 原生 Chat 模板、Harmony 模板、Renderer/Parser 自定义渲染器四类来源,新增 logTemplateSelection 日志函数。调度器 server/sched.go 在加载模型完成后自动调用该函数,INFO 级别日志会打印:模型名称、最终选中的模板来源、渲染器配置、解析器配置、四类模板各自支持的能力清单。这对线上问题排查非常有用,可以快速定位模型对话格式错乱、能力识别异常等问题的根源。
模型 Capability 能力解析重构
拆分 capabilitiesForTemplate 入参,通过 templateCapabilitySource 枚举区分不同模板来源,分别计算模型能力,避免不同模板能力互相覆盖。优化了 GGUF 文件打开逻辑,复用已打开的 GGUF 文件句柄,减少重复 IO 读取模型元数据,提升了大目录批量拉取模型时的加载性能。细化了预优先选用 GGUF Chat Template 的判断条件,基于新版能力计算结果择优切换模板,日志同步记录择优原因。
总结
代码地址:github.com/ollama/ollama
Ollama v0.30.2 从安全、模型内核、第三方生态、硬件兼容、运维可观测性五个维度完成了系统性升级。安全侧封堵了 URL 越权和恶意 Markdown 注入这类高危漏洞;模型侧落地了 Laguna 全新 MoE 架构的原生支持和 llama.cpp 新版本内核;生态侧打通了 Cline 和 Qwen 的一键安装、完成了 Codex 双端配置隔离;运维侧补齐了 llama-server 卡死监控、缓存 Token 精准统计和模板全链路日志。这次更新既解决了不少线上使用中的痛点,又提前兼容了 Poolside Laguna 等新一代开源大模型。无论是个人本地部署,还是企业私有化批量推理场景,都推荐优先升级至 v0.30.2 版本。




