TimechoAI时序预测大模型:单变量与多变量预测开发实战,SDK安装与可视化完整教程

搞过后端开发、数据分析或物联网项目的小伙伴,应该都有切身感受。在时序预测这个领域,最让人头疼的往往不是算法逻辑本身。
真正消耗精力的环节其实是环境配置、模型训练以及参数调优——整套流程走下来,几天时间就过去了。更现实的问题是,大多数开发人员并非时序算法方面的专家,想要深入研究底层原理,时间成本实在太高。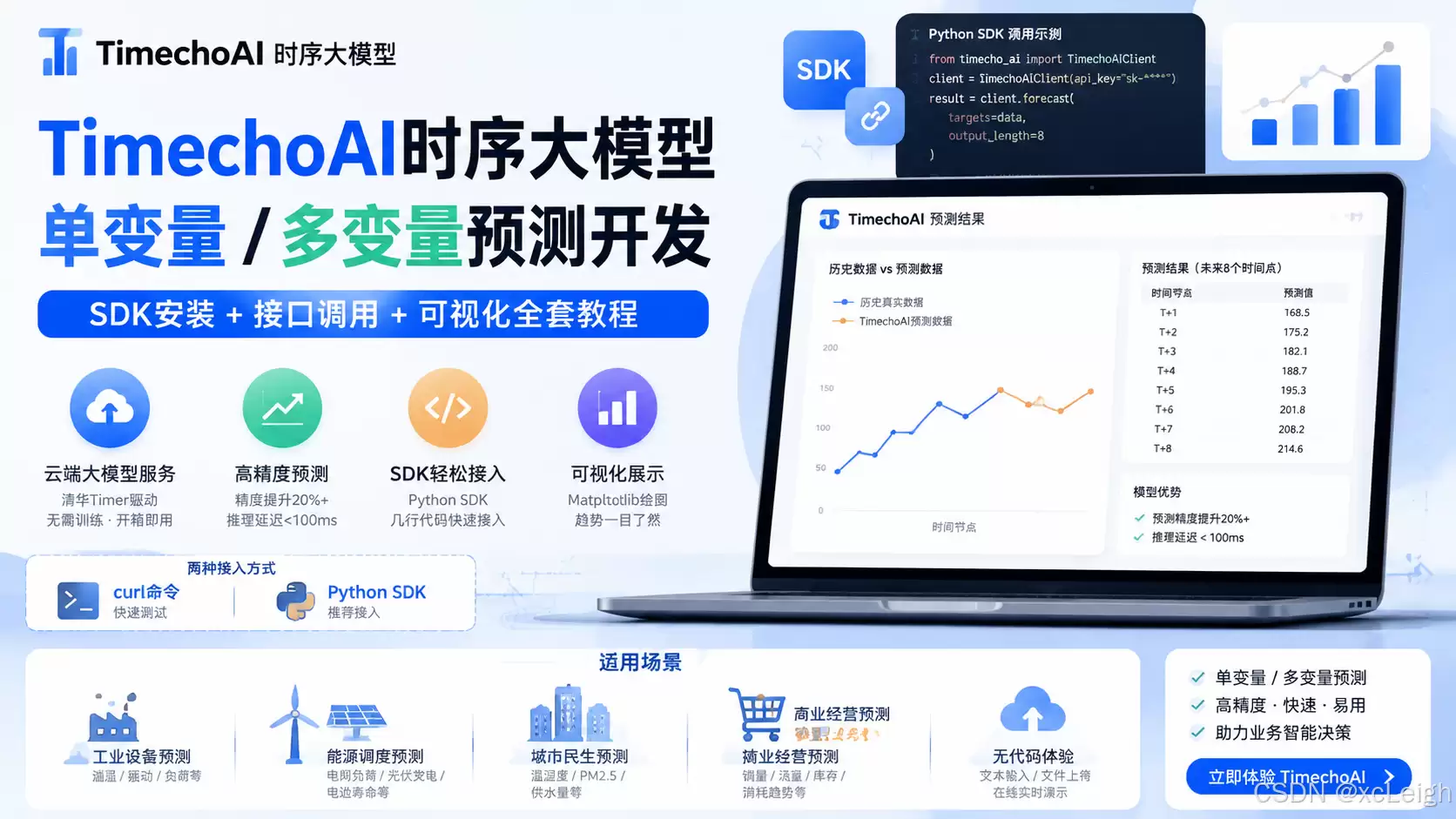
那么,有没有一种办法,可以不用自行训练模型,直接调用现成的在线服务,并且能实现单变量、多变量甚至带协变量的预测任务?答案是肯定的。今天接着上一篇文章,我们详细拆解一下 TimechoAI 时序大模型的高级用法,涵盖 SDK 安装、API 调用、多场景代码示例以及数据可视化,整个流程可以直接复制使用。
一、先回顾一下TimechoAI的核心要点
TimechoAI的底层技术,是基于清华大学Timer时序大模型构建的在线预测服务。
它与传统时序算法工具最大的不同在于:模型训练和推理计算全部在云端完成。开发者只需要上传数据、调用接口,就能直接获取预测结果。
它有两个非常实用的优势:
- 预测精度比传统的统计算法高出20%以上,能够满足日常业务需求
- 推理延迟可以稳定控制在100毫秒以内,即使是实时项目也能流畅使用
官方提供的三个关键入口再列一遍,新手朋友可以收藏备用:
- 开发文档:https://ai.timecho.com/docs/
- 实时演示案例:https://ai.timecho.com/realtime
- API密钥申请:https://ai.timecho.com/settings/keys
二、两种接入方式讲解:curl命令与Python SDK
1. 使用Curl命令快速测试(适合临时调试)
如果不想写代码,可以直接在终端中使用curl命令发送请求,替换为自己的API Key就能运行。
curl -s -X POST https://ai.timecho.com/ai/api/v1/forecast -H "Content-Type: application/json" -H "Authorization: Bearer 你的API-KEY" -d '{"targets": [{"columns": ["value"],"data": [[120],[135],[142],[168],[195],[220]]}],"output_length": [5]}'这个命令的逻辑很清晰:传入6条历史时序数据,让模型往后预测5个时间点的数值。
2. 安装Python官方SDK
如果是正式项目开发,推荐直接使用官方提供的SDK,比原生requests库调用要简洁高效很多。
pip install timecho-ai安装完成后,直接导入模块就能使用,省去了手动拼接请求头和参数的繁琐步骤。
三、单变量预测完整代码实战
单变量预测的核心思路很简单:只跟踪一条数据线的变化趋势,比如气温波动或单品销量变化,这类场景非常常见。
下面这段代码,直接复制就能运行,唯一需要修改的就是API Key。
import pandas as pd
from timecho_ai import TimechoAIClient
# 配置密钥,替换成自己在官网申请的值
api_key = "填写你的TimechoAI密钥"
# 定义输入和预测长度
INPUT_LENGTH = 16
OUTPUT_LENGTH = 8
# 初始化客户端
client = TimechoAIClient(api_key=api_key)
# 读取平台提供的示例时序数据
df = pd.read_csv("https://ai.timecho.com/data/sample.csv")
# 提取历史数据段
history_df = df[["time", "target"]][:INPUT_LENGTH]
# 发起单变量预测请求
result = client.forecast(targets=history_df, output_length=OUTPUT_LENGTH)
# 输出预测结果
print("单变量时序预测结果:")
print(result[0])运行后,控制台会输出未来8个时间点的预测数值,非常适合制作报表或趋势展示。
四、多变量时序预测代码示例
在实际业务场景中,往往需要同时关注多个指标。比如同步监测温度、湿度、PM2.5,就需要一次性预测多条曲线。
TimechoAI原生支持多变量并行预测,用法与单变量预测基本保持一致。
import pandas as pd
from timecho_ai import TimechoAIClient
api_key = "填写你的TimechoAI密钥"
client = TimechoAIClient(api_key=api_key)
# 多列时序数据,包含温度和湿度两组指标
multi_data = pd.DataFrame({
"time": list(range(20)),
"temp": [18,19,20,19,21,22,23,22,24,25,24,26,27,26,28,29,28,30,31,30],
"humidity": [88,87,85,86,84,83,82,83,81,80,81,79,78,79,77,76,77,75,74,75]
})
# 预测后续6个时间点
res_multi = client.forecast(targets=multi_data, output_length=6)
print("多变量预测结果:")
print(res_multi[0])这种写法非常适合气象监测、机房环境监控等多指标并行的应用场景。
五、时序预测结果可视化(使用Matplotlib绘图)
仅仅查看数字可能不够直观,建议将历史数据与预测数据同图展示,方便业务部门了解趋势变化。
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 解决中文乱码问题
# 拼接历史数据与预测数据
history_line = history_df["target"].values
forecast_line = result[0]["target"].values
# 绘制图表
plt.figure(figsize=(12,6))
plt.plot(range(len(history_line)), history_line, label="历史真实数据", color="#1f77b4")
plt.plot(range(len(history_line), len(history_line)+len(forecast_line)),
forecast_line, label="TimechoAI预测数据", color="#ff7f0e")
plt.xlabel("时间节点")
plt.ylabel("数值")
plt.title("TimechoAI时序数据预测趋势图")
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()运行代码后,会直接显示曲线图,历史曲线和预测曲线分段呈现,用于业务汇报或系统大屏展示都非常合适。
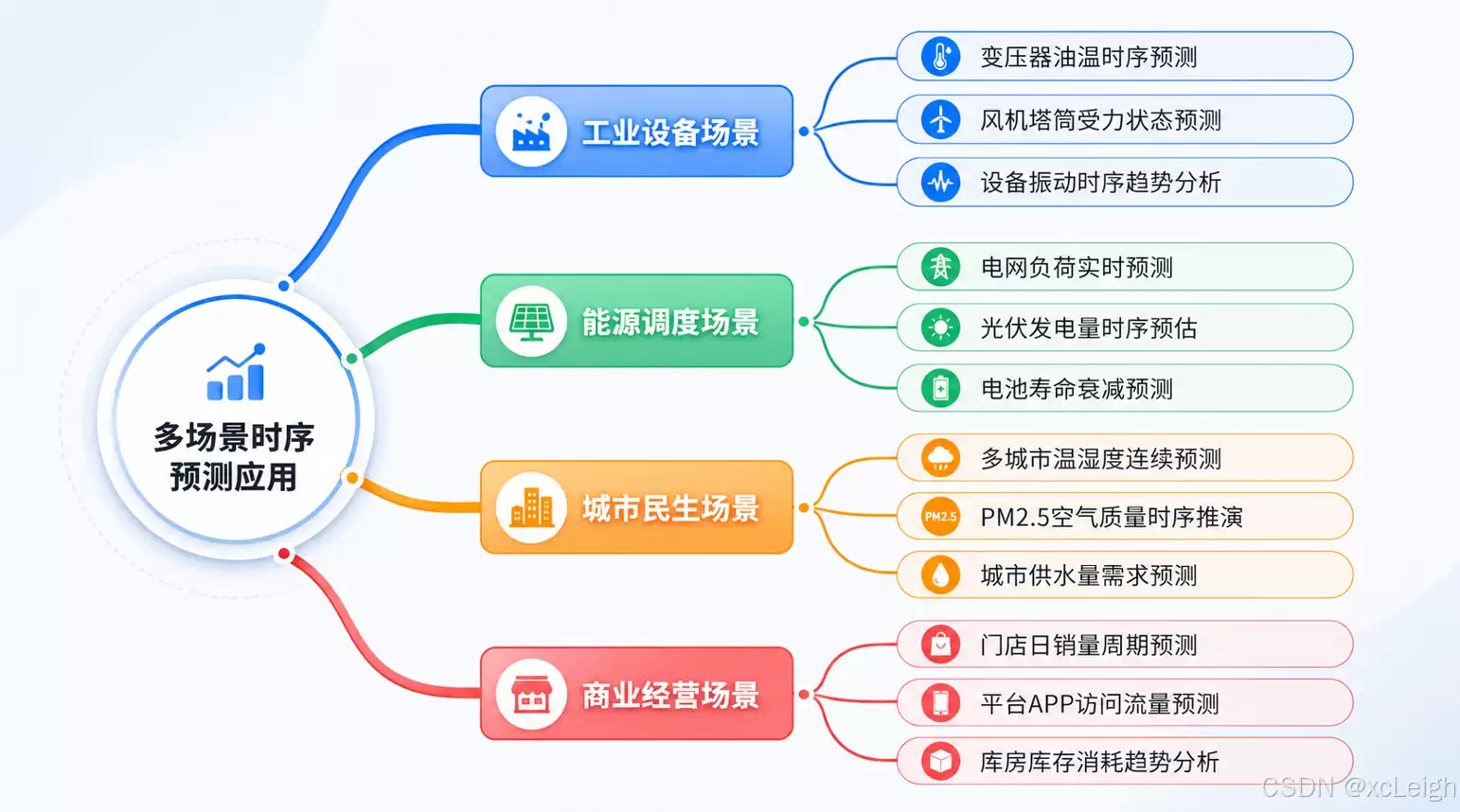
六、适配的工业与民生综合业务场景
七、网页端零代码上手方式
很多非开发人员如果不想接触代码,也可以通过其他方式体验功能。
直接访问TimechoAI官网,零代码即可操作,提供两种模式可供选择:
- 文本输入:直接录入时序数值,选择变压器油温预测这类模板任务,系统会自动生成预测结果
- 文件上传:上传本地CSV格式的时序文件,选择风机塔筒受力预测任务,平台会自动解析并输出预测数据
另外,官网的实时演示页面已经上线了北京、上海、广州三地的气象时序数据,每15分钟自动刷新,可以直观地看到模型实时运行的效果。
八、开发避坑小总结
- API Key务必妥善保管,切勿硬编码到代码仓库中,防止泄露风险。
- 传入的时序数据应尽量保持连续,如果存在缺失值需提前填充,这样预测精度会更高。
- 实时业务场景建议优先使用SDK方式调用,稳定性优于原生curl请求。
- 长周期预测建议拆分为多段请求,避免单次数据量过大导致超时问题。
九、结尾个人感受
平心而论,对于普通开发者和中小企业团队来说,完全没有必要从零开始搭建时序大模型。
训练需要算力,调参需要算法基础,落地还要适配工程代码,每一步都是不小的成本。
TimechoAI这种现成的云端时序服务,恰好解决了这个痛点。安装SDK后几行代码就能接入使用,支持单变量、多变量预测,还能搭配可视化工具直接落地。无论是做毕业设计、个人项目,还是企业正式业务开发,这套方案都完全够用。




