一文教你 OpenClaw Docker 部署 并调用本地Qwen3.5 9B模型
本文将详细介绍在 Ubuntu 24.04.2 LTS 系统上,使用 Docker 部署 Ollama(下载并运行 qwen3.5:9b-q8_0 模型),然后将其接入 OpenClaw 的完整流程。如果你想在本地运行千问 Qwen 模型,并通过 OpenClaw 的 Web UI 进行对话测试,只需按照下面的步骤操作即可。
0. 环境要求(建议提前核对)
- 操作系统:Ubuntu 24.04.2 LTS
- 显卡:NVIDIA,16GB 显存 更为稳妥(本文以此配置为例)
- 驱动:版本 ≥ 535(通常意味着 CUDA 12+ 生态更匹配)
- 内存:至少 16GB
- 磁盘:预留 ≥ 20GB(模型与缓存会占用空间)
1. 环境检测
1.1 NVIDIA 显卡驱动是否正常
nvidia-smi watch -n 1 nvidia-smi
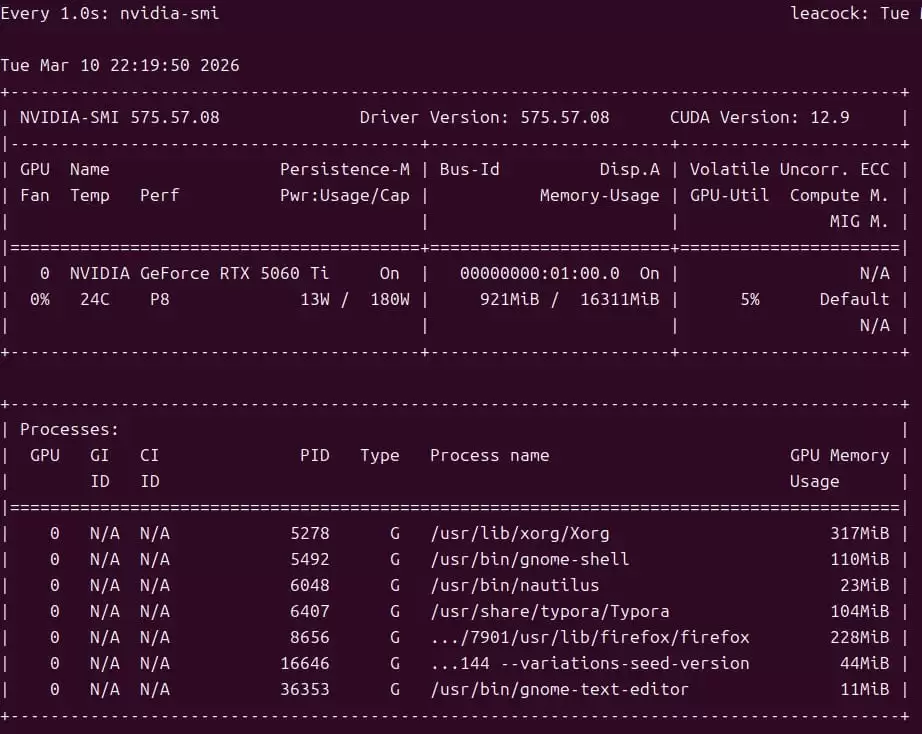
如果 nvidia-smi 命令无输出,或提示找不到该命令,通常意味着显卡驱动未正确安装;若驱动版本较低,建议先升级再继续后续操作。
1.2 Docker 是否已安装
docker -v

若没有显示版本信息,请先安装 Docker:
# 快速安装 Docker(如未安装) curl -fsSL https://get.docker.com | sh # 启动 Docker 并设置开机自启 sudo systemctl start docker sudo systemctl enable docker # 验证 Docker docker --version
2. Ollama:本地部署 Qwen3.5 9B(Q8_0 量化)
2.1 Docker 版 vs 系统服务版(systemctl)有什么区别?
Ollama 有两种常见安装方式:Docker 版 和 系统服务版。那么,它们有何不同?
| 维度 | Docker 版 Ollama | 系统服务版 Ollama(systemctl) |
|---|---|---|
| 运行环境 | 运行在容器内,依赖 Docker | 直接运行在系统中,无容器隔离 |
| GPU 使用 | 需要 --gpus all 显式启用 GPU | 直接使用主机 GPU(前提是驱动正常) |
| 数据位置 | 容器内 /root/.ollama(通常用 Docker 卷持久化) | 主机 ~/.ollama(普通用户)或 /root/.ollama(root) |
| 端口 | 通常映射主机 11434 | 默认直接占用主机 11434 |
| 冲突风险 | 端口映射相同会冲突 | 直接占用端口,容易与 Docker 版冲突 |
这里 推荐使用 Docker 版:更易于迁移和维护——尤其后续还要运行 OpenClaw 时。
2.2 如果你装过系统服务版:先停掉,避免端口冲突
sudo systemctl stop ollama sudo systemctl disable ollama
如果从未安装过系统服务版,这两条命令可能会提示 “Unit ollama.service not found”,忽略即可。
2.3 启动 Docker 版 Ollama(带 GPU + 数据持久化)
使用 Docker 卷 保存模型与缓存,好处是:删除容器不会丢失模型。
docker run -d --name ollama --restart=always --gpus all -p 11434:11434 -v ollama:/root/.ollama ollama/ollama:latest
注意事项:
--gpus all用于启用 GPU。-v ollama:/root/.ollama用于持久化模型数据。
如果遇到报错 could not select device driver "" with capabilities: [[gpu]],说明 Docker 尚未配置好 NVIDIA GPU 运行时(通常需要安装 NVIDIA Container Toolkit)。建议先按照 NVIDIA 官方文档配置好 nvidia-container-toolkit 再继续。
2.4 验证 Ollama 是否启动成功
# 1) 容器是否在运行(看到 Up 即正常) docker ps --filter "name=ollama" # 2) 端口是否可访问(返回 "Ollama is running" 即成功) curl https://127.0.0.1:11434
2.5 下载模型:qwen3.5:9b-q8_0
容易踩的坑:使用 Docker 版 Ollama 时,ollama pull/list 等命令必须在容器内执行(除非你单独在宿主机也安装了 Ollama CLI)。
docker exec -it ollama ollama pull qwen3.5:9b-q8_0
拉取完成后,列出模型确认:
docker exec -it ollama ollama list

然后运行一个简单对话,确认模型可正常工作:
docker exec -it ollama ollama run qwen3.5:9b-q8_0

若能正常输出,同时 nvidia-smi 中 GPU 有占用,说明 Ollama + GPU 配置成功。
2.6 如果拉取模型时报错:升级 Ollama(Docker 镜像)
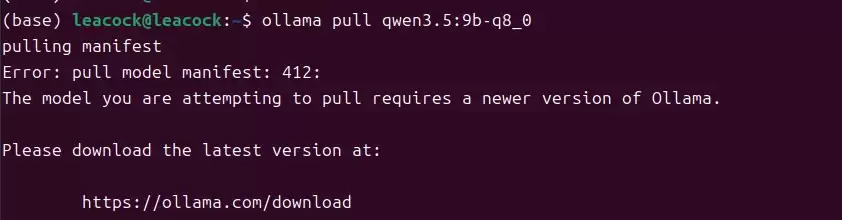
建议按以下顺序升级(数据卷会保留,不会丢失模型):
# 1) 拉取最新版镜像 docker pull ollama/ollama:latest # 2) 停止并删除旧容器(仅删除容器实例,卷数据会保留) docker stop ollama docker rm ollama # 3) 用新镜像重新启动容器 docker run -d --name ollama --restart=always --gpus all -p 11434:11434 -v ollama:/root/.ollama ollama/ollama:latest
3. OpenClaw:安装与对接 Ollama
3.1 准备 OpenClaw 的工作目录与数据卷
下面以 ~/openclaw-docker 为例(你也可以换成其他目录):
mkdir -p ~/openclaw-docker cd ~/openclaw-docker # 创建数据卷:持久化 OpenClaw 的配置与数据 docker volume create openclaw-data
如果想清空 OpenClaw 的所有配置(会丢失 gateway token、模型配置等),再执行:
docker volume rm openclaw-data
3.2 重点:root 与非 root(node)用户不要混用
默认情况下,Docker 部署 OpenClaw 时,root 与非 root(node)用户使用的配置目录不同:
- root 用户(UID 0)
- 主配置 / 工作目录:
/root/.openclaw - 沙箱工作区:
/root/.openclaw/sandboxes
- 主配置 / 工作目录:
- 非 root 用户(node,UID 1000,镜像默认)
- 主配置 / 工作目录:
/home/node/.openclaw - 沙箱工作区:
/home/node/.openclaw/sandboxes
- 主配置 / 工作目录:
关键区别一句话:configure 时使用哪个用户,后续运行容器也必须用同一用户,否则容易出现权限或配置找不到的问题。
本文后续统一使用 --user root,因此挂载路径均以 /root/.openclaw 为准。
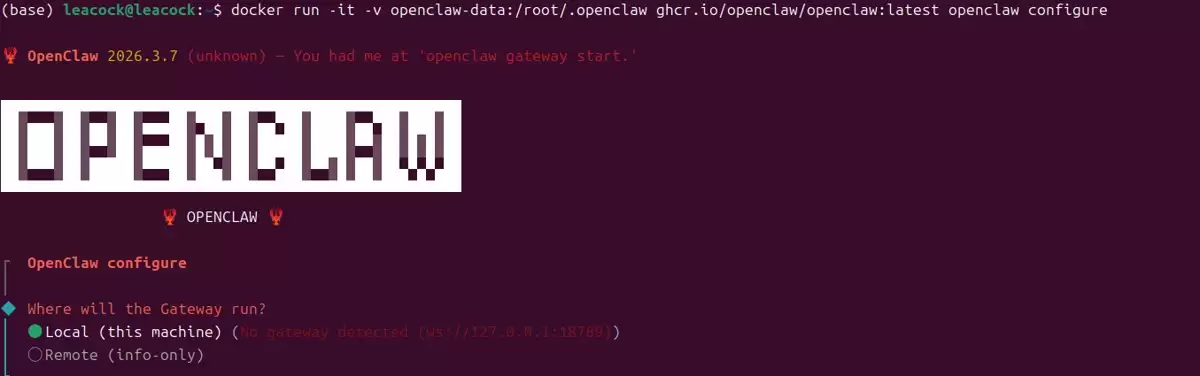
3.3 运行配置向导(openclaw configure)
docker run -it --rm --user root --net=host -v openclaw-data:/root/.openclaw ghcr.io/openclaw/openclaw:latest openclaw configure
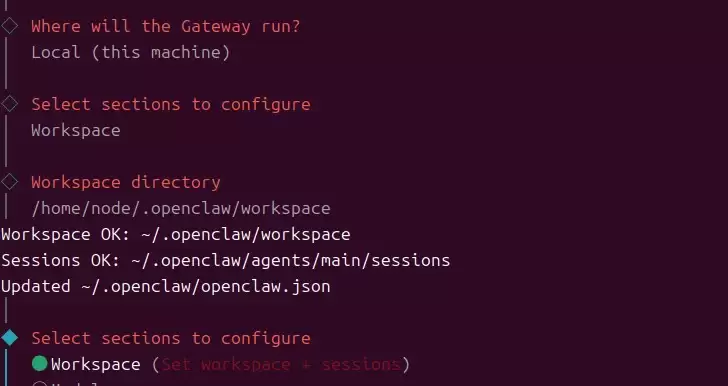
3.3.1 配置 Workspace(工作目录)
3.3.2 配置 Model(对接 Ollama)
建议按如下填写(根据实际情况替换):
- API Base URL:
- 如果像本文一样在
openclaw configure时加了--net=host:填写https://127.0.0.1:11434/v1 - 如果未使用
--net=host:不要填127.0.0.1,应填宿主机 IP,例如https://192.168.1.18:11434/v1
- 如果像本文一样在
- API Key:可随意填写或直接回车(本地 Ollama 通常不做鉴权),例如
sk-123456 - 模型名称:填写
ollama list中显示的模型名,例如qwen3.5:9b-q8_0(注意拼写)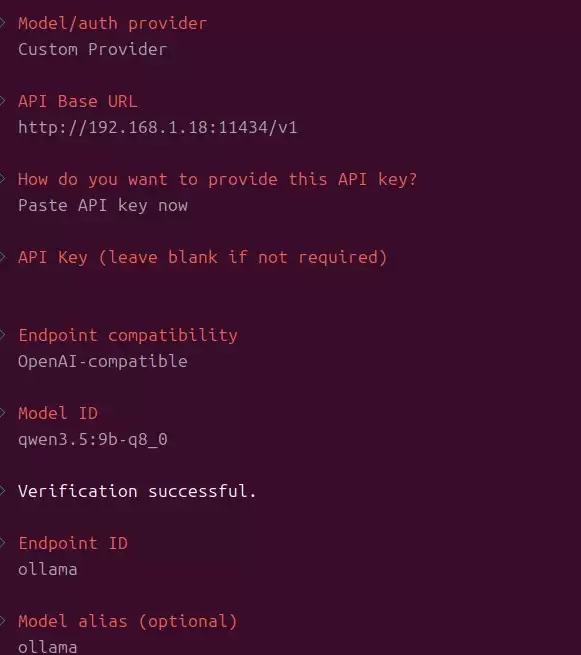
注意:Endpoint ID 建议填写 ollama。如果填写其他名称,可能会在 Web UI 发送消息时出现类似错误:
Agent failed before reply: No API key foun d for provider "custom-...". ...
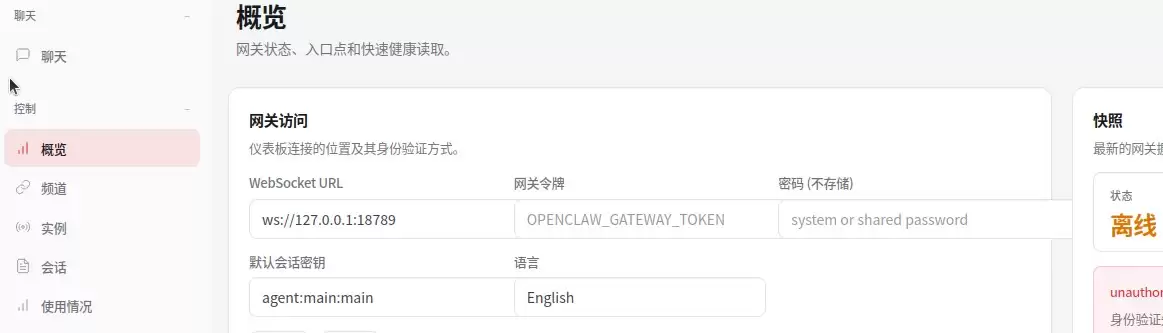
3.3.3 配置 Gateway(用于 Web UI 连接)
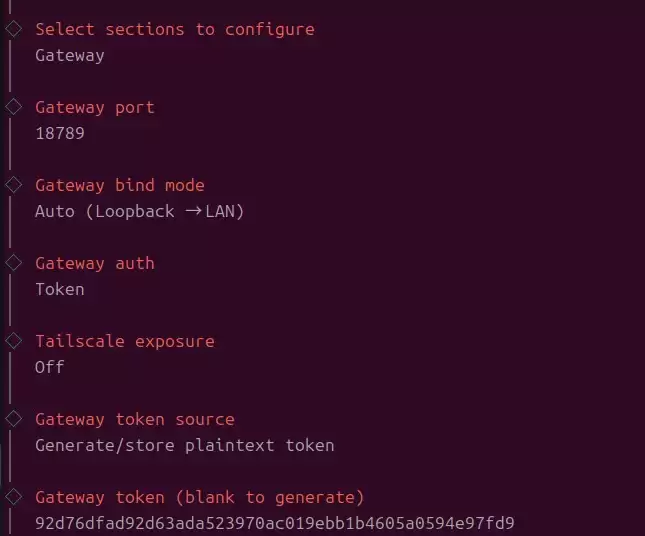
Gateway bind mode、Gateway auth、Tailscale exposure、Gateway token source 这些选项可以先按向导的推荐/默认值进行(本机使用一般不需要复杂的暴露方式)。
这里最重要的一点是:记下 Gateway token(它相当于你的 Web UI 连接口令)。
完成后选择 continue 结束配置:
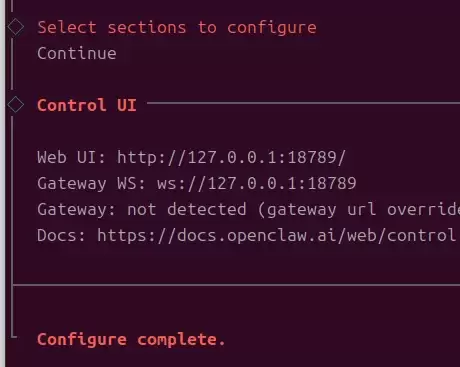
3.4 启动 OpenClaw 并访问 Web UI
在刚才的工作目录中执行(这样 $(pwd) 就是你的 workspace):
docker run -d --name openclaw --net=host --user root -v openclaw-data:/root/.openclaw -v "$(pwd)":/root/.openclaw/workspace -v /var/run/docker.sock:/var/run/docker.sock --restart unless-stopped ghcr.io/openclaw/openclaw:latest
说明:
-v "$(pwd)":/root/.openclaw/workspace:将宿主机当前目录挂载到容器中作为 workspace,方便在主机上直接管理文件。-v /var/run/docker.sock:/var/run/docker.sock:允许 OpenClaw 调用宿主机 Docker(存在安全风险,仅建议在信任的本机环境使用)。
浏览器打开:https://127.0.0.1:18789
如果出现需要令牌的页面,把配置阶段记录的 Gateway token 填入即可:
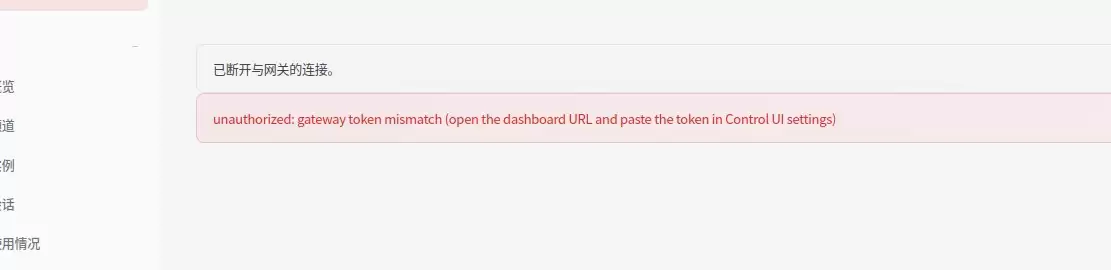
3.4.1 如果一直提示验证不通过
常见原因之一:configure 时使用的用户,与 docker run 运行时使用的用户不一致(例如一个用 root,另一个用 node),导致读取的配置目录不同。
也可以先用以下命令打印出 OpenClaw 的 dashboard 地址(不会自动打开浏览器):
docker exec -it openclaw openclaw dashboard --no-open
4. 简单验证:对话 + 观察 GPU
4.1 聊天询问模型信息
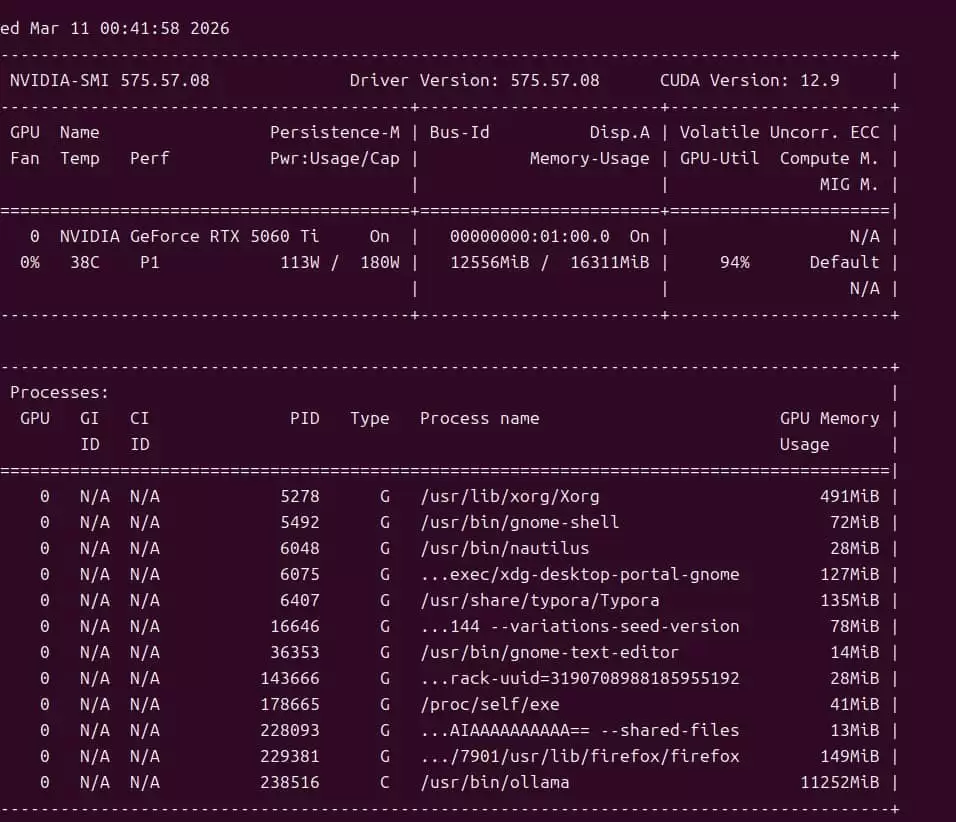
4.2 查看 GPU 使用情况
可以运行 watch -n 1 nvidia-smi,然后在 Web UI 发送几条消息,观察显存和利用率是否上升。
5. 重点坑位(建议作为自检清单)
- 搞不清自己使用的是 Docker 版还是系统服务版 Ollama
- 两者同时存在时,容易抢占 11434 端口,导致“连不上/连错服务”。
- Docker 版 Ollama 却在宿主机直接执行 ollama pull/list
- 除非宿主机也安装了 Ollama CLI,否则请使用
docker exec -it ollama ollama ...。
- 除非宿主机也安装了 Ollama CLI,否则请使用
- OpenClaw 的 root 与 node 用户混用
- 典型表现:权限报错(EACCES)、找不到 token、Web UI 校验失败。
- Model 配置中 Endpoint ID 未填写 ollama
- 可能导致 Web UI 报“No API key found for provider …”。
6. 名词解释(统一放在文章末尾)
- Ollama:用于在本地运行大模型的工具,提供命令行与 HTTP 接口。
- Qwen / 千问:阿里巴巴开源的 Qwen(千问)系列大模型。
- 9B:模型参数规模(约 90 亿参数),通常比 7B 更强,但也更消耗显存/内存。
- 8bit / Q8_0:一种量化方式,将模型权重以更低精度保存,降低显存占用(但可能略微影响效果)。
- CUDA:NVIDIA 的 GPU 计算平台与生态(包括驱动、运行库、工具链等)。
- NVIDIA Container Toolkit:使 Docker 容器能够使用 NVIDIA GPU 的组件(未正确安装会导致
--gpus all失败)。 - Gateway token:OpenClaw Web UI 用于连接网关的令牌,作用类似于“访问口令”。
- Endpoint ID:在 OpenClaw 中为某个模型接口设定的“内部标识名”,后续配置会引用它。
- Web UI:网页界面(通过浏览器操作的界面)。




